图像生成大一统!OmniGen:文生图、图像编辑!还能姿态检测?
【免费送书】????????????本次为大家送出5本《C++设计模式》参与方法:关注下方「3DCV」公众号在「3DCV」公众号后台,回复送书即可参与开奖时间:9月23日 10:000. 论文信息标题:OmniGen: Unified Image Generation作者:Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xin
【免费送书】
👇👇👇
本次为大家送出
5本《C++设计模式》
参与方法:关注下方「3DCV」公众号
在「3DCV」公众号后台,回复 送书 即可参与
开奖时间:9月23日 10:000. 论文信息
标题:OmniGen: Unified Image Generation
作者:Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Shuting Wang, Tiejun Huang, Zheng Liu
机构:Beijing Academy of Artificial Intelligence
原文链接:https://arxiv.org/abs/2409.11340
代码链接:https://github.com/vectorspacelab/omnigen
1. 引言
追求通用人工智能(AGI)加剧了对能够在单一框架内处理各种任务的生成式基础模型的需求。在自然语言处理(NLP)领域,大型语言模型(LLMs)已成为实现这一目标的典范,在众多语言任务(如问答、文本摘要和代码生成)中展现出惊人的通用性。
然而,视觉生成领域尚未出现与LLMs通用性相媲美的模型。当前的图像生成模型在特定任务上表现出色。例如,在文本到图像生成领域,最先进的模型如Stable Diffusion系列、DALL-E和Imagen取得了显著进展。同时,许多研究致力于扩展和优化扩散模型在特定任务上的能力。像ControlNet和T2i-Adapter这样的模型设计了一个额外的网络,插入到文本到图像的扩散模型中,以支持视觉条件。InstructPix2Pix则是在为图像编辑任务量身定制的综合数据集上进行训练的。尽管这些模型有其优势,但它们受限于特定任务的本性,并未展现出视觉生成通用模型所需的全面感知理解和生成能力。
是否有可能在单一的扩散框架内解决各种图像生成任务,如文本到图像、图像编辑、可控生成和图像修复,类似于GPT处理语言任务的方式?如果有一个通用模型,那么在实际应用中训练额外模块(如ControlNet、IP-Adapter、T2I-Adapter)的需求就可以被消除。受此潜力的驱动,我们探索了一个统一的图像生成框架,命名为OmniGen。
与流行的扩散模型不同,OmniGen具有非常简洁的结构,仅包含两个主要组件:一个VAE和一个Transformer模型,没有额外的编码器。OmniGen支持任意交错的文本和图像输入作为条件来指导图像生成,而不是仅限于文本或图像条件。为了训练一个鲁棒的统一模型,我们构建了第一个大规模统一图像生成数据集X2I,该数据集将各种任务统一成一种格式。此外,我们还融入了多个经典的计算机视觉任务,如人体姿态估计、边缘检测和图像去模糊,从而扩展了模型的能力边界,并增强了其在复杂图像生成任务中的熟练度。我们在多个基准测试集上评估了我们的模型,证明了其相比现有模型在文本到图像生成方面的竞争力。此外,我们的模型天然支持多种图像生成任务,如图像编辑、视觉条件生成和主题驱动生成,这些任务超出了当前扩散模型的能力范围。值得注意的是,OmniGen的设计允许在不同场景间进行稳健的迁移学习,便于处理之前未见过的任务和领域,并催生新的能力。
