C++ 面试题-设计模式类问题(万余字总结)
1 、说说什么是单例设计模式,如何实现2、 简述一下单例设计模式的懒汉式和饿汉式,如何保证线程安全3、 请说说工厂设计模式,如何实现,以及它的优点4 、请说说装饰器计模式,以及它的优缺点5 、请说说观察者设计模式,如何实现
C++ 面试题-设计模式类问题
🏠个人主页:@编程ID
🧑个人简介:大家好,我是编程ID,一个想要与大家共同进步的程序员儿
🧑如果各位大佬在准备面试,找工作,刷算法,刷选择题,可以使用我找工作前用的刷题神器哦![面试刷题神器🎁]
💕欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,望能帮到各位想要找工作或者提高自己的小伙伴儿们,如果有什么需要改进的地方,还请大佬不吝赐教🤞🤞
1 、说说什么是单例设计模式,如何实现
单例模式定义:
保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。
那么我们就必须保证:
(1)该类不能被复制。
(2)该类不能被公开的创造。
那么对于C++来说,它的构造函数,拷贝构造函数和赋值函数都不能被公开调用。
单例模式实现方式
单例模式通常有两种模式,分别为懒汉式单例和饿汉式单例。两种模式实现方式分别如下:
(1)懒汉式设计模式实现方式(2种)
a. 静态指针 + 用到时初始化
b. 局部静态变量
(2)饿汉式设计模式(2种)
a. 直接定义静态对象
b. 静态指针 + 类外初始化时new空间实现
懒汉模式
懒汉模式的特点是延迟加载,比如配置文件,采用懒汉式的方法,配置文件的实例直到用到的时候才会加载,不到万不得已就不会去实例化类,也就是说在第一次用到类实例的时候才会去实例化。以下是懒汉模式实现方式C++代码:
(1)懒汉模式实现一:静态指针 + 用到时初始化
(2)懒汉模式实现二:局部静态变量
//代码实例(线程不安全) template class Singleton { public: static T& getInstance() { static T instance; return instance; } private: Singleton(){}; Singleton(const Singleton&); Singleton& operator=(const Singleton&); };
同样,静态局部变量的实现方式也是线程不安全的。如果存在多个单例对象的析构顺序有依赖时,可能会出现程序崩溃的危险。 对于局部静态对象的也是一样的。因为 static T instance;语句不是一个原子操作,在第一次被调用时会调用Singleton的构造函数,而如果构造函数里如果有多条初始化语句,则初始化动作可以分解为多步操作,就存在多线程竞争的问题。 为什么存在多个单例对象的析构顺序有依赖时,可能会出现程序崩溃的危险?
原因:由于静态成员是在第一次调用函数GetInstance时进行初始化,调用构造函数的,因此构造函数的调用顺序时可以唯一确定了。对于析构函数,我们只知道其调用顺序和构造函数的调用顺序相反,但是如果几个Singleton类的析构函数之间也有依赖关系,而且出现类似单例实例A的析构函数中使用了单例实例B,但是程序析构时是先调用实例B的析构函数,此时在A析构函数中使用B时就可能会崩溃。

解决方案:对于析构的顺序,我们可以用一个容器来管理它,根据单例之间的依赖关系释放实例,对所有的实例的析构顺序进行排序,之后调用各个单例实例的析构方法,如果出现了循环依赖关系,就给出异常,并输出循环依赖环。
饿汉模式
单例类定义的时候就进行实例化。因为main函数执行之前,全局作用域的类成员静态变量m_Instance已经初始化,故没有多线程的问题。
(1)饿汉模式实现一:直接定义静态对象
//代码实例(线程安全) //.h文件 class Singleton { public: static Singleton& GetInstance(); private: Singleton(){} Singleton(const Singleton&); Singleton& operator= (const Singleton&); private: static Singleton m_Instance; }; //CPP文件 Singleton Singleton::m_Instance;//类外定义-不要忘记写 Singleton& Singleton::GetInstance() { return m_Instance; } //函数调用 Singleton& instance = Singleton::GetInstance();
优点:
实现简单,多线程安全。
缺点:
a. 如果存在多个单例对象且这几个单例对象相互依赖,可能会出现程序崩溃的危险。原因:对编译器来说,静态成员变量的初始化顺序和析构顺序是一个未定义的行为;具体分析在懒汉模式中也讲到了。
b. 在程序开始时,就创建类的实例,如果Singleton对象产生很昂贵,而本身有很少使用,这种方式单从资源利用效率的角度来讲,比懒汉式单例类稍差些。但从反应时间角度来讲,则比懒汉式单例类稍好些。
