2024 [arXiv] ST-LLM——时空大语言模型用于交通预测
近期,大型语言模型(LLMs)在时间序列分析中显示出卓越能力。不同于现有模型,LLMs主要通过参数扩展和广泛的预训练在保持其基本结构的同时取得进步。本文提出了一种用于交通预测的空间-时间大型语言模型(ST-LLM)。具体来说,ST-LLM将每个地点的时间步骤重新定义为标记,并融入空间-时间嵌入模块来学习标记的空间位置和全局时间表征。然后,这些表征被融合,为每个标记提供统一的空间和时间信息。此外,我
这应该是第一个将LLM用于交通预测(时空图预测),这篇由南洋理工大学龙程(Cheng Long)老师团队与商汤,北大和德国科隆大学(Cologne)合作完成。且抢先使用了最通用的名字时空大模型名字——ST-LLM。
论文标题:Spatial-Temporal Large Language Model for Traffic Prediction
论文链接:https://arxiv.org/abs/2401.10134
作者:Chenxi Liu, Sun Yang, Qianxiong Xu, Zhishuai Li, Cheng Long, Ziyue Li, Rui Zhao
关键词:交通预测,LLM,少样本,零样本
Cool Paper:https://papers.cool/arxiv/2401.10134
摘要:交通预测是智能交通系统的关键组成部分,旨在利用历史数据预测特定地点的未来交通状况。尽管现有的交通预测模型通常强调开发复杂的神经网络结构,但其准确性并未相应提高。近期,大型语言模型(LLMs)在时间序列分析中显示出卓越能力。不同于现有模型,LLMs主要通过参数扩展和广泛的预训练在保持其基本结构的同时取得进步。本文提出了一种用于交通预测的空间-时间大型语言模型(ST-LLM)。具体来说,ST-LLM将每个地点的时间步骤重新定义为标记,并融入空间-时间嵌入模块来学习标记的空间位置和全局时间表征。然后,这些表征被融合,为每个标记提供统一的空间和时间信息。此外,我们提出了一种新颖的LLM部分冻结注意力策略,旨在捕捉交通预测的空间-时间依赖性。在真实交通数据集上的全面实验表明,ST-LLM优于最先进的模型。值得注意的是,ST-LLM在少样本和零样本预测场景中也表现出强大的稳健性。
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是交通预测的准确性问题。交通预测是智能交通系统的关键组成部分,它旨在利用历史数据预测特定位置的未来交通状况。尽管现有的交通预测模型经常强调开发复杂的神经网络结构,但它们的准确性并没有相应提高。论文中指出,现有的模型在捕捉交通数据中的时空依赖性方面存在挑战,特别是对于CNNs和RNNs来说,它们在捕捉空间和时间依赖性方面表现不佳。此外,现有的大型语言模型(LLMs)在时间序列分析方面表现出色,但在交通预测任务中,它们通常只关注数据的时间方面,而忽视了空间方面。
为了解决这些问题,论文提出了一种新的时空大型语言模型(ST-LLM),该模型通过将每个位置的时间步重新定义为标记,并结合时空嵌入模块来学习标记的空间位置和全局时间表示。此外,还提出了一种新的部分冻结注意力策略,旨在捕捉交通预测中的时空依赖性。通过在真实交通数据集上的综合实验,论文证明了ST-LLM优于现有最先进的模型,并且在少样本和零样本预测场景中也表现出强大的性能。
Q: 有哪些相关研究?
