AI论文速读 | UniTS:构建统一的时间序列模型
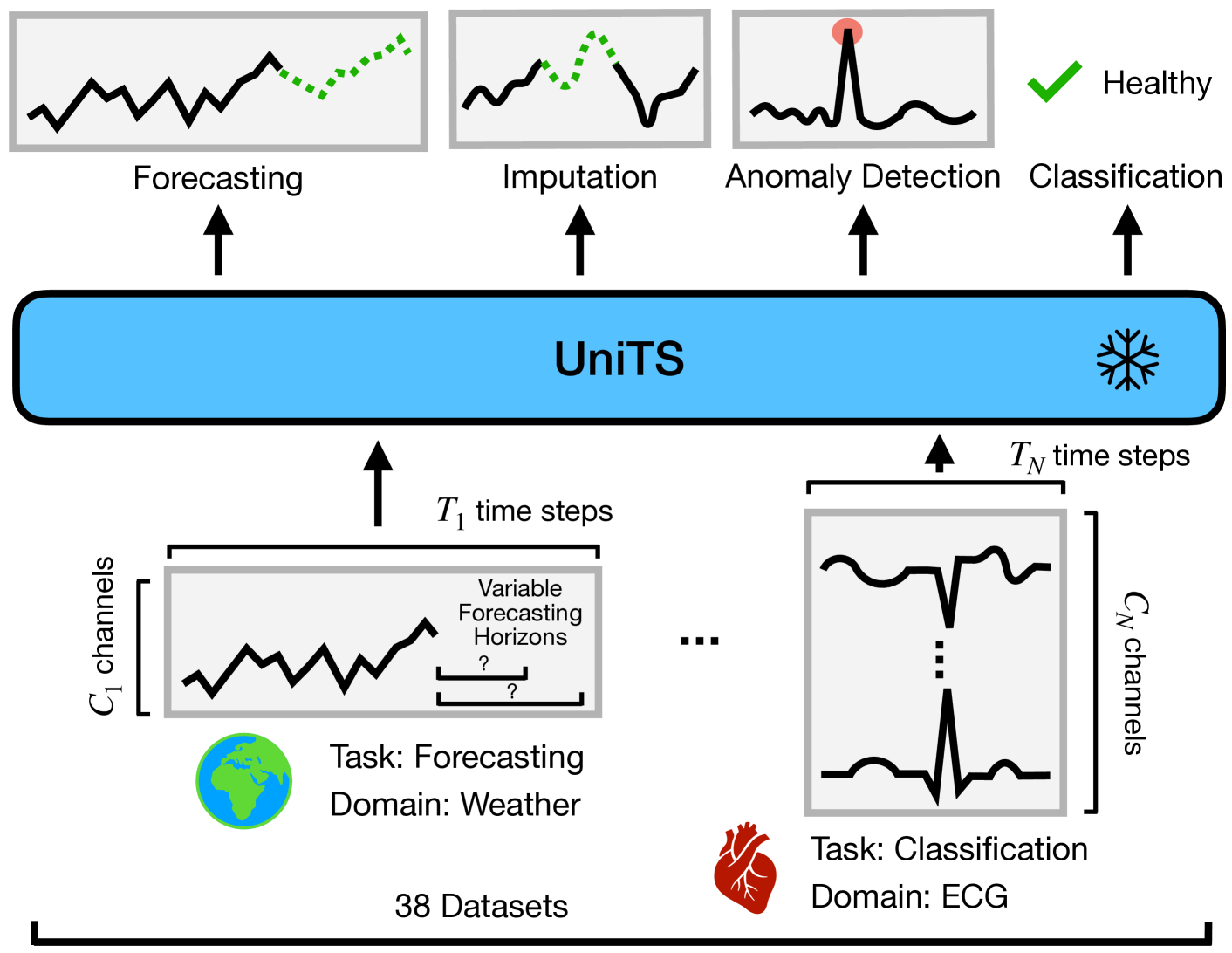
基础模型,尤其是大语言模型,正在深刻地改变深度学习。可以通过少量提示或微调使单个预训练模型适应许多任务,而不是训练许多特定于任务的模型。然而,当前的基础模型适用于序列数据,但不适用于时间序列,由于固有的多样化和多域时间序列数据集、预测、分类和其他类型任务的不同任务规范以及对任务的明显需求需要各自专门的模型(task-specialized model),这带来了独特的挑战。本文开发了 UNITS,
题目:UniTS: Building a Unified Time Series Model
作者:Shanghua Gao(高尚华), Teddy Koker, Owen Queen, Thomas Hartvigsen, Theodoros Tsiligkaridis, Marinka Zitnik
机构:哈佛大学(Harvard),MIT林肯实验室,弗吉尼亚大学(Virginia)
网址:https://arxiv.org/abs/2403.00131
Cool Paper:https://papers.cool/arxiv/2403.00131
代码:https://github.com/mims-harvard/UniTS
项目地址:https://zitniklab.hms.harvard.edu/projects/UniTS
关键词:多任务学习, 跨领域泛化,统一预训练,零样本,小样本,提示学习。
TL; DR: 本文介绍了UniTS,一个统一的时间序列模型,它能够通过共享参数处理多种任务,如分类、预测、插补和异常检测,并且在多领域数据集上展现出优越的性能和显著的零样本、小样本和提示学习能力。

