使用 LiteLLM 构建适用于生产级规模的强大 LLM 应用程序
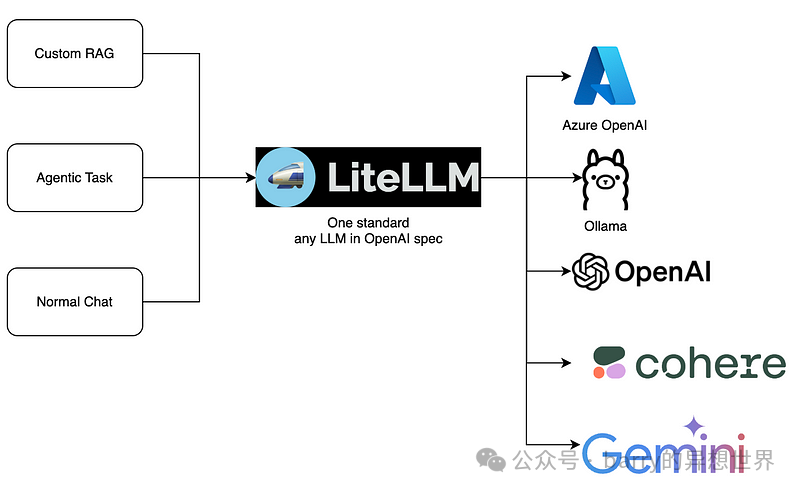
LiteLLM是一个 Python 库,旨在简化多种大型语言模型(LLM)API 的集成。通过支持来自众多提供商的超过 100 种 LLM 服务,它使用户能够使用标准化的 OpenAI API 格式与这些模型进行交互。提供商包括AzureAnthropicCohereOpenAIOllama和Sagemaker等主要品牌。这种广泛的兼容性为用户提供了丰富的语言模型功能,简化了将先进语言模型集成到其
LiteLLM 是一个创新的代理,通过提供符合OpenAI API规范的统一标准,简化了将各种大型语言模型(LLMs)集成到应用程序中的过程。它允许在不同的LLM提供商之间无缝切换,如Azure OpenAI、Ollama、OpenAI、Cohere和Gemini。这种灵活性支持多种用例,包括自定义检索增强生成(RAG)、代理任务和普通聊天交互,提高了部署LLM驱动解决方案的效率和适应性。

你将学习什么?
-
LiteLLM的安装 -
LiteLLM的功能与API -
使用
LlamaIndex和LiteLLM构建基础的RAG应用 -
使用
Qdrant和LiteLLM构建自定义RAG -
使用
LiteLLM guard rails保护生产环境中的LLM应用 -
未来派的LLM架构
什么是 LiteLLM?
LiteLLM 是一个 Python 库,旨在简化多种大型语言模型(LLM)API 的集成。通过支持来自众多提供商的超过 100 种 LLM 服务,它使用户能够使用标准化的 OpenAI API 格式与这些模型进行交互。提供商包括 Azure、AWS Bedrock、Anthropic、HuggingFace、Cohere、OpenAI、Ollama 和 Sagemaker 等主要品牌。这种广泛的兼容性为用户提供了丰富的语言模型功能,简化了将先进语言模型集成到其应用中的过程。参考。
什么是 LiteLLM 代理?
LiteLLM 代理 是 LiteLLM 模型 I/O 库的关键组件,旨在标准化对 Azure、Anthropic 和 OpenAI 等多种语言模型服务的 API 调用。作为中间件,LiteLLM 代理通过提供统一的接口简化了与多个 LLM API 的交互。它管理 API 密钥,处理错误回退,记录请求和响应,跟踪令牌使用和消费,并提供缓存和速率限制等功能。此外,它支持一致的输入/输出格式,对于高效的 LLM 应用管理至关重要。
如何启动您自己的 LiteLLM 代理?
model_list:
- model_name: llama3:latest
litellm_params:
model: ollama/llama3
api_base: http://localhost:11434
- model_name: gemma2:latest
litellm_params:
model: ollama/gemma2
api_base: http://localhost:11434
- model_name: mistral:latest
litellm_params:
model: ollama/mistral
api_base: http://localhost:11434
运行命令:litellm — config litellm-config.yml
此配置为 LiteLLM 代理 定义了要使用的模型列表,并详细指定了每个模型的信息。model_list 包含三个模型:llama3:latest、gemma2:latest 和 mistral:latest。每个条目都有 litellm_params,提供了 LiteLLM 与这些模型交互所需的参数。model 参数标识了托管在 Ollama 上的特定模型版本,而 api_base 参数设置了 API 请求指向的本地端点(http://localhost:11434)。此设置确保 LiteLLM 代理能够正确路由和处理这些模型的请求。
如何启动 LiteLLM 仪表盘?
