全网最全基于ORB的原理讲解与代码实现
一、介绍假如有两张人物图片,我们的目标是要确认这两张图片中的人物是否是同一个人。如果人来判断,这太简单了。但是让计算机来完成这个功能就困难重重。一种可行的方法是:分别找出两张图片中的特征点描述这些特征点的属性,比较这两张图片的特征点的属性。如果有足够多的特征点具有相同的属性,那么就可以认为两张图片中的人物就是同一个人。ORB(Oriented FAST and Rot...
一、介绍
假如有两张人物图片,我们的目标是要确认这两张图片中的人物是否是同一个人。如果人来判断,这太简单了。但是让计算机来完成这个功能就困难重重。一种可行的方法是:
- 分别找出两张图片中的特征点
- 描述这些特征点的属性,
- 比较这两张图片的特征点的属性。如果有足够多的特征点具有相同的属性,那么就可以认为两张图片中的人物就是同一个人。
ORB(Oriented FAST and Rotated BRIEF)就是一种特征提取并描述的方法。ORB是由Ethan Rublee, Vincent Rabaud, Kurt Konolige以及Gary R.Bradski在2011年提出,论文名称为"ORB:An Efficient Alternative to SIFTor SURF",(http://www.willowgarage.com/sites/default/files/orb_final.pdf)。
ORB分两部分,即特征点提取和特征点描述。特征提取是由FAST(Features from Accelerated Segment Test)算法发展来的,特征点描述是根据BRIEF(Binary Robust Independent Elementary Features)特征描述算法改进的。ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。据说ORB算法的速度是sift的100倍,是surf的10倍。
二、Oriented FAST(oFast)特征点的提取
oFast就是在使用FAST提取特征点之后,给其定义一个该特征点的放向,并以此来实现该特征点的旋转不变形。
2.1、粗提取
图像的特征点可以简单的理解为图像中比较显著显著的点,如轮廓点,较暗区域中的亮点,较亮区域中的暗点等。
FAST的核心思想是找出那些卓尔不群的点。即拿一个点跟它周围的点比较,如果它和其中大部分的点都不一样,就人物它是一个特征点。

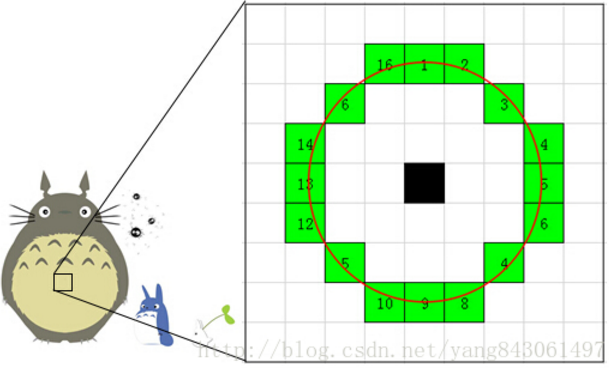
如上图,假设图像中的一点P,及其一个邻域。右半拉是放大的图,每个小方格代表一个像素,方格内的颜色只是为了便于区分,不代表该像素点的颜色。判断该点是不是特征点的方法是,以P为圆心画一个半径为3pixel的圆(周长为16pixel)。圆周上如果有连续n个像素点的灰度值比P点的灰度值大或者小(需事先设定一个阈值T),则认为P为特征点。一般n设置为12。
为了加快特征点的提取,快速排除非特征点,首先检测1、9、5、13位置上的灰度值,如果P是特征点,那么这四个位置上有3个或3个以上的的像素值都大于或者小于P点的灰度值。如果不满足,则直接排除此点。
2.2、使用ID3决策树,将特征点圆周上的16个像素输入决策树中,以此来筛选出最优的FAST特征点。
2.3、使用非极大值抑制算法去除临近位置多个特征点的。具体:为每一个特征点计算出其响应大小(特征点P和其周围16个特征点偏差的绝对值和)。在比较临近的特征点中,保留响应值较大的特征点,删除其余的特征点。
2.4、特征点的尺度不变性
建立金字塔,来实现特征点的多尺度不变性。设置一个比例因子scaleFactor(opencv默认为1.2)和金字塔的层数nlevels(pencv默认为8)。将原图像按比例因子缩小成nlevels幅图像。缩放后的图像为:I’= I/scaleFactork(k=1,2,…, nlevels)。nlevels幅不同比例的图像提取特征点总和作为这幅图像的oFAST特征点。
2.5、特征点的旋转不变形
oFast用矩(moment)法来确定FAST特征点的方向。即计算特征点以r为半径范围内的质心,特征点坐标到质心形成一个向量作为该特征点的方向。矩定义如下:

三、Rotated BRIEF(rBRIEF)特征点的描述
3.1、BRIEF算法
BRIEF算法计算出来的是一个二进制串的特征描述符。它是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)> I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。一般n取128、256或512(opencv默认为256)。
另外,为了增加特征描述符的抗噪性,算法需要先对图像进行高斯平滑处理。在ORB算法中,在这个地方进行了改进,在使用高斯函数进行平滑后又用了其他操作,使其更加的具有抗噪性。具体方法下面将会描述。
在特征点SxS的区域内选取点对的方法,BRIEF论文中测试了5种方法:
- 在图像块内平均采样;
- p和q都符合(0,S2/25)的高斯分布;
- p符合(0,S2/25)的高斯分布,而q符合(0,S2/100)的高斯分布;
- 在空间量化极坐标下的离散位置随机采样;
- 把p固定为(0,0),q在周围平均采样。

3.2、rBRIEF算法
3.2.1、steered BRIEF(旋转不变性改进):
在使用oFast算法计算出的特征点中包括了特征点的方向角度。假设原始的BRIEF算法在特征点SxS(一般S取31)邻域内选取n对点集。

经过旋转角度θ旋转,得到新的点对:

在新的点集位置上比较点对的大小形成二进制串的描述符。这里需要注意的是,在使用oFast算法是在不同的尺度上提取的特征点。因此,在使用BRIEF特征描述时,要将图像转换到相应的尺度图像上,然后在尺度图像上的特征点处取SxS邻域,然后选择点对并旋转,得到二进制串描述符。
3.2.2、rBRIEF-改进特征点描述子的相关性
使用steeredBRIEF方法得到的特征描述子具有旋转不变性,但是却在另外一个性质上不如原始的BRIEF算法,即描述符的可区分性(相关性)。为了解决描述子的可区分性和相关性的问题,ORB论文中没有使用原始BRIEF算法中选取点对时的5种方法中的任意一种,而是使用统计学习的方法来重新选择点对集合。
对每个特征点选取31x31领域,每个领域选择5x5的平均灰度值代替原来单个像素值进行比对,因此可以得到N=(31-5+1)x(31-5+1) = 729个可以比对的子窗口(patch),可以使用积分图像加快求取5x5邻域灰度平均值的速度。一共有M = 1+2+3+...+N = 265356种点对组合,也就是一个长度为M的01字符串。显然M远大于256,我们得筛选。
筛选方法如下:
- 重组所有点以及对应的初始二值串得到矩阵O,行数为提取得到的点数,每行是每个点对应的初始二值描述子
- 对重组后的矩阵O,按照每列均值与0.5的绝对差从小到大排序,得到矩阵T
- 贪心选择:把T中第一列放进矩阵R(一开始为空)中,并从T中移除依次选择T的每列,与R中所有的列进行比较,如果相似度超过一定阈值,忽略,进行下一列,否则放进R中,并从T中移除重复以上过程直到选择256个列,这样每个特征点就有256个0,1组成的描述子。如果不足256个,则降低阈值直到满足256就可,R即为最终特征描述矩阵。
三、特征点匹配
这部分是另外一个话题了。ORB算法最大的特点就是计算速度快 。这得益于使用FAST检测特征点,FAST的检测速度正如它的名字一样是出了名的快。再就是是使用BRIEF算法计算描述子,该描述子特有的2进制串的表现形式不仅节约了存储空间,而且大大缩短了匹配的时间。
例如特征点A、B的描述子如下。
A:10101011
B:10101010
设定一个阈值,比如80%。当A和B的描述子的相似度大于90%时,我们判断A,B是相同的特征点,即这2个点匹配成功。在这个例子中A,B只有最后一位不同,相似度为87.5%,大于80%。则A和B是匹配的。
将A和B进行异或操作就可以轻松计算出A和B的相似度。而异或操作可以借助硬件完成,具有很高的效率,加快了匹配的速度。
四、OpenCV实验(OpenCV3.0以上版本,包含contrib模块)
### orb extract and match
#include <iostream>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <string>
#include <dirent.h>
#include <unistd.h>
#include <vector>
#include <sstream>
#include <fstream>
#include <sys/io.h>
#include <sys/times.h>
#include <iomanip>
#include <tuple>
#include <cstdlib>
using namespace std;
#include "opencv2/imgproc.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/stitching.hpp"
#include "opencv2/xfeatures2d/nonfree.hpp"
using namespace cv;
#define ENABLE_LOG
bool PreapreImg(vector<Mat> &imgs);
bool Match(vector<cv::detail::MatchesInfo> &pairwise_matches,
const vector<cv::detail::ImageFeatures> &features,
const cv::String matcher_type = "homography",
const int range_width = -1,
const bool try_cuda = false,
const double match_conf = 0.3f);
void demo();
int main(int argc, char** argv)
{
cout << "# STA ##############################" << endl;
cout << "\n" << endl;
int64 app_start_time = getTickCount();
demo();
cout << "\n" << endl;
cout << "# END ############################## Time: "
<< ((getTickCount() - app_start_time) / getTickFrequency())
<< " sec" << endl;
return 0;
}
void demo()
{
vector<Mat> imgs;
PreapreImg(imgs);
// define feature finder
Ptr<cv::detail::FeaturesFinder> finder =
cv::makePtr<cv::detail::OrbFeaturesFinder>();
// detect features
int num_images = static_cast<int>(imgs.size());
vector<cv::detail::ImageFeatures> features(num_images);