使用条件:
a. 当肯定不会有构造和析构依赖关系的情况。
b. 想避免频繁加锁时的性能消耗
(2)饿汉模式实现二:静态指针 + 类外初始化时new空间实现
//代码实例(线程安全) class Singleton { protected: Singleton(){} private: static Singleton* p; public: static Singleton* initance(); }; Singleton* Singleton::p = new Singleton; Singleton* singleton::initance() { return p; }
2、 简述一下单例设计模式的懒汉式和饿汉式,如何保证线程安全
参考回答
懒汉式设计模式
懒汉模式的特点是延迟加载,比如配置文件,采用懒汉式的方法,配置文件的实例直到用到的时候才会加载,不到万不得已就不会去实例化类,也就是说在第一次用到类实例的时候才会去实例化。
饿汉模式
单例类定义的时候就进行实例化。因为main函数执行之前,全局作用域的类成员静态变量m_Instance已经初始化,故没有多线程的问题。
答案解析
懒汉设计模式两种实现方式线程不安全问题的解决:
(1)懒汉模式实现一:静态指针 + 用到时初始化
//代码实例(线程不安全) template<typename T> class Singleton {
public: static T& getInstance() {
if (!value_) {
value_ = new T();
}
return *value_;
}
private: Singleton();
~Singleton();
static T* value_; };
template<typename T> T* Singleton<T>::value_ = NULL;
在单线程中,这样的写法是可以正确使用的,但是在多线程中就不行了,该方法是线程不安全的。 a. 假如线程A和线程B, 这两个线程要访问getInstance函数,线程A进入getInstance函数,并检测if条件,由于是第一次进入,value为空,if条件成立,准备创建对象实例。 b. 但是,线程A有可能被OS的调度器中断而挂起睡眠,而将控制权交给线程B。 c. 线程B同样来到if条件,发现value还是为NULL,因为线程A还没来得及构造它就已经被中断了。此时假设线程B完成了对象的创建,并顺利的返回。 d. 之后线程A被唤醒,继续执行new再次创建对象,这样一来,两个线程就构建两个对象实例,这就破坏了唯一性。 另外,还存在内存泄漏的问题,new出来的东西始终没有释放,下面是一种饿汉式的一种线程安全的改进。
//代码实例(线程安全) emplate<typename T> class Singleton {
public: static T& getInstance() {
if (!value_) {
value_ = new T();
}
return *value_; }
private: class CGarbo {
public: ~CGarbo(){
if(Singleton::value_)
delete Singleton::value_;
}
};
static CGarbo Garbo;
Singleton();
~Singleton();
static T* value_; };
template<typename T> T* Singleton<T>::value_ = NULL;
在程序运行结束时,系统会调用Singleton的静态成员Garbo的析构函数,该析构函数会删除单例的唯一实例。使用这种方法释放单例对象有以下特征:
a. 在单例类内部定义专有的嵌套类; b. 在单例类内定义私有的专门用于释放的静态成员; c. 利用程序在结束时析构全局变量的特性,选择最终的释放时机。
(2)懒汉模式实现二:局部静态变量
//代码实例(线程不安全)
template<typename T>
class Singleton
{
public:
static T& getInstance()
{
static T instance;
return instance;
}
private:
Singleton(){};
Singleton(const Singleton&);
Singleton& operator
=(const Singleton&);
};
同样,静态局部变量的实现方式也是线程不安全的。如果存在多个单例对象的析构顺序有依赖时,可能会出现程序崩溃的危险。 对于局部静态对象的也是一样的。因为 static T instance;语句不是一个原子操作,在第一次被调用时会调用Singleton的构造函数,而如果构造函数里如果有多条初始化语句,则初始化动作可以分解为多步操作,就存在多线程竞争的问题。 为什么存在多个单例对象的析构顺序有依赖时,可能会出现程序崩溃的危险?