为了启动 LiteLLM 仪表盘,我们只需对上述配置稍作调整。
model_list:
- model_name: llama3:latest
litellm_params:
model: ollama/llama3
api_base: http://localhost:11434
- model_name: gemma2:latest
litellm_params:
model: ollama/gemma2
api_base: http://localhost:11434
- model_name: mistral:latest
litellm_params:
model: ollama/mistral
api_base: http://localhost:11434
general_settings:
master_key: "sk-1234" # 代理服务器的管理密钥,可用于发送 /chat/completion 请求等
database_url: "postgresql://<user>:<password>@localhost:5432/postgres" # 需要 PostgreSQL 数据库吗?(可以查看 Supabase、Neon 等)
store_model_in_db: true # 允许在数据库中存储模型
使用 http://0.0.0.0:4000/ui 登录管理仪表盘,您将看到以下内容。


LiteLLM 仪表盘的一些重要功能如下。
API 密钥
LiteLLM 中的 API 密钥 部分允许用户管理其访问密钥,提供对其使用和预算的详细控制。用户可以创建新密钥、设置别名,并指定消费限额。此外,他们可以为每个密钥分配不同的模型,并定义每分钟令牌数(TPM)和每分钟请求数(RPM)的限制。界面还包括设置最大预算和密钥过期时间的选项。这种细粒度控制确保在使用 LiteLLM 通过各种 LLM 时,资源和成本得到高效管理。
模型
LiteLLM 中的 模型 标签提供了对各种语言模型的全面管理功能。用户可以轻松添加、配置和监控模型。用户可以为不同的模型(如 llama3:latest)设置特定的重试策略,通过指定针对 BadRequestError 或 TimeoutError 等错误的重试次数。该标签还提供分析功能,展示每个模型的平均延迟每令牌和异常等指标。此外,它支持详细配置,例如设置 API 基础 URL、每分钟令牌数(TPM)、每分钟请求数(RPM)以及每个模型的其他参数,确保模型管理的稳健性和可定制性。
路由器设置
LiteLLM中的路由器设置标签提供了广泛的选项,用于配置请求的处理和路由方式。在负载均衡下,用户可以设置路由策略、允许的失败次数、失败后的冷却时间、重试次数和超时值。回退部分允许设置备用模型,以确保主模型失败时服务的连续性。常规标签管理并行请求限制,指定每个API密钥的最大并行请求数和代理实例的全局并行请求数。这些设置确保了LLM应用中请求的高效和可靠处理。
有许多功能可供选择,但一个重要的安全功能是防护栏,以下是如何在LiteLLM配置中设置默认防护栏的方法。(需要企业账户才能使用此功能)
model_list:
- model_name: llama3:latest
litellm_params:
model: ollama/llama3
api_base: http://localhost:11434
- model_name: gemma2:latest
litellm_params:
model: ollama/gemma2
api_base: http://localhost:11434
- model_name: mistral:latest
litellm_params:
model: ollama/mistral
api_base: http://localhost:11434
litellm_settings:
guardrails:
- prompt_injection: # 防护栏的自定义名称
callbacks: [lakera_prompt_injection] # 使用的litellm回调
default_on: true # 当为true时,将对所有llm请求运行
- pii_masking: # 防护栏的自定义名称
callbacks: [presidio] # 使用litellm的presidio回调
default_on: false # 默认情况下,所有请求都关闭
- hide_secrets_guard:
callbacks: [hide_secrets]
default_on: false
- your-custom-guardrail
callbacks: [hide_secrets]
default_on: false
给定的LiteLLM配置定义了多个防护栏,以确保与大型语言模型交互的安全和合规性。每个防护栏指定了一个自定义名称和相关的回调函数,以处理特定任务。
-
prompt_injection:使用
lakera_prompt_injection回调,默认启用,以防止提示注入攻击。 -
pii_masking:使用
presidio回调来屏蔽个人身份信息(PII),但默认情况下是禁用的。 -
hide_secrets_guard:使用
hide_secrets回调,同样默认禁用。 -
your-custom-guardrail:一个自定义防护栏的示例,使用
hide_secrets回调,默认禁用。
集成与实现
这是一个通过LiteLLM代理连接到Azure OpenAI的简单RAG示例。
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.azure_openai import AzureOpenAI
from llama_index.core import SimpleDirectoryReader, ServiceContext, VectorStoreIndex
'''
以下是LiteLLM配置示例。
model_list:
- model_name: azure-gpt-3.5
model: azure/azure-gpt-3.5 ### 发送到`litellm.completion()`的模型名称 ###
api_base: https://my-endpoint-useeast-mantha-868.openai.azure.com/