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
作者简介(一作和通讯):
- 一作高尚华博士是CV出身,博士师从南开大学程明明教授,目前在哈佛做博后,经典的ResNet变体——Res2Net一作。
- 通讯Marinka Zitnik是哈佛大学的助理教授,是AI4Science的rising star。有一篇发表在《nature》上大佬云集的AI4Science的综述:Scientific discovery in the age of artificial intelligence,Marinka是大通讯。

![2023[Nature]Scientific discovery in the age of artificial intelligence](https://i-blog.csdnimg.cn/blog_migrate/060de4b5f4015912366ecf1bb759d266.png)
摘要
基础模型,尤其是大语言模型,正在深刻地改变深度学习。 可以通过少量提示或微调使单个预训练模型适应许多任务,而不是训练许多特定于任务的模型。 然而,当前的基础模型适用于序列数据,但不适用于时间序列,由于固有的多样化和多域时间序列数据集、预测、分类和其他类型任务的不同任务规范以及对任务的明显需求需要各自专门的模型(task-specialized model),这带来了独特的挑战。 本文开发了 UNITS,这是一个统一的时间序列模型,支持通用任务规范,可容纳分类、预测、插补和异常检测任务。 这是通过一个新颖的统一网络主干来实现的,该主干结合了序列和变量注意力以及动态线性算子,并作为统一模型进行训练。 在 38 个多领域数据集中,与特定于任务的模型和重新利用的基于自然语言的LLM相比,UNITS 表现出了卓越的性能。 在新的数据域和任务上进行评估时,UNITS 表现出卓越的零样本、小样本和提示学习能力。

Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为UniTS(Unified Time Series)的统一时间序列模型,旨在解决以下问题:
- 多任务学习与适应性:传统的时间序列模型通常针对特定任务进行训练,如预测、分类、插值和异常检测等。这些模型往往需要针对新任务进行微调或重新设计任务特定模块,这可能导致过拟合,限制了模型在新任务上的泛化能力。UniTS旨在通过一个统一的模型来处理多种任务,而无需为每个任务单独训练模型。
- 跨领域数据的泛化能力:时间序列数据在不同领域(如医学、工程、科学等)具有广泛的应用,但它们在时间动态、数据表示(变量数量、传感器定义、观测长度)等方面存在显著差异。现有的统一模型可能无法适应这种多样性。UniTS通过设计一个能够捕捉跨领域通用时间动态的模型来解决这一挑战。
- 任务特定模块的需求:为了提高模型在特定任务上的表现,研究者们通常会为每个数据集训练特定的模块。然而,这种方法需要为每个任务调整训练参数,并且需要一定规模的数据集,这与设计一个能够同时处理多个任务的统一模型的概念相矛盾。UniTS通过共享权重来增强模型的泛化能力,并通过统一的掩码重构预训练方案来处理生成和识别任务。
总的来说,UniTS的目标是开发一个能够处理多种时间序列任务、适应不同领域数据、并且具有良好泛化能力的统一模型。通过这种方法,UniTS在38个多领域数据集上展示了优越的性能,并在新数据域和任务上表现出显著的零样本、小样本和提示学习能力。
Q: 有哪些相关研究?
A: 在这篇论文中,作者提到了以下几类相关研究:
- 传统时间序列建模:这些研究涉及统计学和机器学习领域,开发了针对特定时间序列任务(如预测、分类、异常检测和插值)的神经架构。这些模型通常通过监督学习针对单一数据集进行训练。
- 基础模型(Foundation Models):这些模型在多个领域(包括语言建模和计算机视觉)中被广泛研究,它们在广泛的数据上进行训练,以便能够适应多样化的下游任务。在时间序列领域,一些研究尝试开发具有类似能力的模型,例如通过自监督预训练策略来促进有效的迁移学习。
- 提示学习(Prompt Learning):提示学习作为一种高效的任务适应方法,已经在大型神经网络中得到应用。在时间序列领域,TEMPO是一个例子,它引入了一组在推理时检索的学习提示。
- 时间序列的表示学习:一些研究专注于开发能够捕捉复杂时间序列信号的新架构,例如TimesNet,它使用基于傅里叶变换的多层次频率特征。
- 将大型语言模型重新编程为时间序列模型:一些研究尝试将大型预训练语言模型(如GPT-2)重新编程以适应时间序列任务,例如GPT4TS。
- 多任务学习:这些方法涉及使用单一模型处理多个任务,通常通过共享模型的某些部分(如特征提取器)并为每个任务训练特定的输出头。
- 零样本学习(Zero-Shot Learning):零样本学习允许模型在没有针对特定任务的训练数据的情况下进行推理。在时间序列领域,这通常涉及到在训练时未见过的任务上进行测试。
- 小样本学习(Few-Shot Learning):小样本学习关注如何在只有少量样本的情况下适应新任务。这在时间序列领域尤其重要,因为获取大量标注数据可能很困难。
这些相关研究为UniTS模型的开发提供了理论基础和技术背景。UniTS模型试图结合这些方法的优点,以实现对时间序列数据的统一处理。
Q: 论文如何解决这个问题?