原因:由于静态成员是在第一次调用函数GetInstance时进行初始化,调用构造函数的,因此构造函数的调用顺序时可以唯一确定了。对于析构函数,我们只知道其调用顺序和构造函数的调用顺序相反,但是如果几个Singleton类的析构函数之间也有依赖关系,而且出现类似单例实例A的析构函数中使用了单例实例B,但是程序析构时是先调用实例B的析构函数,此时在A析构函数中使用B时就可能会崩溃。
//代码实例(线程安全)
#include <string>
#include <iostream>
using namespace std;
class Log
{
public:
static Log* GetInstance()
{
static Log oLog;
return &oLog;
}
void Output(string strLog)
{
cout<<strLog<<(*m_pInt)<<endl;
}
private:
Log():m_pInt(new int(3))
{
}
~Log()
{cout<<"~Log"<<endl;
delete m_pInt;
m_pInt = NULL;
}
int* m_pInt;
};
class Context
{
public:
static Context* GetInstance()
{
static Context oContext;
return &oContext;
}
~Context()
{
Log::GetInstance()->Output(__FUNCTION__);
}
void fun()
{
Log::GetInstance()->Output(__FUNCTION__);
}
private:
Context(){}
Context(const Context& context);
};
int main(int argc, char* argv[])
{
Context::GetInstance()->fun();
return 0;
}
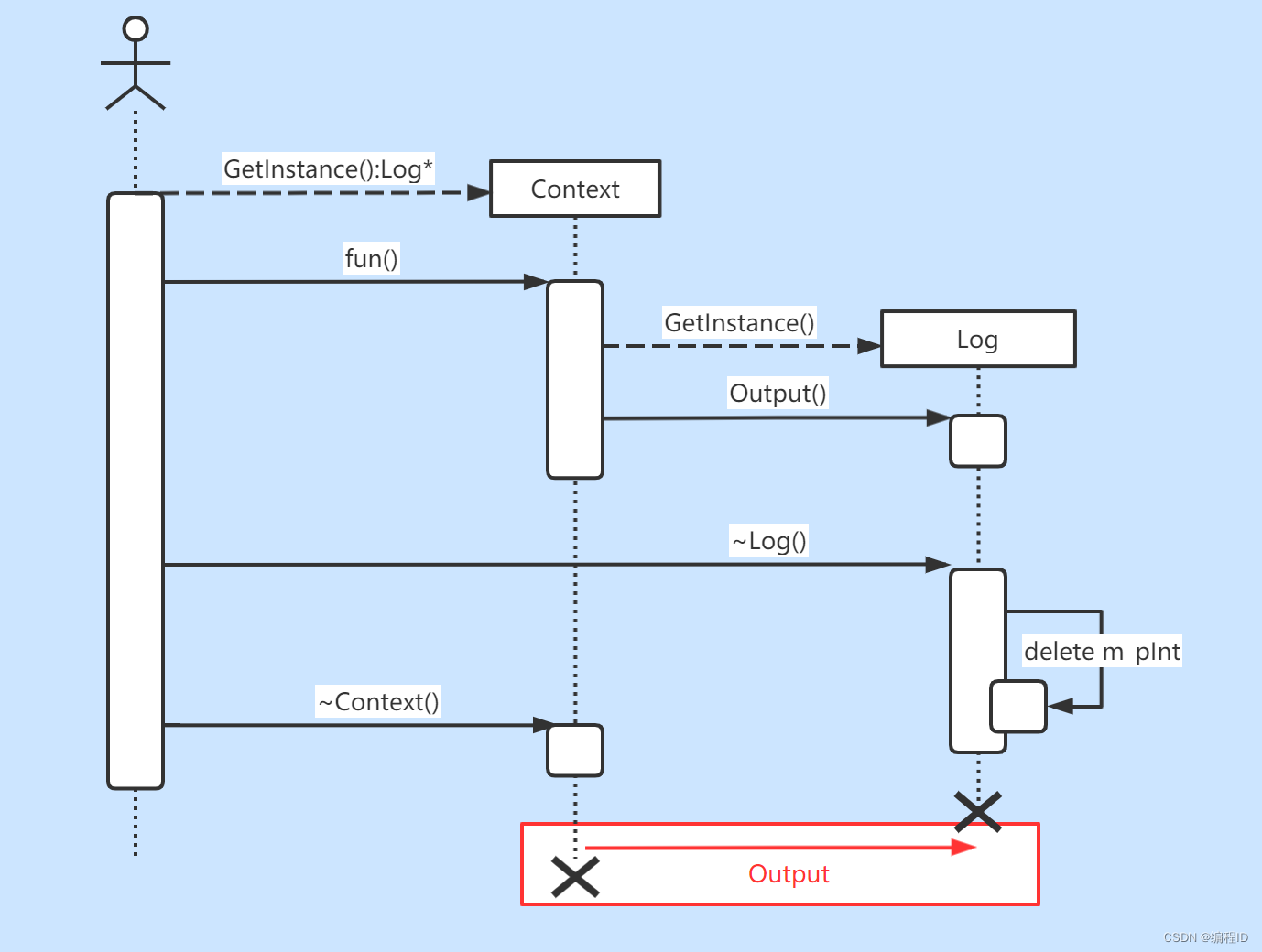
在这个反例中有两个Singleton: Log和Context,Context的fun和析构函数会调用Log来输出一些信息,结果程序Crash掉了,该程序的运行的序列图如下(其中画红框的部分是出问题的部分):
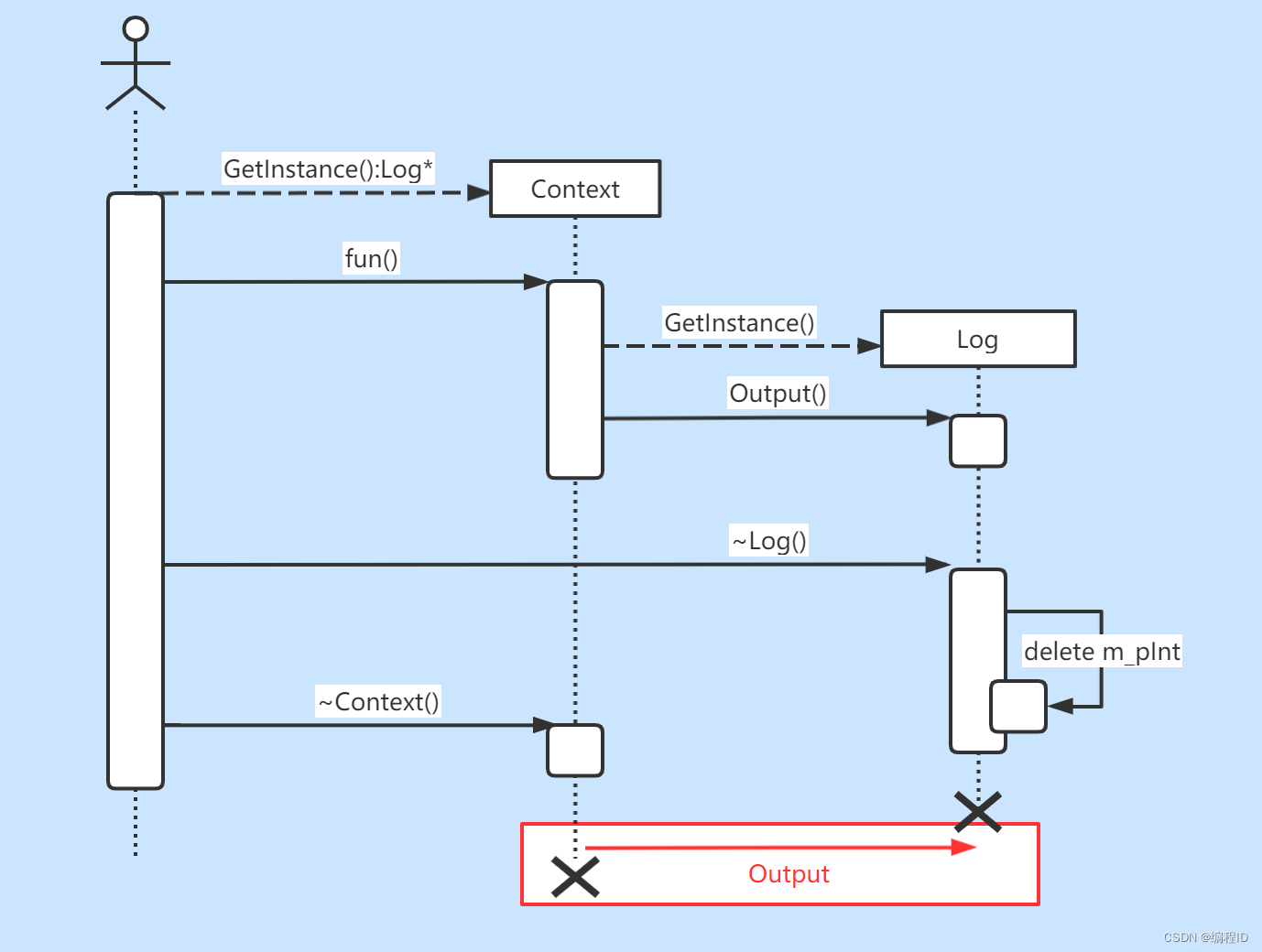
解决方案:对于析构的顺序,我们可以用一个容器来管理它,根据单例之间的依赖关系释放实例,对所有的实例的析构顺序进行排序,之后调用各个单例实例的析构方法,如果出现了循环依赖关系,就给出异常,并输出循环依赖环。
3、 请说说工厂设计模式,如何实现,以及它的优点
工厂设计模式的定义
定义一个创建对象的接口,让子类决定实例化哪个类,而对象的创建统一交由工厂去生产,有良好的封装性,既做到了解耦,也保证了最少知识原则。
工厂设计模式分类