api_key: "YOUR_AZURE_API_KEY" # 使用os.getenv("YOUR_AZURE_API_KEY")
rpm: 6 # [可选] 此部署的速率限制:每分钟请求数(rpm)
'''
embed_model = OllamaEmbedding(model_name='mxbai-embed-large:latest', base_url='http://localhost:11434')
llm = AzureOpenAI(
engine="azure-gpt-3.5", # LiteLLM代理上的模型名称
temperature=0.0,
azure_endpoint="http://localhost:4000", # LiteLLM代理端点
api_key="sk-DdYGeoO7PoanQYWSP_JZjQ", # LiteLLM代理API密钥
api_version="2023-07-01-preview",
)
documents = SimpleDirectoryReader("product_manual_data", required_exts=['.pdf']).load_data()
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()
response = query_engine.query("将产品规格转换为JSON格式")
print(response)
使用Qdrant混合检索和LiteLLM代理API的自定义RAG
qdrant_ops.py
import json
from qdrant_client import QdrantClient, models
from utils.decorator_utils import execution_time_decorator
class HybridQdrantOperations:
def __init__(self):
self.payload_path = "../data.json"
self.collection_name = "hybrid-multi-stage-queries-collection"
self.DENSE_MODEL_NAME = "snowflake/snowflake-arctic-embed-s"
self.SPARSE_MODEL_NAME = "prithivida/Splade_PP_en_v1"
# 连接到我们的Qdrant服务器
self.client = QdrantClient(url="http://localhost:6333", api_key="YOUR_KEY")
self.client.set_model(self.DENSE_MODEL_NAME)
# 注释此行以仅使用密集向量
self.client.set_sparse_model(self.SPARSE_MODEL_NAME)
self.metadata = []
self.documents = []
def load_data(self):
with open(self.payload_path) as fd:
for line in fd:
obj = json.loads(line)
self.documents.append(obj.pop("description"))
self.metadata.append(obj)
def create_collection(self):
if not self.client.collection_exists(collection_name=f"{self.collection_name}"):
self.client.create_collection(
collection_name=f"{self.collection_name}",
vectors_config=self.client.get_fastembed_vector_params(),
# 注释此行以仅使用密集向量
sparse_vectors_config=self.client.get_fastembed_sparse_vector_params(on_disk=True),
optimizers_config=models.OptimizersConfigDiff(
default_segment_number=5,
indexing_threshold=0,
),
quantization_config=models.BinaryQuantization(
binary=models.BinaryQuantizationConfig(always_ram=True),
),
shard_number=4
)
@execution_time_decorator
def insert_documents(self):
self.client.add(
collection_name=self.collection_name,
documents=self.documents,
metadata=self.metadata,
parallel=5, # 如果值为0,则使用所有可用CPU核心进行数据编码
)
# self._optimize_collection_after_insert()
@execution_time_decorator
def hybrid_search(self, text: str, top_k: int = 5):
# self.client.query 如果需要对过滤数据进行查询,也会包含过滤器
search_result = self.client.query(
collection_name=self.collection_name,
query_text=text,
limit=top_k, # 返回最接近的5个结果
)
# `search_result` 包含找到的向量ID及其相似度分数,以及存储的有效负载
# 选择并返回元数据
metadata = [hit.metadata for hit in search_result]
return metadata
def _optimize_collection_after_insert(self):
self.client.update_collection(
collection_name=f'{self.collection_name}',