for (int i = 0; i < num_images; i++) {
(*finder)(imgs[i], features[i]);
features[i].img_idx = i;
#ifdef ENABLE_LOG
cout << ">> features number: " << setw(4) << features[i].img_idx
<< setw(5) << static_cast<int>(features[i].keypoints.size())
<< endl;
Mat tmp;
cv::drawKeypoints(imgs[i], features[i].keypoints, tmp);
stringstream ss;
ss << i;
cv::imwrite(("./img" + string(ss.str()) + "_keypoints.jpg").c_str(), tmp);
#endif
}
// Frees unused memory allocated before if there is any
finder->collectGarbage();
// Pairwise matching
vector<cv::detail::MatchesInfo> pairwise_matches;
Match(pairwise_matches, features);
#ifdef ENABLE_LOG
cout << ">> pairwise matches: "
<< setw(5) << static_cast<int>(pairwise_matches.size())
<< endl;
cout << ">> Saving matches graph..." << endl;
ofstream f("./matchGraph.txt");
vector<cv::String> img_names;
for (int i = 0; i < num_images; i++) {
stringstream ss; ss << i;
img_names.push_back(ss.str());
}
f << matchesGraphAsString(img_names, pairwise_matches, 1.0f);
cout << ">> Saving matches graph OK. Position: ./matchGraph.txt" << endl;
Mat tmp;
cv::drawMatches(imgs[0], features[0].keypoints,
imgs[1], features[1].keypoints,
pairwise_matches[1].matches,
tmp);
cv::imwrite("./matches0_1.jpg", tmp);
#endif
}
bool PreapreImg(vector<Mat> &imgs)
{
Mat image0 = imread("./0.jpg", IMREAD_GRAYSCALE);
Mat image1 = imread("./1.jpg", IMREAD_GRAYSCALE);
imgs.push_back(image0);
imgs.push_back(image1);
// Check if have enough images
int num_images = static_cast<int>(imgs.size());
if (num_images < 2)
{
cout << ">> error. num_images < 2" << endl;
return false;
}
#ifdef ENABLE_LOG
for (int i = 0; i < num_images; i++) {
cout << ">> image " << setw(2) << i << ": "
<< setw(5) << imgs[i].rows
<< setw(5) << imgs[i].cols
<< setw(5) << imgs[i].channels()
<< endl;
}
#endif
return true;
}
/************************************************
* There are 3 kinds of feature matchers offered by "matchers.hpp"
*/
bool Match(vector<cv::detail::MatchesInfo> &pairwise_matches,
const vector<cv::detail::ImageFeatures> &features,
const cv::String matcher_type = "homography",
const int range_width = -1,
const bool try_cuda = false,
const double match_conf = 0.3f)
{
Ptr<cv::detail::FeaturesMatcher> matcher;
if (matcher_type == "affine")
{
bool full_affine = false;
int num_matches_thresh1 = 6;
matcher = makePtr<cv::detail::AffineBestOf2NearestMatcher>(
full_affine, try_cuda, match_conf, num_matches_thresh1);
}
else if (matcher_type == "homography")
{
int num_matches_thresh1 = 6;
int num_matches_thresh2 = 6;
if (range_width == -1)
matcher = makePtr<cv::detail::BestOf2NearestMatcher>(
try_cuda, match_conf, num_matches_thresh1, num_matches_thresh2);
else
matcher = makePtr<cv::detail::BestOf2NearestRangeMatcher>(
range_width, try_cuda, match_conf, num_matches_thresh1, num_matches_thresh2);
}
(*matcher)(features, pairwise_matches);
matcher->collectGarbage();
return true;
} 实验代码:https://code.csdn.net/guoyunfei20/orb.git
实验结果:
输入图像1:

输入图像2:

图像1的ORB特征点位置:

图像2的ORB特征点位置:

利用cv::detail::BestOf2NearestMatcher匹配算法得到的能匹配上的特征点(图像0 -> 图像1):


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)