工厂模式属于创建型模式,大致可以分为三类,简单工厂模式、工厂方法模式、抽象工厂模式。听上去差不多,都是工厂模式。下面一个个介绍:
(1)简单工厂模式
它的主要特点是需要在工厂类中做判断,从而创造相应的产品。当增加新的产品时,就需要修改工厂类。
举例:有一家生产处理器核的厂家,它只有一个工厂,能够生产两种型号的处理器核。客户需要什么样的处理器核,一定要显示地告诉生产工厂。下面给出一种实现方案:
//程序实例(简单工厂模式)
enum CTYPE {COREA, COREB};
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"SingleCore A"<<endl; }
};
//单核B
class SingleCoreB: public SingleCore
{
public:
void Show() { cout<<"SingleCore B"<<endl; }
};
//唯一的工厂,可以生产两种型号的处理器核,在内部判断
class Factory
{
public:
SingleCore* CreateSingleCore(enum CTYPE ctype)
{
if(ctype == COREA) //工厂内部判断
return new SingleCoreA(); //生产核A
else if(ctype == COREB)
return new SingleCoreB(); //生产核B
else
return NULL;
}
};
优点: 简单工厂模式可以根据需求,动态生成使用者所需类的对象,而使用者不用去知道怎么创建对象,使得各个模块各司其职,降低了系统的耦合性。
缺点:就是要增加新的核类型时,就需要修改工厂类。这就违反了开放封闭原则:软件实体(类、模块、函数)可以扩展,但是不可修改。
(2)工厂方法模式
所谓工厂方法模式,是指定义一个用于创建对象的接口,让子类决定实例化哪一个类。Factory Method使一个类的实例化延迟到其子类。
举例:这家生产处理器核的产家赚了不少钱,于是决定再开设一个工厂专门用来生产B型号的单核,而原来的工厂专门用来生产A型号的单核。这时,客户要做的是找好工厂,比如要A型号的核,就找A工厂要;否则找B工厂要,不再需要告诉工厂具体要什么型号的处理器核了。下面给出一个实现方案:
//程序实例(工厂方法模式)
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"SingleCore A"<<endl; }
};
//单核B
class SingleCoreB: public SingleCore
{
public:
void Show() { cout<<"SingleCore B"<<endl; }
};
class Factory
{
public:
virtual SingleCore* CreateSingleCore() = 0;
};
