最全面又最浅显易懂的Langchain快速上手教程
根据上述的理解,对LangChain核心模块的总结如下所示LCEL(LangChain Expression Language)是一种构建复杂链的简便方法,语法是使用或运算符自动创建Chain后,即可完成链式操作。这在背后的原理是python的__ror__魔术函数,比如就相当于。下面看一个简单的LCEL代码,按照传统的方式创建,然后再使用或运算符创建了一个Chain,它自动把这3个组件链接在了一
三. 深入Langchain
1. 架构设计
从上文知道Langchain在架构上使用了从抽象、到具体、再到整合适配的三层架构,这种一层一层逐渐具体的设计最大可能性的保证了架构的可扩展性和维护性。同时这种设计也说明其实每一层架构其实是类似的,无非是一层一层逐渐把抽象的设计实现出来而已。

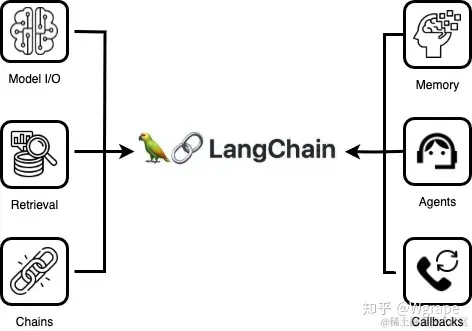
2. 核心模块
(1) Model I/O
Model指LLM大模型,I/O指输入输出系统。所以Model I/O 顾名思义是指以LLM大模型为核心的输入输出系统,如下图所示


① Chat Models/LLMs (Model)
Model即LLM大语言模型,从源码中可以看出来它主要分为Chat Models和LLMs两种类型。

截屏2024-02-22 14 48 23
看到这里,心里一定会有疑问,Model不就是只有LLM大语言模型这一种吗,怎么还会出现Chat Models这种模型呢,它和LLM的关系又是什么呢?
其实这个问题非常容易理解,首先LLM大模型语言就是如GPT模型这种,一般都是生成式的模型,所以应用场景主要用于比如回答问题、聊天对话、生成图片等AIGC的场景。也就是说LLM模型是同时支持回答问题(单轮)和聊天对话(多轮)的,虽然底层都是只使用了这一个LLM模型,但是它确实是提供了这两种不同的聊天能力,只需要向LLM输入不同的内容即可。
所以为了方便使用LLM模型的单轮和多轮的问题回答能力,Langchain提供了这两种不同的Model,与其说是不同的Model,倒不如说是同一个Model(LLM模型)下两种不同的使用方式,而且这两种使用方式都是抽象的接口,以便接入不同的LLM大语言模型供应商(比如OpenAI、Google等)。

- LLMs: 主要用于单轮的问题回答处理,输出和输出的数据格式都是
string即字符串 - Chat Model: 主要用于多轮的对话处理,输入和输出的数据格式都是
List[BaseMessage]即消息数组,BaseMessage消息主要包括AIMessage/HumanMessage/SystemMessage这三种类型
# 创建一个llm类型的model并开始询问
from langchain_openai import OpenAI
llm = OpenAI(openai_api_key="...")
llm.invoke("1 + 1 = ?")
# 创建一个chat model类型的model并开始对话
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(openai_api_key="...")
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="You're good at math"),
HumanMessage(content="1 + 1 = ?"),
]
chat.invoke(messages)
② Prompts (Input)
在 NLP 领域,Prompt(提示)是一种用于引导预训练语言模型解决特定任务的方法。它通常是一段文本,用于构建问题或任务的描述,以便预训练语言模型可以根据其内在知识生成合适的输出。

在Langchain中,Prompt具体是指向大语言模型LLM发起的一组指令或输入,用于引导LLM的响应。它的目标是建立与模型无关的跨语言、跨平台、跨模型的通用性Prompt系统。
根据Model类型的不同,Prompt也主要分为PromptTemplate和ChatPromptTemplate两种。
- PromptTemplate :先使用
from_template()方法创建一个模板,支持传递任意数量的变量,然后使用format()方法格式化即可。 - ChatPromptTemplate :显示
from_messages()方法创建一个消息列表,然后再在消息列表中组装不同类型的BaseMessage类型即可。

