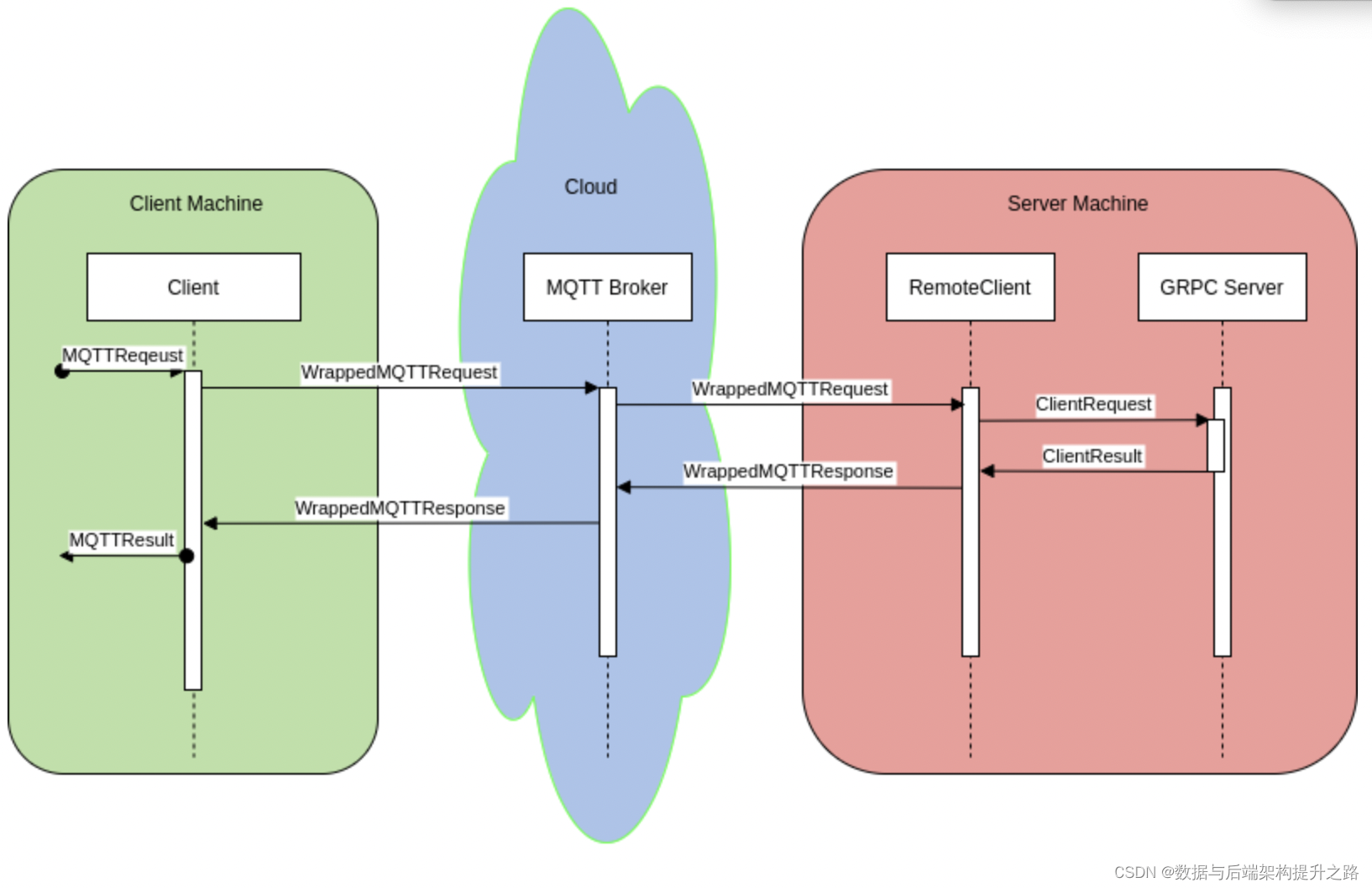
IoT设备海量数据实时传输,Protobuf+MQTT如何实现高效安全的跨平台序列化
Protobuf,在计算机科学中称为Protocol Buffers,是由Google设计并开放源代码的一种语言中立、平台中立、可扩展的数据序列化协议。它被设计用来替代如XML和JSON等传统的数据序列化格式,因其出色的简洁性、效率和跨平台的兼容性。与XML和JSON不同,Protobuf是二进制格式,在网络传输或者应用间的数据传输场景中效率非常高。
目录
3.服务器上实现 MQTT 接收和 Protobuf 反序列化
Protobuf概念介绍

Protobuf,在计算机科学中称为Protocol Buffers,是由Google设计并开放源代码的一种语言中立、平台中立、可扩展的数据序列化协议。它被设计用来替代如XML和JSON等传统的数据序列化格式,因其出色的简洁性、效率和跨平台的兼容性。与XML和JSON不同,Protobuf是二进制格式,在网络传输或者应用间的数据传输场景中效率非常高。
在实际应用范围中,Protobuf广泛用于:
-
跨服务通讯:它作为RPC (远程过程调用)框架的接口定义语言(IDL),可以用于不同服务之间的接口描述和数据交换。
-
数据存储:由于该协议非常紧凑,很多公司使用它作为数据存储时的编码格式,以降低存储空间开销。
-
配置文件:Protobuf也可用于应用程序配置文件的编码。
-
游戏行业:在网络游戏中,Protobuf被广泛用作客户端与服务器间快速、高效通信的格式。
-
物联网(IoT)设备:Protobuf提供小尺寸的二进制数据包,使得其可以在带宽有限的IoT设备中传输数据,且对传输过程的功耗和处理时间有所减少。
IoT中Protobuf 和 MQTT 综合运用

1.定义 Protobuf 消息格式
设计一个 Protobuf 消息格式来表示 IoT 设备的数据(例如温度、湿度)。
syntax = "proto3"; package sensor; message SensorData { double temperature = 1; double humidity = 2; }使用
protoc编译器生成对应的代码(例如,对于 Java,运行protoc --java_out=./java sensor_data.proto)。
2.通过 MQTT 发送数据
在 IoT 设备上,你可以使用 Python 实现 Protobuf 序列化和 MQTT 发送:
import paho.mqtt.client as mqtt
import sensor_data_pb2 # 导入 Protobuf 生成的模块
# 创建一个 MQTT 客户端实例
client = mqtt.Client()
# 连接到 MQTT 服务器
client.connect("mqtt_server_address", 1883, 60)
# 创建一个 Protobuf 消息
sensor_data = sensor_data_pb2.SensorData()
sensor_data.temperature = 25.5
sensor_data.humidity = 60.0
# 序列化数据
serialized_data = sensor_data.SerializeToString()
# 通过 MQTT 发送数据
client.publish("sensor/topic", serialized_data)
# 断开连接
client.disconnect()
3.服务器上实现 MQTT 接收和 Protobuf 反序列化
在服务器端接收 MQTT 消息并使用 Protobuf 反序列化来还原数据。使用 MQTT 客户端库,例如 Eclipse Paho。
首先,在项目中添加相关依赖:
<!-- Maven 依赖 -->
<dependencies>
<dependency>
<groupId>org.eclipse.paho</groupId>
<artifactId>org.eclipse.paho.client.mqttv3</artifactId>
<version>1.2.5</version>
</dependency>
<!-- 添加 Protobuf 依赖 -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.19.0</version>
</dependency>
</dependencies>
然后,实现数据接收逻辑:
import org.eclipse.paho.client.mqttv3.MqttClient;
import org.eclipse.paho.client.mqttv3.MqttMessage;
import org.eclipse.paho.client.mqttv3.IMqttDeliveryToken;
import org.eclipse.paho.client.mqttv3.MqttCallback;
import org.eclipse.paho.client.mqttv3.MqttConnectOptions;
import sensor.SensorDataOuterClass.SensorData;
public class SensorDataSubscriber {
public static void main(String[] args) throws Exception {
// 创建 MQTT 客户端
String broker = "tcp://mqtt_server_address:1883";
String clientId = "JavaSensorSubscriber";