//生产A核的工厂
class FactoryA: public Factory
{
public:
SingleCoreA* CreateSingleCore() { return new SingleCoreA; }
};
//生产B核的工厂
class FactoryB: public Factory
{
public:
SingleCoreB* CreateSingleCore() { return new SingleCoreB; }
};
优点: 扩展性好,符合了开闭原则,新增一种产品时,只需增加改对应的产品类和对应的工厂子类即可。
缺点:每增加一种产品,就需要增加一个对象的工厂。如果这家公司发展迅速,推出了很多新的处理器核,那么就要开设相应的新工厂。在C++实现中,就是要定义一个个的工厂类。显然,相比简单工厂模式,工厂方法模式需要更多的类定义。
(3)抽象工厂模式
举例:这家公司的技术不断进步,不仅可以生产单核处理器,也能生产多核处理器。现在简单工厂模式和工厂方法模式都鞭长莫及。抽象工厂模式登场了。它的定义为提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。具体这样应用,这家公司还是开设两个工厂,一个专门用来生产A型号的单核多核处理器,而另一个工厂专门用来生产B型号的单核多核处理器,下面给出实现的代码:
//程序实例(抽象工厂模式)
//单核
class SingleCore
{
public:
virtual void Show() = 0;
};
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"Single Core A"<<endl; }
};
class SingleCoreB :public SingleCore
{
public:
void Show() { cout<<"Single Core B"<<endl; }
};
//多核
class MultiCore
{
public:
virtual void Show() = 0;
};
class MultiCoreA : public MultiCore
{
public:
void Show() { cout<<"Multi Core A"<<endl; }
};
class MultiCoreB : public MultiCore
{
public:
void Show() { cout<<"Multi Core B"<<endl; }
};
//工厂
class CoreFactory
{
public:
virtual SingleCore* CreateSingleCore() = 0;
virtual MultiCore* CreateMultiCore() = 0;
};
//工厂A,专门用来生产A型号的处理器
class FactoryA :public CoreFactory