optimizer_config=models.OptimizersConfigDiff(indexing_threshold=30000)
)
if __name__ == '__main__':
ops = HybridQdrantOperations()
# 仅在首次创建集合并希望导入数据时运行以下代码
ops.load_data()
ops.create_collection()
ops.insert_documents()
# results = ops.hybrid_search(text="What are the gaming companies in bangalore?", top_k=10000)
# print(results)
custom_rag.py
import json
from qdrant_ops import HybridQdrantOperations
from utils.decorator_utils import execution_time_decorator
import requests
class StartupRAG:
def __init__(self, retriever: HybridQdrantOperations = HybridQdrantOperations()):
self.retriever = retriever
def _fetch_context(self, user_query: str = None):
context_retrieved = self.retriever.hybrid_search(text=user_query, top_k=3)
print(f"context_retrieved: {context_retrieved}")
return context_retrieved
@execution_time_decorator
def completion(self, str_or_query: str = None):
context = self._fetch_context(user_query=str_or_query)
rag_prompt_tmpl = (
"以下是上下文信息。\n"
"---------------------\n"
f"{json.dumps(context)}\n"
"---------------------\n"
"根据提供的上下文信息,请一步一步地回答查询,如果不知道答案,请说'我不知道!'。\n"
f"查询: {str_or_query}\n"
"答案: "
)
llm_response = self._call_litellm(content=rag_prompt_tmpl)
return llm_response
def _call_litellm(self, content: str):
url = "http://0.0.0.0:4000/chat/completions"
payload = {
"model": "ollama/gemma2",
"temperature": 0.8,
"max_tokens": 100,
"messages": [
{
"role": "user",
"content": f"{content}"
}
]
}
headers = {"Content-Type": "application/json", "Authorization": "Bearer sk-DdYGeoO7PoanQYWSP_JZjQ",}
resp = requests.request("POST", url, json=payload, headers=headers)
return resp.text
if __name__ == "__main__":
rag = StartupRAG()
# 启动一个循环,持续获取用户输入
while True:
# 获取用户查询
user_query = input("输入你的查询 [输入'bye'或'exit'退出]: ")
# 检查用户是否要终止循环
if user_query.lower() == "bye" or user_query.lower() == "exit":
break
response = rag.completion(str_or_query=user_query)
print(response)
utility.py
import time
from functools import wraps
def execution_time_decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
execution_time = end_time - start_time
print(f"执行时间 for {func.__name__}: {execution_time:.6f} 秒")
return result
return wrapper
使用 LiteLLM API:
如果你是API爱好者,LiteLLM提供了一系列API,你可以通过http://0.0.0.0:4000查看。

LiteLLM的Swagger界面展示了全面的可用功能和端点列表,便于与LiteLLM服务的各个方面进行交互。主要功能包括:
-
模型管理:管理和配置模型。
-
聊天/补全:处理聊天交互和补全请求。
-
嵌入向量:处理文本嵌入向量。
-
图像和音频:管理图像和音频数据。
-
文件和内容审核:处理文件上传和内容审核。
-
客户和组织管理:管理客户和组织设置。
-
预算和支出追踪:监控和管理预算。
-
缓存和健康监控:配置缓存和监控系统健康。
-
密钥和团队管理:处理API密钥和团队设置。
未来架构:

结论
总之,LiteLLM 及其组件,如 LiteLLM Proxy,为将多种大型语言模型集成到您的应用中提供了一个强大的解决方案。该系统能够标准化 API 调用、管理模型,并处理诸如错误处理、缓存和速率限制等横切关注点,简化了 LLM 驱动服务的开发和部署。通过为模型、路由和护栏提供详细的配置选项,LiteLLM 确保了与多个 LLM 提供商之间的高效、安全和合规的交互。采用 LiteLLM 可以显著增强您的语言模型应用的能力和性能。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 17
17 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)