截屏2024-02-22 15 48 19
from langchain.prompts import PromptTemplate
# ====================== PromptTemplate ======================
# Prompt中有多个变量
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
# 输出: Tell me a funny joke about math.
print(prompt_template.format(adjective="funny", content="math"))
# Prompt中没有任何变量
prompt_template = PromptTemplate.from_template("Tell me a joke")
# 输出: Tell me a joke
prompt = prompt_template.format()
print(prompt)
# 调用llm模型输出: Why couldn't the bicycle stand up by itself? Because it was two-tired.
from langchain_openai import OpenAI
llm = OpenAI()
print(llm.invoke(prompt))
# ====================== ChatPromptTemplate ======================
from langchain_core.prompts import ChatPromptTemplate
# 第1种
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are good at math. Your name is {name}."),
("human", "please help me, my question is: {user_input}"),
]
)
# 输出: [SystemMessage(content='You are good at math. Your name is GaoSi.'), HumanMessage(content='please help me, my question is: 1 + 1 = ?')]
messages = chat_template.format_messages(name="GaoSi", user_input="1 + 1 = ?")
print(messages)
# 第2种
from langchain.prompts import HumanMessagePromptTemplate
from langchain_core.messages import SystemMessage
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are good at math."
"Your name is GaoSi."
)
),
HumanMessagePromptTemplate.from_template("please help me, my question is: {user_input}"),
]
)
# 输出: [SystemMessage(content='You are good at math.Your name is GaoSi.'), HumanMessage(content='please help me, my question is: 1 + 1 = ?')]
messages = chat_template.format_messages(user_input="1 + 1 = ?")
print(messages)
# 调用chat模型输出: content='1 + 1 = 2'
from langchain_openai import ChatOpenAI
chat = ChatOpenAI()
print(chat.invoke(messages))
③ Output Parsers (Output)
比如最常见的对Model输出做JSON化处理场景,如下所示。

如果需要流式输出,使用chain.stream()即可,需要注意的是使用前需要确认具体的某个Output Parser是否支持流式输出功能。

# 创建Model
from langchain_openai import ChatOpenAI
model = ChatOpenAI()
# 创建output_parser(输出)
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
class MathProblem(BaseModel):
question: str = Field(description="the question")
answer: str = Field(description="the answer of question")
steps: str = Field(description="the resolve steps of question")
output_parser = JsonOutputParser(pydantic_object=MathProblem)
# 创建prompt(输入)
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="You are good at math, please answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
# 创建Chain并链式调用
chain = prompt | model | output_parser
print(chain.invoke({"query": "1+1=?"}))
# 使用流式输出
for s in chain.stream({"query": "1+1=?"}):
print(s)
(2) Memory
Memory在LLM技术领域中称为记忆,为了方便理解,下面会称为内存,知晓即可
从上文的Prompts部分,我们知道根据Model类型的不同,将Prompt分为了单轮对话的PromptTemplate和多轮对话的ChatPromptTemplate两种类型。在这里强调了下单轮对话和多轮对话这两个概念,可以猜到用意吗?没错 !本章要讲的Memory其实就是针对于多轮对话的场景,因为在单轮对话下是没有使用Memory需求的。

① 简单的例子 Chat Messages
ChatMessageHistory是一个非常轻量的用于存取HumanMessages/AIMessages等消息的工具类。
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")
# [HumanMessage(content='hi!', additional_kwargs={}), AIMessage(content='whats up?', additional_kwargs={})]
print(history.messages)
② 内存的类型
内存分为Short-term短期存储和Long-term长期存储。
- Conversation Buffer :无窗口的会话缓冲
- Conversation Buffer Window :有窗口的会话缓冲
- Conversation Summary :无窗口的会话摘要(摘要是指对内容的总结压缩,而非全部)
- Conversation Summary Buffer :有窗口的会话摘要
- Conversation Token Buffer :基于token长度计算的会话缓冲
- Backed by a Vector Store :基于向量存储的会话存储
③ 在Chain中使用内存
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI
template = """You are a chatbot having a conversation with a human.
{chat_history}
Human: {human_input}
Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history")
llm = OpenAI()
llm_chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory,
)
# Hello there! How are you?
print(llm_chain.predict(human_input="Hi, my friend"))
④ 在Agent中使用内存
from langchain.agents import AgentExecutor, Tool, ZeroShotAgent
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_openai import OpenAI
# 定义Tool
# 需要定义环境变量 export GOOGLE_API_KEY="", 在网站上注册并生成API Key: https://serpapi.com/searches
search = GoogleSearchAPIWrapper()
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events",
)
]
# 定义Prompt
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}"""
prompt = ZeroShotAgent.create_prompt(
tools,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"],
)
# 定义Memory
memory = ConversationBufferMemory(memory_key="chat_history")
# 定义LLMChain
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
# 定义Agent
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(
agent=agent, tools=tools, verbose=True, memory=memory
)
agent_chain.run(input="How many people live in canada?")
⑤ 内存第三方集成
(3) Agents
基于LLM我们可以做很多事情,比如让它回答我们的问题,让它对某个话题/知识点做总结,让它出一道相似的题目等等。我们会发现当需要LLM做的事情越来越多的时候,很多时候有些功能是可以复用的。也就是说我们可以把基于LLM实现的一个功能抽象成一个可复用的模块,没错,它就是Agent !