{
public:
SingleCore* CreateSingleCore() { return new SingleCoreA(); }
MultiCore* CreateMultiCore() { return new MultiCoreA(); }
};
//工厂B,专门用来生产B型号的处理器
class FactoryB : public CoreFactory
{
public:
SingleCore* CreateSingleCore() { return new SingleCoreB(); }
MultiCore* CreateMultiCore() { return new MultiCoreB(); }
};
优点: 工厂抽象类创建了多个类型的产品,当有需求时,可以创建相关产品子类和子工厂类来获取。
缺点: 扩展新种类产品时困难。抽象工厂模式需要我们在工厂抽象类中提前确定了可能需要的产品种类,以满足不同型号的多种产品的需求。但是如果我们需要的产品种类并没有在工厂抽象类中提前确定,那我们就需要去修改工厂抽象类了,而一旦修改了工厂抽象类,那么所有的工厂子类也需要修改,这样显然扩展不方便。
答案解析
三种工厂模式的UML图如下:
简单工厂模式UML

4 、请说说装饰器计模式,以及它的优缺点
装饰器计模式的定义
指在不改变现有对象结构的情况下,动态地给该对象增加一些职责(即增加其额外功能)的模式,它属于对象结构型模式。
优点
(1)装饰器是继承的有力补充,比继承灵活,在不改变原有对象的情况下,动态的给一个对象扩展功能,即插即用;
(2)通过使用不用装饰类及这些装饰类的排列组合,可以实现不同效果;
(3)装饰器模式完全遵守开闭原则。
缺点
装饰模式会增加许多子类,过度使用会增加程序得复杂性。
装饰模式的结构与实现
通常情况下,扩展一个类的功能会使用继承方式来实现。但继承具有静态特征,耦合度高,并且随着扩展功能的增多,子类会很膨胀。如果使用组合关系来创建一个包装对象(即装饰对象)来包裹真实对象,并在保持真实对象的类结构不变的前提下,为其提供额外的功能,这就是装饰模式的目标。下面来分析其基本结构和实现方法。
装饰模式主要包含以下角色:
(1)抽象构件(Component)角色:定义一个抽象接口以规范准备接收附加责任的对象。
(2)具体构件(ConcreteComponent)角色:实现抽象构件,通过装饰角色为其添加一些职责。
(3)抽象装饰(Decorator)角色:继承抽象构件,并包含具体构件的实例,可以通过其子类扩展具体构件的功能。
(4)具体装饰(ConcreteDecorator)角色:实现抽象装饰的相关方法,并给具体构件对象添加附加的责任。
装饰模式的结构图如下图所示:

装饰模式的实现代码如下:
#include <string>
#include <iostream>
//基础组件接口定义了可以被装饰器修改的操作
class Component {
public:
virtual ~Component() {}
virtual std::string Operation() const = 0;
};
//具体组件提供了操作的默认实现。这些类在程序中可能会有几个变体
class ConcreteComponent : public Component {
public:
std::string Operation() const override {
return "ConcreteComponent";
}
};
//装饰器基类和其他组件遵循相同的接口。这个类的主要目的是为所有的具体装饰器定义封装接口。
//封装的默认实现代码中可能会包含一个保存被封装组件的成员变量,并且负责对齐进行初始化
class Decorator : public Component {
protected:
Component* component_;
public:
Decorator(Component* component) : component_(component) {
}
//装饰器会将所有的工作分派给被封装的组件
std::string Operation() const override {
return this->component_->Operation();
}
};
//具体装饰器必须在被封装对象上调用方法,不过也可以自行在结果中添加一些内容。
class ConcreteDecoratorA : public Decorator {
//装饰器可以调用父类的是实现,来替代直接调用组件方法。
public:
ConcreteDecoratorA(Component* component) : Decorator(component) {
}
std::string Operation() const override {
return "ConcreteDecoratorA(" + Decorator::Operation() + ")";
}
};
//装饰器可以在调用封装的组件对象的方法前后执行自己的方法
class ConcreteDecoratorB : public Decorator {
public:
ConcreteDecoratorB(Component* component) : Decorator(component) {
}
std::string Operation() const override {
return "ConcreteDecoratorB(" + Decorator::Operation() + ")";
}
};
//客户端代码可以使用组件接口来操作所有的具体对象。这种方式可以使客户端和具体的实现类脱耦
void ClientCode(Component* component) {
// ...
std::cout << "RESULT: " << component->Operation();
// ...
