tensorrt-llm与vllm的量化性能比较
准备部署lora微调好的语言大模型,有tensorrt-llm和vllm两种加速策略可选,而量化策略也有llm.int8,gptq,awq可用, 怎样的组合才能获得最佳精度与速度呢,这是个值得探讨的问题,本文以llama-factory训练的qwen-7b的lora模型为基准,探究这几个组合对性能的影响。大模型的效果评估是件很难做的事,尤其是对文本生成类的lora模型,比较简单的办法是把生成文本与
工作告一段落,总结一下过程中大模型部署,量化相关的技术。有tensorrt-llm和vllm两种加速策略可选,而量化策略也有llm.int8,gptq,awq可用, 怎样的组合才能获得最佳精度与速度呢,这是个值得探讨的问题,本文以llama-factory训练的qwen-7b的lora模型为基准,探究这几个组合对性能的影响。
大模型的效果评估是件很难做的事,尤其是对文本生成类的lora模型,比较简单的办法是把生成文本与标签文本用chatgpt去评估打分。对于text2sql类的lora任务,容易处理些,分别使用生成的sql与标签sql去数据库查询,比较结果是否一致即可。
有时间再做专门的效果比较,本文仅比较量化相关的性能。
一 合并lora模型
使用llama-factory lora微调后的得到的是adapter层,需要与原模型merge后才能做后续各种量化
本文使用最新的llama-factory-0.7.1版本操作,使用yaml文件指定参数
理论上,想获得好的lora效果,要使用base模型,因为有更好的泛化性,不要用chat模型。
- lyb_qwen_lora_sft_merge.yaml
# model
model_name_or_path: /mnt/e/PyCharm/PreTrainModel/qwen_7b
adapter_name_or_path: /mnt/e/PyCharm/insteresting/LLaMA-Factory-0.7.1/src/saves/qwen_7b_sft/checkpoint-200
template: qwen
finetuning_type: lora
# export
export_dir: /mnt/e/PyCharm/PreTrainModel/qwen_7b_lora_merge
export_size: 2
export_device: cpu
# 为true,保存为safetensors格式
export_legacy_format: true
- 关于模型合并,官方代码使用命令行操作,不太习惯,这里改成脚本操作,路径指向上面的yaml文件
# -*- coding: utf-8 -*-
# @Time : 2024/5/25 22:21
# @Author : yblir
# @File : lyb_export_model.py
# explain :
# =======================================================
import yaml
from llmtuner.train.tuner import export_model
if __name__ == "__main__":
with open('../examples/yblir_configs/lyb_qwen_lora_sft_merge.yaml', 'r', encoding='utf-8') as f:
param = yaml.safe_load(f)
export_model(param)
二 模型量化
2.1 LLM.int量化
在推理时,直接在llma-factory中指定量化规格,里面使用的量化方法就是llm.int方法。

2.2 gptq量化
使用Qwen官方给的脚本(也是autogptq)run_gptq.py,参数指定如下:
https://github.com/QwenLM/Qwen

脚本是对autogpt代码的封装,量化时需要指定的参数有4个:
- –model_name_or_path: 在(一)中合并后的模型
- data_path: gptq量化需要指定的校准集
- –out_path: 量化后模型输出位置
- –bits: 量化规格,有int8,int4两种可选
下面重点讲下校准集的处理的
校准集尽量覆盖使用场景,官方的校准集是直接从sft数据中抽取的。
使用llama-factory lora微调时,数据集格式如下:
[
{
"instruction": "<question>:表格中所有人的平均年龄是多少?\nCREATE TABLE 人员分布 (姓名 VARCHAR(255),\n年龄 FLOAT,\n城市 VARCHAR(255),\n性别 VARCHAR(255),\n职业 VARCHAR(255));\nINSERT INTO 人员 (姓名, 年龄, 城市, 性别, 职业) VALUES (Bob, 35, salt lake city, male, engineer);",
"input": "",
"output": "SELECT avg(年龄) FROM 人员"
},
{...}
]
但Qwen量化时,需要的数据集格式如下:
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是一个语言模型,我叫通义千问。"
}
]
}
]
因此,需要转换一下格式,转成Qwen lora微调时的数据格式:
# -*- coding: utf-8 -*-
# @Time : 2024/5/26 10:47
# @Author : yblir
# @File : lyb_factory2qwen_format.py
# explain :
# =======================================================
import json
qwen_format_list = []
with open('/mnt/e/PyCharm/insteresting/LLaMA-Factory-0.7.1/data/qwen-7b-sql-gptq.json', 'r', encoding='utf-8') as f:
data = json.load(f)
for i, item in enumerate(data):
temp = {}
temp['id'] = f'identity_{i}'
temp['conversations'] = [{'from': 'user', 'value': item['instruction']},
{'from': 'assistant', 'value': item['output']}]
qwen_format_list.append(temp)
with open('/mnt/e/PyCharm/insteresting/LLaMA-Factory-0.7.1/data/qwen-7b-sql-gptq2.json', 'w', encoding='utf-8') as f:
json.dump(qwen_format_list, f, indent=4, ensure_ascii=False)
接下来,通过指定–bits可以获得int8或int4量化模型
在量化完成后,还必须拷贝被量化模型的*.py, *.cu, *.cpp(这两个文件如果有就复制) 文件和 generation_config.json 文件复制到量化模型的输出目录下。

