一文看懂推荐系统:排序10:wide&deep模型,wide就是LR负责记忆,deep负责高阶特征交叉而泛化
一文看懂推荐系统:排序10:wide&deep模型,wide就是LR负责记忆,deep负责高阶特征交叉而泛化
一文看懂推荐系统:排序10:wide&deep模型,wide就是LR负责记忆,deep负责高阶特征交叉而泛化
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
【17】一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
【18】一文看懂推荐系统:特征交叉01:Factorized Machine (FM) 因式分解机
【19】一文看懂推荐系统:物品冷启01:优化目标 & 评价指标
【20】一文看懂推荐系统:物品冷启02:简单的召回通道
【21】一文看懂推荐系统:物品冷启03:聚类召回
【22】一文看懂推荐系统:物品冷启04:Look-Alike 召回,Look-Alike人群扩散
【23】一文看懂推荐系统:物品冷启05:流量调控
【24】一文看懂推荐系统:物品冷启06:冷启的AB测试
【25】推荐系统最经典的 排序模型 有哪些?你了解多少?
【26】一文看懂推荐系统:排序07:GBDT+LR模型
【27】一文看懂推荐系统:排序08:Factorization Machines(FM)因子分解机,一个特殊的案例就是MF,矩阵分解为uv的乘积
【28】一文看懂推荐系统:排序09:Field-aware Factorization Machines(FFM),从FM改进来的,效果不咋地
提示:文章目录
文章目录
wide&deep模型
这篇博客主要介绍谷歌于2016年发表在RecSys上的一篇文章,
俗话说:谷歌家出品,必属精品。
这篇文章提出的模型wide&deep着实对推荐系统领域有着非常大的影响,
启发了后面几年推荐系统领域的一些工作,比如:deep&cross,deepFM等。 【后边我都会一一说的】
这篇文章也是秉承着Google家文章一贯的风格【大道至简,非常关注工程实践】,
不像国内某互联网公司某团队的paper简直是概念的堆砌,
如果没有概念就造概念,让人看的眼花缭乱,明显是冲着发论文去的。
恶心人!
这篇博客主要以下几个点来介绍下wide&deep模型。
《Wide & Deep Learning for Recommender Systems》

一、提出wide&deep的动机
在这篇论文之前,工业界推荐系统主流的模型基本是LR或者普通的DNN(当然也有像FM和树模型及其变种),
通常而言,线性模型比如LR比较擅长记忆,而DNN则比较擅长泛化。
这里来解释下何为记忆,何为泛化???
记忆: 其实就是模型直接学到样本中一些强特征,
比如,尿布&瓶酒的例子,
如果样本中频繁出现了买了尿布的人同时买了啤酒,
也就是说尿布&啤酒共现的频率很高,
那么模型可以直接记住这种共现,
当做推荐的时候,如果一个人买了尿布,那么应该给他推荐啤酒。
泛化: 泛化则是学习特征的传递能力,
比如某个训练集为树叶,label为判断输入的东西是否是一个树叶,
样本中的树叶基本都是绿色的锯齿状树叶,
那么我们希望模型能够有泛化能力,
当输入一个泛黄的圆形树叶,模型也能判断出这是个树叶。
因此,为了结合这两种能力,提出了wide&deep模型,
wide侧为一个LR模型,负责记忆,
deep部分为一个多层全连接网络,负责泛化。
二、wide&deep模型结构

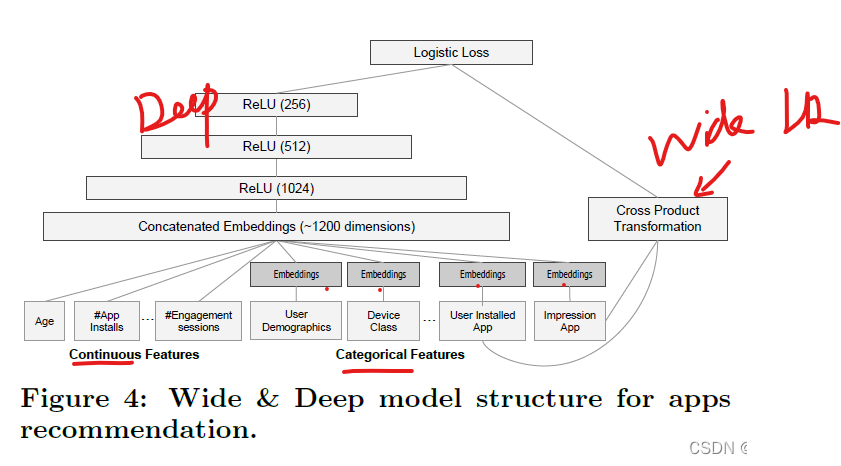
从上图能够非常清晰的看到wide&deep模型包含两个部分,
wide部分和deep部分。
wide部分为一个线性模型LR,

