RV1126_python人脸识别Retinaface+MobilefaceNet
在RKNN上实现人脸识别过程。模型采用RetinafaceMobilefaceNet。采用Python代码 在线实现
RV1126_python人脸识别Retinaface+MobilefaceNet
RV1126 具备RKNN 模块支持大部分如Pytorch、MXNet、Caffe、tensorflow、keras、onnx等常见框架,而且量化部署使用RKNN-toolkit非常方便。以下介绍通过RV1126实现的人脸识别过程。
首先人脸识别需要先做人脸检测>>人脸校正/活体检测(选做)>>人脸特征提取>>数据库进行欧式距离比对。
人脸检测基于Insightface一个开源的人脸识别的开源项目
https://github.com/deepinsight/insightface.git
是基于 MXNet 框架实现的业界主流人脸识别解决方案,包含了数据集制作教程、训练和验证脚本、预训练模型以及和MXNet模型的转换工具。
目前由于考虑RV1126上的RKNN性能不算太强,而目前backbone使用mobilenet的人脸检测准确度也很高,所以retinaface与人脸特征提取都使用mobileface.
本次项目使用的是Retinaface、mobilefaceNet。
由于考虑到还需要移植到海思的NNIE平台,有需要转换成Caffe,而MXNet的mobilefaceNet转换到Caffe最后转换到wk会很麻烦(有些转换层不支持)。而MXNet对Windows支持不好,特别是我使用的RTX30系列的显卡,搭建工程训练就很麻烦。我测试是使用ubuntu 20.04训练这个MXNet。一般要移植到NNIE很多转换出来的模型海思提供Caffe算子不支持,要涉及到修改网络,所以使用了pytorch的项目。
还有个原因,新版本的insightface代码,我在ubuntu,MXNet上训练失败,使用Res50网络训练正常,所以也弃用insightface的代码,使用pytorch版本的。
Pytorch需要转换成onnx再到RV1126上运行,一般项目都会带这个选项。ONNX是通用模型描述标准。
也是为了针对NNIE,一般我还会转换到Caffe,这个再另起一个文章。
Pytorch环境(RTX3060TI_WIN10):
onnx 1.13.1
onnxruntime 1.14.0
onnxsim 0.4.17
torch 1.10.1+cu113
torchvision 0.11.2+cu113
先讲一下原理性的,不看可以跳到后面
Insightface 里的Retinaface原理分析与网络输出结果处理
在目标检测中:
Anchor是一种在图像中生成固定大小和长宽比的框,用于在特征图上采样,以便检测不同尺度和长宽比的目标。
Feature map是卷积神经网络的输出,是一个高维特征空间,其中每个位置表示原始图像中一定大小区域的特征。
Proposal是指在特征图上使用预定义的anchor或者候选区域生成的一组潜在的物体边界框,用于表示可能包含目标的区域,这些提议将被送入目标分类和边界框回归网络进行分类和位置调整。
上图是insightface版本的
