Query Rewrite —— 基于大模型的query扩展改写,PRF+ GRF协同发力减少LLM的幻觉问题(论文)
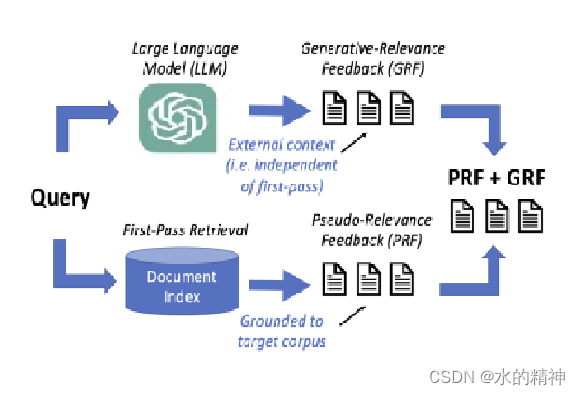
(伪相关反馈)为了解决模型的幻觉问题,在改写前,先拿原始query去进行一次query,然后将召回的数据作为参考内容,送给模型,根据这些内容重新生成query。优势:可以一定程度上解决模型幻觉问题,有效解决解决词汇表不匹配问题。毕竟是根据query召回的内容去生成query的。劣势:这将会很依赖首次的检索,如果召回的数据质量很差,就GG了。(生成相关反馈)最近关于生成相关性反馈(GRF)的研究表明
通过GRF和PRF,可以有效提升召回率,和top的数据质量。两者可以相互互补,发挥更好的作用。
论文:Generative and Pseudo-Relevant Feedback for Sparse, Dense and Learned Sparse Retrieval
什么是PRF ?
什么是GRF
更好的解决在改写过程中模型的幻觉问题

论文中的核心思想
论文:Generative and Pseudo-Relevant Feedback for Sparse, Dense and Learned Sparse Retrieval
论文中阐述了PRF和GRF的不同。用实验数据证明了GRF在召回率提升方面,比PRF好10%左右。 但是PRF + GRF 能带来1+1 大于2的效果。
论文中阐述了GRF的实现细节
GRF如何使用
先用LLM针对query生成K条数据,注意是不同主题方向的数据,从而避免同质化的问题。对于向量检索。论文中给出的query和K条数据的融合方式是,先算K条数据向量的平均值。然后query的向量占一定比例。再和k条数据的平均值向量融合,各自占不同的比例。
对密集的GRF采用Rocchio PRF方法[19],以允许查询向量和反馈向量的不同权重。这允许嵌入llm生成的文本,以一种可控的方式上下文化查询向量。具体来说,公式1表明,新的向量,®𝐺𝑅𝐹,是原始查询向量,®𝑄,和生成的文档向量,®𝐷𝐿𝐿𝑀=1/𝑘×(®𝐷𝐿𝐿𝑀1+®𝐷𝐿𝐿𝑀2+...+®𝐷𝐿𝐿𝑀𝑘).的均值的组合我们包括𝛼和𝛽来衡量查询和GRF向量的相对重要性。
但是我觉得这篇论文,对GRF的阐述不够清晰。请看这篇文章,会有更清晰的理解。Query Rewrite —— 基于大模型的query扩展改写,通过GRM减少LLM的幻觉问题(论文)-CSDN博客
GRF 如何和 PRF融合
论文提出了加权倒易秩融合方法(WRRF),该方法结合了GRF和PRF(PRF+GRF)。公式如下:

WRRF使用一个评分公式𝑟(𝑑),基于文档在特定运行中的排名。有一组要排序的文档𝐷,一组排名𝑅,以及𝑘参数,这样低排名的文档信号就不会消失(默认值通常是60,这里就是召回多少条数据)。我们添加了一个超参数𝜆,它加权了伪相关文档排名的相对重要性,𝑟∈𝑅𝑃𝑅𝐹,和(1−𝜆)的生成文档排名,𝑟∈𝑅𝑃𝑅𝐹。
超参数𝜆是决定PRF和GRF权重占比的参数。论文中给到的𝜆取值范围是[0.2,0.5],具体可以再调试,会有不同的效果。𝜆不同取值的召回率对比如下图。

GRF效果如何?
从论文中,可以看到GRF整提效果都要好于PRF,不挂失在向量检索下还是在BM25检索场景下。

测试项说明
BM25 [ 41 ]: Sparse retrieval method where 𝑘 1 parameter was tunedbetween 0.1 and 5.0 using a step size of 0.2, while 𝑏 was tunedbetween 0.1 and 1.0 with a step size of 0.1, as described earlier.BM25+Relevance Model (RM3) [ 1 ]: We tune 𝑓 𝑏 _ 𝑡𝑒𝑟𝑚𝑠 (between10 and 100 with a step of 10), 𝑓 𝑏 _ 𝑑𝑜𝑐𝑠 (between 10 and 100 with astep of 10), and 𝑜𝑟𝑖𝑔𝑖𝑛𝑎𝑙 _ 𝑞𝑢𝑒𝑟𝑦 _ 𝑤𝑒𝑖𝑔ℎ𝑡 (between 0.1 and 0.9 witha step of 0.1).ColBERT-TCT (TCT) [ 22 ]: is a dense retrieval model incorporating knowledge distillation over ColBERT [ 16 ]. We employ TCTColBERT-v2-HNP’s MS MARCO [ 36 ] model and use a max-passageapproach to convert our passage runs into document runs. ForColBERT-TCT+PRF (TCT+PRF) [ 18 ], we tune Rocchio PRF parameters: 𝑑𝑒𝑝𝑡ℎ (2,3,5,7,10,17), 𝛼 (between 0.1 and 0.9 with a stepof 0.1, and 𝛽 (between 0.1 and 0.9 with a step of 0.1).SPLADE [ 12 ]: is a neural retrieval model which learns sparsequery and document weightings via the BERT MLM head andsparse regularization. We index the term vectors using Pyserini[20] and use their “impact” searcher for max-passage aggregation.For SPLADE+RM3 , we tune 𝑓 𝑏 _ 𝑑𝑜𝑐𝑠 (5,10,15,20,25,30) 𝑓 𝑏 _ 𝑡𝑒𝑟𝑚𝑠(20,40,60,80,100), and 𝑜𝑟𝑖𝑔𝑖𝑛𝑎𝑙 _ 𝑞𝑢𝑒𝑟𝑦 _ 𝑤𝑒𝑖𝑔ℎ𝑡 (between 0.1 and 0.9with a step of 0.1).ColBERT [16] & ColBERT+PRF [ 46 ]: We use the runs providedby Wang et al. [47], which use pyterrier framework [26].
GRF + PRF 效果如何?
从下图我们可以看到,GRF + PRF同时使用,几乎总能带来正面的召回率提升效果。


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 31
31 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)