}
int main() {
Component* simple = new ConcreteComponent;
std::cout << "Client: I've got a simple component:\n";
ClientCode(simple);
std::cout << "\n\n";
Component* decorator1 = new ConcreteDecoratorA(simple);
Component* decorator2 = new ConcreteDecoratorB(decorator1);
std::cout << "Client: Now I've got a decorated component:\n";
ClientCode(decorator2);
std::cout << "\n";
delete simple;
delete decorator1;
delete decorator2;
return 0;
}
5 、请说说观察者设计模式,如何实现
观察者设计模式的定义
指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式、模型-视图模式,它是对象行为型模式。
优点
(1)降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。符合依赖倒置原则。
(2)目标与观察者之间建立了一套触发机制。
缺点
(1)目标与观察者之间的依赖关系并没有完全解除,而且有可能出现循环引用。
(2)当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
观察者设计模式的结构与实现
**观察者模式的主要角色如下:**
(1)抽象主题(Subject)角色:也叫抽象目标类,它提供了一个用于保存观察者对象的聚集类和增加、删除观察者对象的方法,以及通知所有观察者的抽象方法。
(2)具体主题(Concrete Subject)角色:也叫具体目标类,它实现抽象目标中的通知方法,当具体主题的内部状态发生改变时,通知所有注册过的观察者对象。
(3)抽象观察者(Observer)角色:它是一个抽象类或接口,它包含了一个更新自己的抽象方法,当接到具体主题的更改通知时被调用。
(4)具体观察者(Concrete Observer)角色:实现抽象观察者中定义的抽象方法,以便在得到目标的更改通知时更新自身的状态。
可以举个博客订阅的例子,当博主发表新文章的时候,即博主状态发生了改变,那些订阅的读者就会收到通知,然后进行相应的动作,比如去看文章,或者收藏起来。博主与读者之间存在种一对多的依赖关系。下面给出相应的UML图设计:

可以看到博客类中有一个观察者链表(即订阅者),当博客的状态发生变化时,通过Notify成员函数通知所有的观察者,告诉他们博客的状态更新了。而观察者通过Update成员函数获取博客的状态信息。代码实现不难,下面给出C++的一种实现。
//观察者
class Observer
{
public:
Observer() {}
virtual ~Observer() {}
virtual void Update() {}
};
//博客
class Blog
{
public:
Blog() {}
virtual ~Blog() {}
void Attach(Observer *observer) { m_observers.push_back(observer); } //添加观察者
void Remove(Observer *observer) { m_observers.remove(observer); } //移除观察者
void Notify() //通知观察者
{
list<Observer*>::iterator iter = m_observers.begin();
for(; iter != m_observers.end(); iter++)
(*iter)->Update();
}
virtual void SetStatus(string s) { m_status = s; } //设置状态
virtual string GetStatus() { return m_status; } //获得状态
private:
list<Observer* > m_observers; //观察者链表
protected:
string m_status; //状态
};
以上是观察者和博客的基类,定义了通用接口。博客类主要完成观察者的添加、移除、通知操作,设置和获得状态仅仅是一个默认实现。下面给出它们相应的子类实现。
//具体博客类
class BlogCSDN : public Blog
{
private:
string m_name; //博主名称
public:
BlogCSDN(string name): m_name(name) {}
~BlogCSDN() {}
void SetStatus(string s) { m_status = "CSDN通知 : " + m_name + s; } //具体设置状态信息
string GetStatus() { return m_status; }
};
//具体观察者
class ObserverBlog : public Observer
{
private:
string m_name; //观察者名称
Blog *m_blog; //观察的博客,当然以链表形式更好,就可以观察多个博客
public:
ObserverBlog(string name,Blog *blog): m_name(name), m_blog(blog) {}
~ObserverBlog() {}
void Update() //获得更新状态
{
string status = m_blog->GetStatus();
cout<<m_name<<"-------"<<status<<endl;
}
};
//测试案例
int main()
{
Blog *blog = new BlogCSDN("wuzhekai1985");
Observer *observer1 = new ObserverBlog("tutupig", blog);
blog->Attach(observer1);
blog->SetStatus("发表设计模式C++实现(15)——观察者模式");
blog->Notify();
delete blog; delete observer1;
return 0;
}
结束语 🥇🥇🥇
发现非常好用的一个刷题网站,可以检测大家的基础!大家一起努力!加油!!!
包含数据库、Java、C++、C、Python、前端等等题目,难度可以自行选择
在线编程出答案,(也可自行查看答案),也有选择题,非常方便
程序员刷题神器网站点击链接注册即可刷题
祝大家早日找到满意的工作!


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)