A: 在这篇论文中,提到了以下几类相关的研究工作:
- 大型语言模型(LLMs)在时间序列分析中的应用:近年来,LLMs在时间序列分析任务上表现出色,例如预测、分类、异常检测、插值、少样本学习和零样本学习等。例如,TEMPO-GPT(ICLR 2024)通过结合提示工程和季节性趋势分解在生成预训练变换器(GPT)中进行时间序列预测。TIME-LLM(ICLR 2024)重新编程LLM进行时间序列预测,而保持其基础语言模型不变。OFA(NeurIPS 2023)在时间序列分析的各种关键任务中使用冻结的GPT2模型,作者得出结论,LLM在时间序列分析任务上表现更好。
- 交通预测:交通预测旨在基于历史交通数据预测未来的交通流量或速度,这对智能交通系统至关重要。传统的交通预测模型基于统计方法,如ARIMA和卡尔曼滤波器。然而,这些模型由于交通数据的固有时空依赖性而表现不佳。后来,许多努力致力于通过开发各种基于神经网络的模型来推进交通预测技术。首先,卷积神经网络(CNNs)被应用于交通数据以捕捉数据中的空间依赖性。然后,基于图卷积网络(GCN)的模型因其置换不变性、局部连接性和组合性而变得流行。最近,基于注意力的模型已成为主导趋势,它们可以有效地建模动态空间相关性,而不考虑邻接矩阵。
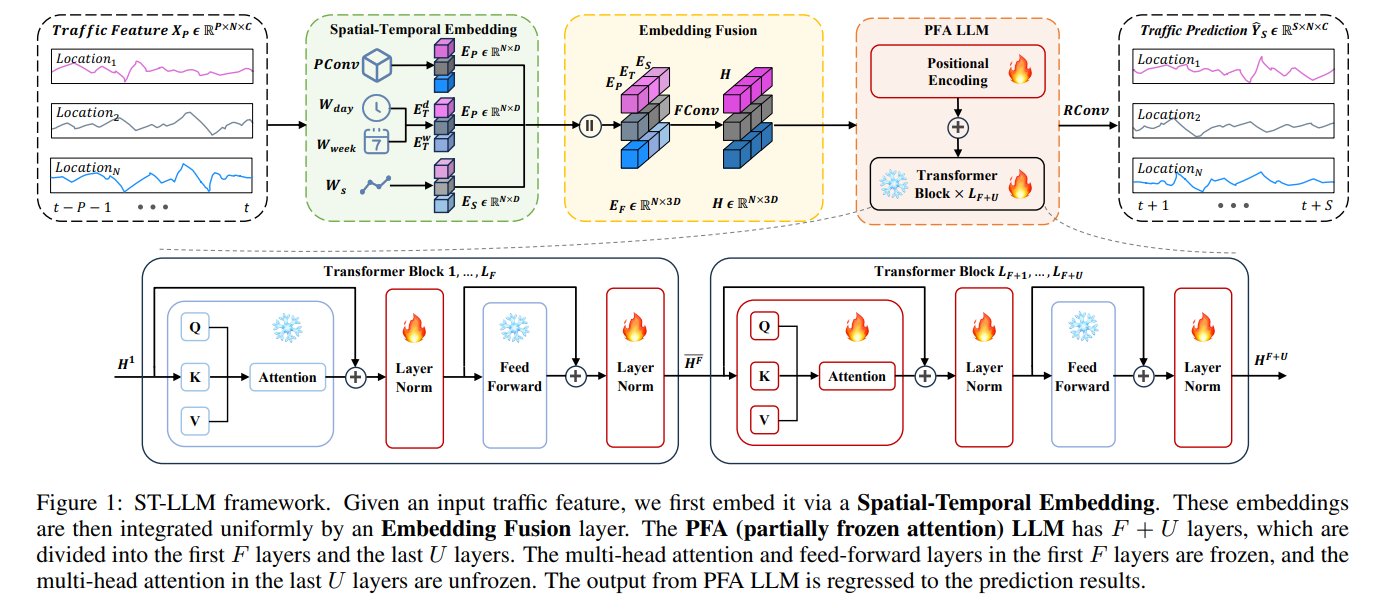
- 时空嵌入和融合:为了改进LLMs以适应交通预测任务,论文提出了一种时空嵌入和融合的方法。这包括将时间步重新定义为标记,并通过专门的时空嵌入层将每个标记嵌入,以强调时空相关性,如空间相关性和时间模式。然后,通过融合卷积将这些表示集成到统一的方式中。
- 部分冻结注意力(PFA)LLM:为了解决FPT LLM在交通预测任务中性能不佳的问题,论文提出了部分冻结注意力(PFA)LLM,这是一种专门设计用于增强交通预测的模型。通过部分冻结多头注意力,ST-LLM能够适应交通预测,同时保留预训练期间获得的基础知识。
这些相关研究为ST-LLM的发展提供了理论基础和技术支持,同时也为比较和评估ST-LLM的性能提供了基准。
问题定义
交通特征: X ∈ R T × N × C X\in \mathbb{R}^{T\times N\times C} X∈RT×N×C
交通预测:给定
P
P
P个历史时间步数据,预测未来
S
S
S步。
[
X
t
−
P
+
1
,
X
t
−
P
+
2
,
…
,
X
t
]
⟶
f
(
⋅
)
θ
[
Y
t
+
1
,
Y
t
+
2
,
…
,
Y
t
+
S
]
\left[\mathbf{X}_{t-P+1}, \mathbf{X}_{t-P+2}, \ldots, \mathbf{X}_{t}\right] \underset{\theta}{\stackrel{f(\cdot)}{\longrightarrow}}\left[\mathbf{Y}_{t+1}, \mathbf{Y}_{t+2}, \ldots, \mathbf{Y}_{t+S}\right]
[Xt−P+1,Xt−P+2,…,Xt]θ⟶f(⋅)[Yt+1,Yt+2,…,Yt+S]
Q: 论文如何解决这个问题?
