跨模态检索论文阅读:Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval
文本到图像的人物检索仍然是一项艰巨的任务,原因在于身份内部的显著差异以及视觉和语言之间的模式异质性。前一个挑战源于这样一个事实,即身份的视觉外观因姿势、视角、照明和其他因素而不同,而文本描述则因任意描述顺序和文本模糊性而不同。后一个挑战是跨模态任务中的主要问题,是由视觉和语言之间固有的表征差异造成的。为了应对上述两个挑战,文本到图像的人物检索的核心研究问题是探索更好的方法来提取具有区分性的特征表征
Cross-Modal Implicit Relation Reasoning and Aligning for Text-to-Image Person Retrieval 用于文本对图像人物检索的跨模态隐式关系推理与对齐
我们提出了 IRRA:一种跨模态隐式关系推理和配准框架,它可以学习局部视觉-文本标记之间的关系,并增强全局图像-文本匹配,而无需额外的先验监督。具体来说,我们首先在掩码语言建模范式中设计了一个隐式关系推理模块。该模块通过跨模态多模态交互编码器将视觉线索整合到文本标记中,从而实现跨模态交互。其次,为了对视觉和文本嵌入进行全局对齐,提出了相似性分布匹配法,以最小化图像-文本相似性分布与归一化标签匹配分布之间的 KL 分歧。所提出的方法在所有三个公共数据集上都取得了最先进的新结果,与之前的方法相比,Rank-1 准确率显著提高了约 3%-9% 。
简介
文本到图像的人物检索仍然是一项艰巨的任务,原因在于身份内部的显著差异以及视觉和语言之间的模式异质性。 前一个挑战源于这样一个事实,即身份的视觉外观因姿势、视角、照明和其他因素而不同,而文本描述则因任意描述顺序和文本模糊性而不同。 后一个挑战是跨模态任务中的主要问题,是由视觉和语言之间固有的表征差异造成的。为了应对上述两个挑战,文本到图像的人物检索的核心研究问题是探索更好的方法来提取具有区分性的特征表征,并设计更好的跨模态匹配方法来将图像和文本统一到一个联合嵌入空间中。

图 1:从文本到图像的人物检索范例的演变 文本到图像的人物检索范例的演变。(a) 早期的全局匹配法直接对齐全局图像和文本嵌入。(b) 最新的局部匹配方法,显式提取并对齐局部图像和文本嵌入。© 我们的隐式关系推理方法,隐式推理所有本地标记之间的关系,以更好地对齐全局图像和文本嵌入。
本文提出了 IRRA:跨模态隐式关系推理与对齐框架,该框架借助跨模态隐式局部关系学习形成全局对齐。 与以往严重依赖显式细粒度局部配准的方法不同,我们的方法隐式地利用细粒度信息来增强全局配准,而不需要任何额外的监督和推理成本(图 1 ©)。 具体来说,我们设计了一个隐式关系推理模块,通过自我关注和交叉关注机制,有效地建立视觉和文本表征之间的关系。 MLM 通常用于视觉语言预训练(VLP)的预训练阶段[6, 9, 27, 31, 41]。在这项工作中,我们首次尝试证明 MLM 在下游微调任务中的有效性。 我们的主要创新是设计了一种多模态交互编码器,它可以有效地融合视觉和文本表征,并通过多模态微调任务调整跨模态细粒度特征。这种设计有助于骨干网络提取更具区分性的全局图像-文本表征,而无需额外的监督。
为了指导图像-文本匹配,常用的损失函数包括排序损失和跨模态映射匹配(CMPM)[53] 损失。与排名损失相比,CMPM 损失不需要选择特定的三元组或调整边际参数。它在不同批次大小的情况下表现出极大的稳定性,因此被广泛应用于文本到图像的人物检索 [5, 39, 50]。不过,我们发现,CMPM 中的投影可视为一个可变权重,用于调整 softmax 输出对数的分布,类似于知识蒸馏中的温度参数 [17]。然而,受限于投影长度的变化,CMPM 无法精确控制投影概率分布,因此很难在模型更新时关注硬负样本。为了探索更有效的跨模态匹配目标,我们进一步提出了图像-文本相似性分布匹配(SDM)损失。SDM 损失最小化了归一化图像-文本相似性得分分布与归一化地面实况标签匹配分布之间的 KL 分歧。此外,我们还引入了一个温度超参数来精确控制相似性分布的紧凑性,从而使模型更新集中于硬负样本,并有效地扩大非匹配对之间的方差和匹配对之间的相关性。
为了解决单模态数据集上单独预训练模型的局限性,我们利用对比语言-图像预训练(CLIP)[35] 作为模型的初始化。CLIP 使用丰富的图像-文本对进行预训练,具有强大的跨模态对齐能力。之前的一些方法[13, 50]要么冻结了部分参数,要么只引入了 CLIP 的图像编码器,导致无法充分利用 CLIP 在图像-文本匹配方面的强大能力。通过所提出的 IRRA,我们成功地从预先训练好的完整 CLIP 模型中直接移植了强大的知识,并在文本到图像的人物检索数据集上继续学习细粒度的跨模态隐式局部关系。此外,与最近的许多方法[5, 38, 50]相比,IRRA 更为高效,因为它在推理阶段只计算一个全局图像-文本对相似性得分。
主要贡献可总结如下:
- 我们提出IRRA 隐式地利用细粒度交互来增强全局配准,而不需要任何额外的监督和推理成本。
- 我们引入了一种新的跨模态匹配损失,名为图像-文本相似性分布匹配(SDM)损失。它直接最小化图像-文本相似性分布与归一化标签匹配分布之间的 KL 分歧。
- 我们证明,完整的 CLIP 模型可应用于文本到图像的人物检索,并可通过直接微调超越现有的最先进方法。此外,我们提出的 IRR 模块可以实现细粒度的图像-文本关系学习,使 IRRA 能够学习更具区分性的图像-文本表征。
- 在三个公共基准数据集(即 CUHK-PEDES [30]、ICFG-PEDES [7] 和 RSTPReid [55])上进行的广泛实验表明,IRRA 的性能始终大大优于最先进的方法。
方法

