Boosting算法
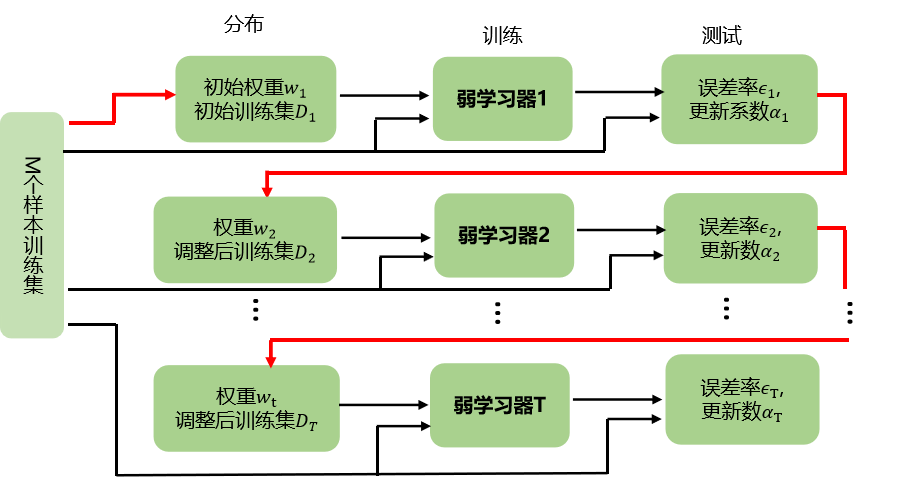
它首先使用一个基本分类器(如决策树、支持向量机等)对样本进行分类,然后根据分类结果对错分样本的权重进行调整,使错分样本的权重增加,而正确分类样本的权重减少。使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的羽学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整
回顾Boosting算法基本原理
Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,
使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的羽学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
一、Bossting结构

- 从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现对训练样本分布进行调整,使得弱学习器1做错的训练样本在后续得到更多关注
- 基于调整后的样本分布来训练弱学习器2,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器进行加权结合,得到最终的强学习器
Adaboost(Adaptive Boosting)是一种集成学习方法,其主要思想是通过串行训练多个弱分类器来构建一个强分类器。具体来说,Adaboost将每个训练样本赋予一个权重,初始时每个样本的权重相等。它首先使用一个基本分类器(如决策树、支持向量机等)对样本进行分类,然后根据分类结果对错分样本的权重进行调整,使错分样本的权重增加,而正确分类样本的权重减少。接着,Adaboost基于更新后的权重再次训练基本分类器,如此循环迭代多次,直到训练出预定数目的基本分类器。
二、Boosting算法(仅针对二分类的算法)
- 是集成算法中的一种,也是一类算法的总称
- Boosting的含义是提升,每次训练的时候都对上一次的训练进行改进提升
2.1 AdaBoost
Boosting族算法最著名算法是: AdaBoost
- 自适应提升算法
- Adaptive Boosting是Boosting算法的一种实现
算法表达式:
G_i(x)为弱分类器,α_i表示其在分类器中的权重
2.2弱分类器在强分类器中的权重是如何计算
如果弱分类器的分类效果好,那么权重应该比较大
如果弱分类器的分类效果一般,权重应该降低
公式如下:

其中e_i代表第i个分类器的分类错误率
2.3每次迭代训练的过程中,如何得到最优弱分类器
- 训练最弱分类器
AdaBoost 算法是通过改变样本的数据分布来实现的
会判断每次训练的样本是否正确分类
正确分类的样本,降低它的权重
被错误分类的样本,增加它的权重
AdaBoost基于上一次得到的分类准确率,来确定这次训练样本中每个样本的权重
然后将修改过权重的新数据集传递给下一层的分类器进行训练通过每一轮训练样本的动态权重,可以让训练的焦点集中到难分类的样本上
AdaBoost算法步骤
- 初始化训练样本的权值分布,每个训练样本的权值应该相等(如果一共有N个样本,则每个样本的权值为1/N;
- 依次构造训练集并训练弱分类器。如果一个样本被准确分类,那么它的权值在下一个训练集中就会降低;相反,如果它被分类错误,那么它在下个训练集中的权值就会提高。权值更新过后的训练集会用于训练下一个分类器。
- 将训练好的弱分类器集成为一个强分类器,误差率小的弱分类器会在最终的强分类器里占据更大的权重,否则较小。