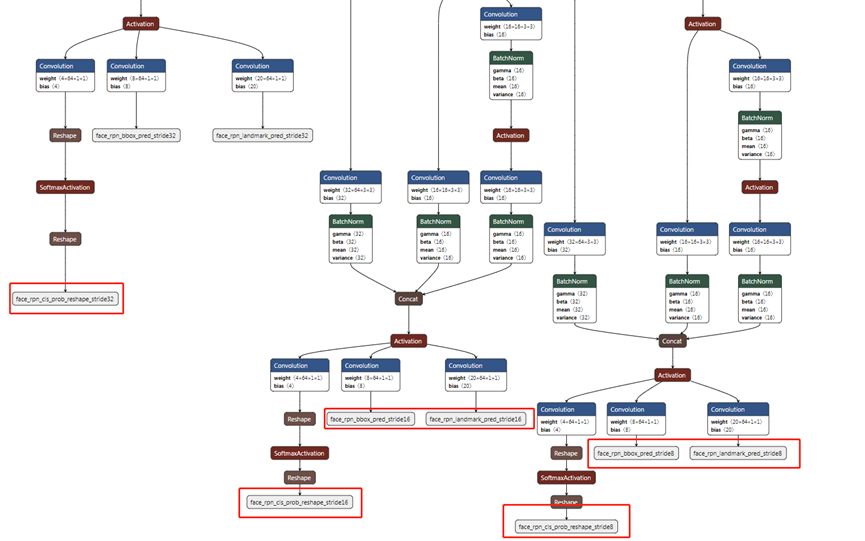
RetinaFace在使用MobileNet作为backbone时,对于每个特征层都定义了不同的anchor。
简化版的RetinaFace在特征金字塔上有3个检测分支,分别对应3个stride: 32, 16和8。在stride32上一个feature map对应的原图的32X32的感受野,可以用来检测较大的区域人脸,同理stride16和stride8可用于中等和较小人脸区域的检测。默认设置为每个stride对应一个ratio,每个ratio对应两个scale,即每个stride对应的feature map的每个位置会在原图上生成两个anchor box。当anchor大于设置threshold时,就会认为是一个Proposal,再经过NMS就可以输出
所以针对640x640输入,stride32这层feature_map对应的anchor就有20x20x2=800,其他类推
至于输出,或者是为什么是这样排列是这些东西,是网络输出结果在跟训练时的标签里的值做损失函数决定的,不断训练到代表这样的意思
Head:
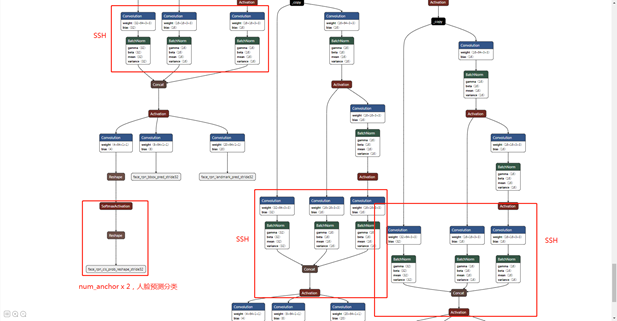
经上述特征提取操作获得 、S3、S4、S5 三个有效特征层,接下来需要通过这三个有效特征层来获得预测结果,每一层都有loc,landmarks,bbox。
retinaface的预测结果分为三个:分类预测、人脸框预测、人脸关键点预测;
(1)分类预测(face or not)
用于判断先验框内部是否包含物体(二分类),Retinaface官方使用的是softmax进行判断(也可以利用一个1x1的卷积,将SSH的通道数调整成num_anchors x 2,用于代表每个先验框内部包含人脸的概率,pytorch_retinaface用此方法做了一些后处理,使得结果处理更简单)。Ncwh, 1,2*2,w,h,每个值都是对应anchor的一个概率。两个值应该是一个是分类,一个是概率
(2)人脸框的回归(bbox)
用于对先验框进行调整从而获得预测框,需要四个参数,前两个用于对先验框的中心进行调整,后两个用于对先验框的宽高进行调整(可以利用一个1x1的卷积,将SSH的通道数调整成num_anchors x 4,用于代表每个先验框的调整参数),Ncwh, 1,2*4,w,h,每个anchor(共w x h)有4个值,分别对应相对于中心点的左上与右下的归一化相对坐标.实际这个blob输出比较大的,只要了前面的。
(3)人脸关键点的回归(landmarks)
用于对先验框进行调整,从而获得人脸关键点坐标,需要十个参数,每一个人脸关键点需要两个调整参数,对先验框中心的x、y轴进行调整获得关键点坐标,一共有五个人脸关键点(可以利用一个1x1的卷积,将SSH的通道数调整成num_anchors x 10(num_anchors x 5 x 2),用于代表每个先验框的每个人脸关键点的调整). Ncwh, 1,2*10,w,h,实际这个输出比较大的,只要了前面的。