Agent的核心思想是基于LLM大语言模型做一系列的操作,并把这一系列操作抽象成一个可复用的功能!明白了这个,就会对后面Agent的理解有很大帮助,让我们把结构精简为下图所示
- Planning :Agent的规划阶段涉及确定如何利用LLM大语言模型以及其他工具来完成特定任务。这包括确定所需的输入和输出,以及选择适当的工具和策略。
- Memory :在记忆阶段,Agent需要能够存储和访问过去的信息,以便在当前任务中使用。这包括对过去对话或交互的记忆,以及对相关实体和关系的记忆。
- Tools ::工具是Agent执行任务所需的具体操作。这可能涉及到执行搜索、执行特定编程语言代码、执行数据处理等操作。这些工具可以是预定义的函数或API如
search(),python_execute()等 - Action :在执行阶段,Agent利用选择的工具执行特定的动作,以完成规划阶段确定的任务。这可能包括生成文本、执行计算、操作数据等。动作的执行通常是基于规划阶段的决策和记忆阶段的信息。

① Agent类型
Agent类型按照模型类型、是否支持聊天历史、是否支持函数并行调用等维度的不同,主要分为以下几种不同的Agent,更多可以参考[agent_types文档]
OpenAI functions:基于OpenAI Function的AgentOpenAI tools:基于OpenAI Tool的AgentXML Agent:有些LLM模型很适合编写和理解XML(比如Anthropic’s Claude),所以可以使用XML Agent
② Tools工具
Tools是Agent最核心的部分之一,也是Agent与外界交互的重要接口,让它具备了与世界沟通的能力。工具充当了Agent与外部环境之间的桥梁,使得Agent能够处理来自外部环境的输入,并生成相应的输出。
Tools并不是Langchain自己发明创造的,而是属于通用的Agent概念中的一个重要组成部分,在OpenAI中它就原生支持除了message之外的Tools参数和Functions参数,这两个参数没有太大区别,只是使用Tools逐步代替了早期的Functions参数。

举例来说,Agent可以使用搜索工具来获取特定主题的信息,使用语言处理工具来理解和生成文本,使用编程执行工具来执行特定的代码等。这些工具允许Agent从外部获取所需的信息,并对外部环境产生影响。在这种情况下它的工作流程如下所示 :
- ① 用户发起请求,Agent接收请求
- ② Agent会把
System Text + User Text + Tools/Functions一起传递给LLM(如调用ChatGPT接口) - ③ 由于LLM发现传递了Tools/Functions参数,所以首次LLM只返回应该调用的函数(如search_func)
- ④⑤ Agent会自己调用对应的函数(如search_func)并获取到函数的返回结果(如search_result)
- ⑥ Agent把函数的返回结果并入到上下文中,最后再把
System Text + User Text + search_result一起传递给LLM - ⑦ LLM把结果返回给Agent
- ⑧ Agent再把结果返回给用户

下面可以通过一个简单的例子来看一下,使用@tool注解自定义一个Tool工具
from langchain.tools import tool
@tool
def search(query: str) -> str:
"""Look up things online."""
return "LangChain"
print(search)

由于OpenAI接口支持Functions和Tools两种使用,所以Langchain也支持把Tool转为Function,可以查看如下例子
from langchain_core.utils.function_calling import convert_to_openai_function
tools = [search]
functions = [convert_to_openai_function(t) for t in tools]
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo")
message = model.invoke(
[HumanMessage(content="hello, my friend ! i want to search dog")], functions=functions
)
print(message)

