RegGAN:打破医学图像转换困境 --- 数据未对齐、噪声干扰和未配对图像
比如,我们有一组CT图像和相应的MRI图像,但这些图像由于患者在不同时间被不同设备扫描,因此它们之间存在未对齐的问题。通过在生成器后面加入 配准网络R 来纠正这种未对齐,使得即便是在噪声影响下也能进行有效的图像到图像的转换。这样,无论原始数据的对齐质量如何,RegGAN最终都能产生高质量的、空间上对齐的输出图像。配准网络将学习必要的空间变换,自动调整生成的图像以匹配目标图像,从而克服了未对齐的问题
论文:https://arxiv.org/pdf/2110.06465.pdf
代码:https://github.com/Kid-Liet/Reg-GAN.git
医学图像转换困境

一、传统的Pix2Pix方法要求输入图像必须是精确成对且对齐的。
- 每个输入图像X都需要一个精确对齐的目标图像Y来训练生成器。
- Pix2Pix 需要像素级对齐的成对图像,但在医学图像中,由于呼吸运动、解剖结构的变化、不同时间拍摄等因素,这种对齐可能难以实现。
- 如果输入的成对图像未对齐或存在其他形式的噪声,Pix2Pix 的性能可能会受到影响,因为不具备处理这些噪声的内置机制。
二、非成对的 Cycle-consistency 算法(如CycleGAN):
- 这种模式不需要输入的成对图像完全对齐,可以处理那些在不同时间、不同设备上拍摄的图像。
- 由于不要求输入和目标图像成对对齐,可能会产生多种解决方案
- 这意味着一个MRI图像可能被转换成多个在视觉上看起来合理,但在医学特征上不一致的PET图像。
- 不一致性可能导致误诊或错误的治疗计划,因为医生依赖于这些图像来确定病变的精确位置和代谢活动的强度。
三、RegGAN 允许输入的图像对,是对齐或者未对齐的。
允许非成对:
- 比如,我们没有每个 MRI 图像的确切 PET 对应图像,但需要从 MRI 推断 PET 图像,RegGAN 也能处理这种未配对的数据。
- TA 能学习不同成像模式之间的关系,即使没有精确的一一对应关系。
能够适应,从无噪声到大规模噪声的各种情况:
-
通过在生成器后面加入 配准网络R 来纠正这种未对齐,使得即便是在噪声影响下也能进行有效的图像到图像的转换。
-
图像会由于各种原因产生噪声,如眼球微小的运动而出现模糊、头部微小的移动导致未对齐、扫描器差异、扫描参数的变化等
不仅对数据集的要求不严格,还能满足医学图像分析的高精度要求。
无论数据集是否对齐,RegGAN 都比 Pix2Pix、Cycle-consistency 模式好。
关键方法:“损失修正”和“噪声模型转换”
- 这是 RegGAN 处理带噪声数据的核心方法,它将噪声视为变形误差并在网络架构中进行显式建模,通过配准网络来纠正和适应这些噪声。
- 配准网络是RegGAN架构中的一个关键部分,专门用于识别和纠正输入图像之间的空间错位。
- 网络目标是确定如何调整一个图像,使其与另一个图像空间对齐。
- 输入图像在开始时是未对齐的,网络的输出是矫正过的,与目标图像对齐的版本。
比如,我们有一组CT图像和相应的MRI图像,但这些图像由于患者在不同时间被不同设备扫描,因此它们之间存在未对齐的问题。
在 RegGAN 中,我们不需要事先手动对这些图像进行对齐。
相反,我们将这些未对齐的图像对输入到RegGAN。
配准网络将学习必要的空间变换,自动调整生成的图像以匹配目标图像,从而克服了未对齐的问题。
这样,无论原始数据的对齐质量如何,RegGAN最终都能产生高质量的、空间上对齐的输出图像。
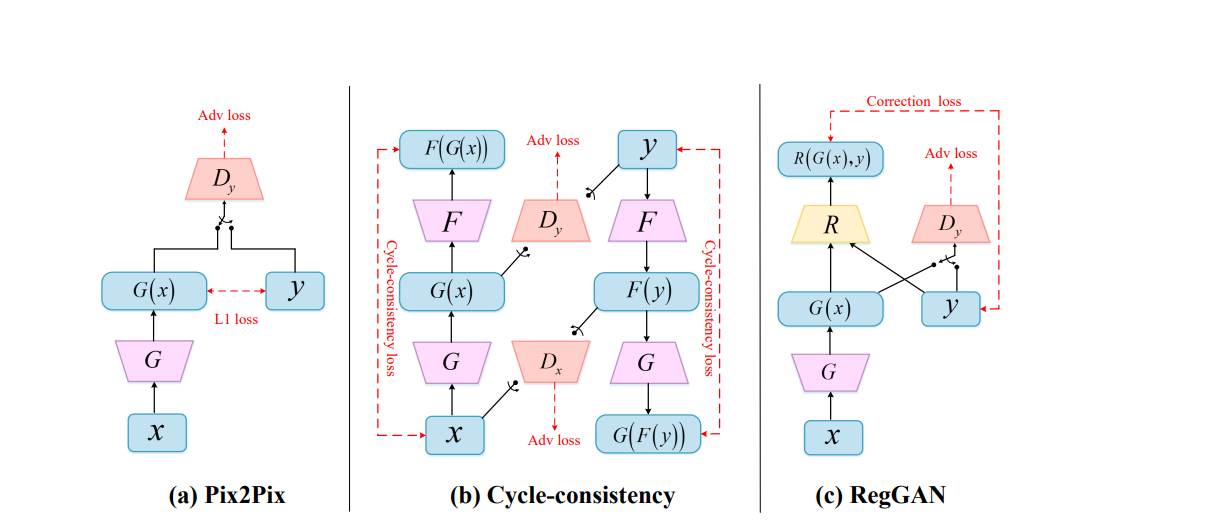
网络结构
上图是,三种不同模式的生成对抗网络(GANs)用于图像到图像的转换:
(a) Pix2Pix
- G:生成器,将输入图像 X 转换为目标图像 G(X)。