若网络输入尺寸为 3∗640∗640 ,经上述处理后得到: S3、S4、S5 的分别为: (80,80,64) , (40,40,64) , (20,20,64) 。这几个是特征层feature_map
了解这些是为了理解MXNet的后处理,如果从神经网络的forward结果中提取出人脸的检测框,关键点。
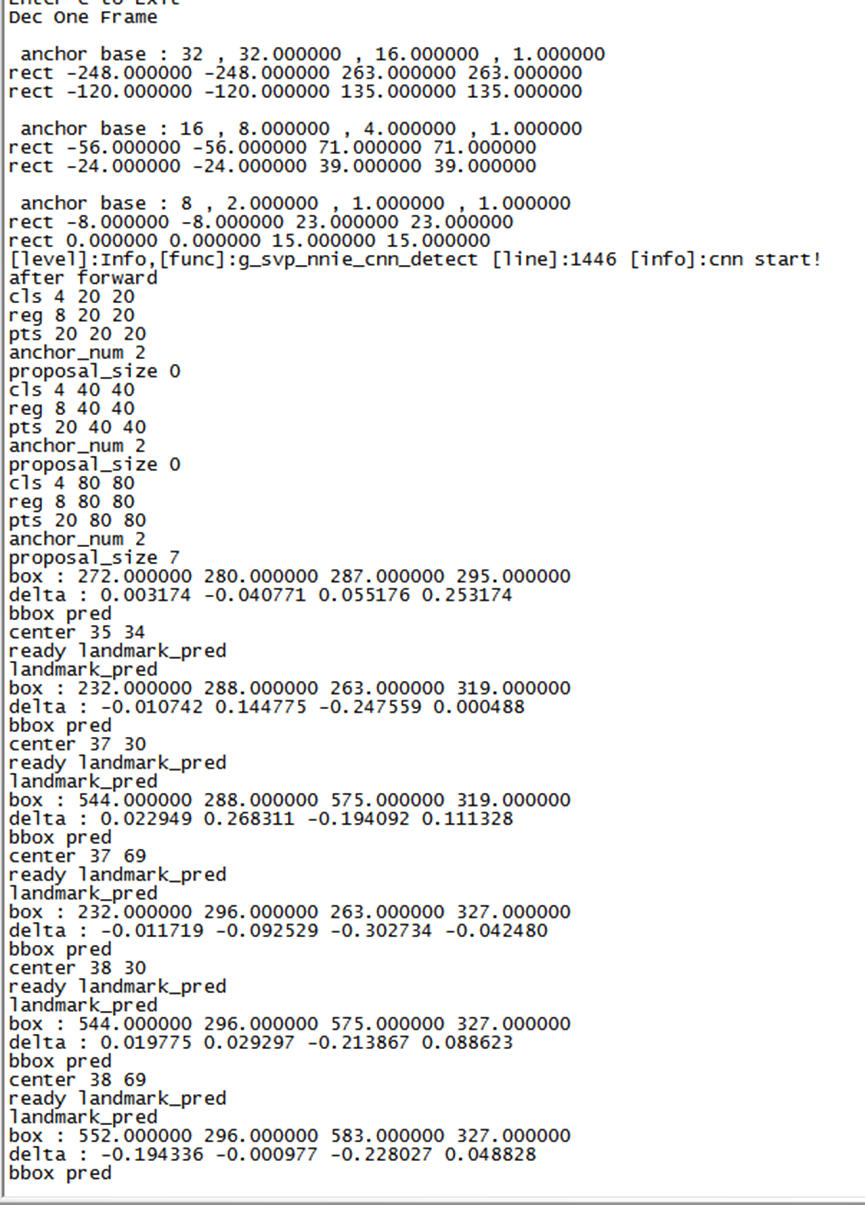
海思的NNIE我使用的是原版的预训练模型
https://github.com/deepinsight/insightface/issues/669
如果是不想进行训练,也可以直接拿来用,但需要知道如何后处理。
Retinaface_c++可以协助分析一下如何处理insightface里的结果
具体参考Cpp工程https://github.com/Charrin/RetinaFace-Cpp
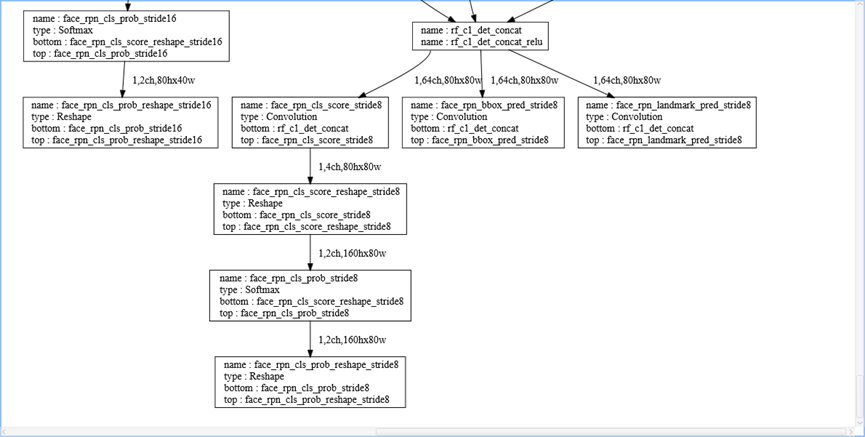
feature_map后再做一个卷积与softmax ,后,每个stride都有3个输出,分别是cls,landmark,bbox。具体处理时是caffe分别从Stride32 16 8拿到相应 的bbox(预测框),cls(分类概率),landmark(特征点位置),分别过滤Stride32 16 8的预检测(anchor)概率阈值,然后写到Proposal中。经过【Head】完成调整、判断之后,还需要进行非极大值抑制(即筛选出一定区域内属于同一种类得分最大的框)。
关于pytorch_retinaface里用了prmute操作来实现transpose,把输出结果ncwh转换成nwhc,再做后面处理。MXNet版本是输出ncwh来处理的,Retinaface_c++也是处理ncwh,所以具体部署时要注意。
在Pytorch_retinaface代码中,网络的输出结果,针对640x640,最后输出,cls:[1,16800,2]。(20*20+40*40+80*80)*2=16800,为3个feature_map对应anchor的数量,2是每个feature_map块对应的anchor的数量。使用了torch的view强制转换成二维
[1,80,80,4]>>[1,6400,4]
[1,6400,4] [1,1600,4] [1,400,4] 使用torch.cat>> [1,16800,4] 最后一维4是achor0_class,achor0_score,achor1_class,achor1_score
所以上层使用时就
scores = conf.squeeze(0).data.cpu().numpy()[:,1]就只拿了最后一维score的
landmark,bbox其他也类推。因为后期我使用的是python在RV1126在线部署,方便调试,使用的是retinaface_pytorch的后处理代码。
训练的标签格式如下
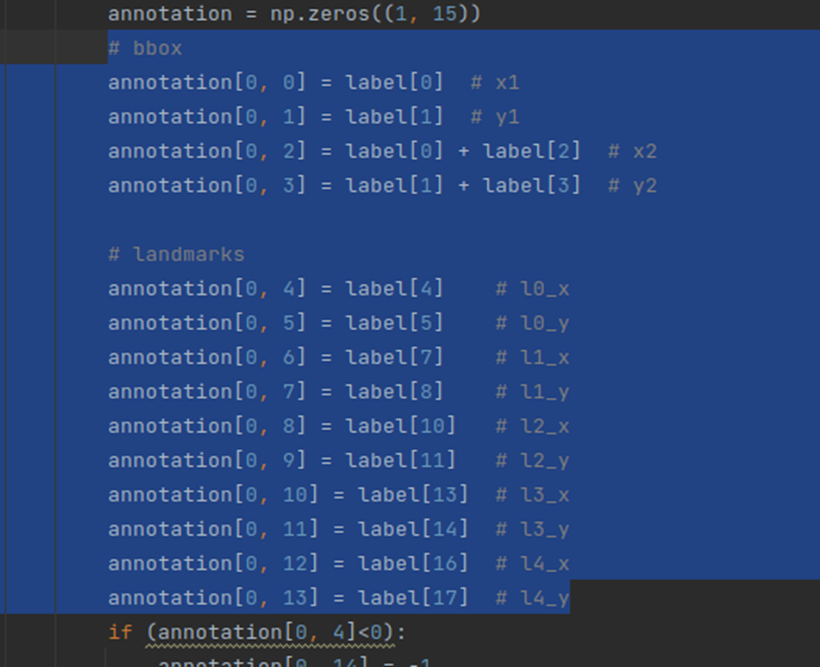
Insightface的Retinaface实际海思上跑的网络输出
使用的是MXNet ncwh输出,这里的caffe模型输出应该是
Cls_8
Land_8
Bbox_8
Cls_16
Land_16
Bbox_16
Cls_32
Land_32