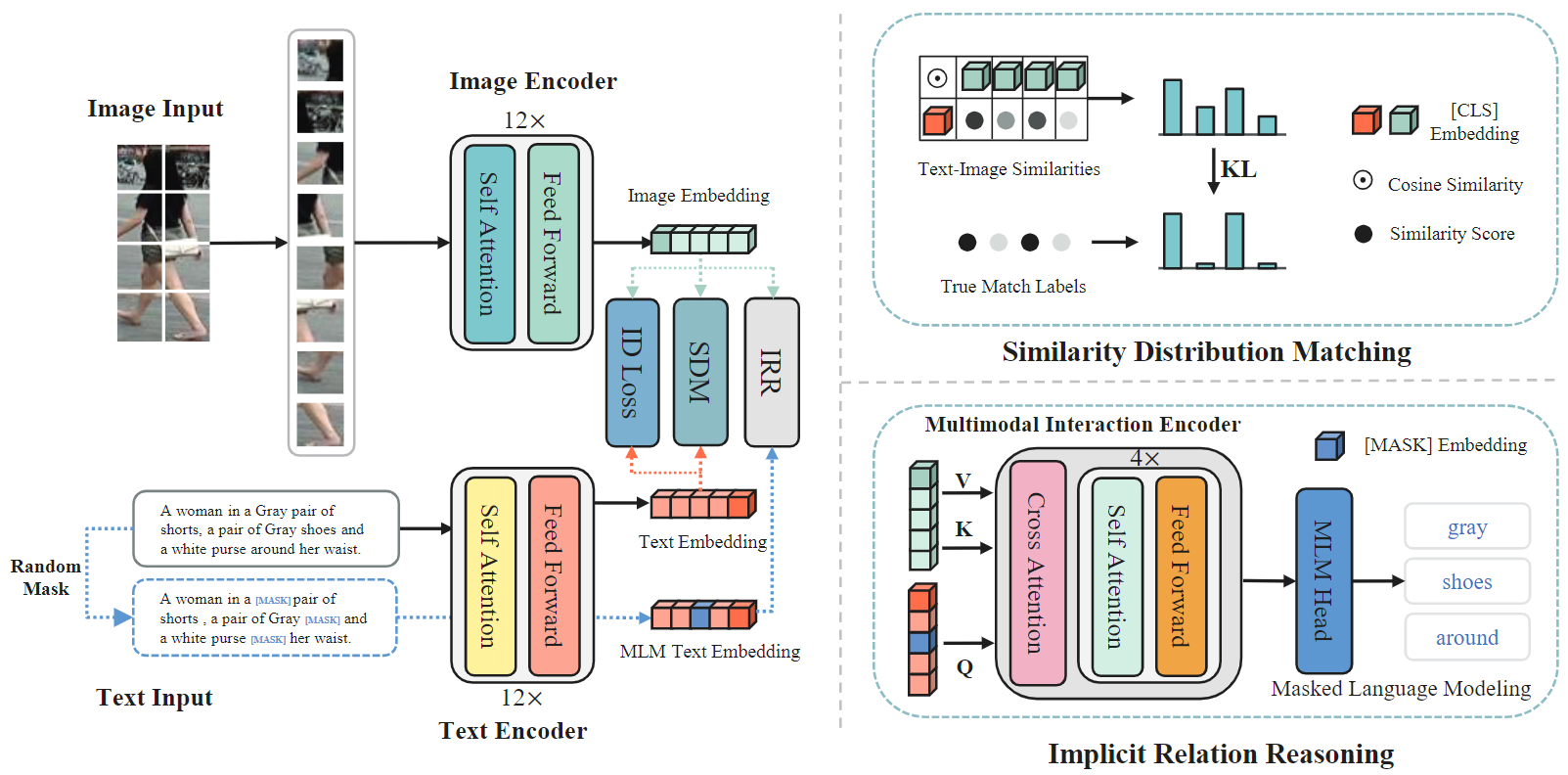
图 2. 提出的 IRRA 框架概览。它由双流特征提取主干和三个表征学习分支组成,即隐式关系推理(IRR)、相似性分布匹配(SDM)和身份识别(ID loss)。IRR 的目的是隐式地利用细粒度信息来学习具有区分性的全局表征。SDM 可最小化图像-文本相似度得分分布与真实标签匹配分布之间的 KL 发散,从而有效地扩大非匹配配对之间的方差和匹配配对之间的相关性。此外,我们还采用了 ID loss 来聚合同一身份的特征表示,从而进一步提高了检索性能。IRRA 通过这三个任务进行端到端训练,只计算一个全局图像-文本相似度得分,因此计算效率很高。虚线连接的模块将在推理阶段删除。
特征提取双编码器
以往的文本到图像人物检索工作通常使用在单模态数据集上分别预训练的图像和文本编码器。从 CLIP 到文本-图像人物检索的知识转移取得了部分成功[13],受此启发,我们直接用完整的 CLIP 图像和文本编码器初始化我们的 IRRA,以增强其基本的跨模态对齐能力。
图像编码器:给定输入图像 I ∈ RH×W ×C 后,采用 CLIP 预先训练好的 ViT 模型来获取图像嵌入。我们首先将 I 分割为 N = H × W/P 2 固定大小的非重叠补丁序列,其中 P 表示补丁大小,然后通过可训练的线性投影将补丁序列映射为一维标记 {f v i }|N i=1。注入位置嵌入和额外的[CLS]标记后,标记序列 {f v cls, f v 1 ,…, f v N } 被输入 L 层变换块,以模拟每个补丁的相关性。最后,采用线性投影法将 fv cls 映射到联合图像-文本嵌入空间,作为全局图像表示。