A: 论文提出了一个名为Spatial-Temporal Large Language Model (ST-LLM) 的新框架来解决交通预测的准确性问题。这个框架通过以下几个关键步骤来解决这个问题:
- 时空嵌入:论文首先将每个位置的时间步重新定义为标记,并使用一个专门的时空嵌入层来学习这些标记的空间位置和全局时间表示。这包括空间相关性、小时和星期几的模式以及标记信息。
- 融合卷积:接着,使用融合卷积(FConv)将这些表示集成到一个统一的方式中,从而为每个标记提供统一的时空信息。
- 部分冻结注意力(PFA)LLM:论文提出了一种新的部分冻结注意力(PFA)LLM策略,这是专门为了增强交通预测而设计的。在这种策略中,前F层的多头注意力和前馈层被冻结以保留预训练的知识,而最后U层的多头注意力层被解冻以增强模型捕捉不同标记之间时空依赖性的能力。
- 回归卷积:最后,将PFA LLM的输出输入到一个回归卷积层(RConv),以预测接下来的交通数据。
- 实验验证:在真实交通数据集上进行的广泛实验表明,ST-LLM在各种设置下都优于现有最先进的模型。特别是在少样本和零样本预测场景中,ST-LLM表现出了在领域内和领域间知识迁移的能力。
通过这些方法,ST-LLM能够有效地捕捉交通数据中的时空依赖性,并在交通预测任务中取得了优越的性能。
从模型图来看,训练策略和时序的大模型基本类似,冻结参数,只训练位置编码,对于Transformer的训练:层归一化(Layer Norm),前F层,多头注意力冻结;后U层,多头注意力不冻结,进行训练。

Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证提出的Spatial-Temporal Large Language Model (ST-LLM)的性能:
- 数据集:使用了四个真实世界的交通数据集进行实验,包括NYCTaxi、CHBike、METR-LA和PEMS-BAY。这些数据集涵盖了不同类型的交通流量数据(如出租车的上下车)和交通速度数据。
- 基线模型:与10个基线模型进行了比较,这些模型包括基于图神经网络(GNN)的模型、基于注意力的模型以及基于大型语言模型(LLM)的模型。这些基线模型覆盖了不同的方法,并已被广泛用于时空预测任务。
- 实现细节:详细描述了数据集的划分方式、训练和验证集的比例、历史时间步(P)和未来时间步(S)的设置、一周的天数(Tw)、时间间隔(Td)以及实验的硬件配置。
- 评估指标:使用了四个评估指标来衡量模型的预测性能,包括平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方根误差(RMSE)和加权绝对百分比误差(WAPE)。
- 结果和分析:通过与基线模型的比较,展示了ST-LLM在不同交通预测场景中的优越性能。特别是在交通速度预测场景中,ST-LLM的表现尤为突出。
- 消融研究:进行了消融研究来分析ST-LLM中不同组件的影响,包括是否包含LLM、是否包含时空嵌入(ST)、是否包含时间嵌入(T)以及是否包含空间嵌入(S)。
- 参数分析:分析了在ST-LLM框架中,决定解冻多头注意力层数的超参数U对模型性能的影响。
- 少样本预测:在只有10%数据的情况下训练模型,以评估ST-LLM在有限数据下识别复杂模式的能力。
- 零样本预测:评估模型在没有对特定数据集进行过训练的情况下的跨数据集适应能力,即零样本预测。
这些实验全面验证了ST-LLM在交通预测任务中的有效性和稳健性,并与现有的先进模型进行了比较。(主要还是网格流量数据,出度和入度)




Q: 有什么可以进一步探索的点?