- Dy:判别器,用来判断生成的图像 G(X) 是否足够接近真实目标图像 Y。
- L1 loss:表示生成的图像 G(X) 和真实图像 Y 之间的像素级损失,用于训练生成器 G 使其输出与真实图像尽可能相似。
- Adv loss:对抗损失,用于训练判别器 Dy 以更好地区分生成的图像和真实图像。
(b) Cycle-consistency (如CycleGAN)
- G 和 F:互为反向的两个生成器,G 负责从 X 到 Y 的转换,而 F 负责从 Y 到 X 的反向转换。
- Dx 和 Dy:两个判别器,分别针对两个不同的域(X 和 Y)。
- Cycle-consistency loss:循环一致性损失,确保图像在经过两个相反方向的转换后能够回到原始状态,以此来训练 G 和 F。
- Adv loss:对抗损失,用于训练判别器 Dx 和 Dy。
© RegGAN
- G:生成器,将输入图像 X 转换为目标图像 G(X)。
- Dy:判别器,判断生成的图像 G(X) 是否足够接近真实目标图像 Y。
- R:配准网络,用于调整生成器 G 的输出,以更好地适应未对齐噪声的分布。
- Correction loss:修正损失,用于训练配准网络 R,帮助生成器适应目标图像的噪声分布。
- Adv loss:对抗损失,用于训练判别器 Dy。
效果

三种不同图像转换模型 CycleGAN©、Pix2Pix和RegGAN,在不同噪声水平下的性能。
性能指标包括,归一化平均绝对误差(NMAE)、峰值信噪比(PSNR)和结构相似性指数(SSIM)。
- 箭头向下,值越小越好,最好值用黑体加粗
- 箭头向上,值越大越好,最好值用黑体加粗
表中列出了七种不同的噪声设置,从Noise.0(无噪声)到Noise.5(最高噪声水平),以及一个非仿射噪声设置Noise.NA。
从表中看出:
- 在无噪声的条件下(Noise.0),所有模型都显示出相对较好的性能,但是随着噪声水平的增加,CycleGAN©和Pix2Pix的性能逐渐下降。
- 在所有噪声条件下,RegGAN 的性能都保持相对稳定,并且在多数情况下优于其他两种方法。
- 对于非仿射噪声(Noise.NA),RegGAN 的性能也表现出鲁棒性,这表明 RegGAN 可以有效处理各种类型的变形误差。
在医学图像转换上,非常好用。
- 对于成对且对齐的条件下,RegGAN 的性能至少与 Pix2Pix 相当,都优于 CycleGAN©。
- 对于成对但未对齐的条件下,RegGAN 的性能优于 CycleGAN©,CycleGAN© 的性能又优于 Pix2Pix。
- 对于未配对的条件下,RegGAN 的性能同样优于 CycleGAN©,而CycleGAN© 的性能优于 Pix2Pix。
解法拆解
目的:提出一种新的医学图像翻译模式RegGAN,解决现有Pix2Pix和Cycle-consistency模式存在的问题。
问题:
- Pix2Pix需要配对且对齐的图像数据,这在实际医疗场景中难以获得
- Cycle-consistency虽然不需要严格对齐的数据,但性能不够理想(需要两个生成器和判别器 且可能产生多解)
解法:设计RegGAN模式,包含以下子解法:
子解法1 - 基于"损失校正"理论
- 特征:将未对齐的目标图像视为带噪声的标签
- 对应关系:通过校正生成器输出来匹配噪声分布
子解法2 - 引入配准网络
- 特征:需要自适应拟合错位噪声分布
- 对应关系:在生成器后添加配准网络R来校正结果
子解法3 - 联合训练优化
- 特征:需要同时优化图像翻译和配准任务
- 对应关系:设计联合损失函数包含:校正损失、平滑损失和对抗损失
例子:以T1和T2脑部MRI图像翻译为例,RegGAN可以自适应处理未对齐的图像对,并保持良好的翻译性能。
- 逻辑链结构:
RegGAN
├── 损失校正理论