文本编码器:对于输入文本 T,我们直接使用 CLIP 文本编码器来提取文本表示,它是由 Radford 等人[35]修改的 Transformer [44]。在 CLIP 之后,我们首先使用词汇量为 49152 的小写字节对编码(BPE)[37] 来标记输入的文本描述。文本描述用[SOS]和[EOS]标记括起来,以表示序列的开始和结束。然后,将标记化文本 {f t sos, f t 1, …f t eos} 输入变换器,并通过掩码自注意利用每个补丁的相关性。最后,将变换器最高层的[EOS] 标记 f t eos 线性投射到图像-文本联合嵌入空间,从而得到全局文本表示。
隐式关系推理
为了充分利用细粒度信息,弥合视觉与语言之间的巨大模态差距至关重要。大多数现有方法都是通过显式对齐图像和文本之间的局部特征来实现这一目的,而本文则引入了一种新方法。具体来说,我们使用 MLM 来隐式挖掘细粒度关系,并学习具有区分性的全局特征。
屏蔽语言建模:屏蔽语言建模(MLM)最初是由泰勒 [43] 于 1953 年提出的,当 BERT 模型将其作为一种新颖的预训练任务时,它就广为人知了。在这项工作中,我们利用 MLM 来预测被遮蔽的文本标记,不仅通过未被遮蔽的文本标记的其余部分,还通过视觉标记来预测。与 Fu 等人[11]在纯语言预训练中的分析类似,MLM 优化了两个属性:(1)图像和文本上下文化表示与屏蔽文本标记静态嵌入的对齐性;(2)联合嵌入空间中静态嵌入的均匀性。如图 3 所示,在对齐特性中,掩码文本标记的采样嵌入作为锚,可对齐图像和文本上下文化表示。我们发现,这种局部锚对于建模局部依赖关系至关重要,并能隐式地利用细粒度的局部信息进行全局特征对齐。