MqttClient client = new MqttClient(broker, clientId);
// 设置回调
client.setCallback(new MqttCallback() {
public void messageArrived(String topic, MqttMessage message) throws Exception {
// 反序列化 Protobuf 消息
byte[] bytes = message.getPayload(); // 获取序列化的数据
SensorData sensorData =
ProtostuffUtil.deserializeProtoStuffDataListToProductsObject(bytes, SensorData.class);
//SensorData sensorData = SensorData.parseFrom(message.getPayload());
System.out.println("Received sensor data: Temperature = " + sensorData.getTemperature() + ", Humidity = " + sensorData.getHumidity());
}
public void connectionLost(Throwable cause) {
System.out.println("Connection lost: " + cause.getMessage());
}
public void deliveryComplete(IMqttDeliveryToken token) {
// not used in this example
}
});
// 连接到 MQTT 服务器
ProtostuffUtil
封装代码
package cn.btkj.utils;
import java.util.ArrayList;
import java.util.List;
import io.protostuff.LinkedBuffer;
import io.protostuff.ProtostuffIOUtil;
import io.protostuff.Schema;
import io.protostuff.runtime.RuntimeSchema;
/*
项目中http通信离不开对象的序列化和反序列化,以前框架使用的是json,通用、可读性强,
对于对速度要求不高的系统来说,的确是一种不错的选择。使用protobuf,因为其速度比json快非常多,
而业界说到java的序列化和反序列化,更离不开基于protobuf的protostuff
*/
public class ProtostuffUtil {
//在 ProtostuffUtil 中,每次序列化操作都会创建一个新的 LinkedBuffer。对于频繁的序列化操
//作,这可能不是最高效的做法。考虑重用 LinkedBuffer 可以提高性能,尤其是在高负载或高频率调用
//的情况下
private static final LinkedBuffer BUFFER = LinkedBuffer.allocate(4096);
public static List<byte[]> serializeProtoStuffObjectList(List<?> list, Class<?> clazz) {
if (list == null || list.isEmpty()) {
return null;
}
List<byte[]> bytesList = new ArrayList<>();
Schema<?> schema = RuntimeSchema.getSchema(clazz);
for (Object obj : list) {
byte[] protostuff = ProtostuffIOUtil.toByteArray(obj, schema, buffer);
bytesList.add(protostuff);
BUFFER.clear();
}
return bytesList;
}
public static <T> List<T> deserializeProtoStuffDataListToObjectList(List<byte[]> bytesList, Class<T> clazz) {
if (bytesList == null || bytesList.isEmpty()) {
return null;
}
List<T> objects = new ArrayList<>();
Schema<T> schema = RuntimeSchema.getSchema(clazz);
for (byte[] bytes : bytesList) {
T obj = schema.newMessage();
ProtostuffIOUtil.mergeFrom(bytes, obj, schema);
objects.add(obj);
}
return objects;
}
public static byte[] serializeProtoStuffObject(Object obj, Class<?> clazz) {
if (obj == null) {
return null;
}
Schema<?> schema = RuntimeSchema.getSchema(clazz);
try {
return ProtostuffIOUtil.toByteArray(obj, schema, BUFFER);
} finally {
BUFFER.clear();
}
}