│ └── 未对齐图像作为噪声标签
├── 配准网络
│ ├── 自适应拟合噪声分布
│ └── 校正生成结果
└── 联合训练
├── 校正损失
├── 平滑损失
└── 对抗损失
- 隐性特征:
- 图像变形场的平滑性假设:假定变形场T满足T∘T^(-1)≡I
- 注册网络的选择:基于U-Net架构实现配准功能
- 配准与生成的交互机制:通过联合训练实现两个任务的互相促进
- 潜在局限性:
- 仅适用于医学图像,对自然图像效果可能不理想
- 对非刚性形变的处理能力有限
- 计算成本较高,需要同时训练多个网络
- 对于形变过大的图像对可能存在性能下降
- 理论基础中的平滑性假设在实际应用中可能不总是成立
算法设计原理
图像配准和翻译被视为独立问题
- 图像不对齐本质上是一种带噪声的标签问题
- 配准和翻译可以统一到同一框架下
- 一个生成器+配准网络可以替代双生成器结构
发现的关键规律:
- 统一性规律
- 特征:图像翻译和配准本质上都在处理域间映射
- 压缩:将两个任务统一到一个框架中
两个任务本质上都是域间映射问题、存在共同的优化目标和约束条件、可以共享特征表示和学习过程。
就像把英语翻译成中文(域间翻译)、同时把口语变成书面语(域间配准)、本质上都是在处理"从一个形式转换到另一个形式"。
图像翻译: T1 MRI → T2 MRI
- 改变图像的视觉特征/像素强度
图像配准: 未对齐 → 对齐
- 改变图像的空间位置关系
统一观点:都是在处理"映射转换"
- 翻译:像素值的映射
- 配准:空间位置的映射
- 噪声等价性规律
- 特征:不对齐等价于带噪声标签
- 压缩:用噪声校正理论统一处理对齐/未对齐数据
标准字帖:永
学生临摹:永 (歪歪扭扭,笔画位置偏移)
把"位置偏移"视为一种可以建模的噪声:
- 未对齐的"永" = 标准的"永" + 位置偏移量
就像:
- 歪歪扭扭的"永" = 标准"永" + 每个笔画的偏移量
- 配准网络R学习这个偏移量
- 生成器G学习字的形状特征
应用到医学图像:
未对齐的T2图像 = 对齐的T2图像 + 空间变形
具体实现:
1. 不把未对齐当作错误数据丢弃
2. 而是建模这种"偏移噪声"
3. 让配准网络R自动学习纠正偏移
4. 同时让生成器G学习图像特征转换
传统方法:把未对齐视为"坏数据"
RegGAN:把未对齐视为"带噪声的好数据"
- 噪声是有规律的空间变形
- 这种变形是可以学习和纠正的
- 不需要预先对齐数据
- 结构简化规律
- 特征:多个网络存在功能重叠
- 压缩:用单一生成器+配准网络实现相同功能
重复模式的删除:
- 网络架构
- 原有:需要两个生成器和判别器
- 压缩:一个生成器+配准网络即可
CycleGAN结构:
- 生成器G1: T1 → T2
- 生成器G2: T2 → T1
- 判别器D1和D2
RegGAN结构:
- 一个生成器G
- 一个配准网络R
- 一个判别器D
简化原理:
- 不需要来回翻译验证
- 用配准网络替代第二个生成器
- 减少了参数和计算量
- 损失函数
- 原有:cycle-consistency loss + 对抗损失
- 压缩:correction loss + smoothness loss + 对抗损失
- 数据预处理
- 原有:需要严格对齐的训练数据
- 压缩:直接处理未对齐数据
这种压缩视角揭示了RegGAN的本质创新:
- 通过统一理论框架压缩了问题表述
- 通过简化网络结构压缩了模型复杂度
- 通过自适应处理压缩了数据预处理要求
RegGAN通过发现和利用医学图像翻译任务中的内在规律和重复模式,实现了更高效的解决方案。它不是简单地堆叠更多组件,而是通过深入的理解来简化和统一处理方法。
传统方法 ≈ 死板的教学:
- Pix2Pix像要求学生必须先规范写字
- CycleGAN像两个老师反复纠正
RegGAN ≈ 灵活的教师:
- 理解学生的潦草字迹(处理未对齐)
- 在教学过程中顺便纠正书写(配准)
- 一个老师就能完成教学任务(简化结构)
假设我们有一组脑部MRI图像:
- T1序列扫描图像A
- T2序列扫描图像B
传统方法处理流程:
- 先用配准算法将A和B对齐
- 再用Pix2Pix做T1到T2的翻译
- 或者用CycleGAN处理,但需要两个生成器来回翻译
存在的冗余:
- 重复的域间映射:配准和翻译都在处理空间变换
- 多余的网络结构:两个生成器其实功能有重叠
- 繁琐的预处理:严格对齐要求增加了复杂度
RegGAN的压缩处理:
- 统一性规律示例
- 直接输入未对齐的A和B
- 同时学习空间变换(配准)和像素变换(翻译)
- 一次前向传播完成两个任务
- 噪声等价性规律示例
- 将B看作是带有空间变形"噪声"的目标
- 配准网络自动学习这种变形模式
- 不需要预先对齐,降低了数据处理难度
- 结构简化规律示例
- 一个生成器G: T1 → T2
- 一个配准网络R: 处理空间变形
- 一个判别器D: 评估真实性
最终效果:
- 输入:未对齐的T1图像
- 输出:对齐且翻译后的T2图像
- 中间过程自动处理了配准和翻译
- 网络参数量减少,训练更高效
观察
数据对齐程度:
- Noise.0:完全对齐
- Noise.1-5:不同程度的错位
- Noise.NA:非仿射变换
观察到的现象:
- Pix2Pix性能随错位增加急剧下降
- CycleGAN性能相对稳定但不够好
实验设计:
1. 不同噪声等级测试
2. 配对/未配对数据对比
3. 与现有方法对比
验证结果:
- RegGAN在所有噪声等级下都优于Pix2Pix
- 单生成器+配准网络优于双生成器结构
- 理论分析证明了噪声建模的可行性
分析
A. 叠加形态(从基础到高级的叠加):
底层:基础图像对齐
↓
中层:图像特征转换
↓
高层:自适应噪声处理
B. 构成形态(小部分组成大部分,涌现新能力):
基础组件:
- 生成器(G):图像翻译能力
- 配准网络(R):空间变换能力
- 判别器(D):真实性评估能力
组合后涌现:
- G + R:自适应处理未对齐图像
- G + R + D:高质量的跨模态转换
C. 分化形态(一个功能分化为多个子功能):
图像转换任务
├── 空间转换
│ ├── 旋转校正
│ ├── 平移调整
│ └── 缩放修正
└── 模态转换
├── 特征提取
├── 风格迁移
└── 细节重建
- 线性结构分析(发展趋势):
过去 → 现在 → 未来
Pix2Pix → CycleGAN → RegGAN
(严格对齐) → (双向循环) → (统一框架)
性能提升趋势:
- 数据要求:严格 → 宽松
- 网络结构:复杂 → 简化
- 适应能力:有限 → 通用
- 矩阵结构(问题定位):
数据对齐度
方法 高 中 低
-----------------------
Pix2Pix 优 差 差
CycleGAN 中 中 中
RegGAN 优 优 优
计算复杂度
网络 参数量 训练时间 推理速度
-----------------------------
单生成器 低 快 快
双生成器 高 慢 慢
RegGAN 中 中 快
- 系统分析(组件关系):
核心系统组件:
[生成器G] ←→ [配准网络R]
↓ ↓
[判别器D] ←→ [损失函数]
反馈循环:
1. 正向流程
- G生成图像
- R进行配准
- D评估质量
2. 反馈调节
- 损失函数指导训练
- 网络权重更新
- 性能逐步提升
组合分析的关键发现:
- 从层级结构看:
- RegGAN实现了功能的优雅集成
- 各部分协同产生了更强的能力
- 从线性趋势看:
- 反映了医学图像处理的演进方向
- 展示了简化和统一的趋势
- 从矩阵定位看:
- RegGAN在各种条件下都保持稳定性能
- 平衡了效率和效果