2. 摘要
在这项工作中,我们介绍了OmniGen,一种新的统一图像生成扩散模型。与流行的扩散模型(如稳定扩散)不同,OmniGen不再需要额外的模块(如ControlNet或IP适配器)来处理不同的控制条件。OmniGenis具有以下特征:1)统一性:OmniGenis不仅展示了文本到图像的生成能力,还内在地支持其他下游任务,如图像编辑、主题驱动的生成和可视条件生成。此外,OmniGen可以通过将经典的计算机视觉任务转换为图像生成任务来处理这些任务,如边缘检测和人体姿势识别。2)简单性:OmniGen的架构高度简化,不需要额外的文本编码器。此外,与现有的扩散模型相比,它更加用户友好,使得复杂的任务能够通过指令来完成,而不需要额外的预处理步骤(例如,人体姿态估计),从而显著简化了图像生成的工作流程。3)知识转移:通过统一格式的学习,OmniGen有效地跨不同任务转移知识,管理看不见的任务和领域,并展现出新颖的能力。我们还探讨了模型的推理能力和思维链机制的潜在应用。这项工作代表了对通用图像生成模型的首次尝试,但仍有几个未解决的问题。
3. 效果展示

4. 主要贡献
我们的贡献总结如下:
• 我们引入了OmniGen,一个在多个领域表现出色的统一图像生成模型。OmniGen展示了具有竞争力的文本到图像生成能力,并天然支持多种下游任务,如可控图像生成和主题驱动生成。此外,它还能执行经典的计算机视觉任务。据我们所知,OmniGen是第一个实现如此全面功能的图像生成模型。
• 我们构建了一个名为X2I的综合性图像生成数据集,代表“任何到图像”。该数据集包含了各种图像生成任务,并统一成了一种格式。推荐课程:彻底搞懂3D人脸重建原理,从基础知识、算法讲解、代码解读和落地应用。
• 通过在多任务数据集上进行统一训练,OmniGen能够将所学知识应用于解决未见过的任务和领域,并展现出新的能力。此外,OmniGen还表现出一定程度的推理能力。
5. 方法
设计原则。当前的扩散模型通常局限于常见的文本到图像任务,无法执行更广泛的下游图像生成任务。为了实现实际应用,用户通常需要设计和集成额外的网络结构来扩展扩散模型的能力,这使得模型变得非常繁琐。更糟糕的是,这些额外的参数网络通常是任务特定的,不能用于其他任务,除非为不同功能设计和训练更多的网络。为了规避这些问题,OmniGen的设计原则如下:1)通用性:接受各种任务和形式的图像和文本输入;2)简洁性,避免过于复杂的结构设计和众多额外组件。
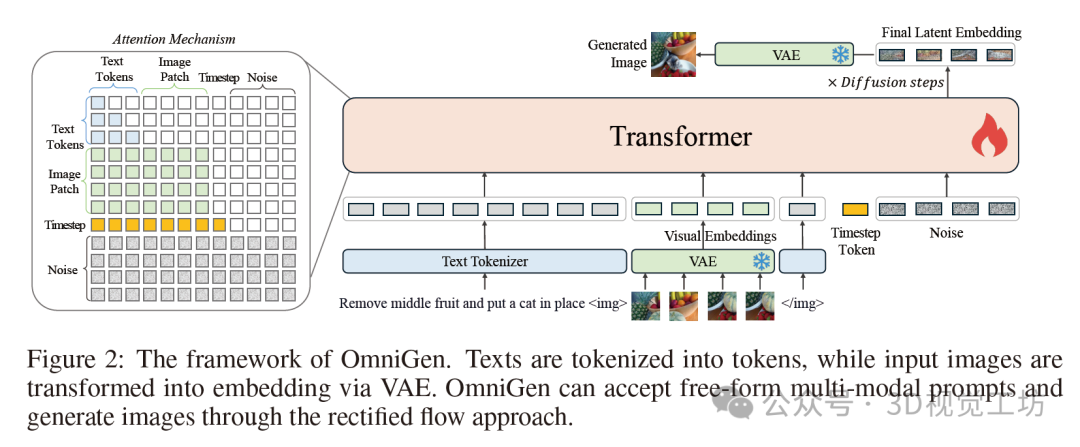