图 3. MLM 目标图示。MLM 使用屏蔽文本标记的静态嵌入作为本地细粒度密钥,使同一上下文中的图像和文本上下文化表示保持一致。
多模态交互编码器:为了实现图像和文本模态之间的全面交互,我们设计了一种高效的多模态交互编码器来融合图像和文本嵌入,与其他两种流行的多模态交互模块[9, 16]相比,我们的设计计算效率更高,如图 4 所示。多模态交互编码器由多头交叉注意(MCA)层和 4 层转换器块组成。给定输入文本描述 T,我们以 15% 的概率随机屏蔽文本标记,并用特殊标记 [MASK] 进行替换。根据 BERT,替换为 10%的随机标记、10% 的不变标记和 80% 的 [MASK]。屏蔽后的文本定义为 ˆ T,并按照第 3.1 节所述输入文本转换器。然后,文本转换器和视觉转换器的最后一个隐藏状态 {hˆ t i }L i=1 和 {hv i }N i=1 将共同输入多模态交互编码器。为了更有效地融合图像和遮蔽文本表示,遮蔽文本表示 {hˆ t i }L i=1 充当查询(Q),图像表示 {hv i }N i=1 充当键(K)和值(V)。


图 4. 我们的多模态交互编码器和其他两个流行交互模块的图示。(a) 协同注意、文本和视觉特征被分别馈送到具有 selfattn 和 crossattn 的独立变换器模块中,以实现跨模态交互。(b) 合并注意力、文本和视觉特征,然后将其输入一个转换器模块。© 我们的多模态交互编码器,文字和视觉特征首先通过交叉注意力层进行融合,然后输入到单个变换器模块中。
相似性分布匹配
我们引入了一种新的跨模态匹配损失,称为 “相似性分布匹配”(Similarity Distribution Matching,SDM),它将 N ×N 文本图像对嵌入的余弦相似性分布纳入 KL 发散,以关联不同模态的表示。给定一个由 N 个图像-文本对组成的迷你批次,对于每个图像的全局表示 f v i,我们构建一个图像文本表示对集合为 {(f v i ,ft j ), yi,j }N j=1,其中 yi,j 是真正的匹配标签,yi,j = 1 表示 (f v i ,ft j ) 是来自同一身份的匹配对,而 yi,j = 0 表示未匹配对。设 sim(u, v) = u⊤v/∥u∥v∥ 表示 L2 归一化 u 和 v 之间的点积(即余弦相似度)。那么,匹配配对的概率就可以用下面的软最大值函数来简单计算了:

优化:如前所述,IRRA 的主要目标是改进联合嵌入空间中全局图像文本表示的学习。为了实现这一目标,我们还采用了常用的 ID 损失[54]以及 SDM 损失和 IRR 损失来优化 IRRA。ID 损失是一种软最大损失,它根据图像或文本的特性将其分为不同的组。它明确考虑了模内距离,并确保同一图像/文本组的特征表示在联合嵌入空间中紧密聚类在一起。IRRA 采用端到端方式进行训练,训练的总体优化目标定义为L = Lirr + Lsdm + Lid.

表 1. 在 CUHK-PEDES 数据集上与最先进方法的性能比较。结果根据 Rank-1 准确率排序。"Type"栏中的 "G "和 "L "代表全局匹配/局部匹配方法


表 4. 在 CUHK-PEDES、ICFG-PEDES 和 RSTPReid 上对 IRRA 各组成部分进行的消融研究

表 5. CUHK-PEDES 上 IRRA 不同多模态交互模块之间的比较

图 5. 对于每个文本查询,基准(第一行)和 IRRA(第二行)在 CUHKPEDES 上检索结果前十名的比较。与查询文本相对应的图像、匹配图像和不匹配图像分别用黑色、绿色和红色矩形标出。
定性结果图 5 比较了基准和我们提出的 IRRA 的前 10 名检索结果。 如图所示,IRRA 的检索结果要准确得多,而且当基准线无法重新检索时,IRRA 也能获得准确的检索结果。 这主要归功于我们设计的隐含关系推理(IRR)模块,它充分利用了细粒度的判别线索来区分不同的行人。图 5 中的橙色高亮文本和图像区域框说明了这一点。 此外,我们还发现,我们的模型只学习了词层面的语义信息,却无法理解描述文本中短语层面的语义,这导致了语义信息的失真。 这是因为我们在 MLM 中只屏蔽了随机的单个标记,而没有进行词组级屏蔽。 我们计划在未来解决这个问题。
结论
本文介绍了一种跨模态隐式关系推理和对齐框架(IRRA),用于学习无差别的全局图像-文本表征。 为了实现全面的跨模态交互,我们提出了一个隐式关系推理模块,该模块利用 MLM 挖掘视觉和文本标记之间的细粒度关系。我们还提出了相似性分布匹配损失,以有效地扩大非匹配对之间的方差和匹配对之间的相关性。 这些模块相互协作,将图像和文本对齐到一个联合嵌入空间中。 在三个流行基准数据集上的显著性能提升证明了我们提出的 IRRA 框架的优越性和有效性。我们相信,基于CLIP的方法将成为文本到图像的人物检索的未来趋势。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 26
26 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)