- 从系统关系看:
- 组件间的交互形成了自适应机制
- 整体大于部分之和
论文大纲
├── 1 图像翻译问题【核心问题】
│ ├── 现有方法的局限【问题分析】
│ │ ├── Pix2Pix【监督学习方法】
│ │ │ ├── 优点:翻译质量高【性能评价】
│ │ │ └── 缺点:需要对齐数据【限制条件】
│ │ └── CycleGAN【无监督学习方法】
│ │ ├── 优点:不需严格对齐【适用条件】
│ │ └── 缺点:性能次优【性能评价】
│ └── 解决思路【方法创新】
│ ├── 将未对齐视为噪声【理论基础】
│ └── 统一配准和翻译【方法突破】
│
├── 2 RegGAN方法【技术方案】
│ ├── 理论基础【原理支撑】
│ │ ├── 损失校正理论【核心理论】
│ │ └── 噪声建模方法【技术手段】
│ ├── 网络结构【架构设计】
│ │ ├── 生成器G【功能模块】
│ │ ├── 配准网络R【功能模块】
│ │ └── 判别器D【功能模块】
│ └── 损失函数【优化目标】
│ ├── 校正损失【约束条件】
│ ├── 平滑损失【约束条件】
│ └── 对抗损失【约束条件】
│
├── 3 实验验证【效果验证】
│ ├── 数据集【实验素材】
│ │ ├── BraTS 2018【数据来源】
│ │ ├── 配对数据【数据类型】
│ │ └── 未配对数据【数据类型】
│ ├── 对比实验【方法对比】
│ │ ├── 不同噪声级别【实验变量】
│ │ └── 不同方法比较【实验设计】
│ └── 性能指标【评估标准】
│ ├── NMAE【评价指标】
│ ├── PSNR【评价指标】
│ └── SSIM【评价指标】
│
└── 4 应用价值【实际意义】
├── 医学诊断【应用场景】
├── 治疗规划【应用场景】
└── 研究价值【理论贡献】
方法部分:
├── 输入层【数据流入】
│ ├── 源域图像x【输入数据】
│ │ └── T1序列MRI【数据类型】
│ └── 目标域图像y【参考数据】
│ ├── T2序列MRI【数据类型】
│ └── 带有空间变形噪声【数据特征】
│
├── 理论基础【核心原理】
│ ├── 损失校正理论【基础理论】
│ │ ├── 输入:带噪声标签ỹ【数据定义】
│ │ ├── 建模:y = ỹ ∘ T【数学表达】
│ │ └── 目标:找到最优G【优化目标】
│ └── 噪声建模方法【技术实现】
│ ├── 空间变形建模【处理方式】
│ └── 自适应拟合【优化策略】
│
├── 处理流程【网络架构】
│ ├── 生成器G【主干网络】
│ │ ├── 输入:源域图像x【数据流】
│ │ ├── 处理:域间特征转换【功能】
│ │ └── 输出:初步转换结果G(x)【中间结果】
│ ├── 配准网络R【辅助网络】
│ │ ├── 输入:G(x)和ỹ【数据流】
│ │ ├── 处理:计算变形场【功能】
│ │ └── 输出:配准后结果R(G(x),ỹ)【处理结果】
│ └── 判别器D【评估网络】
│ ├── 输入:生成结果和真实图像【数据流】
│ ├── 处理:真实性判断【功能】
│ └── 输出:判别概率【评估结果】
│
└── 优化目标【损失函数】
├── 校正损失LCorr【主要约束】
│ ├── 计算:∥ỹ - G(x)∘R(G(x),ỹ)∥1【数学表达】
│ └── 作用:确保生成质量【优化目的】
├── 平滑损失LSmooth【辅助约束】
│ ├── 计算:∥∇R(G(x),ỹ)∥2【数学表达】
│ └── 作用:保证变形场平滑【优化目的】
└── 对抗损失LAdv【质量约束】
├── 计算:Ex,y[log(D(y)) + log(1-D(G(x)))]【数学表达】
└── 作用:提升生成真实性【优化目的】
能不能用于 fundus 生成OCT?
