【小白深度学习入门】【1】卷积神经网络CNN 结构、基本原理以及常见问题详解
【小白深度学习入门】【1】卷积神经网络CNN 结构、基本原理以及常见问题详解
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言
卷积神经网络(CNN)是一种常用于计算机视觉的深度学习神经网络架构。计算机视觉是人工智能的一个领域,它使计算机能够理解和解释图像或视觉数据。
在机器学习方面,人工神经网络表现非常出色。神经网络用于各种数据集,如图像、音频和文本。不同类型的神经网络用于不同的目的,例如,为了预测单词序列,我们使用循环神经网络,更准确地说是LSTM,同样,对于图像分类,我们使用卷积神经网络。在这篇博客中,我们将为 CNN 构建一个基本块。
在常规神经网络中,有三种类型的层:
- 输入层:这是我们向模型提供输入的层。此层中的神经元数量等于我们数据中的特征总数(图像中的像素数)。
- 隐藏层:输入层的输入随后被输入到隐藏层。根据我们的模型和数据大小,可以有许多隐藏层。每个隐藏层可以有不同数量的神经元,这些神经元通常大于特征的数量。每层的输出都是通过将前一层的输出与该层的可学习权重进行矩阵乘法计算得出的,然后加上可学习偏差,再加上激活函数,这使得网络呈非线性。
- 输出层:隐藏层的输出随后被输入到像 sigmoid 或 softmax 这样的逻辑函数中,该函数将每个类的输出转换为每个类的概率分数。
数据被输入到模型中,并从上述步骤中获得每一层的输出,这被称为[*前馈*],然后我们使用误差函数计算误差,一些常见的误差函数是交叉熵、平方损失误差等。误差函数衡量网络的运行情况。之后,我们通过计算导数反向传播到模型中。此步骤称为[*反向传播*],主要用于最小化损失。
卷积神经网络
卷积神经网络 (CNN) 是人工神经网络 (ANN)的扩展版本,主要用于从网格状矩阵数据集中提取特征。例如,数据模式发挥重要作用的图像或视频等视觉数据集。
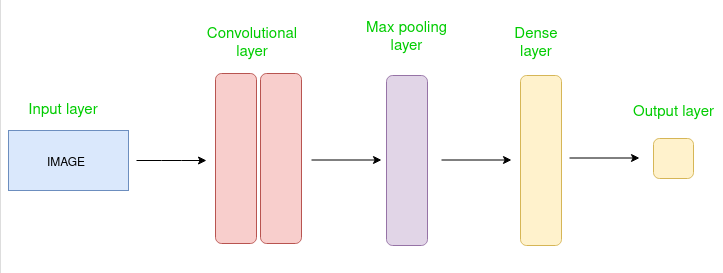
CNN 架构
卷积神经网络由多个层组成,如输入层、卷积层、池化层和全连接层。

卷积层对输入图像应用滤波器以提取特征,池化层对图像进行下采样以减少计算量,全连接层进行最终预测。网络通过反向传播和梯度下降来学习最佳滤波器。
卷积层的工作原理
卷积神经网络是共享参数的神经网络。假设您有一张图像。它可以表示为一个长方体,具有其长度、宽度(图像的尺寸)和高度(即通道,因为图像通常具有红色、绿色和蓝色通道)。

现在想象一下从这幅图像中取出一小块,并在其上运行一个小型神经网络(称为过滤器或内核),例如,有 K 个输出并垂直表示它们。现在将该神经网络滑过整个图像,结果,我们将得到另一幅具有不同宽度、高度和深度的图像。现在我们拥有的通道不只是 R、G 和 B 通道,而是更多通道,但宽度和高度更小。此操作称为卷积。如果补丁大小与图像大小相同,它将是一个常规神经网络。由于这个小补丁,我们的权重更少。