Bbox_32具体在转换模型时还得调整顺序才能编过,具体输出又对应,搞不清楚
判断nwhc

给这个是为了如果你选择使用MXNet要知道如何处理,不然后面RV1126上运行时结果就不对。
具体参考Cpp工程https://github.com/Charrin/RetinaFace-Cpp
人脸检测完后,就需要进行人脸识别。
InsightFace提供了一个ARCFace网络,有MXNetpytorch等实现。
MobilefaceNet,
就是backbone使用mobilenet,将人脸特征提取成128维特征值
在进行训练或者评估的时候,需要下载数据集,原始的在。
https://github.com/deepinsight/insightface/tree/master/recognition/_datasets_
但有很多下载下来需要授权,刚好有一个开源的公开了这份训练数据集
https://github.com/TreB1eN/InsightFace_Pytorch
下载下来的是使用bcolz压缩了的,需要解码,
Unzip faces_emore.zip
mv faces_emore data/
pip install bcolz==1.2.1
安装时遇到些问题
2 -DSHUFFLE_AVX2_ENABLED -mavx2
c-blosc/blosc/shuffle.c:170:1:error: conflicting types for ‘_xgetbv’
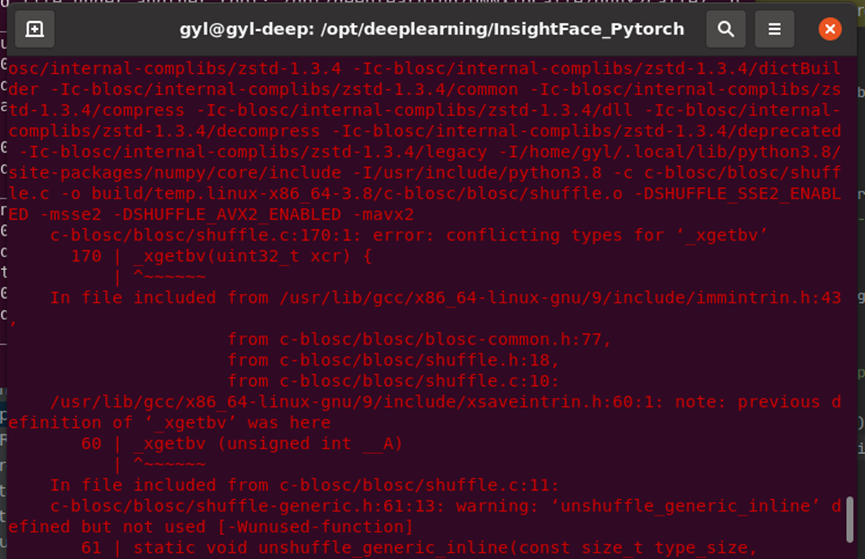
export DISABLE_BCOLZ_AVX2=true
pip install bcolz==1.2.1
使用开源工程里的python prepare_data.py解压出来。
解压后,很大很大,所以想测试训练的话,过程很慢,需要好几天才训练完,所以使用一部分数据集会比较快看到效果
实际使用开源项目训练
后来由于MXNet训练需要在Ubuntu上,我比较习惯windows的环境,所以就使用了pytorch。
默认安装了windows的pytorch环境,不懂自己去下载。
Retinaface人脸检测
Retinaface
https://github.com/biubug6/Pytorch_Retinaface
按ReadMe来操作训练即可训练出
训练与测试集
已经训练好的facenet_mobilenet.pth和facenet_inception_resnetv1.pth可以在百度网盘下载。
链接: https://pan.baidu.com/s/1K20hyxU_UgSej1eZWih0Ag 提取码:anv6
训练用的CASIA-WebFaces数据集以及评估用的LFW数据集可以在百度网盘下载。
链接: https://pan.baidu.com/s/1qMxFR8H_ih0xmY-rKgRejw 提取码: bcrq
训练出来修改detect.py来检测模型
运行test_widerface.py来测试测试数据集,前提是需要使用
python label2imglist.py
import os
import argparse
