MetalLB:本地Kubernetes集群的LoadBalancer负载均衡利器
大多数的官方教程为了简化部署的步骤,都是写着直接用kubectl命令部署一个yaml的url,这样子的好处是部署简单快捷,但是坏处就是本地自己没有存档,不方便修改等操作,因此我个人更倾向于把yaml文件下载到本地保存再进行部署。但如果是计划外的事故导致的,此时在有故障的客户端刷新其缓存条目之前,将无法访问服务IP。由于Layer 2 模式会使用单个选举出来的Leader来接收服务IP的所有流量,这
背景
在本地集群进行测试时,我们常常面临一个棘手的问题:Service Type不支持LoadBalancer,而我们只能选择使用NodePort作为替代。这种情况下,我们通常会配置Service为NodePort,并使用externalIPs将流量导入Kubernetes环境。然而,这些解决方案都存在明显的缺陷,使得在私有环境部署Kubernetes的用户在这个生态中感觉自己像是二等公民。
值得注意的是,Kubernetes默认并未提供负载均衡器的实现。在Kubernetes生态中,网络负载均衡器的实现通常依赖于各种IaaS平台,如Google Cloud Platform (GCP)、Amazon Web Services (AWS)、Azure等。因此,如果你不在这些IaaS平台上运行Kubernetes,你创建的Service中的type: LoadBalancers将一直处于Pending状态,如下所示:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx LoadBalancer 10.93.15.64 <pending> 8080:31322/TCP,443:31105/TCP 1h
这种情况下,我们急需一个解决方案,一个可以在本地环境中实现负载均衡的解决方案。这就是我们今天要介绍的主角——MetalLB。
Metallb 通过标准路由协议能解决该问题。MetalLB 也是 CNCF 的沙箱项目,最早发布在 https://github.com/google/metallb 开发,后来迁移到 https://github.com/metallb/metallb 中。
原理
Metallb 会在 Kubernetes 内运行,监控服务对象的变化,一旦察觉有新的LoadBalancer 服务运行,并且没有可申请的负载均衡器之后,
MetalLB 通过 MetalLB hooks 为 Kubernetes 中提供网络负载均衡器的实现。简单的说,它允许你在非云供应商提供的(私有的) Kubernetes 中创建 type: LoadBalancer 的 services。
MetalLB 有两大功能:
- 地址分配:在 IaaS 平台申请 LB,会自动分配一个公网 IP,因此,MetalLB也需要管理 IP 地址的分配工作
- IP 外部声明:当 MetalLB 获取外部地址后,需要对外声明该 IP 在 k8s 中使用,并可以正常通信。
IP 声明可以使用 ARP、 NDP、或 BGP 协议,因此 MetalLB 有两种工作模式:
- BGP 工作模式,使用 BGP 协议分配地址池
- L2 工作模式,使用 ARP/NDP 协议分配地址池
Layer2模式
在2层模式下,Metallb会在Node节点中选出一台作为Leader,与服务IP相关的所有流量都会流向该节点。在该节点上, kube-proxy将接收到的流量传播到对应服务的Pod。当leader节点出现故障时,会由另一个节点接管。从这个角度来看,2层模式更像是高可用,而不是负载均衡,因为同时只能在一个节点负责接收数据。
在二层模式中会存在以下两种局限性:单节点瓶颈和故障转移慢的情况。
由于Layer 2 模式会使用单个选举出来的Leader来接收服务IP的所有流量,这就意味着服务的入口带宽被限制为单个节点的带宽,单节点的流量处理能力将成为整个集群的接收外部流量的瓶颈。
在故障转移方面,目前的机制是MetalLB通过发送2层数据包来通知各个节点,并重新选举Leader,这通常能在几秒内完成。但如果是计划外的事故导致的,此时在有故障的客户端刷新其缓存条目之前,将无法访问服务IP。
BGP模式
BGP模式是真正的负载均衡,该模式需要路由器支持BGP协议 ,群集中的每个节点会与网络路由器建议基于BGP的对等会话,并使用该会话来通告负载均衡的IP。MetalLB发布的路由彼此等效,这意味着路由器将使用所有的目标节点,并在它们之间进行负载平衡。数据包到达节点后,kube-proxy负责流量路由的最后一跳,将数据包发送到对应服务的Pod。
负载平衡的方式取决于您特定的路由器型号和配置,常见的有基于数据包哈希对每个连接进行均衡,这意味着单个TCP或UDP会话的所有数据包都将定向到群集中的单个计算机。
BGP模式也存在着自身的局限性,该模式通过对数据包头中的某些字段进行哈希处理,并将该哈希值用作后端数组的索引,将给定的数据包分配给特定的下一跳。但路由器中使用的哈希通常不稳定,因此只要后端节点数量发生变化时,现有连接就会被随机地重新哈希,这意味着大多数现有连接将被转发到另一后端,而该后端并不清楚原有的连接状态。为了减少这种麻烦,建议使用更加稳定的BGP算法,如:ECMP散列算法。
系统要求
在开始部署MetalLB之前,我们需要确定部署环境能够满足最低要求:
- 一个k8s集群,要求版本不低于1.13.0,且没有负载均衡器相关插件
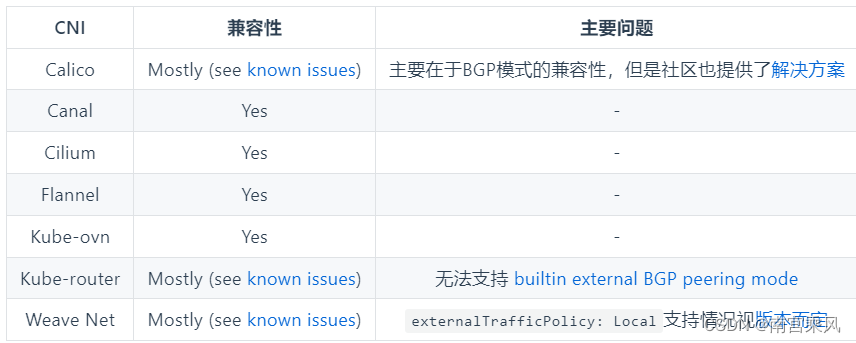
- k8s集群上的CNI组件和MetalLB兼容
- 预留一段IPv4地址给MetalLB作为LoadBalance的VIP使用
- 如果使用的是MetalLB的BGP模式,还需要路由器支持BGP协议
- 如果使用的是MetalLB的Layer2模式,因为使用了memberlist算法来实现选主,因此需要确保各个k8s节点之间的7946端口可达(包括TCP和UDP协议),当然也可以根据自己的需求配置为其他端口

安装要求
准备
(根据情况而定)
如果你在 IPVS 模式下使用 kube-proxy,从 Kubernetes v1.14.2 开始,必须启用严格 ARP 模式。
注意,如果使用 kube-router 作为 service-proxy,则不需要这样做,因为它默认启用严格 ARP。
部署Layer2模式需要把k8s集群中的ipvs配置打开strictARP,开启之后k8s集群中的kube-proxy会停止响应kube-ipvs0网卡之外的其他网卡的arp请求,而由MetalLB接手处理。
