Spark中reduceByKey 和 groupByKey 的区别 [超级详细]
Spark中reduceByKey 和 groupByKey 的区别 [超级详细]
文章目录
前言
用scala语言讲解Spark
一、先看结论
1、从Shuffle的角度
reduceByKey 和 groupByKey都存在shuffle操作,但是reduceByKey可以在shuffle之前对分区内相同key的数据集进行预聚合(combine),这样会减少落盘的数据量,而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能比较高。
2、从功能的角度
reduceByKey其实包含分组和聚合的功能;groupByKey只能分组,不能聚合,所以在分组聚合的场合下,推荐使用reduceByKey,如果仅仅是分组而不需要聚合,那么还是只能使用groupByKey。
二、 举例、画图说明
1、实现的功能分别是什么?
为方便理解,分别用两个算子来实现WordCount程序。假设单词已经被处理成(word,1)的形式,我用List((“a”, 1), (“a”, 1), (“a”, 1), (“b”, 1))作为数据源。
1).groupByKey 实现 WordCount
- 功能:groupByKey可以将数据源的数据根据 key 对 value 进行分组
首先来看下,单单使用groupByKey,其返回值是什么
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// 获取 RDD
val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1), ("b", 1)))
val reduceRDD = rdd.groupByKey()
reduceRDD.collect().foreach(println)
sc.stop()
/**
* 运行结果:
* (a,CompactBuffer(1, 1, 1))
* (b,CompactBuffer(1))
*/
}
可以看到,返回的结果是RDD[(String, Iterable[Int])],也就是(a,(1,1,1)),(b,(1,1,1))。
若要实现WordCount,还需要一步Map操作:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// 获取 RDD
val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1), ("b", 1)))
val reduceRDD = rdd.groupByKey().map {
case (word, iter) => {
(word, iter.size)
}
}
reduceRDD.collect().foreach(println)
sc.stop()
/**
* 运行结果:
* (a,3)
* (b,1)
*/
}
2).reduceByKey 实现 WordCount
功能:reduceByKey可以将数据按照相同的 Key 对 Value 进行两两聚合,这个聚合的方式是需要指定的。
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// 获取 RDD
val rdd = sc.makeRDD(List(("a", 1), ("a", 1), ("a", 1), ("b", 1)))
// 指定计算公式为 x+y
val reduceRDD = rdd.reduceByKey((x,y) => x + y)
reduceRDD.collect().foreach(println)
sc.stop()
/**
* 运行结果:
* (a,3)
* (b,1)
*/
}
2、画图解析两种实现方式的区别
为方便演示Shuffle过程,现在假设有两个分区的数据。
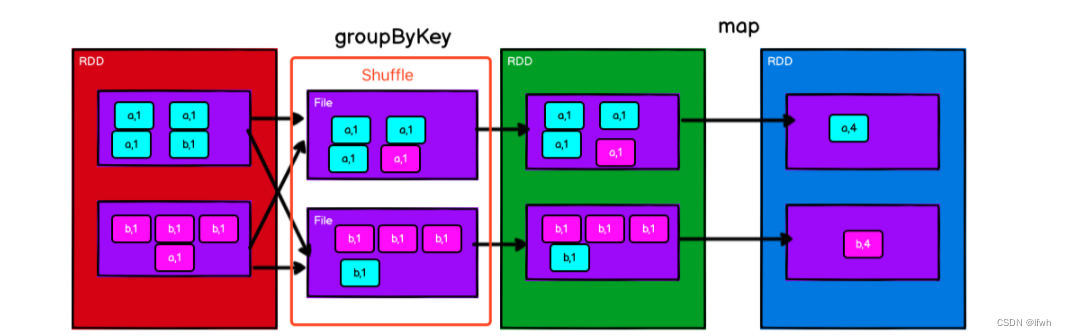
1) groupByKey 实现 WordCount

解读:
1.红色RDD是数据源,包含两个分区的(word,1)数据
2.Shuffle过程(都知道Shuffle过程是需要磁盘IO的)
3.groupByKey后的RDD,根据key分组对Value进行聚合
4.Map操作计算WordCount
2).reduceByKey 实现 WordCount(简单流程)

解读:
1.红色RDD是数据源,包含两个分区的(word,1)数据
2.Shuffle过程
3.根据指定的聚合公式,对Value进行两两聚合后的结果RDD
到这来看,感觉 groupbykey 和 reduceByKey 实现WordCount的计算方式来看感觉差不多嘛,从性能上来说,都有Shuffle操作,所以从计算性能上来说没多大区别;从功能上来说,都有分组,只是reduceByKey有聚合操作,而groupbykey没有聚合操作,它的聚合是通过增加map操作来实现的,所以看似也没多大区别。
那么究竟他两的核心区别是什么呢?
3).reduceByKey 实现 WordCount(终极流程)
再来一遍reduceByKey的功能介绍:可以将数据按照相同的 Key 对 Value 进行两两聚合。
思考一个问题:从 2) 的图中有没有发现一个现象,在红色RDD的一个分区中就有相同的Key,而且value是可以聚合的。在 groupbykey 实现过程中,由于groupbykey没有聚合功能,实现聚合计算是将所有数据分组完成后再进行聚合。而 reduceByKey 是有聚合功能的,实现过程中,在分组前也同样满足聚合条件(有相同的key,value能聚合),那么reduceByKey是不是在分组前就将数据先进行聚合了呢?(答案是肯定的,我们叫预聚合操作)
所以,它的流程图就变成这样:

解读:
1.红色RDD是数据源,包含两个分区的(word,1)数据,在分组前先对分区内的数据进行预聚合
2.Shuffle操作
3.根据指定的聚合公式,对Value进行两两聚合后的结果RDD
有哪些变化呢?
1.分组前对数据进行了预聚合,参与分组的数据量变小,也即参与Shuffle的数据量变小
2.因为参与Shuffle的数据量变小,所以Shuffle时的磁盘IO次数将变少
3.聚合计算时量量计算的次数变少
由此可以得出一个结论:
reduceByKey支持分区内预聚合功能,可以有效减少Shuffle时落盘的数据量,提升Shuffle的性能。
总结
如果此篇文章有帮助到您, 希望打大佬们能
关注、点赞、收藏、评论支持一波,非常感谢大家!
如果有不对的地方请指正!!!

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)