现在让我们讨论一下整个卷积过程中涉及的一些数学知识。
- 卷积层由一组可学习的过滤器(或核)组成,这些过滤器具有较小的宽度和高度,并且深度与输入量相同(如果输入层是图像输入,则深度为 3)。
- 例如,如果我们要对尺寸为 34x34x3 的图像进行卷积。过滤器的可能大小可以是 axax3,其中“a”可以是 3、5 或 7 之类的任何值,但与图像尺寸相比要小一些。
- 在前向传递过程中,我们逐步将每个过滤器滑动到整个输入量上,其中每个步骤称为*步幅*(对于高维图像,其值可以是 2、3 甚至 4),并计算核权重和输入量的补丁之间的点积。
- 当我们滑动过滤器时,我们将获得每个过滤器的 2-D 输出,然后将它们堆叠在一起,这样我们将获得深度等于过滤器数量的输出量。网络将学习所有过滤器。
用于构建卷积神经网络的层
完整的卷积神经网络架构也称为 convnets。convnets 是一系列层,每个层通过可微分函数将一个体积转换为另一个体积。
*层的类型:* 数据集
让我们以在尺寸为 32 x 32 x 3 的图像上运行 covnets 为例。
- 输入层:这是我们向模型提供输入的层。在 CNN 中,输入通常是图像或图像序列。此层保存宽度为 32、高度为 32、深度为 3 的图像的原始输入。
- 卷积层:此层用于从输入数据集中提取特征。它将一组可学习的过滤器(称为内核)应用于输入图像。过滤器/内核是较小的矩阵,通常为 2×2、3×3 或 5×5 形状。它在输入图像数据上滑动并计算内核权重与相应输入图像块之间的点积。此层的输出称为特征图。假设我们为该层使用总共 12 个过滤器,我们将获得尺寸为 32 x 32 x 12 的输出体积。
- 激活层:通过在前一层的输出中添加激活函数,激活层为网络添加了非线性。它将逐元素激活函数应用于卷积层的输出。一些常见的激活函数是****RELU****:max(0, x)、 *Tanh*、 ****Leaky RELU****等。体积保持不变,因此输出体积的尺寸为 32 x 32 x 12。
- 池化层:该层定期插入到 covnet 中,其主要功能是减小体积,从而加快计算速度、减少内存并防止过度拟合。两种常见的池化层类型是****最大池化*和*平均池化****。如果我们使用具有 2 x 2 个过滤器和步长为 2 的最大池化,则生成的体积将为 16x16x12。

- 平坦化:经过卷积层和池化层之后,生成的特征图被平坦化为一维向量,以便可以将它们传递到完全链接层进行分类或回归。
- 全连接层:它获取来自前一层的输入并计算最终的分类或回归任务。

- 输出层:完全连接层的输出随后被输入到用于分类任务的逻辑函数中,例如 sigmoid 或 softmax,它将每个类的输出转换为每个类的概率分数。
例子:
让我们考虑一幅图像,并应用卷积层、激活层和池化层操作来提取内部特征,并且做可视化。
输入图像:

基本步骤:
- 导入必要的库
- 设置参数
- 定义内核
- 加载图像并绘制。
- 重新格式化图像
- 应用卷积层操作并绘制输出图像。
- 应用激活层操作并绘制输出图像。
- 应用池化层操作并绘制输出图像。
# import the necessary libraries
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from itertools import product
# set the param
plt.rc('figure', autolayout=True)
plt.rc('image', cmap='magma')
# define the kernel
kernel = tf.constant([[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
])
# load the image
image = tf.io.read_file('Ganesh.jpg')
image = tf.io.decode_jpeg(image, channels=1)
image = tf.image.resize(image, size=[300, 300])
# plot the image
img = tf.squeeze(image).numpy()
plt.figure(figsize=(5, 5))
plt.imshow(img, cmap='gray')
plt.axis('off')
plt.title('Original Gray Scale image')
plt.show();
# Reformat
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.expand_dims(image, axis=0)
kernel = tf.reshape(kernel, [*kernel.shape, 1, 1])
kernel = tf.cast(kernel, dtype=tf.float32)
# convolution layer
conv_fn = tf.nn.conv2d
image_filter = conv_fn(
input=image,
filters=kernel,
strides=1, # or (1, 1)
padding='SAME',
)
plt.figure(figsize=(15, 5))
# Plot the convolved image
plt.subplot(1, 3, 1)
plt.imshow(
tf.squeeze(image_filter)
)
plt.axis('off')
plt.title('Convolution')
# activation layer
relu_fn = tf.nn.relu
# Image detection
image_detect = relu_fn(image_filter)
plt.subplot(1, 3, 2)
plt.imshow(
# Reformat for plotting
tf.squeeze(image_detect)
)
plt.axis('off')
plt.title('Activation')
# Pooling layer
pool = tf.nn.pool
image_condense = pool(input=image_detect,
window_shape=(2, 2),
pooling_type='MAX',
strides=(2, 2),
padding='SAME',
)
plt.subplot(1, 3, 3)
plt.imshow(tf.squeeze(image_condense))
plt.axis('off')
plt.title('Pooling')
plt.show()
*输出*:


卷积神经网络(CNN)的优点:
- 擅长检测图像、视频和音频信号中的模式和特征。
- 对于平移、旋转和缩放不变性具有鲁棒性。
- 端到端训练,无需手动提取特征。
- 可以处理大量数据并达到高精度。
卷积神经网络(CNN)的缺点:
- 训练的计算成本很高,并且需要大量内存。
- 如果数据不足或没有使用适当的正则化,则容易过度拟合。
- 需要大量标记数据。
- 可解释性有限,很难理解网络学到了什么。
常见问题 (FAQ)
1:什么是卷积神经网络(CNN)?\
卷积神经网络 (CNN) 是一种深度学习神经网络,非常适合图像和视频分析。CNN 使用一系列卷积层和池化层从图像和视频中提取特征,然后使用这些特征对物体或场景进行分类或检测。
2:CNN 如何工作?
CNN 的工作原理是将一系列卷积层和池化层应用于输入图像或视频。卷积层通过在图像或视频上滑动一个小过滤器或内核并计算过滤器和输入之间的点积来从输入中提取特征。然后,池化层对卷积层的输出进行下采样,以降低数据的维度并提高计算效率。
3:CNN 中使用哪些常见的激活函数?
CNN 中使用的一些常见激活函数包括:
- 整流线性单元 (ReLU):ReLU 是一种非饱和激活函数,计算效率高且易于训练。
- 泄漏整流线性单元 (Leaky ReLU):泄漏 ReLU 是 ReLU 的一个变体,允许少量负梯度流过网络。这有助于防止网络在训练期间死亡。
- 参数整流线性单元 (PReLU):PReLU 是 Leaky ReLU 的泛化,允许学习负梯度的斜率。
4:在CNN中使用多个卷积层的目的是什么?
在 CNN 中使用多个卷积层可让网络从输入图像或视频中学习越来越复杂的特征。第一个卷积层学习简单的特征,例如边缘和角落。更深的卷积层学习更复杂的特征,例如形状和物体。
5:CNN 中使用了哪些常见的正则化技术?
正则化技术用于防止 CNN 过度拟合训练数据。CNN 中使用的一些常见正则化技术包括:
- Dropout:Dropout 在训练期间随机从网络中丢弃神经元。这迫使网络学习不依赖于任何单个神经元的更强大的特征。
- L1 正则化:L1 正则化对网络中权重的绝对值进行正则化。这有助于减少权重数量并提高网络效率。
- L2 正则化:L2 正则化对网络中权重的平方进行正则化。这也有助于减少权重数量并提高网络效率。
6:卷积层和池化层有什么区别?
卷积层从输入图像或视频中提取特征,而池化层则对卷积层的输出进行下采样。卷积层使用一系列过滤器来提取特征,而池化层使用各种技术对数据进行下采样,例如最大池化和平均池化。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 15
15 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)