论文阅读:SimVP: Simpler yet Better Video Prediction
作者认为,现有的CNN,RNN,Transformer 之类的视频预测领域的模型都过于复杂了,作者想要找到一个简单的方式,同时可以达到与之相当的效果。作者提出了 SimVP,这是一个简单的视频预测模型,完全基于 CNN 构建,通过均方误差(MSE)损失函数以端到端的方式进行训练。在不引入任何额外技巧与复杂策略的情况下,就可以实现最先进的性能。
论文地址:arxiv
摘要
作者认为,现有的CNN,RNN,Transformer 之类的视频预测领域的模型都过于复杂了,作者想要找到一个简单的方式,同时可以达到与之相当的效果。
作者提出了 SimVP,这是一个简单的视频预测模型,完全基于 CNN 构建,通过均方误差(MSE)损失函数以端到端的方式进行训练。在不引入任何额外技巧与复杂策略的情况下,就可以实现最先进的性能。
正文
深度视频预测模型当前主要有 4 类,如图所示:

分别是:
- RNN-RNN-RNN
- CNN-RNN-CNN
- CNN-ViT-CNN
- CNN-CNN-CNN
在纯 CNN 基础模型方面,要提高准确度,通常要使用各种技术,但是作者探索出了一个简单模型的新高度。
问题描述
给定一个在时间 t t t 的包含过去 T T T 帧的视频序列 X t , T = { x i } t − T + 1 t X_{t,T}=\{x_{i}\}^t_{t-T+1} Xt,T={xi}t−T+1t,而目标是在时间 t t t 预测未来的序列 Y t , T ′ = { x i } t t + T ′ Y_{t,T'} = \{x_{i}\}^{t+T'}_t Yt,T′={xi}tt+T′。该序列包含接下来的 T ′ T' T′ 帧,其中 x i x_{i} xi 是一个具有通道数 C C C,高度 H H H 和宽度 W W W 的图像。形式上,预测模型是一个映射 F Θ : X t , T − > Y t , T ′ F_\Theta:X_{t,T}->Y_{t,T'} FΘ:Xt,T−>Yt,T′,其中的可学习参数 Θ \Theta Θ 通过以下公式优化:
Θ
∗
=
arg
min
Θ
L
(
F
Θ
(
X
t
,
T
)
,
Y
t
,
T
′
)
\Theta ^* = \arg \min _{\Theta } \mathcal {L}(\mathcal {F}_{\Theta }(\boldsymbol {X}_{t, T}), \boldsymbol {Y}_{t, T'})
Θ∗=argΘminL(FΘ(Xt,T),Yt,T′)
L
L
L 可以是各种损失函数。
模型架构