5WHY分析:
WHY 1: 为什么RegGAN能实现不配对的医学图像转换?
- 将未对齐视为噪声问题
- 通过配准网络自适应学习空间变形
- 利用生成对抗网络学习域间映射
WHY 2: 为什么这个原理不能直接用于眼底图转OCT?
- 眼底图(2D)和OCT(3D)维度不同
- 两种模态的信息结构差异大
- 缺乏直接的空间对应关系
WHY 3: 为什么维度和结构差异如此重要?
- 2D到3D是信息增维过程
- 缺失的深度信息难以准确估计
- 解剖结构的投影关系复杂
WHY 4: 为什么现有方法难以解决这个问题?
- 缺乏足够的先验知识约束
- 3D结构重建存在多解性
- 模态间的信息鸿沟太大
WHY 5: 最根本的原因是什么?
- 信息不对等:2D到3D的本质信息损失
- 结构复杂:眼部组织的复杂层次结构
- 对应关系:缺乏可靠的跨模态映射机制
SO 1: 可以如何改进?
├── 架构改进
│ ├── 引入3D先验知识
│ ├── 设计深度估计模块
│ └── 增加解剖结构约束
└── 方法创新
├── 分层生成策略
│ ├── 2D特征提取
│ ├── 深度推理
│ └── 3D重建
└── 多任务学习
├── 表面重建
├── 层次分割
└── 特征对齐
关键发现和建议:
- 主要挑战
- 维度差异:2D到3D的信息补全
- 结构复杂:眼部组织的精细重建
- 模态差异:跨模态特征映射
虽然眼底图转OCT面临较大挑战,但通过适当的技术创新和方法改进,实现这一转换是可能的。
关键在于如何有效处理维度差异和结构复杂性的问题。
- 维度差异处理案例:
A. CT重建的启发
├── 问题类比
│ ├── X光(2D) → CT(3D)重建
│ └── 眼底图(2D) → OCT(3D)重建
├── 技术借鉴
│ ├── 反投影算法
│ │ └── 从多角度2D图像重建3D结构
│ ├── 迭代重建方法
│ │ └── 逐步优化3D体积估计
│ └── 深度学习方法
│ └── NeRF网络的3D场景重建
- 人脸重建案例:
A. 单张照片重建3D人脸
├── 技术路线
│ ├── 3D形变模型(3DMM)
│ │ ├── 建立统计形状模型
│ │ ├── 提取特征参数
│ │ └── 生成3D模型
│ └── 深度估计网络
│ ├── 学习面部深度图
│ ├── 提取几何特征
│ └── 重建surface模型
- 眼底结构重建方案:
A. 分层重建策略
├── 解剖学分层
│ ├── 视网膜表面
│ ├── 神经纤维层
│ ├── 视网膜色素上皮
│ └── 脉络膜
├── 技术实现
│ ├── 第一步:2D分割
│ │ ├── 分割各解剖结构
│ │ └── 提取层次关系
│ ├── 第二步:深度估计
│ │ ├── 基于解剖先验
│ │ ├── 血管深度推理
│ │ └── 组织厚度预测
│ └── 第三步:3D重建
│ ├── 层次化重建
│ ├── 结构对齐
│ └── 体积插值
- 多模态融合案例:
A. 眼底多模态数据融合
├── 数据源
│ ├── 眼底照相
│ ├── 荧光血管造影
│ ├── 自发荧光
│ └── 超声数据
├── 融合策略
│ ├── 特征级融合
│ │ ├── 提取多模态特征
│ │ └── 特征对齐与整合
│ ├── 决策级融合
│ │ ├── 独立重建结果
│ │ └── 结果投票或加权
│ └── 端到端融合
│ ├── 多流网络
│ └── 注意力机制
- 实际解决方案:
A. 混合架构设计
├── 网络组件
│ ├── 2D特征提取器
│ │ ├── 使用ResNet提取眼底特征
│ │ └── 注意力机制突出关键区域
│ ├── 深度估计模块
│ │ ├── 基于解剖先验的深度预测
│ │ └── 不确定性建模
│ ├── 3D重建模块
│ │ ├── 3D卷积生成器
│ │ └── 体素refinement网络
│ └── 质量评估模块
│ ├── 结构一致性检查
│ └── 临床可用性评估
└── 损失函数设计
├── 重建损失
│ ├── 体素级别L1损失
│ └── 结构相似性损失
├── 解剖约束损失
│ ├── 层间关系约束
│ └── 厚度分布约束
└── 对抗损失
├── 3D判别器
