【数学建模笔记】【第十讲(1)】聚类模型之:K-均值聚类
聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间的相关性和主要差异。聚类和分类的区别:分类是已知类别的,聚类未知。
一、定义
聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间的相关性和主要差异。
聚类和分类的区别:分类是已知类别的,聚类未知。
二、算法流程
K-means聚类的算法流程:
- 指定需要划分的簇[cù]的个数K值(类的个数);
- 随机地选择K个数据对象作为初始的聚类中心 (不一定要是我们的样本点);
- 计算其余的各个数据对象到这K个初始聚类中心的距离,把数据对象划归到距离它最近的那个中心所处在的簇类中;
- 调整新类并且重新计算出新类的中心;
- 循环步骤三和四,看中心是否收敛(不变),如果收敛或达到迭代次数则停止循环;
- 结束
【举例】
1.指定聚类个数为2
2.随机地选择K个数据对象作为初始的聚类中心

3.计算其余的各个数据对象到这K个初始聚类中心的距离,把数据对象划归到距离它最近的那个中心所处在的簇类中;

4.调整新类并且重新计算出新类的中心;

5.循环步骤三和四,看中心是否收敛(不变),如果收敛或达到迭代次数则停止循环;

K-均值聚类可视化可以在这个网站自己动手尝试:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
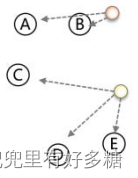
三、算法流程图

四、K-means算法评价
优点:
- 算法简单,快速
- 对处理大数据集,该算法是相对高效率的
缺点:
- 要求用户必须事先给出要生成的簇的数目K
- 对初值敏感(选择的初始中心不同,则最后收敛后的中心位置也不同)
- 对于孤立点数据敏感(孤立数据极容易造成聚类中心的严重偏移,不符合数据集本身的聚集程度)
K-means++算法可以改进2和3的缺点
五、算法改进
K-means++算法介绍:
k-means++算法只是改进了一点:就是在选择初始聚类中心的时候,选择初始聚类中心的基本原则是:初始的聚类中心之间的相互距离要尽可能的远。
算法描述如下:
(只对K-means算法“初始化K个聚类中心” 这一步进行了优化)
步骤一:
-
随机选取一个样本作为第一个聚类中心;
-
计算每个样本与当前已有聚类中心的最短距离(即与最近一个聚类中心的距离),这个值越大,表示被选取作为聚类中心的概率较大;最后,用轮盘法(依据概率大小来进行抽选)选出下一个聚类中心;
-
重复步骤二,直到选出K个聚类中心。选出初始点后,就继续使用标准的K-means算法了
这样,由于初始聚类中心已经是尽可能远的,所以基本上是确定唯一的,而不会是随机的,并且即使有孤立点的存在,那么就会在选择初始聚类中心的时候直接将其选为聚类中心,最后极有可能只有该聚类中心仅有一个孤立点,而不会包含其他点。所以不会影响到聚类中心对该数据集分布情况的描述。
六、SPSS软件操作举例
1.将数据导入spss软件中

2.在“分析”选项中找到“K-均值聚类”

3.设置分析的各种参数
将“食品”到“杂项”的各栏数据放入变量中,“省份”放入个案标记依据中,其余不用管。
“迭代”中可以选择迭代次数,代表:如果迭代至X次之后还没有收敛,就会自动终止。

“保存”选项里的两个都勾上。
结果可以反映出每个省份是属于第几聚类,每个省份距离聚类中心的距离是多少。

“选项”中勾选情况如下:

点击确定即可。
4.分析结果:
可以看到spss分析的每一项的聚类中心:
就“食品”一项而言,其初始聚类中心分别是值为“3712”和“1304”的省份,不难发现分别是省份中的“上海”和“内蒙古”,并且二者分别是最大值与最小值。可以看出spss默认使用的是“K-均值++”算法。

分出的聚类成员如下:可以看到聚类类别为1的省份和聚类类别为2的省份分别是哪些。
从而可以得出一些大致的结论:比如,这个聚类分析算法按两个聚类分,其实把省份分成了高收入水平和低收入水平两种省份。

下图显示的是最终的聚类中心:

以上就是K-均值算法对于消费数据的分类的一个应用。
七、K-means算法的一些讨论
1.聚类的个数K值怎么定?
答:分几类主要取决于个人的经验与感觉,通常的做法是多尝试几个K值,
看分成几类的结果更好解释,更符合分析目的等。
2.数据的量纲不一致怎么办?
答:如果数据的量纲不一样,那么算距离时就没有意义。例如:如果X1单位是米,X2单位是吨,用距离公式计算就会出现“米的平方”加上“吨的平方”
再开平方,最后算出的东西没有数学意义,这就有问题了。
方法:先进行标准化

在spss软件中如何操作:


然后就会生成这些数据的标准化值及其各种指标数据:
可以将生成的下图放入论文中,说明你进行了标准化数据这一操作。

然后我们看spss在变量中保存的标准化数据:

这些名字带“Z”的数据就是标准化后的数据,代表着用的是“Z”标准化方法进行的标准化。用这些数据再进行K-均值聚类也可得到与刚才同样的效果。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)