strict ARP开启之后相当于把 将 arp_ignore 设置为 1 并将 arp_announce 设置为 2 启用严格的 ARP,这个原理和LVS中的DR模式对RS的配置一样,可以参考之前的文章中的解释。
可以通过编辑当前集群的 kube-proxy 配置来实现:
# 查看kube-proxy中的strictARP配置
$ kubectl get configmap -n kube-system kube-proxy -o yaml | grep strictARP
strictARP: false
# 手动修改strictARP配置为true
$ kubectl edit configmap -n kube-system kube-proxy
configmap/kube-proxy edited
# 使用命令直接修改并对比不同
$ kubectl get configmap kube-proxy -n kube-system -o yaml | sed -e "s/strictARP: false/strictARP: true/" | kubectl diff -f - -n kube-system
# 确认无误后使用命令直接修改并生效
$ kubectl get configmap kube-proxy -n kube-system -o yaml | sed -e "s/strictARP: false/strictARP: true/" | kubectl apply -f - -n kube-system
# 重启kube-proxy确保配置生效
$ kubectl rollout restart ds kube-proxy -n kube-system
# 确认配置生效
$ kubectl get configmap -n kube-system kube-proxy -o yaml | grep strictARP
strictARP: true
部署MetalLB(Layer2模式)
MetalLB的部署也十分简单,官方提供了manifest文件部署(yaml部署),helm3部署和Kustomize部署三种方式,这里我们还是使用manifest文件部署。
大多数的官方教程为了简化部署的步骤,都是写着直接用kubectl命令部署一个yaml的url,这样子的好处是部署简单快捷,但是坏处就是本地自己没有存档,不方便修改等操作,因此我个人更倾向于把yaml文件下载到本地保存再进行部署
# 下载v0.12.1的两个部署文件
$ wget https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/namespace.yaml
$ wget https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb.yaml
# 如果使用frr来进行BGP路由管理,则下载这两个部署文件
$ wget https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/namespace.yaml
$ wget https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb-frr.yaml
下载官方提供的yaml文件之后,我们再提前准备好configmap的配置,github上面有提供一个参考文件,layer2模式需要的配置并不多,这里我们只做最基础的一些参数配置定义即可:
protocol这一项我们配置为layer2
addresses这里我们可以使用CIDR来批量配置(198.51.100.0/24),也可以指定首尾IP来配置(192.168.0.150-192.168.0.200),指定一段和k8s节点在同一个子网的IP。也可以指定宿主机的网络分配。
# config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.102.50-192.168.102.60
还可以指定多个网段
addresses:
- 192.168.12.0/24
- 192.168.144.0/20
除了自动分配IP外,Metallb 还支持在定义服务的时候,通过 spec.loadBalancerIP 指定一个静态IP 。
使用kubectl log -f [matellb-contoller-pod]能看到配置更新过程
接下来就可以开始进行部署,整体可以分为三步:
- 部署namespace
- 部署deployment和daemonset
- 配置configmap
# 创建namespace
$ kubectl apply -f namespace.yaml
namespace/metallb-system created
$ kubectl get ns
NAME STATUS AGE
default Active 8d
kube-node-lease Active 8d
kube-public Active 8d
kube-system Active 8d
metallb-system Active 8s
nginx-quic Active 8d
# 部署deployment和daemonset,以及相关所需的其他资源
$ kubectl apply -f metallb.yaml
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/controller created
podsecuritypolicy.policy/speaker created
serviceaccount/controller created
serviceaccount/speaker created
clusterrole.rbac.authorization.k8s.io/metallb-system:controller created
clusterrole.rbac.authorization.k8s.io/metallb-system:speaker created
role.rbac.authorization.k8s.io/config-watcher created
role.rbac.authorization.k8s.io/pod-lister created
role.rbac.authorization.k8s.io/controller created