(4) Chains
官方对Chains的定义是指Prompt、LLM、Tool等一系列的调用组合,也就是说只要定义完各个模块,我们使用Chain就可以自动把各个模块之间连接起来并运行。我们知道在Langchain Lib整个结构中,从底向上依次是抽象层、具体实现层、以及整合适配层,现在有没有发现些什么呢 ?没错!这个整合适配层的核心实现,就是基于Chains链!
在下图所示中,经过3和4的连接,Chain就可以把Prompts和Model这两个模块连接在一起,形成了一个自动执行的序列。


- LCEL Chains :LCEL (LangChain Expression Language) 即Langchain提供的一种更简单的链式操作的表达式语言
- Legacy Chain :传统的基于类调用的方式实现,是Langchain遗留的Chains操作,底层不是基于LCEL实现,而是基于类调用
(5) Retrieval
在《深入浅出LLM大语言模型》文章中,提到了RAG是最常用的LLM应用场景之一。所以Langchain提供了完整的RAG接入方式,称为Retrieval检索模块。如果对RAG检索不是很理解,强烈建议先阅读《深入浅出LLM大语言模型》文章,有助于对本Retrieval模块的理解。

一个完整的检索模块按照流程,主要包括以下部分


在下面这个例子中,会定义一个on_chain_start的自定义回调函数
# 定义一个自定义的回调函数
from typing import Any, Dict
from langchain.callbacks.base import BaseCallbackHandler
class MyCustomHandler(BaseCallbackHandler):
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> None:
"""Print out that we are entering a chain."""
class_name = serialized.get("name", serialized.get("id", ["<unknown>"])[-1])
print(f"\n\n\033[1m> [This is custom callback handler] Entering new {class_name} chain...\033[0m")
# 创建llm/prompt/handler
from langchain_openai import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
handler = MyCustomHandler()
# 链式调用
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler], verbose=True)
chain.invoke({"number": 2})

3. 模块总结
根据上述的理解,对LangChain核心模块的总结如下所示

四. 优雅且高效的LCEL
1. 介绍
LCEL(LangChain Expression Language)是一种构建复杂链的简便方法,语法是使用|或运算符自动创建Chain后,即可完成链式操作。这在背后的原理是python的__ror__魔术函数,比如chain = prompt | model就相当于chain = prompt.__or__(model)。
下面看一个简单的LCEL代码,按照传统的方式创建prompt/model/output_parser,然后再使用|或运算符创建了一个Chain,它自动把这3个组件链接在了一起,这都是在底层实现的,对应用层十分友好 !
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI()
output_parser = StrOutputParser()
chain = prompt | model | output_parser
print(chain.invoke({"topic": "math"}))
在LCEL的底层,主要是实现了一套通用的Runnable协议,只要各类组件遵循并实现此协议,便可以自动完成链式组合和调用。
- 统一的接口 :每个LCEL对象都实现该Runnable接口,该接口定义了一组通用的调用方法(invoke、batch、stream、ainvoke、 …)。这使得LCEL对象链也可以自动支持这些调用。也就是说,每个LCEL对象链本身就是一个LCEL对象。
- 组合原语 :LCEL提供了许多原语(比如ror魔术函数),可以轻松组合链、并行化组件、添加后备、动态配置链内部等等。
2. 为什么使用LECL

3. 简单的上手示例
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI()
output_parser = StrOutputParser()
chain = prompt | model | output_parser
# invoke: 普通输出
print(chain.invoke({"topic": "math"}))
# ainvoke: 异步输出
chain.ainvoke({"topic": "math"})
# stream: 流式输出
for chunk in chain.stream({"topic": "math"}):
print(chunk, end="", flush=True)
# Batch: 批量输入
print(chain.batch([{"topic": "math"}, {"topic": "English"}]))
- Prompt + LLM
- RAG
- Multiple chains
- Querying a SQL DB
- Agents
- Using tools
更多使用场景和示例,可以自行查看
五. 总结
总的来说,LangChain提供了一种灵活、强大的工具,用于将各种操作组合在一起,从而实现复杂的自然语言处理任务。通过本教程的学习,可以对LangChain有了一个全面的了解,并且能够使用它进行链式操作的构建和管理。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 19
19 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)