parser = argparse.ArgumentParser(description='Retinaface')
parser.add_argument('--dataset_folder', default='./data/widerface/val/images/', type=str, help='dataset path')
args = parser.parse_args()
if __name__ == '__main__':
# testing dataset
testset_folder = args.dataset_folder
testset_list = args.dataset_folder[:-7] + "label.txt"
with open(testset_list, 'r') as fr:
test_dataset = fr.read().split()
num_images = len(test_dataset)
for i, img_name in enumerate(test_dataset):
print("line i :{}".format(i))
if img_name.endswith('.jpg'):
print(" img_name :{}".format(img_name))
f = open(args.dataset_folder[:-7] + 'wider_val.txt', 'a')
f.write(img_name+'\n')
f.close()
来通过label.txt生成没带标签只带图片路径的
python test_widerface.py --trained_model weight_file --network mobile0.25
跑完后,可以进入widerface_evaluate,跑
cd ./widerface_evaluate
python setup.py build_ext --inplace
python evaluation.py即可输出测试集的精度,基本与项目的结果一致
首先使用Pytorch_retinaface项目中的convert_to_onnx.py
但需要增加优化,将一些indetyfy层去掉,其实是进行simplify,也可以运行命令行,不然转换会有问题
# loadyour predefined ONNX model
nx_model = onnx.load(output_onnx)
#convert model
model_simp, check = simplify(nx_model)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp,"retinaface.onnx")
转换时会提示scipy里的numpy typeDic没这接口
需要升级 一下
pip install --user --upgrade scipy --proxy=https://127.0.0.1:1090
MobilefaceNet特征提取
为了方便训练,使用了另一个pytorch的实现
https://github.com/bubbliiiing/facenet-pytorch