└── 切片级判别器
关键技术要点:
- 深度信息重建:
- 利用解剖学先验
- 血管网络作为深度线索
- 组织层次作为约束
- 结构保持:
- 保持血管连续性
- 维持层间关系
- 确保形态学特征
- 验证机制:
- 多角度切片验证
- 解剖结构验证
- 专家评估反馈
这些案例和方案说明,虽然眼底图转OCT是个复杂问题,但可以通过:
4. 借鉴其他领域成熟技术
5. 充分利用医学先验知识
6. 设计专门的网络架构
来逐步实现这个目标。关键是要将问题分解,并在各个环节都加入合适的约束和验证机制。
创意
让我使用这些创意思维方法来分析RegGAN潜在的创新点:
- 组合视角
- 现有组合:配准网络 + 生成网络
创新点:
├── 跨领域组合
│ ├── 图像压缩 + RegGAN:自适应压缩配准
│ ├── 注意力机制 + RegGAN:区域重要性自动配准
│ └── 联邦学习 + RegGAN:分布式医学图像处理
└── 功能组合
├── 多模态融合:CT+MRI+超声联合配准翻译
├── 诊断系统集成:RegGAN+医疗报告生成
└── 实时处理:手术导航+即时图像转换
- 拆开视角
现有结构:单一大型网络
创新点:
├── 功能拆分
│ ├── 轻量级RegGAN:针对不同设备优化
│ ├── 模块化设计:可插拔的配准组件
│ └── 分级处理:粗配准+精配准分离
└── 任务拆分
├── 专科化:针对不同器官优化的子网络
├── 分辨率层次:多尺度配准策略
└── 特征分解:解耦的特征提取和转换
- 转换视角
现有应用:医学图像翻译
创新方向:
├── 领域迁移
│ ├── 工业检测:零件缺陷对比分析
│ ├── 遥感图像:多时相图像配准
│ └── 安防监控:跨摄像头目标追踪
└── 功能扩展
├── 医学教育:病例对比学习系统
├── 手术规划:术前术后图像匹配
└── 药物研发:分子影像配准分析
- 借用视角
从其他领域借鉴:
├── 技术借鉴
│ ├── 自然语言处理:Transformer架构用于空间注意力
│ ├── 强化学习:自适应配准策略
│ └── 图神经网络:解剖结构建模
└── 方法论借鉴
├── 迁移学习:跨域适应能力
├── 元学习:快速适应新任务
└── 对比学习:提升特征表示
- 反向思考视角
颠覆传统假设:
├── 反转设计思路
│ ├── 从配准引导生成到生成引导配准
│ ├── 从像素级对齐到语义级对齐
│ └── 从空间变换到特征变换
└── 挑战常规认知
├── 不需要配准网络的图像翻译
├── 完全无监督的质量评估
└── 自适应的网络结构演化
- 问题视角
深入分析现有局限:
├── 技术挑战
│ ├── 计算效率:轻量化网络设计
│ ├── 鲁棒性:对抗扰动处理
│ └── 泛化性:跨设备适应
└── 应用挑战
├── 隐私保护:联邦学习整合
├── 实时性:流处理架构
└── 可解释性:注意力可视化
- 类比型思维
第一步:通过相似性获得灵感
├── 自然界类比
│ ├── 视觉系统:人眼对焦机制启发的自适应配准
│ ├── 免疫系统:错误检测和自我修正机制
│ └── 群体智能:多agent协同配准策略
└── 社会系统类比
├── 交通调度:多层级路径优化启发的配准网络
├── 教育系统:渐进式学习策略
└── 市场机制:供需平衡启发的特征匹配
第二步:探索背景结构
├── 机制分析
│ ├── 生物适应性:启发自适应学习率
│ ├── 反馈机制:实时质量评估
│ └── 分层架构:多层次特征提取
└── 流程优化
├── 并行处理:多分支网络设计
├── 资源分配:计算资源动态调度
└── 质量控制:多重验证机制
- 印象型思维
基于直观感受:
├── 视觉印象
│ ├── 渐变过渡:平滑的图像转换效果
│ ├── 层次分明:多尺度特征表示
│ └── 对比鲜明:关键区域增强
└── 体验印象
├── 交互友好:简化操作界面
├── 实时反馈:处理进度可视化
└── 直观展示:结果对比展示
- 自我对话方法
├── 用户视角
│ ├── 如何简化操作流程?
│ │ └── 一键式处理Pipeline
│ ├── 如何提高可信度?
│ │ └── 多模态验证机制
│ └── 如何保证实用性?