public static <T> T deserializeProtoStuffDataListToProductsObject(byte[] bytes, Class<T> clazz) {
if (bytes == null) {
return null;
}
Schema<T> schema = RuntimeSchema.getSchema(clazz);
T obj = schema.newMessage();
ProtostuffIOUtil.mergeFrom(bytes, obj, schema);
return obj;
}
}
Maven依赖
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.8.0</version>
</dependency>
Descriptors.Descriptor优化
1、预加载和缓存
- 在初始化时预加载了一系列 Protobuf 描述文件(
.desc文件),并将它们存储在缓存中。这种预加载和缓存机制避免了在每次需要时都解析这些描述文件,从而显著提高了运行时的效率。
2、动态查找和构建
- 通过动态查找和构建
FileDescriptor和Descriptors.Descriptor对象,可以根据需要解析和访问具体的 Protobuf 消息类型。这对于处理动态生成或在运行时确定的 Protobuf 消息类型非常有效。
3、减少冗余解析
- 在处理大量 Protobuf 消息时,避免重复解析相同的描述信息可以节省大量的时间和资源。通过缓存已解析的描述符,可以快速访问这些信息,而无需重新执行解析操作。
import com.google.protobuf.DescriptorProtos;
import com.google.protobuf.Descriptors;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Map;
public class ProtoDescriptorUtils {
private static final Map<String, Descriptors.Descriptor> descriptorCache = new HashMap<>();
static {
try {
// 预加载 .desc 文件
InputStream input = ProtoDescriptorUtils.class.getClassLoader().getResourceAsStream("example.desc");
DescriptorProtos.FileDescriptorSet descriptorSet = DescriptorProtos.FileDescriptorSet.parseFrom(input);
// 构建 FileDescriptor
for (DescriptorProtos.FileDescriptorProto fdp : descriptorSet.getFileList()) {
Descriptors.FileDescriptor[] dependencies = new Descriptors.FileDescriptor[fdp.getDependencyCount()];
for (int i = 0; i < fdp.getDependencyCount(); i++) {
String depName = fdp.getDependency(i);
dependencies[i] = Descriptors.FileDescriptor.getByName(depName);
}
Descriptors.FileDescriptor fd = Descriptors.FileDescriptor.buildFrom(fdp, dependencies);
// 缓存 Descriptor
for (Descriptors.Descriptor descriptor : fd.getMessageTypes()) {
descriptorCache.put(descriptor.getFullName(), descriptor);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static Descriptors.Descriptor getDescriptor(String messageTypeName) {
return descriptorCache.get(messageTypeName);
}
// 其他方法,如解析 Protobuf 消息等...
}
public class Main {
public static void main(String[] args) {
// 获取指定消息类型的 Descriptor
Descriptors.Descriptor descriptor = ProtoDescriptorUtils.getDescriptor("example.ExampleMessage");
if (descriptor != null) {
// 使用 Descriptor 进行消息的解析等操作
}
}
}
- 这个示例中的
ProtoDescriptorUtils类在静态初始化块中加载了.desc文件,并将所有的消息类型描述符存储在一个静态的缓存中。- 通过调用
getDescriptor方法,可以根据消息类型的名称直接获取对应的描述符。这避免了在每次解析消息时重新加载和解析.desc文件。- 这种方法在处理多种不同的消息类型时非常有效,特别是当这些类型在运行时是已知的,或者在处理大量的消息时,可以显著提高效率。
相关资料

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)