由于mobilefaceNet训练数据集很大,时间很长,具体按项目说明即可,主要是下载数据集训练,大力出奇迹。
直接先看项目结果,就使用预训练模型。
最主要是确定输入预处理是什么,格式是BGR还是RGB
输入预处理,MXNet的mobilefacenet模型,使用的是means=127.5,127.5,127.5 std_values=128,128,128,即先减127.5再除以128.这个在ONNX模型里是有个minus_scalar以及mul_scalar,参数就是127.5 128.BGR输入的。.
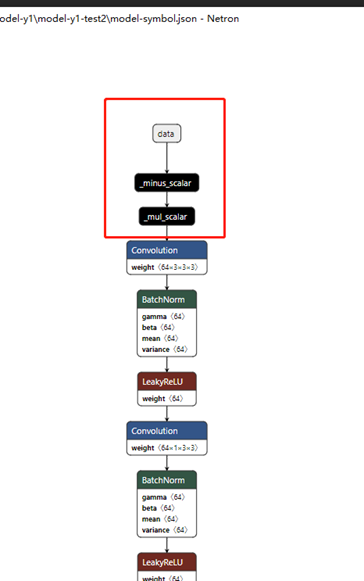
MXNet的Mobilefacenet模型
facenet-pytorch看python源码使用的是RGB输入,mean=0,0,0 std_valus=255,255,255。配置需要根据训练时模型代码来决定。
RV1126上运行
好,终上所述,最后得到两个onnx模型。正面开始运行在RV1126上
首先需要先搭建好RKNN-toolkit环境,如何搭建参考SDK文档,还需要更新RV1126的驱动
我使用的版本是
D RKNNAPI:==============================================
D RKNNAPI: RKNN VERSION:
D RKNNAPI: API: 1.7.3 (0cfd4a1 build: 2022-08-15 17:20:38)
D RKNNAPI: DRV: 1.7.3 (c4ea832 build: 2022-08-13 09:29:29)
D RKNNAPI:==============================================
使能NTB模式。在RV1126版本终端里(ssh或者串口登录)
cat /etc/init.d/.usb_config
usb_adb_en
usb_ntb_en
exportLD_LIBRARY_PATH="/usr/lib32/:$LD_LIBRARY_PATH"
重启rknn_server.sh
这样PC才能找到设备
(rknn) C:\Users\deep>python -mrknn.bin.list_devices
*************************
all device(s) with ntb mode:
d81352278dd4de31
*************************
需要用(RKNN-TOOLKIT里的)rknpu_full_driver,这样才能PC通过USB连接调试
rv1126驱动为 galcore_puma.ko
一开始能找到ntb设备,run_init就报错 RKNN_ERR_DEVICE_UNAVAILABLE
原因是NTB的驱动没安装好,使用
D:\depplearning\rknn-toolkit\platform-tools\drivers_installer\windows-x86_64\zadig-2.4.exe
安装。安装好后即可
注意:不用CUDA转换才能量化正常,之前使用CUDA量化,一直不正常,搞了很久很久。。。
代码在github上,良心贡献!