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:controller created
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:speaker created
rolebinding.rbac.authorization.k8s.io/config-watcher created
rolebinding.rbac.authorization.k8s.io/pod-lister created
rolebinding.rbac.authorization.k8s.io/controller created
daemonset.apps/speaker created
deployment.apps/controller created
# 这里主要就是部署了controller这个deployment来检查service的状态
$ kubectl get deploy -n metallb-system
NAME READY UP-TO-DATE AVAILABLE AGE
controller 1/1 1 1 86s
# speaker则是使用ds部署到每个节点上面用来协商VIP、收发ARP、NDP等数据包
$ kubectl get ds -n metallb-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
speaker 3 3 3 3 3 kubernetes.io/os=linux 64s
$ kubectl get pod -n metallb-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
controller-55bbcf48c8-qst68 1/1 Running 0 2d19h 172.20.28.118 node02 <none> <none>
speaker-8wctf 1/1 Running 0 2d19h 192.168.102.41 node02 <none> <none>
speaker-txdsv 1/1 Running 0 2d19h 192.168.102.30 master01 <none> <none>
speaker-xdzrr 1/1 Running 0 2d19h 192.168.102.40 node01 <none> <none>
$ kubectl apply -f configmap-layer2.yaml
configmap/config created
kubectl wait --for=condition=Ready pods --all -n metallb-system
# pod/controller-57fd9c5bb-d5z9j condition met
# pod/speaker-6hz2h condition met
# pod/speaker-7pzb4 condition met
# pod/speaker-trr9v condition met
部署测试服务
# mentallb/whoami.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: whoami
labels:
app: containous
name: whoami
spec:
replicas: 2
selector:
matchLabels:
app: containous
task: whoami
template:
metadata:
labels:
app: containous
task: whoami
spec:
containers:
- name: containouswhoami
image: containous/whoami
resources:
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: whoami
spec:
ports:
- name: http
port: 80
selector:
app: containous
task: whoami
type: LoadBalancer
或者 nginx
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.23-alpine
ports:
- name: http
containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
#loadBalancerIP: x.y.z.a # 指定公网IP
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx
type: LoadBalancer


可见分配的 EXTERNAL-IP 为 192.168.102.52
分别在虚拟机和宿主机试试:
curl 192.168.102.52
[root@bt metallb]# curl 192.168.102.52
Hostname: whoami-665585b57c-kngqc
IP: 127.0.0.1
IP: 172.20.28.123
RemoteAddr: 127.0.0.6:47635
GET / HTTP/1.1
Host: 192.168.102.52
User-Agent: curl/7.29.0
Accept: */*
X-B3-Sampled: 1
X-B3-Spanid: 0268f13fd66b2858
X-B3-Traceid: c6984aca633971850268f13fd66b2858
X-Forwarded-Proto: http
X-Request-Id: 6664e21c-b2d4-9abe-af63-6d79485cbdd8
这时如果你 ping 这个 ip 的话,会发现无法 ping 通
这个是正常的,因为它是一个虚拟IP地址,所以根本无法ping 通(此虚拟IP与物理网卡共用同一个 MAC 地址,那么这个IP是如何工作的呢?又是如何收到流量请求的呢?很值得思考)。
那如何测试这个虚拟IP是否能正常提供服务呢,其实只需要使用 telnet 命令就可以了,如
[root@bt metallb]# telnet 192.168.102.52 80
Trying 192.168.102.52...