deep部分为一个三层隐藏层[1024,512,256]的DNN。

模型网络结构虽然简直直白,但有几个细节需要关注下:
训练方式:
wide部分和deep部分使用logistics loss连接在一起,通过bp联合训练,而不是单独训练然后做ensemble。
优化算法:
wide部分采用Google家出产的FTRL优化算法
deep部分采用AdaGrad(关于AdaGrad参见本人的博客:深度学习中优化方法
——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam)
那么随之而来的2个问题:
(a)两个不同的优化算法放在一起怎么优化?
(b)为什么LR部分采用ftrl,而deep部分采用AdaGrad
这两个问题留到博客最后的【一些思考】里再介绍。
特征:
在Google play的场景下主要分为连续值特征和类别特征,
在这篇论文中,连续值特征被归一化到[0,1]范围内,类别特征则做了embedding,
然后直接做了concate,输入到deep网络中。
wide部分主要输入的是一些交叉特征,用于记忆。
模型训练:
采用热启的方式训练模型,上一次(天级别或者小时级)的模型embedding向量和权重初始化下一个时间的模型
(ented a warm-starting system which initializes a new model with the embeddings and the linear model weights from the previous model.)。
这一点和我厂的abacus保持一致。这样做的好处显而易见,lifetime learning + Fine Tune。
模型更新校验: 每次更新到线上之前要做一次校验,
校验待更新的模型是否正常,防止把有问题的模型更新到线上,发生问题。
这一点透露着浓浓的工业风,也是一个工业系统必备的环节。
三、一些思考
问题1: wide部分和deep采用联合训练,
但wide部分采用FTRL优化算法,deep部分采用AdaGrad优化算法,这个该怎么训练?
这个问题直接看TensorFlow官方代码:https://github.com/tensorflow/tensorflow/blob/r1.11/tensorflow/python/estimator/canned/dnn_linear_combined.py
deep侧:
# deep侧
with variable_scope.variable_scope(
dnn_parent_scope,
values=tuple(six.itervalues(features)),
partitioner=dnn_partitioner) as scope:
dnn_absolute_scope = scope.name
dnn_logit_fn = dnn._dnn_logit_fn_builder( # pylint: disable=protected-access
units=head.logits_dimension,
hidden_units=dnn_hidden_units,
feature_columns=dnn_feature_columns,
activation_fn=dnn_activation_fn,
dropout=dnn_dropout,
input_layer_partitioner=input_layer_partitioner,
batch_norm=batch_norm)
dnn_logits = dnn_logit_fn(features=features, mode=mode)
wide侧:
# wide侧
with variable_scope.variable_scope(
linear_parent_scope,
values=tuple(six.itervalues(features)),
partitioner=input_layer_partitioner) as scope:
linear_absolute_scope = scope.name
logit_fn = linear._linear_logit_fn_builder( # pylint: disable=protected-access
units=head.logits_dimension,
feature_columns=linear_feature_columns,
sparse_combiner=linear_sparse_combiner)
linear_logits = logit_fn(features=features)
loss直接把wide部分的loss和deep部分的loss相加
# loss函数
if n_classes == 2:
head = head_lib._binary_logistic_head_with_sigmoid_cross_entropy_loss( # pylint: disable=protected-access
weight_column=weight_column,
label_vocabulary=label_vocabulary,
loss_reduction=loss_reduction)
else:
head = head_lib._multi_class_head_with_softmax_cross_entropy_loss( # pylint: disable=protected-access
n_classes,
weight_column=weight_column,
label_vocabulary=label_vocabulary,
loss_reduction=loss_reduction)
# Combine logits and build full model.
if dnn_logits is not None and linear_logits is not None:
logits = dnn_logits + linear_logits
elif dnn_logits is not None:
logits = dnn_logits
else:
logits = linear_logits
BP时,采用不用的优化器优化wide侧和deep侧,
这里核心语句在于:
train_op = control_flow_ops.group(train_ops),
从而做到了可以用不同的优化器来优化两侧。
def _train_op_fn(loss):
"""Returns the op to optimize the loss."""
train_ops = []
global_step = training_util.get_global_step()
if dnn_logits is not None:
train_ops.append(
dnn_optimizer.minimize(
loss,
var_list=ops.get_collection(
ops.GraphKeys.TRAINABLE_VARIABLES,
scope=dnn_absolute_scope)))
if linear_logits is not None:
train_ops.append(
linear_optimizer.minimize(
loss,
var_list=ops.get_collection(
ops.GraphKeys.TRAINABLE_VARIABLES,
scope=linear_absolute_scope)))
# 核心语句,采用group函数
train_op = control_flow_ops.group(*train_ops)
with ops.control_dependencies([train_op]):
return state_ops.assign_add(global_step, 1).op
return head.create_estimator_spec(
features=features,
mode=mode,
labels=labels,
train_op_fn=_train_op_fn,
logits=logits)
问题2: 为什么wide侧采用FTRL,而deep侧采用AdaGrad?
我个人觉得在wide侧采用FTRL,一方面是为了产生稀疏解,
毕竟在论文中能够看到wide部分的交叉特征是两个id特征的交叉,
这样可以大大缩小模型体积,利于线上部署。
另外一方面,由于联合训练,必然会出现wide部分收敛速度远远快于deep部分,
应该是谷歌大佬们为了缓解这种情况,因为ftrl和adagrad都是随着梯度的累计,
学习率会变小,并且ftrl结合了L1正则和L2正则,使得ftrl收敛速度慢。
注:这一点只是个人理解,如果有大佬有更好的理解,欢迎留言交流。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:为了结合这两种能力,提出了wide&deep模型,wide侧为一个LR模型,负责记忆,deep部分为一个多层全连接网络,负责泛化。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 2
2 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)