│ └── 临床需求导向设计
└── 技术视角
├── 如何提升性能?
│ └── 硬件加速优化
├── 如何保证稳定性?
│ └── 鲁棒性增强策略
└── 如何降低成本?
└── 模型压缩技术
- 以终为始
目标导向分析:
├── 最终目标
│ ├── 临床应用
│ │ ├── 诊断辅助系统集成
│ │ ├── 手术规划支持
│ │ └── 疗效评估工具
│ └── 技术指标
│ ├── 实时处理能力
│ ├── 亚毫米级精度
│ └── 99.9%可靠性
└── 路径规划
├── 技术路线
│ ├── 深度学习框架优化
│ ├── 硬件加速方案
│ └── 算法效率提升
└── 应用路线
├── 临床试验验证
├── 产品化开发
└── 市场推广策略
- 思维风暴(量化创意)
├── 技术创新点
│ ├── 自进化网络架构
│ ├── 动态配准策略
│ ├── 多模态融合机制
│ └── 智能质量评估
└── 应用创新点
├── 跨平台部署方案
├── 云端协同处理
├── 个性化定制服务
└── 开放API生态
- 最渴望联结
医生和患者的核心需求:
├── 医生需求
│ ├── 诊断准确性
│ ├── 操作便捷性
│ └── 时间效率
└── 患者需求
├── 诊断可靠性
├── 治疗精准性
└── 成本可接受性
- 空隙填补
市场空白分析:
├── 技术空白
│ ├── 超大规模数据处理
│ ├── 极端场景适应
│ └── 实时3D配准
└── 应用空白
├── 移动端轻量化方案
├── 低资源环境解决方案
└── 专科定制化服务
- 再定义视角
重新定义RegGAN的本质:
├── 身份重定义
│ ├── 从图像处理工具到医疗诊断平台
│ │ ├── 集成病历分析
│ │ ├── 诊断建议生成
│ │ └── 治疗方案推荐
│ └── 从单一任务到全流程管理
│ ├── 预处理自动化
│ ├── 质量控制体系
│ └── 后处理优化
└── 功能重定义
├── 从静态模型到动态系统
│ ├── 在线学习能力
│ ├── 自适应优化
│ └── 持续进化
└── 从工具到平台
├── 开放API生态
├── 插件化架构
└── 社区协作模式
- 软化视角
减轻技术门槛:
├── 交互软化
│ ├── 可视化配置界面
│ │ ├── 拖拽式网络设计
│ │ ├── 参数可视化调节
│ │ └── 实时效果预览
│ └── 智能辅助系统
│ ├── 配置建议生成
│ ├── 错误自动修正
│ └── 性能优化提示
└── 应用软化
├── 渐进式部署方案
│ ├── 基础版到专业版
│ ├── 模块化升级
│ └── 按需扩展
└── 场景适应策略
├── 自动场景识别
├── 参数自适应
└── 结果自优化
- 附身视角
模拟其他成功系统:
├── 模拟自然系统
│ ├── 生态系统
│ │ ├── 自组织架构
│ │ ├── 适应性进化
│ │ └── 共生发展
│ └── 神经系统
│ ├── 分布式处理
│ ├── 可塑性学习
│ └── 冗余容错
└── 模拟人工系统
├── 工业生产线
│ ├── 标准化流程
│ ├── 质量控制
│ └── 效率优化
└── 社交网络
├── 用户交互
├── 信息传播
└── 价值创造
- 配角视角
关注辅助功能:
├── 数据管理
│ ├── 智能存储系统
│ │ ├── 自动数据分类
│ │ ├── 版本控制
│ │ └── 检索优化
│ └── 数据增强工具
│ ├── 自动标注
│ ├── 质量评估
│ └── 数据清洗
└── 运维支持
├── 监控系统
│ ├── 性能监控
│ ├── 故障预警
│ └── 资源调度
└── 运维工具
├── 自动部署
├── 日志分析
└── 远程维护
- 刻意视角
极端思维探索:
├── 极限性能
│ ├── 超高速处理
│ │ ├── 毫秒级响应
│ │ ├── 实时流处理
│ │ └── 并行加速
│ └── 极致精度
│ ├── 亚像素配准
│ ├── 零误差转换
│ └── 完美还原
└── 极限应用
├── 极端场景
│ ├── 超低分辨率
│ ├── 严重畸变
│ └── 噪声干扰
└── 极限扩展
├── 全模态支持
├── 跨维度处理
└── 无限扩展

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 21
21 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)