-
样本的权重集合
-
- 每个样本都对应一个权重(样本权重公式)
-
- 在构建第一个弱模型之前,所有的训练样本的权重是一样的
-
- 第一个模型完成后,要加大那些被这个模型错误分类(分类问题)、或者说预测真实差值较大(回归问题)的样本的权重
-
- 依次迭代,最终构建多个弱模型
每个弱模型所对应的训练数据集样本是一样的,只是数据集中的样本权重不一样
- 依次迭代,最终构建多个弱模型
-
弱模型的权重集合
-
- 每个弱模型都对应一个权重(分类器权重公式)
-
- 精度越高(分类问题的错分率越低,回归问题的错误率越低)的模型,其权重就越大,最终集成结果时,其话语权也就越大
三、Adaboost的Scikit-learn实现
3.1AdaBoostClassifier 类
sklearn.ensemble.AdaBoostClassifier(base_estimator=None, *, n_estimators=50, learning_rate=1.0, algorithm=‘SAMME.R’, random_state=None)

3.2方法
- fit(X_train, y_train): 在训练集上训练模型
- predict(X): 用训练好的模型来预测待预测的数据集X,返回测试集对应的标签 y
- score(X_test, y_test): 返回的是测试集上的预测的准确率
- predict_proba(X): 返回数组,数组的元素依次是预测集X属于各个类别的概率
3.3属性
- base_estimator_:The base estimator from which the ensemble is grown.
- estimators_ : 拟合的子估计器的集合
- classes_ : 类别标签(单一输出问题),或者类别标签的数组序列(多输出问题)
- n_classes_ : 类别的数量(单输出问题),或者一个序列,包含每一个输出的类别数量(多输出问题)
- n_features_ : 执行拟合时的特征数量
- n_outputs_ :执行拟合时的输出数量
- feature_importances_ : 特征的重要性(值越高,特征越重要)
四、AdaBoost算法问题
4.1 简述AdaBoost算法权值更新的方法
- 初始化权值分布;
- 找到误差最小的弱分类器;·计算弱分类器的权值;
- 更新下一轮样本的权值分布;
- 集台多个弱分类器成一个最终的强分类器。
4.2 Boosting和Bagging之间的区别,从偏差方差的角度解释Adaboost?
集成学习提高学习精度,降低模型误差,模型的误差来自于方差和偏差,其中:
- Bagging方式是降低模型方差,一般选择多个相差较大的模型进行Bagging。
- Boosting是主要是通过降低模型的偏差来降低模型的误差。其中Adaboost每一轮通过误差来改变数据的分布,使偏差减小。
4.3 为什么Adaboost方式能够提高整体模型的学习精度?
根据前向分布加法模型,Adaboost算法每一次都会降低整体的误差,虽然单个模型误差会有波动,但是整体的误差却在降低,整体模型复杂度在提高。
AdaBoost的优点和缺点
- Adaboost提供一种框架,在框架内可以使用各种方法构建子分类器。可以使用简单的弱分类器,不用对特征进行筛选,也不存在过拟合的现象。
- Adaboost算法不需要弱分类器的先验知识,最后得到的强分类器的分类精度依赖于所有弱分类器。无论是应用于人造数据还是真实数据,Adaboost都能显著的提高学习精度。
- Adaboost算法不需要预先知道弱分类器的错误率上限,且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,可以深挖分类器的能力。Adaboost可以根据弱分类器的反馈,自适应地调整假定的错误率,执行的效率高。
- Adaboost对同一个训练样本集训练不同的弱分类器,按照一定的方法把这些弱分类器集合起来,构造一个分类能力很强的强分类器,即“三个臭皮匠赛过一个诸葛亮”。
缺点:

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)