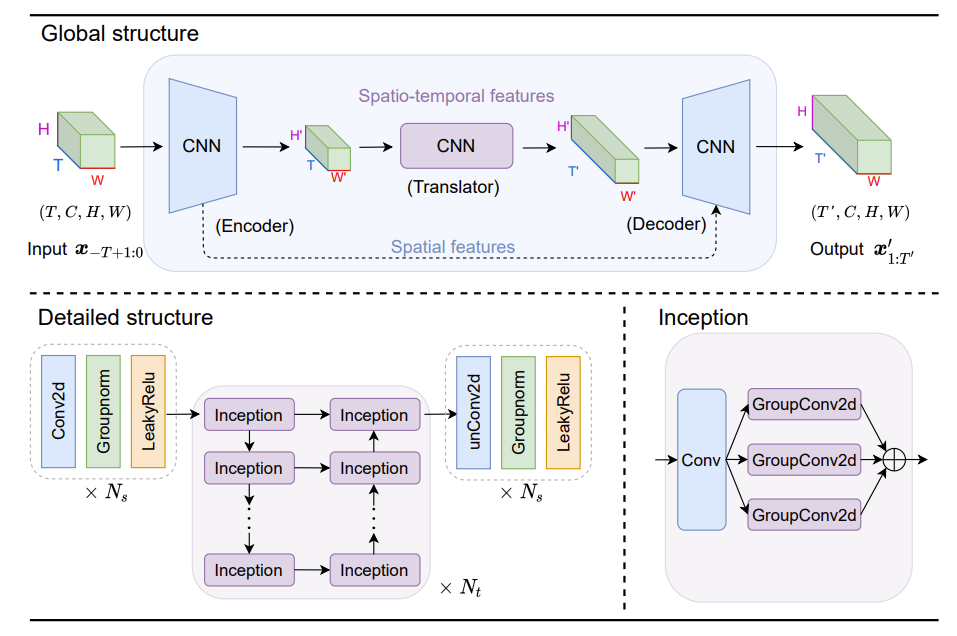
SimVP 由一个编码器,一个翻译器,一个解码器组成。
- 编码器用于提取空间特征
- 翻译器学习时间演变
- 解码器则整合时间信息以预测未来帧
编码器
编码器堆叠了 N s N_s Ns 个 ConvNormReLU 块(Conv2d+LayerNorm+LeakyReLU)来提取空间特征,即在 (H,W)上进行 C 通道的卷积。隐藏特征表示为:
z i = σ ( L a y e r N o r m ( C o n v 2 d ( z i − 1 ) ) ) , 1 ≤ i ≤ N s z_{i} = \sigma (\mathrm {LayerNorm} (\mathrm {Conv2d}(z_{i-1}))), 1 \leq i \leq N_s zi=σ(LayerNorm(Conv2d(zi−1))),1≤i≤Ns
其中输入 z i − 1 z_{i-1} zi−1 和输出 z i z_i zi 的形状分别为 ( T , C , H , W ) (T, C, H, W) (T,C,H,W) 和 ( T , C , H ^ , W ^ ) (T, C, \hat{H}, \hat{W}) (T,C,H^,W^)。
翻译器
翻译器使用 N t N_t Nt 个 Inception 模块来学习时间演变,即在 ( H , W ) (H, W) (H,W) 上进行 T ∗ C T*C T∗C 通道的卷积。
Inception 模块由一个 1*1 大小的 Conv2d 后接并行的 GroupConv2d 操作符完成。隐藏特征表示为:
z
j
=
I
n
c
e
p
t
i
o
n
(
z
j
−
1
)
,
N
s
<
j
≤
N
s
+
N
t
z_{j} = \mathrm {Inception}( z_{j-1} ), N_s < j \leq N_s+N_t
zj=Inception(zj−1),Ns<j≤Ns+Nt
其中输入
z
j
−
1
z_{j-1}
zj−1 和输出
z
j
z_j
zj 的形状分别为
(
T
∗
C
,
H
,
W
)
(T*C, H, W)
(T∗C,H,W) 和
(
T
^
∗
C
^
,
H
,
W
)
(\hat{T}*\hat{C}, H, W)
(T^∗C^,H,W)。
解码器
解码器使用
N
s
N_s
Ns 个 unConvNormReLU 块(ConvTranspose2d+GroupNorm+LeakyReLU)来重建真实帧,在(H, W)上进行 C 通道的卷积。隐藏特征表示为
z k = σ ( G r o u p N o r m ( u n C o n v 2 d ( z k − 1 ) ) ) , N s + N t < k ≤ 2 N s + N t z_{k} = \sigma (\mathrm {GroupNorm} (\mathrm {unConv2d}(z_{k-1}))),\\ N_s+N_t < k \leq 2N_s + N_t zk=σ(GroupNorm(unConv2d(zk−1))),Ns+Nt<k≤2Ns+Nt
其中,输入
z
k
−
1
z_{k-1}
zk−1 与输出
z
k
z_k
zk 的形状分别为
(
T
,
C
^
,
H
^
,
W
^
)
(T,\hat{C},\hat{H}, \hat{W})
(T,C^,H^,W^) 与
(
T
,
C
,
H
,
W
)
(T,C,H,W)
(T,C,H,W)。使用 ConvTransposed2d 作为 unConv2d 操作符。
模型评估
使用均方误差(MSE)、平均绝对误差(MAE)、结构相似性指数(SSIM)和峰值信噪比(PSNR)来评估预测质量。
在五个数据集上进行实验,从而来进行评估,如下所示:

性能评估

可以看到,SimVP、PhyDNet和CrevNet显著优于先前的方法,MSE降低达到42%。然而,SimVP比PhyDNet和CrevNet简单得多,没有使用RNN、LSTM或复杂模块。
训练时间

由上可知,SimVP 的训练过程比其他方法快得多,所以 SimVP 可以更容易地使用与扩展。
翻译器的使用
使用 RNN 和 Transformer 替换了 CNN ,再进行测试。使用了不同模型中的翻译器来,测试后得到以下结果:


可以得出结论:
- CNN和RNN在有限的计算成本下实现了最先进的性能。
- 如果模型容量足够,RNN在长期内收敛速度更快。
- CNN训练更稳健,在大学习率下不会剧烈波动。
- 在类似的资源消耗下,Transformer在我们的SimVP框架中没有优势。
评判能否到 SOTA 水平

SimVP可以在轻量级其次上达到 SOTA 结果。此外,与 PhyDNet 相比,SimVP 的训练时间更短。

可以看到在不同的数据集上有良好的泛化能力。

可以看到,SimVP 在灵活预测长度的情况下扩展良好。SimVP 达到了最新的性能。
消融实验
哪个架构的设计对于性能有关键的作用?

由上图 1-4 可知:空间UNet、时间UNet、分组卷积和分组归一化都能带来性能提升,其重要性排序为:分组卷积 > 分组归一化 ≈ 空间UNet ≈ 时间UNet。
卷积核对性能的影响
由上图 5-8 可知,随着核大小的增加,可以看到显著的性能提升。通过将模型 8 的隐藏维度加倍构建于模型 9,这种提高可以进一步增强。
编码器,转换器,解码器的角色

- 转换器主要关注预测物体的位置和内容。
- 解码器负责优化前景物体的形状。
- 编码器可以通过空间UNet连接消除背景误差。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)