Connected to 192.168.102.52.
Escape character is '^]'.
注意:
注意:并非所有的LoadBalancer都允许设置 loadBalancerIP。
如果LoadBalancer支持该字段,那么将根据用户设置的 loadBalancerIP 来创建负载均衡器。
如果没有设置 loadBalancerIP 字段,将会给负载均衡器指派一个临时 IP。
如果设置了 loadBalancerIP,但LoadBalancer并不支持这种特性,那么设置的 loadBalancerIP 值将会被忽略掉。
我们在创建LoadBalancer服务的时候,默认情况下k8s会帮我们自动创建一个nodeport服务,这个操作可以通过指定Service中的allocateLoadBalancerNodePorts字段来定义开关,默认情况下为true
不同的loadbalancer实现原理不同,有些是需要依赖nodeport来进行流量转发,有些则是直接转发请求到pod中。对于MetalLB而言,是通过kube-proxy将请求的流量直接转发到pod,因此我们需要关闭nodeport的话可以修改service中的spec.allocateLoadBalancerNodePorts字段,将其设置为false,那么在创建svc的时候就不会分配nodeport。
但是需要注意的是如果是对已有service进行修改,关闭nodeport(从true改为false),k8s不会自动去清除已有的ipvs规则,这需要我们自行手动删除。
我们重新定义创建一个svc
apiVersion: v1
kind: Service
metadata:
name: nginx-lb-service
namespace: nginx-quic
spec:
allocateLoadBalancerNodePorts: false
externalTrafficPolicy: Cluster
internalTrafficPolicy: Cluster
selector:
app: nginx-lb
ports:
- protocol: TCP
port: 80 # match for service access port
targetPort: 80 # match for pod access port
type: LoadBalancer
loadBalancerIP: 10.31.8.100
此时再去查看对应的svc状态和ipvs规则会发现已经没有nodeport相关的配置
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.8.62.180:80 rr
-> 10.8.65.18:80 Masq 1 0 0
-> 10.8.65.19:80 Masq 1 0 0
-> 10.8.66.14:80 Masq 1 0 0
-> 10.8.66.15:80 Masq 1 0 0
TCP 10.31.8.100:80 rr
-> 10.8.65.18:80 Masq 1 0 0
-> 10.8.65.19:80 Masq 1 0 0
-> 10.8.66.14:80 Masq 1 0 0
-> 10.8.66.15:80 Masq 1 0 0
$ kubectl get svc -n nginx-quic
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-lb-service LoadBalancer 10.8.62.180 10.31.8.100 80/TCP 23s
如果是把已有服务的spec.allocateLoadBalancerNodePorts从true改为false,原有的nodeport不会自动删除,因此最好在初始化的时候就规划好相关参数
$ kubectl get svc -n nginx-quic nginx-lb-service -o yaml | egrep " allocateLoadBalancerNodePorts: "
allocateLoadBalancerNodePorts: false
$ kubectl get svc -n nginx-quic
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-lb-service LoadBalancer 10.8.62.180 10.31.8.100 80:31405/TCP 85m
参考文档:
https://tinychen.com/20220519-k8s-06-loadbalancer-metallb
https://juejin.cn/post/6906447786112516110

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)