A: 论文中提到了未来工作的几个潜在方向,可以进一步探索:
- 额外任务:研究ST-LLM在其他任务上的应用,如交通插补(imputation)。这可能需要对模型进行调整以适应不同类型的输入数据和预测目标。
- 内存效率:开发针对交通数据分析的内存高效LLM。这可能涉及到模型压缩、蒸馏或者设计更轻量级的模型结构,以便在资源受限的环境中部署。
- 模型泛化能力:进一步研究ST-LLM在不同领域和场景下的泛化能力。这可能包括在更多样化的数据集上进行训练和测试,以及探索模型在新领域中的适应性。
- 实时预测:研究ST-LLM在实时交通预测中的应用,这可能需要对模型进行优化以减少推理时间,并提高在线预测的准确性。
- 多模态数据融合:探索将ST-LLM与其他类型的数据(如图像、传感器数据等)结合起来进行多模态交通预测。这可能需要开发新的融合策略以整合不同类型的信息。
- 可解释性:提高ST-LLM的可解释性,以便更好地理解模型的预测过程和决策依据。这可能涉及到可视化技术或者可解释性模型的开发。
- 模型稳健性:研究ST-LLM在面对数据噪声、异常值或者模型参数扰动时的稳健性。这可能需要设计新的正则化方法或者稳健性损失函数。
- 模型训练策略:探索不同的训练策略,如迁移学习、元学习或者在线学习,以提高模型在不断变化的交通环境中的适应性和性能。
通过这些方向的进一步研究,可以不断提升ST-LLM在交通预测领域的应用价值和实用性。
Q: 总结一下论文的主要内容
A: 这篇论文提出了一种名为Spatial-Temporal Large Language Model (ST-LLM)的新框架,用于交通预测。以下是论文的主要内容总结:
背景:
- 交通预测是智能交通系统的关键组成部分,它利用历史数据预测特定位置的未来交通状况。
- 现有的交通预测模型在捕捉时空依赖性方面存在挑战,尤其是CNNs和RNNs。
- 大型语言模型(LLMs)在时间序列分析中表现出色,但在交通预测中通常只关注数据的时间方面。
提出的问题:
- 现有的LLMs在交通预测任务中主要通过参数扩展和预训练来发展,但它们在空间方面的处理不足。
解决方案:
- 提出了ST-LLM框架,它通过将每个位置的时间步重新定义为标记,并结合时空嵌入模块来学习标记的空间位置和全局时间表示。
- 提出了一种新的部分冻结注意力(PFA)LLM策略,以捕捉交通预测中的时空依赖性。
实验:
- 在真实世界的交通数据集(NYCTaxi、CHBike、METR-LA和PEMS-BAY)上进行了广泛的实验。
- ST-LLM在各种设置下都优于现有的最先进的模型,尤其在少样本和零样本预测场景中表现出色。
贡献:
- 提出了ST-LLM,一个用于交通预测的新型时空大型语言模型。
- 提出了PFA策略,一种新的LLM策略,专门设计用于增强交通预测。
- 在真实交通数据集上的实验验证了ST-LLM的有效性。
未来工作:
- 探索ST-LLM在其他任务(如交通插补)中的应用。
- 开发针对交通数据分析的内存高效LLM。
- 研究ST-LLM在不同领域和场景下的泛化能力。
- 提高ST-LLM的实时预测能力。
- 探索将ST-LLM与其他类型的数据结合起来进行多模态交通预测。
- 提高ST-LLM的可解释性和稳健性。
交通插补)中的应用。 - 开发针对交通数据分析的内存高效LLM。
- 研究ST-LLM在不同领域和场景下的泛化能力。
- 提高ST-LLM的实时预测能力。
- 探索将ST-LLM与其他类型的数据结合起来进行多模态交通预测。
- 提高ST-LLM的可解释性和稳健性。
- 探索不同的训练策略以提高模型的适应性和性能。
欢迎关注公众号“时空探索之旅”


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 18
18 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)