(a)将 UniTS 模型与现有模型进行比较,在现有模型中,UniTS 模型可以处理不同的输入并实现多个时间序列任务; 以前的模型需要针对不同任务和输入数据集的单独模块。
(b)预测: 输入按文本中描述的方式进行token化,掩码token un-patchified以推断预测时间。(时间序列表示为patch级别)
©分类: CLS token用于表示类别信息,然后与类别token进行比较得到预测类别。
A: 论文通过开发UniTS(Unified Time Series)模型来解决上述问题,具体方法如下:
- 统一网络架构:UniTS采用了一个统一的网络架构,该架构能够处理多种时间序列任务,而不需要为每个任务设计特定的模块。这个架构通过共享参数来增强模型的泛化能力。
- 序列和变量的自注意力(MHSA):为了适应不同领域和任务的时间序列数据,UniTS在序列和变量维度上都使用了多头自注意力(MHSA)机制。这允许模型捕捉序列中的全局关系,同时处理不同长度和变量数量的时间序列。
- 动态线性操作(DyLinear):UniTS引入了动态线性操作器,这是一种简单而有效的模型密集关系的方法,能够适应不同长度的序列。这种操作器通过权重插值方案来处理序列长度的变化。
- 统一的掩码重构预训练:为了提高模型对生成和识别任务的适应性,UniTS采用了统一的掩码重构预训练方案。这种预训练方法利用了提示和CLS(分类)token的语义内容,以有效地重建掩码的时间序列部分。
- 多任务学习:UniTS通过多任务学习策略,使用单一模型处理多种任务。这种方法减少了对任务特定微调的需求,并展示了模型在不同领域和任务上的灵活性。
- 零样本、小样本和提示学习:UniTS展示了在新数据域和任务上的零样本、小样本和提示学习能力。这意味着模型可以在没有额外训练的情况下适应新任务,或者通过少量样本快速适应新任务。
- 数据集和任务的多样性:UniTS在38个多领域数据集上进行了评估,这些数据集涵盖了广泛的任务,如预测、分类、插值和异常检测。这证明了模型在处理不同类型时间序列数据时的泛化能力。
通过这些方法,UniTS能够在多个任务上实现竞争性能,同时保持对新任务的快速适应能力。这为时间序列分析领域提供了一个强大的通用模型。

类似于双塔模型:统一不同领域时间序列和任务种类。共享CLS塔和Mask塔将任务token转换为生成和分类的预测结果。(这图上下画反了。。)
Q: 论文做了哪些实验?


