图机器学习——5.10 图神经网络:预测任务
首先回顾一下整个GNN的结构,前面我们所介绍的都是红色框内所解决的任务。最终得到的节点嵌入结果,是一个关于每个在LLL层节点嵌入的集合:{hv(L),∀v∈G}\left\{\mathbf{h}_{v}^{(L)}, \forall v \in G\right\}{hv(L),∀v∈G}下面来我们来介绍图网络里,蓝色框中的预测任务(prediction head),其中包括:节点水平、边水平、图
首先回顾一下整个GNN的结构,前面我们所介绍的都是红色框内所解决的任务。

最终得到的节点嵌入结果,是一个关于每个在 L L L层节点嵌入的集合:
{ h v ( L ) , ∀ v ∈ G } \left\{\mathbf{h}_{v}^{(L)}, \forall v \in G\right\} {hv(L),∀v∈G}
下面来我们来介绍图网络里,蓝色框中的预测任务(prediction head),其中包括:节点水平、边水平、图水平的三种预测:

① 节点水平预测
节点水平的预测我们可以直接采用最终的嵌入结果。也可以再进行一个线性变换最终得到所需要的结果。这里假设在经过 GNN 的计算后,我们可以得到一个 d d d 维的嵌入向量: { h v ( L ) ∈ R d , ∀ v ∈ G } \left\{\mathbf{h}_{v}^{(L)} \in \mathbb{R}^{d}, \forall v \in G\right\} {hv(L)∈Rd,∀v∈G}。
假设我们需要的实际结果是 k k k 个目标的(可以为 k k k 维的分类问题;或者是 k k k 个目标的回归问题),那么最终的预测结果如下:
y ^ v = Head node ( h v ( L ) ) = W ( H ) h v ( L ) \widehat{y}_{v}=\operatorname{Head}_{\text {node }}\left(\mathbf{h}_{v}^{(L)}\right)=\mathbf{W}^{(H)} \mathbf{h}_{v}^{(L)} y v=Headnode (hv(L))=W(H)hv(L)
其中 W ( H ) ∈ R k ∗ d \mathbf{W}^{(H)} \in \mathbb{R}^{k * d} W(H)∈Rk∗d,为权重矩阵。
② 边水平预测
假设边水平的预测也同样需要输出 k k k个预测结果,需要预测 u , v u, v u,v两个节点之间的边嵌入结果。

预测公式如下:
y ^ u v = Head edge ( h u ( L ) , h v ( L ) ) \widehat{\boldsymbol{y}}_{u v}=\operatorname{Head}_{\text {edge }}\left(\mathbf{h}_{u}^{(L)}, \mathbf{h}_{v}^{(L)}\right) y uv=Headedge (hu(L),hv(L))
- 方式一:拼接+线性变换
这种方式之前在 attention 机制中出现过:
具体操作方式是先拼接,再进行线性变换。
y ^ u v = Linear ( Concat ( h u ( L ) , h v ( L ) ) ) \widehat{\boldsymbol{y}}_{u v}=\operatorname{Linear}\left(\operatorname{Concat}\left(\mathbf{h}_{u}^{(L)}, \mathbf{h}_{v}^{(L)}\right)\right) y uv=Linear(Concat(hu(L),hv(L)))
- 方式二:内积
要求输出的边嵌入为一维时,可以直接通过如下内积方式得到:
y ^ u v = ( h u ( L ) ) T h v ( L ) \widehat{y}_{u v}=\left(\mathbf{h}_{u}^{(L)}\right)^{T} \mathbf{h}_{v}^{(L)} y uv=(hu(L))Thv(L)
要求为 k k k维时,参考多头注意力机制,构建一系列可训练的权重矩阵: W ( 1 ) , … , W ( k ) \mathbf{W}^{(1)}, \ldots, \mathbf{W}^{(k)} W(1),…,W(k)。具体 k k k个维度的构造如下:
y ^ u v ( 1 ) = ( h u ( L ) ) T W ( 1 ) h v ( L ) y ^ u v ( k ) = ( h u ( L ) ) T W ( k ) h v ( L ) y ^ u v = Concat ( y ^ u v ( 1 ) , … , y ^ u v ( k ) ) ∈ R k \begin{gathered} \widehat{y}_{u v}^{(1)}=\left(\mathbf{h}_{u}^{(L)}\right)^{T} \mathbf{W}^{(1)} \mathbf{h}_{v}^{(L)} \\ \widehat{y}_{u v}^{(k)}=\left(\mathbf{h}_{u}^{(L)}\right)^{T} \mathbf{W}^{(k)} \mathbf{h}_{v}^{(L)} \\ \widehat{\boldsymbol{y}}_{u v}=\operatorname{Concat}\left(\widehat{y}_{u v}^{(1)}, \ldots, \widehat{y}_{u v}^{(k)}\right) \in \mathbb{R}^{k} \end{gathered} y uv(1)=(hu(L))TW(1)hv(L)y uv(k)=(hu(L))TW(k)hv(L)y uv=Concat(y uv(1),…,y uv(k))∈Rk
③ 图水平预测
图水平的预测其实非常类似GNN中的聚合操作:

y ^ G = AGG ( { h v ( L ) ∈ R d , ∀ v ∈ G } ) \widehat{\boldsymbol{y}}_{G} = \operatorname{AGG}\left( \left\{\mathbf{h}_{v}^{(L)} \in \mathbb{R}^{d}, \forall v \in G\right\}\right) y G=AGG({hv(L)∈Rd,∀v∈G})
其中的 AGG \operatorname{AGG} AGG 可以为 Mean , Max , Sum \operatorname{Mean}, \operatorname{Max}, \operatorname{Sum} Mean,Max,Sum 等。
但这样的嵌入可能会损失一些信息,特别是针对一些比较大的图结构时。例如两个完全不同的图,节点嵌入分别为:
G
1
:
{
−
1
,
−
2
,
0
,
1
,
2
}
G_{1}:\{-1,-2,0,1,2\}
G1:{−1,−2,0,1,2}
G
2
:
{
−
10
,
−
20
,
0
,
10
,
20
}
G_{2}:\{-10,-20,0,10,20\}
G2:{−10,−20,0,10,20}
如果聚合函数选择为
Sum
\operatorname{Sum}
Sum时,图嵌入为:
G
1
:
y
^
G
=
Sum
(
{
−
1
,
−
2
,
0
,
1
,
2
}
)
=
0
G_{1}: \hat{y}_{G}=\operatorname{Sum}(\{-1,-2,0,1,2\})=0
G1:y^G=Sum({−1,−2,0,1,2})=0
G
2
:
y
^
G
=
Sum
(
{
−
10
,
−
20
,
0
,
10
,
20
}
)
=
0
G_{2}: \hat{y}_{G}=\operatorname{Sum}(\{-10,-20,0,10,20\})=0
G2:y^G=Sum({−10,−20,0,10,20})=0
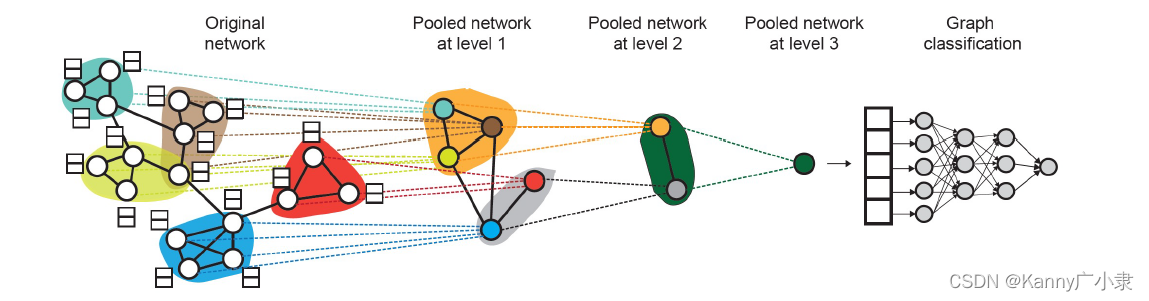
两者结果完全一致。因此我们考虑一种层级全局池化方法(hierarchical global pooling),进行聚合操作,得到最终的图嵌入。
我们的GNN网络分别用于两种操作,第一种就是前面介绍的节点嵌入。第二种就是构建一个聚类网络,对原始网络中的每个节点进行聚类,而后在根据层级聚类结果进行一层一层的池化聚合操作,最终得到我们需要的整个图的嵌入结果。整个流程如下:

以前面的方法举例,假设我们根据 G 1 , G 2 G_{1}, G_{2} G1,G2 由五个节点组成的图最终被聚成了两类(前两个节点一类,后两个节点一类),那么我们逐层进行聚合:
-
G 1 G_{1} G1 的节点嵌入: { − 1 , − 2 , 0 , 1 , 2 } \{-1,-2,0,1,2\} {−1,−2,0,1,2}
第一轮: y ^ a = ReLU ( Sum ( { − 1 , − 2 } ) ) = 0 , y ^ b = ReLU ( Sum ( { 0 , 1 , 2 } ) ) = 3 第二轮: y ^ G = ReLU ( Sum ( { y a , y b } ) ) = 3 \begin{aligned} &\text { 第一轮:} \hat{y}_{a}=\operatorname{ReLU}(\operatorname{Sum}(\{-1,-2\}))=0, \quad \hat{y}_{b}= \operatorname{ReLU}(\operatorname{Sum}(\{0,1,2\}))=3 \\ &\text { 第二轮:} \hat{y}_{G}=\operatorname{ReLU}\left(\operatorname{Sum}\left(\left\{y_{a}, y_{b}\right\}\right)\right)=3 \end{aligned} 第一轮:y^a=ReLU(Sum({−1,−2}))=0,y^b=ReLU(Sum({0,1,2}))=3 第二轮:y^G=ReLU(Sum({ya,yb}))=3 -
G 2 G_{2} G2 的节点嵌入: { − 10 , − 20 , 0 , 10 , 20 } \{-10,-20,0,10,20\} {−10,−20,0,10,20}
第一轮: y ^ a = ReLU ( Sum ( { − 10 , − 20 } ) ) = 0 , y ^ b = ReLU ( Sum ( { 0 , 10 , 20 } ) ) = 30 第二轮: y ^ G = ReLU ( Sum ( { y a , y b } ) ) = 30 \begin{aligned} &\text { 第一轮:} \hat{y}_{a}=\operatorname{ReLU}(\operatorname{Sum}(\{-10,-20\}))=0, \quad \hat{y}_{b}= \operatorname{ReLU}(\operatorname{Sum}(\{0,10,20\}))=30 \\ &\text { 第二轮:} \hat{y}_{G}=\operatorname{ReLU}\left(\operatorname{Sum}\left(\left\{y_{a}, y_{b}\right\}\right)\right)=30 \end{aligned} 第一轮:y^a=ReLU(Sum({−10,−20}))=0,y^b=ReLU(Sum({0,10,20}))=30 第二轮:y^G=ReLU(Sum({ya,yb}))=30
两个图会得到不一样的结果,因此这种方式是能够有效区分这种情形。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)