https://github.com/guolele1990/rknn_FaceRecognization.git
分别是
Retinaface.onnx (pytorch_retinaface)
Mobilefacenet.onnx (facenet_pytorch)
Retinaface量化
pythonRetinafaceConvertTest.py
注意修改模型路径,以及输入输出层 代码中使用的是 ret =rknn.load_onnx(model='./weights/retinaface.onnx', inputs='input0',input_size_list=[[3,640,640]], outputs=['output0','590','589']) 输入输出层可以使用netron查看,基本output0 590 589要分别对应loc, conf, landms。错了运行会报错
把不量化直接运行的结果判断一下,简单先判断是否人脸检测正常。
BUILD_QUANT= False
NEED_BUILD_MODEL= True
量化结果会打印每层的量化精度,再判断是否人脸检测正常
BUILD_QUANT= True
NEED_BUILD_MODEL= True
MobilefaceNet量化
修改
cfg= cfg_facenet_mxnet
选择对应的模型配置
把不量化直接运行的结果判断一下,结果与pytorch工程里的输出对比
BUILD_QUANT= False NEED_BUILD_MODEL = True 量化结果会打印每层的量化精度,结果与pytorch工程里的输出对比 BUILD_QUANT = True NEED_BUILD_MODEL = True
测试: 先编码
pythonencoding.py
图片预测:
pythonpredict.py
rtsp预测:
pythonrtspPredict.py
这里的mobilefaceNet的量化,一开始使用默认的方式,精度损失比较厉害,虽然能用,但检测效果不是很好,所以就直接使用
quantized_dtype='dynamic_fixed_point-i16'
这样出现基本与不量化前的模型一致。
针对量化与不量化的差异对比,我使用了
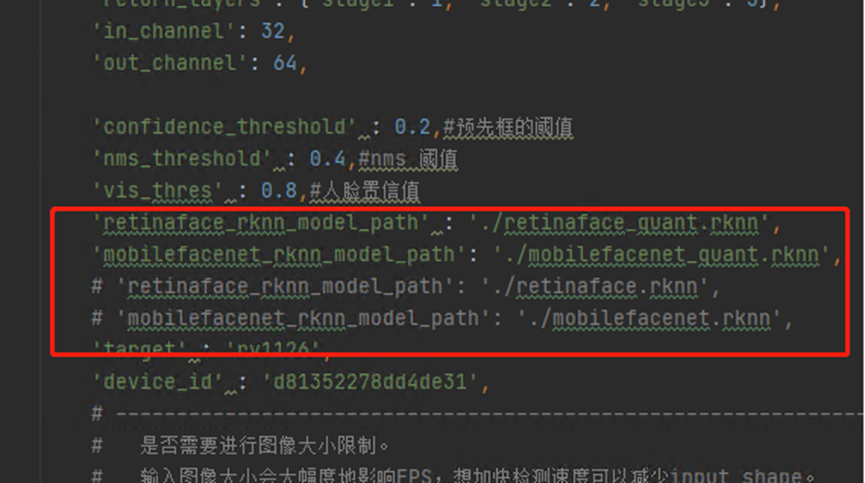
FaceRecognition.py里的一个配置来切换,这样可以比较方便的调试
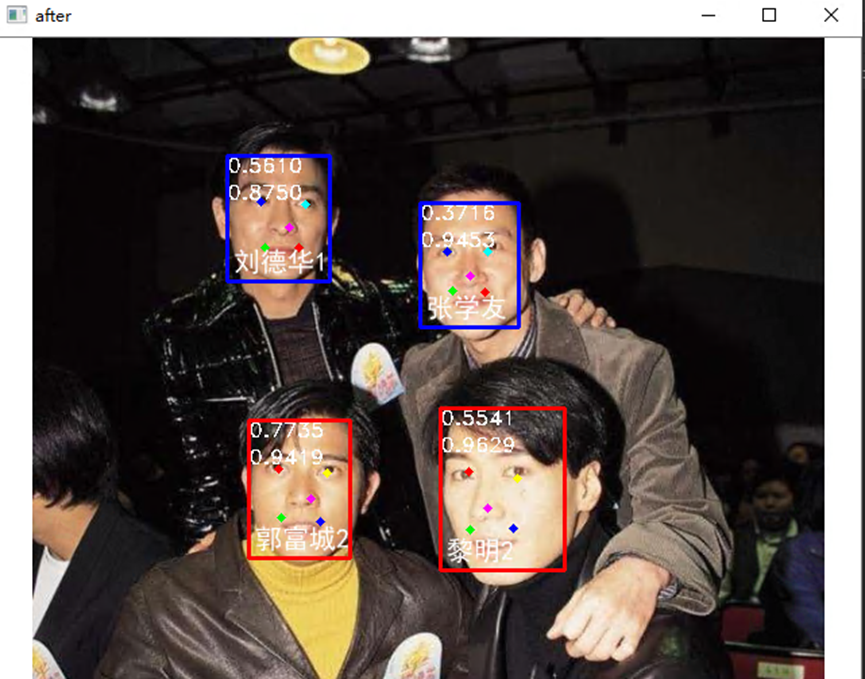
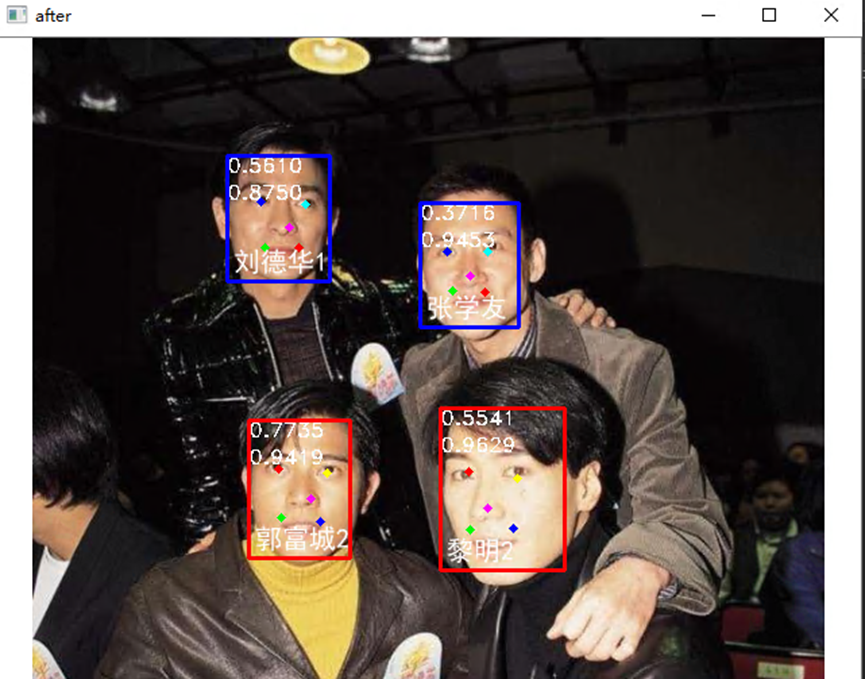
最后结果:

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)