其中**Sup.**表示监督学习,Prompt表示提示学习

5个跨域数据集的预测零样本


A: 论文中进行了一系列的实验来评估UniTS模型的性能,主要包括以下几个方面:
- 多任务学习基准测试:UniTS与现有的时间序列方法进行了比较,包括iTransformer、TimesNet、PatchTST、Pyraformer和Autoformer等。这些比较在20个预测任务和18个分类任务上进行,以展示UniTS在不同任务上的性能。
- 零样本学习:UniTS在5个新的预测任务上进行了零样本学习测试,这些任务在预训练期间未见过。实验比较了UniTS与LLMTime模型的性能,后者是专门为零样本预测设计的大型语言模型。
- 小样本学习:在新的分类和预测任务上,UniTS进行了小样本学习实验。这些任务包括在新领域数据集上进行分类和预测,以及在训练数据有限的情况下进行插值和异常检测。
- 提示学习与监督学习的性能比较:通过使用固定预训练的UniTS模型,并仅通过适当的提示token来适应新任务,实验比较了提示学习与完全监督学习的性能。
- 消融研究:为了验证UniTS模型中关键设计的有效性,进行了消融研究。这包括对提示token数量、序列和变量MHSA、动态MLP层以及门控模块的影响进行评估。
- 预训练方案的影响:研究了统一掩码重构预训练方案对模型性能的影响,包括CLStoken和提示token的掩码重构损失。
- 模型大小对提示学习能力的影响:探讨了模型大小对UniTS在提示学习任务中性能的影响,包括在不同模型大小下的性能比较。
- 跨数据集的提示token相似性:分析了不同数据集之间提示token的相似性,以了解它们在任务需求上的共性。
- 分类任务的性能分层:在各个数据集上展示了UniTS在分类任务上的性能,以评估模型在不同领域的适用性。
这些实验结果表明,UniTS在多个任务和领域中展现出优越的性能,特别是在零样本、小样本和提示学习方面的能力。此外,消融研究进一步证实了模型设计中各个组件的重要性。
Q: 有什么可以进一步探索的点?
A: 尽管UniTS模型在多个方面取得了显著的成果,但仍有一些潜在的研究方向可以进一步探索:
- 更复杂的时间序列数据:UniTS可以在多领域数据集上进行评估,但可能还有更复杂的时间序列数据(如高维、非线性、非平稳时间序列)需要进一步测试和优化。
- 长期依赖性建模:时间序列数据可能包含长期依赖性,这是当前模型可能需要改进的地方。研究如何更好地捕捉和利用这些长期依赖性可能会提高模型的性能。
- 可解释性和可视化:提高模型的可解释性,使得用户可以理解模型是如何做出预测的,这对于实际应用至关重要。开发可视化工具和解释模型决策的方法可以增加用户对模型的信任。
- 实时数据流处理:UniTS目前主要处理静态数据集,但许多实际应用需要实时或近实时的预测。研究如何将UniTS应用于实时数据流,并处理潜在的延迟和数据不完整性问题。
- 跨领域迁移学习:尽管UniTS在多领域数据上表现良好,但进一步研究如何更有效地在不同领域之间迁移学习,以及如何利用领域知识来提高迁移效率和效果,仍然是一个有待探索的领域。
- 模型压缩和加速:为了在资源受限的环境中部署UniTS,研究模型压缩和加速技术,如知识蒸馏、模型剪枝和量化,可能是一个有价值的方向。
- 多模态时间序列分析:现实世界的时间序列数据往往是多模态的,例如结合了传感器数据、文本描述和图像信息。开发能够处理和整合多模态信息的统一模型可能会提高分析的准确性和稳健性。
- 不确定性估计:在时间序列预测中,提供预测的不确定性估计对于决策支持非常重要。研究如何量化模型预测的不确定性,并将其整合到最终的决策过程中。
- 模型稳健性:研究如何提高UniTS对异常值、噪声和对抗性攻击的稳健性,使其在面对现实世界数据的挑战时更加稳定。
通过探索这些方向,研究者可以进一步提高UniTS模型的性能,使其在更广泛的应用场景中发挥作用。
Q: 总结一下论文的主要内容
A: 这篇论文介绍了UniTS(Unified Time Series),这是一个统一的时间序列模型,旨在解决多任务学习和跨领域时间序列分析的挑战。以下是论文的主要内容总结:
- 问题背景:传统的时间序列模型通常针对特定任务进行训练,这限制了它们在新任务和新领域的适应性。为了克服这一限制,需要一个能够处理多种任务并适应不同领域数据的统一模型。
- UniTS模型:UniTS通过一个共享参数的统一网络架构来处理分类、预测、插值和异常检测等任务。它利用序列和变量的自注意力机制来捕捉时间序列数据的全局关系,并采用动态线性操作器来适应不同长度的序列。
- 统一任务规范:UniTS使用提示(prompt)框架将各种任务转换为统一的token表示,从而创建适用于所有任务的通用规范。这使得模型能够通过少量或无需额外训练即可适应新任务。
- 实验评估:UniTS在38个多领域数据集上进行了评估,展示了其在多任务学习、零样本学习、小样本学习和提示学习方面的能力。实验结果表明,UniTS在多个任务上优于现有的任务特定模型和基于自然语言的大型语言模型(LLMs)。
- 消融研究:通过消融研究,论文验证了UniTS中关键设计元素的有效性,包括提示token、自注意力机制、动态MLP层和门控模块。
- 代码和数据集:为了促进研究和应用,UniTS的源代码和数据集已经公开提供。
定模型和基于自然语言的大型语言模型(LLMs)。
5. 消融研究:通过消融研究,论文验证了UniTS中关键设计元素的有效性,包括提示token、自注意力机制、动态MLP层和门控模块。
6. 代码和数据集:为了促进研究和应用,UniTS的源代码和数据集已经公开提供。
总的来说,UniTS模型为时间序列分析领域提供了一个强大的通用模型,它在多个任务和领域中展现出优越的性能,并为未来的时间序列模型研究提供了新的方向。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 21
21 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)