网络架构。如图2所示,OmniGen框架采用了一个由变分自编码器(VAE)[28]和预训练的大型Transformer模型组成的架构。具体来说,VAE从图像中提取连续的视觉特征,而Transformer模型则根据输入条件生成图像。在本文中,我们使用SDXL[52]中的VAE,并在训练过程中冻结它。我们使用Phi-3[1]来初始化Transformer模型,继承其出色的文本处理能力。与最先进的扩散模型不同,后者需要额外的编码器来预处理条件信息(如CLIP文本编码器和图像编码器),OmniGen本身就能编码条件信息,从而大大简化了流程。此外,OmniGen在单个模型内联合建模文本和图像,而不是像现有工作[67; 68; 70; 63; 9]那样使用单独的编码器独立建模不同的输入条件,这缺乏不同模态条件之间的交互。
输入格式。模型的输入可以是自由形式的多模态交错文本和图像。我们使用Phi-3的分词器来处理文本,无需任何修改。对于图像,我们首先使用带有简单线性层的VAE来提取潜在表示。然后,通过在线性空间中嵌入每个补丁,将它们展平为一系列视觉标记。遵循[50],我们对输入视觉标记应用基于标准频率的位置嵌入,并使用与SD3[13]相同的方法来处理不同纵横比的图像。此外,我们还将每个图像序列封装在两个特殊标记“”和“”中,然后将其插入到文本标记序列中。我们还在输入序列的末尾添加了时间步嵌入[50]。
注意力机制。与可以分解为离散标记进行建模的文本不同,我们认为图像应该作为一个整体进行建模。因此,我们修改了LLM中常见的因果注意力机制,将其与双向注意力相结合,如图2所示。具体来说,我们对序列中的每个元素应用因果注意力,但在每个图像序列内部应用双向注意力。这允许每个补丁关注同一图像内的其他补丁,同时确保每个图像只能关注之前出现的其他图像或文本序列。
推理。在推理过程中,我们随机采样一个高斯噪声,然后应用流匹配方法来预测目标速度,迭代多个步骤以获得最终的潜在表示。最后,我们使用VAE将潜在表示解码为预测的图像。默认的推理步骤设置为50。由于注意力机制,OmniGen可以像LLMs一样使用kv-cache加速推理:在GPU上存储输入条件的先前和当前键和值状态,以计算注意力而无需冗余计算。
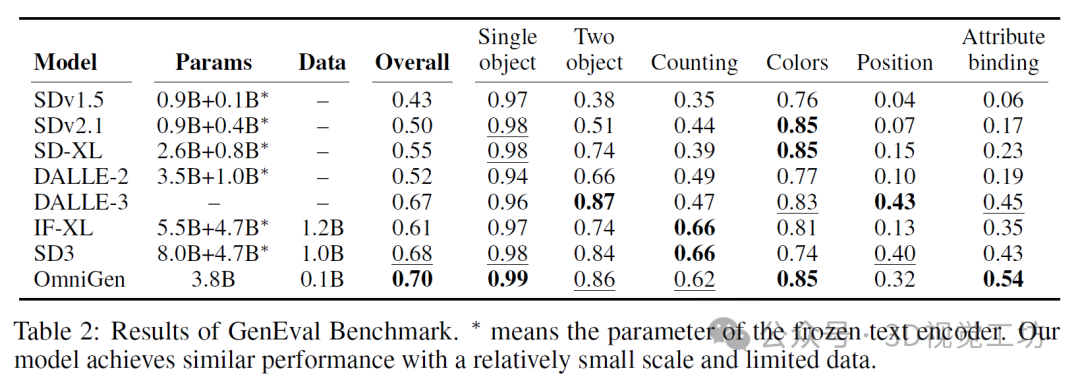
6. 实验结果

7. 局限性 & 未来工作
我们将当前模型的局限性总结如下:
• 与现有的扩散模型类似,OmniGen对文本提示敏感。通常,详细的文本描述会产生更高质量的图像。
• 当前模型的文本渲染能力有限;它可以处理较短的文本段落,但无法准确生成较长的文本。此外,由于资源限制,训练过程中输入图像的数量最多仅限于三张,这导致模型无法处理长图像序列。
• 生成的图像可能包含错误的细节,尤其是小而精致的部分。在主体驱动的生成任务中,面部特征偶尔无法完全对齐。OmniGen有时也会产生错误的手部描绘。
• OmniGen无法处理未见过的图像类型(例如,用于表面法线估计的图像)。
我们相信,通过在更多相关数据上训练模型,可以解决大多数局限性。此外,与大多数模型相比,对OmniGen进行下游任务的微调更为简单,因为它本质上支持各种图像生成任务,而无需投入大量精力和成本来构建额外的网络。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
【免费送书】
👇👇👇
本次为大家送出
5本《C++设计模式》
参与方法:关注下方「3DCV」公众号
在「3DCV」公众号后台,回复 送书 即可参与
开奖时间:9月23日 10:00
开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)