2.3 autoawq量化
https://github.com/casper-hansen/AutoAWQ
awq的量化也需要数据集,只是对数据集的要求没有gptq那么敏感,这里只测速度,就用内置的默认数据集。
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = '/mnt/e/PyCharm/PreTrainModel/qwen_7b_lora_merge'
quant_path = '/mnt/e/PyCharm/PreTrainModel/qwen_7b_awq_int4'
quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM" }
# Load model
model = AutoAWQForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
2.4 tensorrt-llm编译
在新版tensorrt-llm中官方已经提供qwen系列加速代码,想起在0.5版本刚发布时没有qwen,只有llama,只能把llama的model.py拷贝一份,修改代码去适配qwen,现在能直接用,真是太幸福了~
官方另有提供weight only的量化方法:int8,int4, 但他们自己都表示weight only的方法掉点严重,因此这里我们只测试gptq-int4和awq-int4.
ps: 从官方测试结果看,fp8效果很好,如果显卡是30系列及以上,优先推荐使用fp8量化,精度损失更小。
examples/qwen文件夹内:
2.4.1 gptq量化 在前面已gptq量化好的基础上,编译tensorrt引擎
- 量化
python3 convert_checkpoint.py --model_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_gptq_int4 \
--output_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_gptq_int4_trt \
--dtype float16 \
--use_weight_only \
--weight_only_precision int4_gptq \
--per_group
- 编译tensorrt引擎,tensorrt_llm/commands/build.py
python tensorrt_llm/commands/build.py --checkpoint_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_gptq_int4_trt \
--output_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_int4_GPTQ/1-gpu \
--gemm_plugin float16
2.4.2 awq量化
tensorrt-llm不支持直接使用awq量化好的模型,但提供了定制版的awq量化方法,这个功能似乎不太完善,仅支持2个数据集,不能传lora微调的数据。
如果校准数据集下载不到,下载到本地修改加载路径, 这里使用的是pileval数据集:

python ../quantization/quantize.py --model_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_lora_merge \
--dtype float16 \
--qformat int4_awq \
--awq_block_size 128 \
--output_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_quantized_int4-awq_trt \
--calib_size 32
python tensorrt_llm/commands/build.py --checkpoint_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_quantized_int4-awq_trt \
--output_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_int4_AWQ/1-gpu \
--gemm_plugin float16
2.4.3 耗时统计
tensorrt-llm耗时通过运行提供的run.py统计
# 统计gptq
python3 run.py --input_text "<question>:表格中所有人的平均年龄是多少?\nCREATE TABLE 人员分布 (姓名 VARCHAR(255),\n年龄 FLOAT,\n城市 VARCHAR(255),\n性别 VARCHAR(255),\n职业 VARCHAR(255));\nINSERT INTO 人员 (姓名, 年龄, 城市, 性别, 职业) VALUES (Bob, 35, salt lake city, male, engineer);" \
--max_output_len=50 \
--tokenizer_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_chat_lora_merge \
--engine_dir=/home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_chat_int4_GPTQ/1-gpu \
--run_profiling
# 统计awq
python3 run.py --input_text "<question>:表格中所有人的平均年龄是多少?\nCREATE TABLE 人员分布 (姓名 VARCHAR(255),\n年龄 FLOAT,\n城市 VARCHAR(255),\n性别 VARCHAR(255),\n职业 VARCHAR(255));\nINSERT INTO 人员 (姓名, 年龄, 城市, 性别, 职业) VALUES (Bob, 35, salt lake city, male, engineer);" \
--max_output_len=50 \
--tokenizer_dir /home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_chat_lora_merge \
--engine_dir=/home/TensorRT-LLM-0.9.0/checkpoints/qwen_7b_int4_AWQ/1-gpu \
--run_profiling
三 模型推理耗时统计
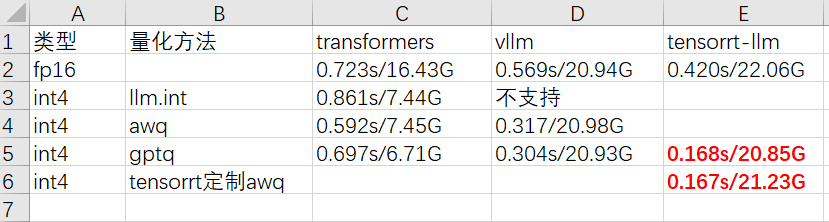
综合以上量化方法,可以得到以下耗时统计:

通过比较可知:
- vllm能获得比transformers多60%的提速,另外,如果不手动限度显存使用量,会默认占满所有显存。
- tensorrt-llm提速最多,英伟达还是NB!int4量化后提速3~4倍,显存问题同上。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 26
26 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)