Web 自动化测试(基于Pytest极简)
pytest 是一个非常流行且成熟的,全功能的 Python 测试框架,适用于单元测试、UI 测试、接口测试。它和单元测试框架 unittest 类似,但是 pytest 更简洁、高效。所以很多测试人员学习 unittest 和 pytest 之后,都会感觉到 pytest 才是做测试的最好框架。这是因为 pytest 有许多优点。简单灵活,容易上手。支持参数化。可标记测试功能与属性。
Pytest 初体验
在使用 Python 进行 Web UI 自动化测试时,我们除了使用 unittest 单元测试框架,还可以使用 pytest,本节实验就给大家简单的介绍一下 pytest。
环境配置
本系列实验我们借助 VS Code 工具编写代码,使用的 Python 版本是 3.8,大家可以在命令行输入 python -V 查看 Python 版本。操作截图如下:

添加 Python 插件
下面需要大家手动在 VS Code 中添加 Python 插件,并且选择解释器,如此我们才可以在 VS Code 中直接运行 Python 代码。
-
启动 VS Code 程序。
-
安装 Python 插件。
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件并且插入。一般情况下,搜索出来的第一个就是我们需要的。截图如下:

插件安装后在编写 Python 脚本时便可使用代码自动补全功能。
- 选择 Python 解释器。
使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,然后选择 /usr/bin/python 中的 Python3.8 解释器。截图如下所示:

至此,环境准备完成。
pytest 简介
pytest 是一个非常流行且成熟的,全功能的 Python 测试框架,适用于单元测试、UI 测试、接口测试。它和单元测试框架 unittest 类似,但是 pytest 更简洁、高效。所以很多测试人员学习 unittest 和 pytest 之后,都会感觉到 pytest 才是做测试的最好框架。这是因为 pytest 有许多优点。
pytest 主要优点如下:
- 简单灵活,容易上手。
- 支持参数化。
- 可标记测试功能与属性。
- pytest 具有很多第三方插件,并且可以自定义扩展,比较好用的如 pytest-selenium(集成 Selenium)、pytest-html(生成 HTML 测试报告)、pytest-rerunfailures(失败 case 重复执行)等。
- 使用 skip 和 xfail 可以处理不成功的测试用例。
- 可通过 xdist 插件分发测试到多个 CPU。
- 允许直接使用 assert 进行断言,而不需要使用 self.assert *。
- 方便在持续集成工具中使用。
接下来我们安装 pytest,打开 Xfce 终端,输入命令 sudo pip install pytest 然后回车,操作截图如下:

安装完成后,输入命令 pytest -V 或 pytest --version 检查 pytest 是否安装成功,操作截图如下:

如果出现 pytest version 等版本信息,则表示安装成功。
实例体验
我们在 /home/shiyanlou/ 下新建一个文件夹 test,然后使用 VS Code 打开 test 文件夹。再在 test 文件夹下新建一个 py 文件,并且命名为 test_example.py 。编写 test_example.py 内容如下:
import pytest
def add(a, b):
return a + b
def test_add1():
print("add(2, 3)的结果是:{}".format(add(2, 3)))
assert add(2, 3) == 5
def test_add2():
assert add(2, 3) == 6
if __name__ == "__main__":
pytest.main()
提示:输入中文可使用搜狗输入法。虚拟环境中已经帮助大家安装好了搜狗输入法。可以双击桌面上的搜狗输入法图标激活搜狗输入法。然后右键点击虚拟环境右下角的键盘图标,而后选择搜狗输入法,便可以得到切换。
运行 pytest 标记的测试用例有两种方法,在 py 文件中添加 pytest.main() ,使用 VS Code 工具右上角的运行按钮执行。另一种方法是在命令行中使用命令运行,本次实验我们采用在命令行中运行。
打开 VS Code 的终端,通过命令 cd /home/shiyanlou/test/ 进入到 test 文件夹下,输入 pytest 后回车,操作截图如下:

从运行结果中可以看到一些信息:
- 可以看到运行的平台,运行的 Python 版本,执行的根目录。
- 收集的测试用例,collected 2 items 表示总共检测到两条测试用例。
- 执行的测试文件及测试文件中测试用例的结果,其中 . 表示测试通过的用例,F 表示测试失败的用例。
- [100%] 指运行所有测试用例的总体进度。
- 如果测试用例运行不通过,则会显示具体的测试用例,并且标注出错的地方。
- 在最后,会对运行的整体情况给出一个简单的统计。例如 1 failed, 1 passed in 0.09s。
注解:
我们在命令行中输入 pytest 后,会遵照下面几条标准去收集测试文件:
- 如果未指定参数,则从 testpaths (如果配置)或当前目录收集。
- 递归到目录文件中。
- 搜索 test_*.py 或 *_test.py 文件。
收集到测试文件后,再从测试文件中收集测试用例。收集测试用例的标准是:
- 不在类里面的,以 test 开头的函数或方法。
- 以 Test 开头的类,在此类下面的,以 test 开头的函数或方法。但是类中不能有构造函数 __init__ 方法。
参数说明
在命令行中执行 pytest 命令时还可以添加一些参数,添加某些特定意义的事件,比如 -v、-q。
我们还是在 VS Code 的终端,通过命令 cd /home/shiyanlou/test/ 进入到 test 文件夹下,然后使用命令添加参数执行文件。
-v 参数
-v 参数用于查看测试的详细信息。
在命令行中执行命令 pytest -v ,操作截图如下:

测试结果是 test_example.py::test_add1 PASSED [ 50%]。比起不添加参数 -v 的输出结果更加详细,详细到每条测试用例的测试名字、结果、测试整体进度都会显示出来,而不仅仅再是一个结果标识。
如果需要在脚本中添加运行代码,则可写成 pytest.main(['-v']) 。添加其他参数运行也是类似的。
-q 参数
-q 与 -v 相反,可简化输出信息。
在命令行中执行命令 pytest -q ,操作截图如下:

通过查看运行结果可知,-q 参数简化了许多,只使用 . 和 F 标注出了测试用例运行后是成功的还是失败的。比直接使用命令 pytest 还简洁。
-s 参数
-s 是将我们在测试用例中的调式信息进行输出,比如 print 打印信息。
在命令行中执行命令 pytest -s ,操作截图如下:

从结果中可以看到,打印出了我们在函数 test_add1 中添加的打印信息。在test_example.py 后面输出了打印信息:add(2, 3)的结果是:5 。
其他参数
在前面给大家介绍了 -v、-q、-s 参数,在 pytest 还有其他好多参数可以使用,我们可以通过命令 pytest -h 查看帮助信息。使用命令 pytest -h 后,部分内容信息截图如下:

通过帮助信息可以知道 pytest 的使用语法和所有能够使用的参数。我们可以看到 pytest 命令语法是:
pytest [options] [file_or_dir] [file_or_dir] [...]
即 pytest 后面接固定参数,然后接文件目录或文件。
下面给大家列出一些比较常见的参数:
| 参数 | 含义 | 示例 |
|---|---|---|
| -l | 由于失败的测试用例会被堆栈追踪,所以所有的局部变量及其值都会显示出来 | pytest -l |
| -k | 模糊匹配时使用 | pytest -k |
| -m | 标记测试并且分组,运行时可以快速选择分组并且运行 | pytest -m |
| -x | pytest 运行时遇到失败的测试用例后会终止运行 | pytest -x |
| --collect-only | 显示要执行的用例,但是不会执行 | pytest --collect-only |
| --ff | 也可以写成 --failed-first ,先执行上次失败的测试,然后执行上次正常的测试 | pytest --ff |
| --lf | 也可以写成 --last-failed ,只执行上次失败的测试 | pytest --lf |
| --setup-show | 用于查看具体的 setup 和 teardown 顺序 | pytest --setup-show |
| --sw | 也可以写成 --stepwise ,测试失败时退出并从上次失败的测试继续下一次 | pytest --sw |
| --junit-xml=path | 在指定路径创建 JUnit XML 样式的报告文件 | pytest --junit-xml=path |
| --color=color | 终端信息彩色输出(是/否/自动),可选值 yes、no、auto | pytest --color=color |
Pytest之mark标记
pytest.mark 是用来对测试方法进行标记的一个装饰器,主要作用是在执行过程中对标记的测试用例进行判断且选择性的执行。本次实验会为大家详细介绍 mark 标记的使用。
标记测试函数
mark 装饰器使用起来非常方便。在使用之前我们先来看看可以怎么使用。在命令行模式下执行命令 pytest --markers 查看官方提供的 mark 说明,操作截图如下:

下面对 mark 标记做以下说明:
- @pytest.mark.filterwarnings(warning) :在标记的测试方法上添加警告过滤。
- @pytest.mark.skip(reason=None) :执行时跳过标记的测试方法,reason 为跳过的原因,默认为空。
- @pytest.mark.skipif(condition) :通过条件判断是否跳过标记的测试方法。如果 condition 的判断结果为真则跳过,否则不跳过。
- @pytest.mark.xfail(condition, reason=None, run=True, raises=None, strict=False) : 如果条件 condition 的值为 True,则将测试的预期结果标记为 False。
- @pytest.mark.parametrize(argnames, argvalues) :测试函数参数化,即调用多次测试函数,依次传递不同的参数。 如果 argnames 只有一个名称,则 argvalues 需要以列表的形式给出值;如果 argnames 有多个名称,则 argvalues 需要以列表嵌套元组或列表的形式给出值。如果 parametrize 的参数名称和 fixture 名称一样,会覆盖掉 fixture。例如:@parametrize('arg1', [1,2]) 将对测试函数调用两次,第一次调用 arg1 = 1,第二次调用 arg1 = 2。@parametrize('arg1, arg2', [(1,2), (3,4)]) 将对测试函数调用两次,第一次调用 arg1 = 1, arg2 = 2;第二次调用 arg1 = 3, arg2 = 4。
- @pytest.mark.usefixtures(fixturename1, fixturename2, ...) :将测试用例标记为需要指定的所有 fixture。和直接使用 fixture 的效果是一样的,只不过不需要把 fixture 名称作为参数放置在方法声明当中,并且可以使用 class( fixture 暂时不能用于 class )。
- @pytest.mark.tryfirst :标记一个挂钩实现函数,使所标记的测试方法可以首先或尽早执行。在实际情况中,如果有 fixture 的 parametrize,测试方法执行的顺序会比较复杂。
- @pytest.mark.trylast :标记一个挂钩实现函数,使所标记的测试方法可以最后或尽可能晚执行。和 tryfirst 相反。
接下来会为大家详细介绍最常用的 skip、skipif、xfail、parametrize 装饰器。
skip
如果在测试用例函数之上添加装饰器 @pytest.mark.skip(reason=None) ,则在执行中遇到该测试用例函数会跳过不执行。reason 是方便我们在代码中做说明,为什么要跳过,或者跳过的原因是什么,但是 reason 对结果是没有任何影响的。
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_skip.py ,然后编写如下内容:
import pytest @pytest.mark.skip() def test_skip1(): assert 1 == 1 @pytest.mark.skip(reason="跳过该条测试用例") def test_skip2(): assert 1 == 1 if __name__ == "__main__": pytest.main(['-v'])
我们定义了两个测试用例函数 test_skip1 和 test_skip2 ,并且都添加了 @pytest.mark.skip 装饰器,其中函数 test_skip2 的装饰器中添加了跳过的原因。
下面我们通过 VS Code 工具右上角的执行按钮执行文件,执行后截图如下所示:

从结果中可以看到,两条测试用例的结果都被标示为 SKIPPED。SKIPPED 代表的就是跳过。
skipif
skipif 是对事物进行判断,从而决定是否跳过测试用例函数。如果满足条件则跳过,否则执行。
在做 skipif 实验之前,我们先来查看系统信息,在命令行中依次执行如下语句,可获取当前环境是什么系统,代码如下:
python import sys sys.platform
操作截图如下:

从结果中可知当前系统是 linux。
下面我们进行 skipif 实验。通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_skipif.py ,然后编写如下内容:
import pytest
@pytest.mark.skipif('sys.platform == "linux"',reason="不适合在 linux 系统运行")
def test_skipif1():
assert 1 == 1
@pytest.mark.skipif('sys.platform != "linux"')
def test_skipif2():
assert 1 == 2
if __name__ == "__main__":
pytest.main(['-v'])
我们定义了两个测试用例函数 test_skipif1 和 test_skipif2 。在 test_skipif1 函数上添加 skipif 判断条件装饰器,如果当前系统是 linux 则结果记为 True。在 test_skipif2 函数上也添加 skipif 判断条件装饰器,如果当前系统不是 linux 系统则结果记为 True。只有判断条件为 True 时才会跳过对应的测试用例函数。
我们使用 VS Code 工具执行脚本,结果截图如下所示:

由于我们当前系统是 linux,所以 test_skipif1 函数上添加的装饰器条件判断结果是 True,因此跳过了该测试用例函数。 test_skipif2 函数上添加的装饰器条件判断结果是 False,所以执行了。
xfail
xfail 表示的是可以预期到结果是失败的测试。xfail 装饰器解决的是对于很清楚知道它的结果是失败的,但是又不想直接跳过的测试方法,通过添加 xfail 装饰器可以在结果中给出明显的标识。
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_xfail.py ,然后编写如下内容:
import pytest @pytest.mark.xfail(reason="0 不能做除数") def test_xfail1(): assert 2 / 0 == 1 @pytest.mark.xfail def test_xfail2(): assert 2 / 1 == 2 if __name__ == "__main__": pytest.main(['-v'])
我们定义了两个测试用例函数 test_xfail1 和 test_xfail2 ,并且都添加了装饰器 xfail,其中 test_xfail1 函数的断言是失败的,test_xfail2 函数的断言是正确的。
使用 VS Code 工具执行脚本,结果截图如下所示:

从结果中可以得知,测试用例函数 test_xfail1 的结果是 XFAIL,test_xfail2 函数的结果是 XPASS。也就是说,使用 xfail 装饰器标记的测试用例函数并不会跳过,还是会继续执行的,执行的结果也会正常显示,只不过会在执行的结果前会添加一个 X 做出标识。
parametrize
parametrize 用于对测试方法进行数据参数化,使得同一个测试方法可以结合不同的测试数据进行测试。
单个参数
如果被装饰的函数参数只有一个,则需要以列表的形式给出值。
我们通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_parametrize1.py,然后编写如下内容:
import pytest
list = [1, 2, 3]
@pytest.mark.parametrize('num', list)
def test_parametrize(num):
assert num in list
if __name__ == "__main__":
pytest.main(['-v'])
定义一个列表 list 和一个测试用例函数 test_ parametrize 。并且在 test_ parametrize 函数上添加装饰器 @pytest.mark.parametrize('num', list) ,在 pytest 执行时就会遍历 list 中的元素并且依次作为参数传入 test_parametrize 。
使用 VS Code 工具执行脚本,结果截图如下所示:

通过测试结果我们看到 test_parametrize1.py 文件后出现了 3 条测试成功的标识,并且测试用例函数 test_parametrize 出现的三次都带有参数值,与列表 list 中的元素一致。
多个参数
如果被装饰的函数有多个参数,则需要以列表嵌套元组或列表的形式给出值。当然以元祖套元祖的形式也是允许的。
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_parametrize2.py ,然后编写如下内容:
import pytest
list = [(1, 2, 3), (2, 3, 5), (3, 4, 7)]
@pytest.mark.parametrize('num1, num2, sum', list)
def test_parametrize(num1, num2, sum):
assert num1 + num2 == sum
if __name__ == "__main__":
pytest.main(['-v'])
定义了一个列表 list = [(1, 2, 3), (2, 3, 5), (3, 4, 7)] 和一个测试用例函数 test_ parametrize ,在 test_ parametrize 函数前添加装饰器 @pytest.mark.parametrize('num1, num2, sum', list) , 测试用例函数 test_ parametrize 断言是第一个参数和第二个参数之和等于第三个参数。
使用 VS Code 工具执行脚本,结果截图如下所示:

通过测试结果我们看到 test_parametrize2.py 文件后出现了 3 条测试成功的标识,并且测试函数 test_parametrize 出现的三次都带有参数值,与列表 list 中的元祖元素一致。
直接标记
mark 标记是通过在测试方法上添加装饰器进行标记,还有一种标记方法是在命令行中使用参数进行标记。
使用参数进行标记的方法有两种:一种是直接标记,即只运行某个固定的 py 文件,或在 py 文件后通过添加双引号 (::) 运行固定的测试方法;另一种是通过参数 -k 进行模糊匹配标记。
运行指定 py 文件
打开 VS Code 工具的终端,使用命令 cd /home/shiyanlou/test/ 进入 test 文件夹下。
接着我们使用命令 pytest -v test_parametrize2.py 运行指定的 py 文件 test_parametrize2.py 。操作后结果截图如下所示:

可以看到只运行了 test_parametrize2.py 文件中测试用例函数 test_parametrize 的三条测试用例。
运行指定测试用例
进入 VS Code 工具的终端,在 /home/shiyanlou/test/ 文件夹下使用命令 pytest -v test_xfail.py::test_xfail2 运行文件 test_xfail.py 中的测试用例函数 test_xfail2 。操作截图如下所示:

从结果中可以看到只运行了 test_xfail.py 文件中的 test_xfail2 测试用例函数。
如果一次需要执行多个测试用例函数,则可写成如下语句的形式:
pytest C:\test_1.py::test_1 C:\test_2.py::test_2
模糊匹配
在直接标记中一次只能执行指定的测试文件或测试函数。如果某些测试用例有共同的特点,我们可使用模糊匹配标记,一次执行多个具有共同特点的测试用例函数。模糊匹配标记使用很简单,在使用 pytest 运行时添加参数 -k ,后面添加匹配的字符串即可进行匹配。
模糊匹配可以匹配测试 py 文件,也可匹配测试函数。
下面我们匹配测试用例函数名中含有 parametrize 字符串的文件和函数。
进入 VS Code 工具的终端,在 /home/shiyanlou/test/ 文件夹下执行命令 pytest -v -k parametrize 。操作截图如下所示:

从结果中可以看到,匹配到了 test_parametrize1.py 和 test_parametrize2.py 两个文件中的六条测试用例。
自定义标记
我们可以使用 mark 进行自定义标记,只需在测试方法前添加装饰器 pytest.mark.标记名 即可。标记名建议根据项目取比较容易识别的词,例如:commit、merger、done、undo 等。
使用时,只需要通过参数 -m 加上标记名就可执行被标记的测试用例函数。
我们通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_customize.py,然后编写如下内容:
import pytest @pytest.mark.done def test_customize_done(): assert 1 == 1 @pytest.mark.undo def test_customize_undo1(): assert 1 == 1 @pytest.mark.undo def test_customize_undo2(): assert 1 == 1 if __name__ == "__main__": pytest.main(['-v'])
定义了三个测试用例函数 test_customize_done、test_customize_undo1 和 test_customize_undo2 。其中 test_customize_done 函数添加装饰器 @pytest.mark.done ,test_customize_undo1 和 test_customize_undo2 添加装饰器 @pytest.mark.undo 。
进入 VS Code 工具的终端,在 /home/shiyanlou/test/ 文件夹下执行命令 pytest -v -m "undo" 。操作截图如下所示:

从结果中可以看到,只执行了 test_customize.py 文件中被装饰器 @pytest.mark.undo 标记的两条测试用例函数。
细心的同学已经发现在结果中弹出了警告(由于截图内容有限,上面的截图中未能显示出警告提示),我们可以通过添加参数 --disable-warnings 禁用。但是一般情况下不建议禁用,因为某些警告可能会转换成错误。
Pytest 之 fixture 固件使用
fixture 是 pytest 中非常重要的一个内容,用于测试用例函数在执行前的数据准备、环境搭建和执行后的数据销毁、环境恢复等工作。与单元测试框架 unittest 中的 setup、teardown 功能类似,但是 pytest 中提供的 fixture 更方便使用,灵活度也更高。还允许代码运行时在测试用例和测试用例之间传递参数和数据。本次实验将会带大家熟悉 fixture 的功能。
fixture 的使用
如果我们在写自动化脚本时需要将一个函数当作 fixture 使用,则只需要在该函数上面添加装饰器 @pytest.fixture() 便可。
实例体验
下面我们来写一个简单的示例进行体验一下。
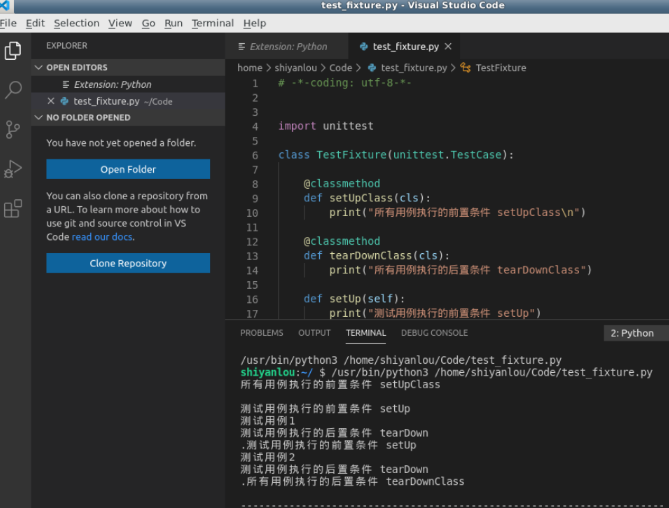
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_fixture.py,编写如下内容:
import pytest
@pytest.fixture()
def fixture_demo():
print("这是一个 fixture 示例,在测试用例函数之前执行")
def test_fixture1(fixture_demo):
print("fixture 示例中第一个测试用例函数")
def test_fixture2(fixture_demo):
print("fixture 示例中第二个测试用例函数")
if __name__ == "__main__":
pytest.main(['-v', '-s', 'test_fixture.py'])
我们定义了一个函数 fixture_demo ,并且添加了装饰器 @pytest.fixture() ,使其可以作为 fixture 使用。然后写了两个测试用例函数 test_fixture1 和 test_fixture1 ,并且将 fixture_demo 以参数的形式传入,此时 fixture_demo 就与两个测试用例函数形成了关联。
使用语句 pytest.main(['-v', '-s', 'test_fixture.py']) 执行测试脚本,表示只运行 test_fixture.py 文件, 参数 -v 和 -s ,我们在第一节实验中已经使用过了,就不再做解释。
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下所示:

从结果中可以看到,两个测试用例函数 test_fixture1 和 test_fixture1 在执行前都执行了 fixture 函数 fixture_demo 。也就是说在每条测试用例函数执行前都执行一次。在此大家就会体会到,和 unittest 单元测试框架中 setup 具有一样的效果。
fixture 定义
下面我们来看下源码中 fixture 的定义。
源码中 fixture 的定义是 fixture(scope="function", params=None, autouse=False, ids=None, name=None) 。我们可以看到有 scope、params、autouse、ids、name 共 5 个参数可以使用。下面对这 5 个参数做简单的解释:
- scope:定义 fixture 作用域,有 4 个可选值,分别是 function、class、module、package/session ,默认是 function。在下面小节 fixture 作用域中会详细作出说明。
- params:参数化,会使用多个参数调用 fixture 函数。在下面小节 fixture 参数化中会详细作出说明。
- autouse:布尔类型参数,如果是 True ,则所有测试用例函数都会执行此固件函数;如果是 False ,则只会对添加了固件函数的测试用例函数使用。默认值是 False 。
- ids:每个参数都与列表中的字符串 id 对应,因此它们是测试 id 的一部分。如果没有提供 id 将会从参数中自动生成。
- name:fixture 的名称,默认为装饰器的名称。如果 fixture 在它定义的模块中使用,那么这个 fixture 功能名称就会被请求的 fixture 功能参数遮盖。我们就可以通过将装饰函数命名为 fixture_ <fixturename> ,然后使用 @pytest.fixture(name ='<fixturename>') 解决这个问题。
fixture 作用域
fixture 作用域是用来指定固件的使用范围,通过参数 scope 可声明作用范围。scope 参数有 4 个可选值,分别是 function、class、module、package/session,下面对这 4 个可选项做简单的说明:
- function:函数级别,也是默认值。意思是在每个测试用例函数执行前都会执行一次。
- class:类级别,每个测试类执行前执行一次。
- module:模块级别,每个模块执行前执行一次,也就是每个 .py 文件执行前都会执行一次。
- package/session:会话级别,一次测试只执行一次,即多个文件调用一次,可以跨 .py 文件。
下面我们来做一个小示例进行说明。
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_fixture_scope.py,编写如下内容:
import pytest
@pytest.fixture(scope='session')
def fixture_session():
print("session 级别的 fixture")
@pytest.fixture(scope='module')
def fixture_module():
print("module 级别的 fixture")
@pytest.fixture(scope='class')
def fixture_class():
print("class 级别的 fixture")
@pytest.fixture(scope='function')
def fixture_function():
print("function 级别的 fixture")
def test_scope(fixture_session, fixture_module, fixture_class, fixture_function):
print("fixture scope 示例中的测试用例函数")
if __name__ == "__main__":
pytest.main(['-v', '--setup-show', 'test_fixture_scope.py'])
我们定义了四个不同级别的固件函数 fixture_session、fixture_module、fixture_class、fixture_function 。然后写了一个测试用例函数 test_scope ,并且将四个固件函数都以参数的形式传入到测试用例函数。
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下所示:

添加参数 --setup-show(查看具体的 setup 和 teardown 顺序)运行脚本,可以清楚地看到各个固件的作用域和执行顺序。
从结果中可以看到,添加了不同作用域的四个 fixture 函数,执行时有明显的先后顺序。我们也可以通过 S、M、C、F 等标识来知道 fixture 的作用范围。
- S:表示作用范围最大的 fixture,session 会话级。
- M:表示 module 模块级。
- C:表示 class 类级别的 fixture。
- F:表示 function 函数级。
mark.usefixtures
在上面的示例体验中,我们可以看到,如果某个测试用例函数需要使用 fixture ,则只需要将指定的 fixture 以参数的形式传入到测试用例函数中即可。但是,如果我们有一个测试类,测试类中有很多测试用例方法,这些测试用例方法都需要使用某个固定的 fixture ,那么每个测试用例方法都以参数的形式传入 fixture ,是不是觉的很累?很不舒服。
这个时候我们就可以选择在 class 类上添加装饰器 @pytest.mark.usefixtures('fixture_name') ,使整个 class 类都使用 fixture。
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_fixture_mark_use.py,然后编写如下内容:
import pytest
@pytest.fixture(scope='function')
def fixture_mark_use():
pass
@pytest.mark.usefixtures('fixture_mark_use')
class TestFixture():
def test_mark_use1(self):
pass
def test_mark_use2(self):
pass
if __name__ == "__main__":
pytest.main(['-v', '--setup-show', 'test_fixture_mark_use.py'])
我们定义了一个固件函数 fixture_mark_use ,并将作用级别设置为 function 。然后写了一个测试类 TestFixture ,测试类中又添加了两个测试用例方法 test_mark_use1 和 test_mark_use2 。测试类上添加了装饰器 @pytest.mark.usefixtures('fixture_mark_use') ,使 fixture 函数 fixture_mark_use 作用于整个测试类。
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下所示:

从结果中可以看到,测试类下的每个测试用例方法在执行前都先执行了 fixture_mark_use 函数。
autouse
我们在测试用例函数中通过以参数的形式使用 fixture 固件。但是大家有没有想过,当测试用例函数特别多时,每次都以参数的形式传入会不会显得有些麻烦呢?当然有同学可能会想到使用 mark.usefixtures 作用在类上进行解决,当然是可以的。但是如果我们的测试用例函数都不在类中呢?又该怎样解决。
其实在将具体的函数标记为 fixture 时,我们就可以通过将参数 autouse 设置为 True 来达到自动将测试固件添加到测试用例函数上。
参数 autouse 的类型是布尔类型,默认值是 Fasle,不启用。如果设置为 True 则开启自动使用 fixture 功能,如此每次使用时不需要当作参数传入也可使用测试固件。
下面我们来做一个小示例进行说明。
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_fixture_autouse.py ,编写如下内容:
import pytest
@pytest.fixture(autouse=True)
def fixture_autouse():
print("\n 自动使用 fixture")
def test_fixture_autouse():
print("fixture autouse 示例中的测试用例函数")
class TestFixture():
def test_autouse(self):
print("fixture autouse 示例中的测试用例方法")
if __name__ == "__main__":
pytest.main(['-v', '-s', '--setup-show', 'test_fixture_autouse.py'])
我们定义了一个固件函数 fixture_autouse ,并且将参数 autouse 设置为 True 。接着写了一个测试用例函数 test_fixture_autouse 和一个测试类 TestFixture ,测试类下添加了一个测试用例方法 test_autouse 。
在 pytest.main() 中添加参数 -v、-s 和 –-setup-show。然后点击 VS Code 工具右上角的执行按钮运行 test_fixture_autouse.py 脚本,截图如下所示:

从结果中可以看到,无论是测试用例函数还是测试用例方法,在执行前都先执行了 fixture_autouse 函数。也就是说只要将参数 autouse 设置为 True ,则在运行脚本中就会自动启用 fixture 。
参数化
在第二次实验 mark 标记中,我们已经使用过装饰器 @pytest.mark.parametrize() 对参数化有过讲解。本次我们将使用固件中的参数 params 实现参数化。
在测试中如果我们需要使用不同的参数和基本相同逻辑来构造环境或者结果稍微有所不同的场景,这个时候就可以利用 fixture 的参数化(parametrizing)来实现。
下面我们来做一个小示例进行说明。
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_fixture_params.py ,编写如下内容:
import pytest @pytest.fixture(params=[ (1, 2, 3), (2, 3, 5), (3, 4, 7) ]) def fixture_params(request): return request.param def test_add(fixture_params): assert fixture_params[2] == fixture_params[0] + fixture_params[1] if __name__ == "__main__": pytest.main(['-v', 'test_fixture_params.py'])
我们对 fixture_params 函数添加 fixture 时,在参数 params 添加了一个数组,数组中有三个元祖类型的数据。然后写了一个测试用例函数 test_add,并且将 fixture_params 函数以参数的形式传入。
代码在执行时 fixture 参数化会使用 pytest 内置的固件 request,并通过 request.param 来获取参数。
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下所示:

从结果中可以看到,测试用例函数总共运行了 3 次,与我们添加的 3 组测试数据数量相同。
Pytest 之 fixture 固件功能
本次实验将会为大家介绍 fixture 更多的一些用法。带领大家结合关键词 yield 设置后置处理,多个文件共享相同的 fixture,以及内置 fixture 三个方面继续学习 fixture 固件。
yield 的使用
在上节实验 autouse 的讲解中,大家有没有发现一个问题,在测试结果显示的测试脚本中的 print() 内容都是在测试用例函数之前,测试用例函数执行之后就没有内容打印。那么,如果需要在测试用例执行之后有所操作该怎么办呢?
现在我们就来解决这个问题。
在 pytest 中使用 fixture,如果想要在测试用例函数执行之后进行某些操作,就需要关键字 yield 配合,如果没有 yield 就相当于只有 setup 而没有 teardown。如果在函数中添加了 yield,则 yield 之后的内容就相当是 teardown。我们在写测试脚本时,通常会使用关键字 yield, 这样就可以将同一组的准备、销毁工作写在一起,理解起来更清晰。
接下来通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_fixture_yield.py ,编写如下内容:
import pytest
@pytest.fixture()
def fixture_yield():
print("\n 测试用例函数执行前操作")
yield
print("\n 测试用例函数执行后操作")
def test_fixture_yield1(fixture_yield):
print("fixture yield 示例中的第一个测试用例函数")
def test_fixture_yield2(fixture_yield):
print("fixture yield 示例中的第二个测试用例函数")
if __name__ == "__main__":
pytest.main(['-v', '-s', 'test_fixture_yield.py'])
上面的代码比较简单,相信经过前面的 fixture 的学习不难理解。在此就不再做说明了。
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下所示:

从结果中可以看到,两个测试用例函数 test_fixture_yield1 和 test_fixture_yield2 在执行前都运行了固件函数 fixture_yield 中关键字 yield 之前的语句。两个测试用例函数在执行后都运行了固件函数中关键字 yield 之后的语句。
注意:
- 如果测试用例中的代码出现异常或者断言失败,并不会影响固件函数中关键字 yield 后面代码的执行。
- 如果固件函数中 yield 之前的代码出现异常,那么测试方法不会继续执行,关键字 yield 后面的代码也不会再执行。
- yield 只是一个关键字,后面或前面的代码执行范围取决于 fixture 装饰器给出的作用域。
共享 fixture 功能
在 pytest 框架下提供了一个共享 fixture 的功能。意思是我们只需要创建一个名为 conftest.py 的文件,然后将需要共享的功能写在 conftest.py 文件里面,在脚本运行时其他测试文件就会自动查找使用。
在使用 conftest.py 文件时需要注意以下几点:
- conftest.py 文件名称需固定,不能更改。
- conftest.py 需要与运行的测试用例文件在同一个 pakage 下。
- 使用 conftest.py 时不需要 import 导入,pytest 会自动识别。
- 如果 conftest.py 放在项目的根目录下,则对全局生效。如果放在某个 package 下则只对 package 下的用例文件生效。
- 允许存在多个 conftest.py 文件。
- conftest.py 文件不能被其他文件导入。
- 所有同目录测试文件运行前都会执行 conftest.py 文件。
接下来通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件夹 FileConftest ,然后在 FileConftest 下创建一个 __init__.py 文件、一个 conftest.py 文件和两个测试文件 test_file1.py 、test_file2.py 。
创建后的文件目录如下截图所示:

编写 /home/shiyanlou/test/FileConftest/conftest.py 文件内容如下:
import pytest
@pytest.fixture
def fixture_conftest():
print("\n 测试用例函数开始执行")
yield
print("\n 测试用例函数结束执行")
我们定义了一个固件函数 fixture_conftest ,使测试用例函数在执行前打印“测试用例函数开始执行”内容,测试用例函数在执行后打印“测试用例函数结束执行”内容。
在 /home/shiyanlou/test/FileConftest/test_file1.py 文件中定义一个测试用例函数 test_conftest1 ,内容如下:
import pytest
def test_conftest1(fixture_conftest):
print("fixture conftest 示例中的第一个测试用例函数")
在 /home/shiyanlou/test/FileConftest/test_file2.py 文件中定义两个测试用例函数 test_conftest2 和 test_conftest3 ,内容如下:
import pytest
def test_conftest2(fixture_conftest):
print("fixture conftest 示例中的第二个测试用例函数")
def test_conftest3(fixture_conftest):
print("fixture conftest 示例中的第三个测试用例函数")
打开 VS Code 的终端,通过命令 cd /home/shiyanlou/test/FileConftest 进入到 FileConftest 文件夹下,输入 pytest -v -s 运行脚本,操作截图如下所示:

从结果中可以看到,所有的测试用例函数在运行前和运行后都执行共享文件 /home/shiyanlou/test/FileConftest/conftest.py 中的 fixture 函数 fixture_conftest 。因为 conftest.py 文件中函数 fixture_conftest 作用域是 function 级别的,所以每个测试用例函数都会使用。如果想要在程序运行过程中只运行一次,那么只需要将 fixture 作用域修改为会话 session 级别即可。
内置 fixture
上面我们学习了 pytest 中固件的使用。其实在 pytest 测试框架中已经内置了许多 fixture ,我们可以直接使用,不需要再单独编写代码。使用内置的 fixture 可以大幅简化测试工作,提高工作效率。
打开命令行工具,使用命令 pytest --fixtures 或 pytest --funcargs 查看所有可用的 fixture,包括内置的、插件中的以及当前项目定义的,操作截图如下所示:

对截图中部分插件做以下说明:
-
pytestconfig:使用内置固件 pytestconfig 能够方便地读取命令行参数和配置文件,可以通过命令行参数、选项、配置文件、插件、运行目录等方式来控制 pytest。准确地说,pytestconfig 是 request.config 的快捷方式,在 pytest 文档中也被称为“ pytest 配置对象”。
-
capsys:用于捕获 stdout 和 stderr 的内容,并临时关闭系统输出。
-
recwarn:用于检查待测代码产生的警告信息,有两种使用方法,一种是当作参数传入被测方法中,例如 test_warn(recwarn) ;另一种是当作方法使用 pytest.warns() 。
-
monkeypatch:程序在运行时动态修改类或模块,测试结束后无论结果成功或失败代码都会还原,不会影响下次运行。
-
tmp_path:在临时目录的根目录中创建一个独立的临时目录,方便测试时使用。默认情况下,临时目录创建为系统临时目录的子目录。
-
tmpdir:用于临时文件和目录的管理,在测试开始前创建临时文件目录,并在测试结束后进行销毁。作用范围是在函数级别。
-
tmpdir_factory:与 tmpdir 使用和作用是一样的,只不过作用范围是在会话级别。
-
cache:能够存储一段测试会话的信息并且在下一段测试会话中使用。
固件 tmpdir
tmpdir 用于临时文件和目录的管理,在测试开始前创建临时文件目录,并在测试结束后进行销毁。适用于在测试过程中创建一个临时文件,并且对文件进行读写操作的场景。
接下来通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 test_fixture_tmpdir.py ,编写如下内容:
import pytest
def test_tmpdir(tmpdir):
# 创建临时目录
tmp_dir = tmpdir.mkdir('testdir')
# 创建临时 txt 文件
tmp_file = tmp_dir.join('tmpfile.txt')
# 对临时文件写入内容
tmp_file.write("这是一个临时文件")
# 对写入临时文件中的内容进行验证
assert tmp_file.read() == "这是一个临时文件"
if __name__ == "__main__":
pytest.main(['-v', 'test_fixture_tmpdir.py'])
在 tmpdir 中使用 tmpdir.mkdir() 可创建临时目录,使用 tmpdir.join() 可创建临时文件。
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下所示:

从结果中可以看到测试用例是通过的,断言是成功的,显然临时目录和临时文件是创建成功的,并且可以对创建的文件进行读写操作。
下面给大家再简单的介绍一下 tmpdir_factory。
tmpdir_factory 与 tmpdir 使用和作用是一样的,但是 tmpdir 的作用范围是函数级别的,而 tmpdir_factory 的作用范围是会话级别的,在 session、module、class 和 function 中都可以使用。
使用也很简单,给大家写一个简单的示例,代码如下:
import pytest
@pytest.fixture(scope='module')
def fixture_tmpdir_factory(tmpdir_factory):
# 创建临时目录
tmp_dir = tmpdir_factory.mktemp('testdir')
# 创建临时 txt 文件
tmp_file = tmp_dir.join('tmpfile.txt')
# 对临时文件写入内容
tmp_file.write("这是一个临时文件")
def test_tmpdir_factory(fixture_tmpdir_factory):
pass
固件 cache
在自动化测试中,我们有时候会希望每个测试的会话可以重复,不会因为上一段会话的运行影响到下一段的测试行为。对于这种将上一段会话信息传递给下一段的工作可以使用 pytest 框架内置的 cache 固件,该固件能够存储一段测试会话的信息并且在下一段测试会话中使用。
先给大家介绍一下 cache 固件中一些命令参数,然后再练习。
cache 固件中经常使用的命令参数有以下几个:
- --lf:也可以写成 --last-failed,只执行上次失败的测试,如果没有失败的测试用例则全部执行。
- --ff:也可以写成 --failed-first,先执行上次失败的测试,然后执行上次正常的测试。执行过程中可能会对测试进行重置,从而导致重复执行 fixture。
- --cache-show:显示缓存内容,不执行收集或测试。
- --cache-clear:在测试运行开始时删除所有缓存的内容。
实例演示
接下来通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件夹 FileCache ,再在 FileCache 下新建文件 test_fixture_cache.py ,编写如下内容:
import pytest def test_cache1(): assert 1 == 1 def test_cache2(): assert 0 def test_cache3(): assert True if __name__ == "__main__": pytest.main(['-v', 'test_fixture_cache.py'])
上面我们写了三个测试用例函数,其中 test_cache2 函数断言是失败的,test_cache1 和 test_cache3 是成功的。
打开 VS Code 的终端,通过命令 cd /home/shiyanlou/test/FileCache 进入到 FileCache 文件夹下,输入 pytest -v 执行脚本,操作截图如下所示:

查看缓存
脚本执行完成后,使用命令 pytest --cache-show 查看缓存的内容,操作截图如下所示:

从结果中可以看到缓存的内容,上次执行失败的是 test_cache.py 文件中的 test_cache2 测试用例函数。
细心的同学可能已经发现了,我们每次运行脚本后都会在脚本所在的文件下生成一个 .pytest_cache 文件夹,这里面存放的也是缓存文件。截图如下所示:

例如 /home/shiyanlou/test/FileCache/.pytest_cache/v/cache 下的 lastfailed 文件,就是专门存放上次执行失败的测试用例。其内容如下:
{
"test_fixture_cache.py::test_cache2": true
}
根据缓存执行脚本
接下来我们使用 --lf 参数只执行上次失败的测试用例函数。在 VS Code 的终端中进入 /home/shiyanlou/test/FileCache 文件夹下,输入命令 pytest -v --lf 后回车,操作截图如下所示:

结果很明显,只执行了上次失败的测试用例函数 test_cache2 。
Pytest 之插件
pytest 测试框架是非常受大家喜欢的一个框架,不只是因为它拥有非常灵活地测试固件 fixture,还是因为它拥有非常强大的插件生态系统,所以有时候也称 pytest 是一个插件化的测试平台。本次实验将会给大家简单的介绍插件,并且会实例体验 Allure 插件。
插件简介
在 pytest 插件生态系统中,有许多非常强有力的插件。我们可以使用不同的插件满足测试过程中的一些特殊需求,这就使得 pytest 拥有了更多的便利与可能性。
在 pytest Plugin Compatibility 的网站中可以查看针对不同 pytest 和 Python 版本的几乎所有的插件列表。
如下截图中就是 pytest Plugin Compatibility 网站列出的部分插件状态:

下面给大家列举一些非常实用的插件:
- pytest-sugar:改变 pytest 的默认外观,增加了一个进度条,并立即显示失败的测试。使用非常方便,只要安装了 pytest-sugar 插件并且使用 pytest 运行测试就可获得更漂亮、更有用的输出。
- pytest-xdist:允许开启多个 worker 进程,同时执行多个测试用例,达到并发运行的效果,提升了构建效率。
- pytest-allure-adaptor:生成漂亮的 Allure 报告,在持续集成中推荐使用。
- pytest-instafail:在测试运行期间报告失败。修改 pytest 默认行为,将失败和错误的代码立即显示,改变了 pytest 需要完成每个测试后才显示的行为。
- pytest-rerunfailures:失败用例重跑,是个非常实用的插件。如果对失败的测试用例进行重新测试,将有效地提高报告的准确性。
- pytest-ordering:可以指定一个测试套中所有用例执行顺序。pytest 默认情况下是根据测试方法名由小到大执行的,使用 pytest-ordering 插件则可改变这种运行顺序。
- pytest-cov:覆盖率报告,与分布式测试兼容。支持 pytest 的代码覆盖,显示已经被测和没有测试的代码,还包括项目的测试覆盖率。
- pytest-django:为 Django 应用程序和项目添加 pytest 支持。
- pytest-timeout: 根据函数标记或全局定义使测试超时。
插件安装与卸载
插件安装
pytest 的第三方插件安装很简单,和 Python 的包安装类似,使用 Python 包管理工具 pip 安装即可。
插件安装语法为:pip install pytest-NAME ,NAME 为插件名。
例如我们安装插件 pytest-ordering。
打开命令行工具,输入命令 pip install pytest-ordering ,操作截图如下所示:

插件卸载
卸载插件和安装插件类似,只需要将 install 换成 uninstall。
插件卸载语法为:pip uninstall pytest-NAME ,NAME 为插件名。
例如我们卸载插件 pytest-ordering。
在命令行工具输入命令 pip uninstall pytest-ordering ,操作截图如下所示:

插件 sugar
插件 sugar 是一个比较有意思的插件,笔者一直很喜欢。pytest-sugar 改变了 pytest 的默认外观,增加了一个进度条,并立即显示失败的测试。它不需要配置,只需安装 pytest-sugar,然后使用 pytest 运行测试脚本,便可获得一个漂亮、有用的输出。
打开命令行工具,输入命令 pip install pytest-sugar 安装插件 sugar,操作截图如下所示:

然后使用命令 cd /home/shiyanlou/test/ 进入 test 文件夹下。
接着输入命令 pytest -v ,然后回车。运行 test 文件夹下所有的测试文件,操作截图如下所示:

大家可以看到,结果展示与没有安装插件 sugar 之前显示是不同的。从截图中可以看到每一个测试用例函数执行完成后都会有一个进度条展示执行进度。失败的测试用例也会显示出失败的信息。
插件 Allure
Allure 是一款非常轻量级且灵活的开源测试报告生成框架,它支持绝大多数测试框架, 例如 TestNG、Pytest、JUint 等,使用起来很简单,也可配合持续集成工具 Jenkins 使用。
如果要使用 Allure 则需要安装 Allure 程序,如果要在 pytest 框架下使用 Allure,还需要安装 Allure Pytest 插件。只有安装了 Allure Pytest 插件,才可以通过 pytest 命令运行测试脚本生成 Allure 需要的数据,然后在通过 Allure 工具将这些数据生成 HTML 测试报告。
Allure 安装
Allure 是基于 Java 语言的一个程序,所以在使用时需要 Java 环境。在我们的虚拟环境中已经安装好了 Java,我们可以直接使用。
提示: 如果大家以后需要使用 Allure,请确保已经安装了 Java JDK。最后是 Java1.8+ 。
安装 Allure 程序,只需要进入到 Allure 下载界面 进行下载,然后解压使用。
由于我们的虚拟环境是 Linux 系统,所以可以通过 npm 命令进行安装,在命令行工具中输入安装命令 npm install -g allure-commandline --save-dev 。
等到安装完成,我们在命令行中输入命令 allure 进行验证是否安装成功。操作截图如下所示:

Allure Pytest 安装
Allure Pytest 是 pytest 的一个插件,所以遵循 pytest 插件安装的规则,在命令行工具中执行命令 pip install allure-pytest 即可完成安装。操作截图如下所示:

安装成功后会在最后面出现 Successfully installed 信息。
Allure 使用
Allure 的使用需要分两步走,先生成 JSON 数据文件,然后利用 JSON 数据文件生成 HTML 测试报告。
生成测试数据
在命令行模式下使用命令 cd /home/shiyanlou/test/ 进入 test 文件夹下。
然后输入命令 pytest --alluredir ./result/ 执行测试脚本,并且产生测试数据。添加 --alluredir 参数,意思是将测试数据保存。如上命令就是将测试数据保存到当前文件夹下的 result 文件中。操作截图如下所示:

脚本执行完成后,会在当前文件夹下创建一个 result 文件夹,存放产生的 JSON 格式测试数据文件。产生的文件如下截图:

生成 HTML 报告
接下来我们进入 cd /home/shiyanlou/test/ 文件夹下,利用产生的测试数据通过命令 allure generate ./result/ -o ./report/ --clean 生成 HTML 格式的测试报告。
对上面命令中的参数做以下说明:
- generate:生成测试报告,后面跟测试数据路径。
- --clear:也可以写成 -c,清除之前的旧报告。
- -o:也可以写成 --report-dir 或 --output,生成报告的路径。
在命令行模式下进入 cd /home/shiyanlou/test/ 文件夹下,执行命令 allure generate ./result/ -o ./report/ --clean ,操作截图如下所示:

命令执行完成后会在当前文件夹下生成一个 report 文件夹,里面存放的便是测试报告文件。 report 文件夹下内容如下截图:

下面我们在浏览器中打开 /home/shiyanlou/test/report/ 下的 index.html 文件,查看测试报告内容。截图如下所示:

注意: 由于跨域等问题的影响,在打开 index.html 后可能会显示数据一直加载,404 等现象。此时我们可在 VS Code 工具中安装插件 Live Server,然后右键点击,选择 【Open with Live Server】进行打开。
打开之后大家可以通过左边菜单,以不同的形式查看报告内容。
数据库操作 PyMySQL
在自动化测试中经常需要用到大量的数据,由于数据的类型多样,所以我们需要将这些数据按一定的规则存储,以便使用时易于获取。存贮这些数据最好的解决方案就是数据库。而 MySQL 数据库以入门容易、语法简单、功能强大、适应性广等特点,得到了广泛应用。本次实验为大家介绍在 Python3 中使用 PyMySQL 连接数据库,并实现简单的增删改查。
创建数据库
在我们的实验环境中已经安装了 MySQL 的一个分支数据库 MariaDB ,它与 MySQL 在绝大多数功能上是兼容的,所以我们可以使用它来替代 MySQL ,因为它在某些时候占用的系统资源更少,性能却并不减弱。
在使用过程中,我们可以把 MariaDB 当作 MySQL ,所有的命令都是一样。
启动 MySQL
在命令行中使用下面命令进行启动:
sudo service mysql start
提示:如果虚拟环境进行了保存,重新启动后需要再次执行上面的命令启动 MySQL。
连接 MySQL
命令行中输入 mysql -u root -p ,然后输入回车键,回车后提示需要输入密码,然后继续输入回车键,就可以连接数据库。由于我们的数据库没有设置密码,所以直接使用命令 mysql -u root 便可以连接 MySQL 数据库。操作如下截图:

查看数据库
使用 SHOW DATABASES; 命令可以查看 MySQL 中已经存在那些数据库。如下截图:

可以看到已经存在三个数据库,information_schema,mysql,perfomance_schema。这是 MySQL 默认存在的三个库。
创建数据库
下面我们使用命令 CREATE DATABASE test_case; 创建一个数据库 test_case。
然后使用 SHOW DATABASES; 命令查看数据库。如下截图:

从截图中可以看到,数据库 test_case 已经创建成功。
退出数据库
使用 exit 命令,或者快捷键 Ctrl + C 可以退出数据库。
连接数据库
安装 PyMySQL
PyMySQL 模块是 Python 的一个第三方库,使用时需要先安装,在命令行中输入 sudo pip install PyMySQL 便可安装,操作截图如下所示:

连接数据库
通过 VS Code 工具在 /home/shiyanlou/test/ 下新建文件 database_operation.py ,编写如下内容
import pymysql
# 连接数据库
db = pymysql.connect(
host="localhost",
user="root",
password="",
database="test_case",
)
# 创建游标对象
cursor = db.cursor()
# 执行 SQL 查询
cursor.execute("SELECT VERSION()")
# 获取一条数据
data = cursor.fetchone()
# 打印获取的数据
print ("Database version : %s " % data)
# 关闭游标
cursor.close()
# 断开连接
db.close()
连接数据库时用到了一些参数,做以下说明:
- host="localhost":数据库地址,IP。
- user="root":用户名。
- password="":密码。
- database="test_case":数据库名。
然后点击 VS Code 工具右上角的执行按钮运行脚本,截图如下:

从截图中可以看到,输出了 “Database version : 10.5.8-MariaDB-1:10.5.8+maria~focal” 内容。表示数据库连接成功,并且执行了 SQL 查询。
创建数据表
连接数据库后,我们便可以对连接的数据库做一些操作。下面我们来创建一个数据表 LOGIN。
创建数据表的方法很简单,使用 execute() 方法执行创建表的 SQL 语句即可。
下面我们编辑 /home/shiyanlou/test/database_operation.py 文件,注释掉所有的代码,重新编写内容如下:e()
import pymysql # 连接数据库 db = pymysql.connect( host="localhost", user="root", password="", database="test_case", ) # 创建游标对象 cursor = db.cursor() sql = """ CREATE TABLE LOGINCASE( `id` INT UNSIGNED AUTO_INCREMENT, `title` CHAR(200) NOT NULL, `email` CHAR(100), `password` CHAR(100), `expected_location` CHAR(100), `expected_results` CHAR(200), PRIMARY KEY ( `id` )) """ cursor.execute(sql) # 关闭游标 cursor.close() # 断开连接 db.close()
注意: 数据表名,字段名尽量和示例一致,因为在接下来的实验中我们会使用到。
在此我们创建了一张表 LOGINCASE ,有六个字段,分别是 id、title、email、password、expected_location、expected_results。并且将 id 设置成了主键。
然后点击 VS Code 工具右上角的执行按钮运行脚本。
接下来在命令行中依次执行下面语句,查看创建的数据表:
mysql -u root USE test_case; DESC LOGINCASE;
操作截图如下:

从结果中可以看到,成功创建了数据表。
数据库插入数据
可以通过执行 SQL 语句对数据表添加数据。
下面我们编辑 /home/shiyanlou/test/database_operation.py 文件,注释掉所有的代码,重新编写内容如下:
import pymysql
# 连接数据库
db = pymysql.connect(
host="localhost",
user="root",
password="",
database="test_case",
)
# 创建游标对象
cursor = db.cursor()
sql = """
INSERT INTO LOGINCASE(title,
email, password, expected_location, expected_results)
VALUES ("登录成功", 'admin@tynam.com', 'tynam123', 'login success', "登录成功!")
"""
try:
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# 如果发生错误则回滚
db.rollback()
# 关闭游标
cursor.close()
# 断开连接
db.close()
我们向数据表 LOGINCASE 中插入了一条数据【title="登录成功",email='admin@tynam.com',password='tynam123',expected_location='login success',expected_results="登录成功!"】。
然后点击 VS Code 工具右上角的执行按钮运行脚本。
接着我们将上面的插入数据进行修改为 【title="邮箱地址不输入",email='',password='tynam124',expected_location='email error',expected_results="邮箱地址不可为空"】,再次点击 VS Code 工具右上角的执行按钮运行脚本。
我们总共向数据库中插入了两条数据。
数据库查询数据
PyMySQL 中可以使用 fetch 获取数据,默认是以元组的形式返回。常用的方法如下:
- 获取第一行数据:cursor.fetchone()
- 获取前 n 行数据:cursor.fetchmany(n)
- 获取所有数据:cursor.fetchall()
下面我们编辑 /home/shiyanlou/test/database_operation.py 文件,注释掉所有的代码,重新编写内容如下:
import pymysql # 连接数据库 db = pymysql.connect( host="localhost", user="root", password="", database="test_case", ) # 创建游标对象 cursor = db.cursor() sql = """ select * from LOGINCASE """ cursor.execute(sql) # 获取第一行数据 row_first = cursor.fetchone() print(row_first) cursor.execute(sql) # 获取前两行数据 row_n = cursor.fetchmany(2) print(row_n) cursor.execute(sql) # 获取所有数据 row_all = cursor.fetchall() print(row_all) # 关闭游标 cursor.close() # 断开连接 db.close()
我们分别使用 cursor.fetchone()、 cursor.fetchmany(n) 和 cursor.fetchall() 获取表 LOGINCASE 中的数据。
然后点击 VS Code 工具右上角的执行按钮运行脚本。截图如下:

从结果中可以看到,以元组的形式的返回了数据,得到的数据与预期结果一致。
数据库更新数据
可以通过执行 SQL 语句对数据表更新数据。
下面我们编辑 /home/shiyanlou/test/database_operation.py 文件,注释掉所有的代码,重新编写内容如下:
import pymysql # 连接数据库 db = pymysql.connect( host="localhost", user="root", password="", database="test_case", ) # 创建游标对象 cursor = db.cursor() sql = """ select * from LOGINCASE WHERE id = 2 """ # 更新前 id=2 的内容 cursor.execute(sql) print(cursor.fetchone()) sql_upadte = """ UPDATE LOGINCASE SET password = 'tynam111' WHERE id = 2 """ try: cursor.execute(sql_upadte) db.commit() except: db.rollback() # 更新后 id =2 的内容 cursor.execute(sql) print(cursor.fetchone()) # 关闭游标 cursor.close() # 断开连接 db.close()
我们对数据表 LOGINCASE 进行数据更新,如果 id=2 则将其 password 变更为 tynam111。并且将更新前后的 id=2 的数据进行输出。
然后点击 VS Code 工具右上角的执行按钮运行脚本。截图如下:

从结果中可以看到,数据 id=2 的 password 成功地由 tynam124 变更为 tynam111。
数据库删除数据
可以通过执行 SQL 语句对数据表删除数据。
下面我们编辑 /home/shiyanlou/test/database_operation.py 文件,注释掉所有的代码,重新编写内容如下:
import pymysql # 连接数据库 db = pymysql.connect( host="localhost", user="root", password="", database="test_case", ) # 创建游标对象 cursor = db.cursor() sql = """ select * from LOGINCASE """ # 删除操作前所有的数据 cursor.execute(sql) print(cursor.fetchall()) sql_delete = """ DELETE FROM LOGINCASE WHERE id > 1 """ try: cursor.execute(sql_delete) db.commit() except: db.rollback() # 删除操作后所有的数据 cursor.execute(sql) print(cursor.fetchall()) # 关闭游标 cursor.close() # 断开连接 db.close()
我们对数据表 LOGINCASE 进行数据删除,如果 id>1 则将其删除。并且将删除前后的所有数据进行输出。
然后点击 VS Code 工具右上角的执行按钮运行脚本。截图如下:

从结果中可以看到,删除前存在 id>1 的数据,删除操作后没有 id>1 的数据,说明成功进行了删除操作。
本次实验给大家介绍了数据库的操作模块 PyMySQL。通过本次实验的学习,大家可以掌握简单的增删改查操作。在自动化测试中,特别是数据驱动模型,就需要提供大量的测试数据,并且以一定的格式存储,相信这些对大家来说将不再是问题。
数据驱动模型实战之结构设计
在本系列实验会结合 pytest 框架实战练习数据驱动模型和关键字驱动模型。
本次实验进行数据驱动模型实战,会以一个登录页面为例,将数据存储在数据库中进行实战。
数据驱动模型简介
数据驱动模型是针对同一个功能使用一套测试脚本进行不同数据的测试,从而检测测试结果的变化。数据驱动的形式有很多种,比如通过定义数据变量、字典的方式进行参数化,或者通过读取 Excel、CSV 等文件的方式进行参数化。
数据驱动模型简介
数据驱动模型是从某个数据文件(例如 txt 文件、Excel 文件、CSV 文件、数据库等)中读取输入或输出的测试数据,然后以变量的形式传入事先录制好的或手工编写好的测试脚本中。在这个过程中,作为传递(输入/输出)的变量被用来验证应用程序的测试数据,而测试数据只包含在数据文件中而不是脚本里。测试脚本只是作为一个“驱动”,更恰当的说是一个传送数据的机制。同一个测试脚本可使用不同的测试数据来执行,测试数据和测试行为完全分离,这样的测试脚本设计模式叫做数据驱动模型。
数据驱动的一般流程如下:
- 测试结构搭建:设计测试结构,做到目录清晰,项目容易解读。
- 设计测试用例:数据文件以怎样的数据格式进行设计,明确测试用例。
- 数据文件的操作:对数据文件中的数据进行操作。
- 编写测试脚本:包括对获取的文件数据处理、断言的封装及测试用例的步骤。
- 执行且生成测试报告:运行测试用例,将测试结果输出。
ddt 介绍
在《Python Web 自动化测试入门与实战》书籍第八章中,介绍数据驱动模型时使用的是 ddt + unittest 框架。因为在 unittest 单元测试框架中自身是没有参数化功能,所以就需要 ddt 框架。在本系列实验中,给大家介绍 pytest 框架,pytest 自身就有参数化功能,所以我们就不需要再多一个框架的引入。但是 ddt 是一个不错的参数化框架,在此给大家做以简单的提及。
ddt 是 data-driven tests 的缩写,字面意思可理解为数据驱动测试。使用时用于给一个测试用例传入不同的参数,每组参数都会运行一次,就像是运行了多个测试用例一样。
关于 ddt 的使用可参考 ddt 的 Demo 示例:Example usage — DDT 1.5.0 documentation 。
使用比较简单,就不再做练习了,因为与本系列实验关系不大。
结构搭建
根据数据驱动的特性,我们来搭建一个简单的自动化测试结构。
首先我们在 /home/shiyanlou/Code/ 下创建一个文件夹,并且命名为 DataDrivenModel ,用以存放我们本次数据驱动实战的相关文件。然后使用 VS Code 打开 DataDrivenModel 文件夹。
接下来将我们项目进行分类管理,创建相关的文件夹。在 /home/shiyanlou/Code/DataDrivenModel/ 下创建文件夹 page、common、case、report 。然后创建文件 run.py 和 readme.md 。最后在所有的文件夹下添加一个 __init__.py 文件,包括 DataDrivenModel 文件夹。这样就可以将所在的文件夹变成一个可以被导入的 Python 包。创建完成后打开 VS Code 工具的终端,使用 tree 命令查看 /home/shiyanlou/Code/DataDrivenModel 下目录结构,操作截图如下:

下面对我们创建的文件做以说明:
- case:存放测试用例脚本层。
- common:公共层,存放数据文件的读写等公共文件。
- page:页面层,包含页面元素定位,页面操作步骤等。
- report:存放测试报告层。
- run.py:运行脚本并生成测试报告。
- readme.md:对项目的说明。
readme.md 是对我们项目的说明。例如我们可以进行说明每个文件夹的作用。接下来我们编辑 readme.md 文件,内容如下:
- case:测试用例层,存放测试用例脚本目录。 - common:公共目录,存放数据文件的读写等公共操作。 - page:页面目录,对页面元素定位,编写测试步骤等。 - report:存放测试报告目录。 - run.py:运行脚本并生成测试报告。
创建项目
下面我们来写一个简单的登录页面,作为数据驱动模型实战的案例。
使用 VS Code 在 /home/shiyanlou/Code/DataDrivenModel/ 下新建文件夹 LoginProject 。然后在 LoginProject 下新建两个文件 index.html 和 index.css 。 index.html 文件用于写登录页面,index.css 文件用于对登录页面美化。
编辑 index.html 文件,内容如下:
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>数据驱动模型实战</title>
<link href="./index.css" rel="stylesheet" type="text/css" />
</head>
<body>
<h1>数据驱动模型实战</h1>
<div class="login box">
<!-- form starts-->
<div id="login-form">
<div class="txt">
<input placeholder="请输入您的邮箱" id="ty-email" />
<div class="msg" id="ty-email-error"></div>
</div>
<div class="txt">
<input type="password" placeholder="请输入密码" id="ty-pwd" />
<div class="msg" id="ty-pwd-error"></div>
</div>
<div class="login-btn">
<input type="button" οnclick="login()" value="登 录" />
</div>
<div class="account">
<p>账号: admin@tynam.com; 密码: tynam123</p>
</div>
</div>
</div>
<!-- form ends -->
<!--copyright-->
<div class="copyright">
<p>Copyright © 2021 Tynam</p>
</div>
<!--copyright-->
<script type="text/javascript">
var emailMsg = document.getElementById("ty-email-error");
var pwdMsg = document.getElementById("ty-pwd-error");
var email = document.getElementById("ty-email");
var pwd = document.getElementById("ty-pwd");
var regex_mail = /^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/;
function login() {
emailMsg.innerHTML = "";
pwdMsg.innerHTML = "";
if (email.value == "") {
emailMsg.innerHTML = "邮箱地址不可为空";
return false;
} else if (email.value.indexOf(" ") != -1) {
emailMsg.innerHTML = "邮箱地址中不能有空格";
return false;
} else if (email.value.length < 6 || email.value.length > 30) {
emailMsg.innerHTML = "邮箱地址长度在 6~30 位";
return false;
} else if (!regex_mail.test(email.value)) {
emailMsg.innerHTML = "邮箱地址格式不正确";
return false;
}
if (pwd.value == "") {
pwdMsg.innerHTML = "密码不可为空";
return false;
} else if (pwd.value.length < 6 || pwd.value.length > 20) {
pwdMsg.innerHTML = "密码长度在 6~20 位";
return false;
}
if (email.value == "admin@tynam.com" && pwd.value == "tynam123") {
email.value = "";
pwd.value = "";
alert("登录成功!");
return true;
} else {
alert("邮箱或密码错误!");
return false;
}
}
</script>
</body>
</html>
上面我们写了一个简单的登录页面。大家可以直接将内容复制进去。注意;如果直接复制进去,由于编码格式不同导致汉子显示有问题。因此我们可以把内容保存成文件,通过实验环境右侧菜单上传文件,然后再进行下一步操作。
下面我们用火狐浏览器会打开 /home/shiyanlou/Code/DataDrivenModel/LoginProject/index.html ,页面截图如下:

可以看到,内容已经有了。此处大家需要记住打开后的 URL 是 file:///home/shiyanlou/Code/DataDrivenModel/LoginProject/index.html 。
内容有了,但是还缺少一些样式。接下来我们编辑 /home/shiyanlou/Code/DataDrivenModel/LoginProject/ 下的 index.css 文件,编辑内容如下:
html,
body {
margin: 0;
padding: 0;
border: 0;
vertical-align: baseline;
background: rgb(86, 228, 221);
}
body {
font-family: "Catamaran", sans-serif;
font-size: 100%;
text-align: center;
}
.login {
display: flex;
justify-content: center;
align-items: center;
justify-content: center;
}
h1 {
font-size: 2.8em;
font-weight: 300;
text-transform: capitalize;
color: #333;
text-shadow: 1px 1px 1px #000;
letter-spacing: 2px;
margin: 1.2em 1vw;
text-align: center;
}
#login-form {
max-width: 500px;
margin: 0 5vw;
padding: 3.5vw;
border-width: 5px 0;
box-sizing: border-box;
display: flex;
flex-wrap: wrap;
background: #fff;
}
.txt {
flex-basis: 100%;
margin-bottom: 1.5em;
}
#ty-email,
#ty-pwd {
width: 100%;
color: rgb(0, 0, 0);
outline: none;
background: rgba(192, 192, 192, 0.726);
font-size: 17px;
letter-spacing: 0.5px;
padding: 12px;
box-sizing: border-box;
border: none;
-webkit-appearance: none;
font-family: "Catamaran", sans-serif;
}
.login ::placeholder {
color: rgb(95, 95, 95);
}
.msg {
color: red;
text-align: left;
margin: 5px 0;
font-size: 14px;
}
.login-btn input {
color: rgb(255, 255, 255);
background: rgba(46, 45, 45, 0.904);
width: 100%;
padding: 0.4em 0;
font-size: 1em;
font-weight: 400;
letter-spacing: 2px;
cursor: pointer;
border: none;
outline: none;
}
.login-btn input:hover {
color: rgb(255, 255, 255);
background: rgb(46, 46, 46);
}
.login-btn {
margin-top: 1em;
width: 100%;
}
.account {
font-size: 0.8em;
color: rgb(95, 95, 95);
}
.copyright {
margin: 4em 0 2em;
}
.copyright p {
color: #333;
font-size: 1em;
letter-spacing: 1.5px;
line-height: 1.8;
margin: 0 3vw;
}
大家将内容直接复制进去,具体含义不做解释,因为这不是我们本系列实验的重点。如果有兴趣的话可以了解一些前端知识,了解后上面的代码含义则不难理解。
填充内容后保存文件。然后刷新浏览器,页面截图如下:

可以看到,一个简单登录页面以及经过了美化。
项目解析
从上面的登录页面出发,我们来分析怎么进行自动化测试,使用脚本进行测试的正常操作流程为:
- 打开浏览器。
- 输入 URL 后访问登录页面。
- 输入邮箱地址。
- 输入密码。
- 单击登录按钮。
- 对结果进行断言。
- 退出系统,关闭浏览器。
项目在数据驱动模型中进行的流程为:
- 根据功能测试用例设计方法,设计测试用例,编写用例编号、用例标题、预期结果等。本次实验我们将测试用例存储在数据库。
- 编写脚本文件,读取测试用例数据。即从数据库中读取测试用例。
- 对页面进行元素定位,根据手动测试的步骤使用代码写成测试用例函数。
- 利用 pytest 框架,将读取到的测试用例数据对测试用例函数进行参数化。
- 编写测试用例执行脚本,运行测试用例,对成功或失败的用例进行标记。
下面根据上面分析,我们对流程步骤展开说明。
设计测试用例
测试用例设计思想
根据页面的输入及操作可知,数据需要邮箱地址、密码和登录操作;根据自动化测试的操作可知,除了邮箱地址、密码、登录操作还需要 URL、操作步骤、预期结果和实际结果;除以上数据外还可增加用例的编号、用例标题,方便用例设计时知道用例的作用。
在本系列第六次实验数据库的操作中,我们知道数据表中可以设置主键,因此可以将主键作为用例编号使用。
URL 可直接写入代码中,操作步骤是在执行过程中需要代码实现的,实际结果是在一个用例运行后使用代码获取的。因此测试用例数据格式可设计为:用例标题、邮箱地址、密码、预期结果。
大家可以对项目进行手工测试。由手工测试操作可知,预期结果会在三个地方出现。邮箱地址输入错误时出现在邮箱地址输入框下方;密码输入错误时出现在密码输入框下方;登录时出现在 alert 弹窗中。总之,预期结果出现的位置不唯一,所以需要确定预期结果的位置。因此测试用例数据格式中还需要添加预期结果定位。
经过以上分析,最终确定测试用例的格式为:用例标题、邮箱地址、密码、预期结果定位、预期结果。
测试用例实现
根据上面的分析和测试用例设计方法,我们来设计手工测试用例数据,结果如下:
| 用例标题 | 邮箱地址 | 密码 | 预期结果定位 | 预期结果 |
|---|---|---|---|---|
| 登录成功 | admin@tynam.com | tynam123 | login success | 登录成功! |
| 邮箱地址不输入 | tynam124 | email error | 邮箱地址不可为空 | |
| 邮箱地址输入空格 | tynam125 | email error | 邮箱地址中不能有空格 | |
| 邮箱地址长度小于 6 位 | a@t.c | tynam126 | email error | 邮箱地址长度在 6 ~ 30 位 |
| 邮箱地址长度大于 30 位 | adminadmadminadminci min@adminadmin.comcom | tynam127 | email error | 邮箱地址长度在 6 ~ 30 位 |
| 邮箱格式错误 1 | adminadm123 | tynam128 | email error | 邮箱地址格式不正确 |
| 邮箱格式错误 2 | @#$%^&@f.234$% | tynam129 | email error | 邮箱地址格式不正确 |
| 密码不输入 | admin@tynam.com | password error | 密码不可为空 | |
| 密码长度小于 6 位 | admin@tynam.com | tynam | password error | 密码长度在 6 ~ 20 位 |
| 密码长度大于 20 位 | admin@tynam.com | tynam133tynam133 tynam133tynam133 | password error | 密码长度在 6 ~ 20 位 |
| 邮箱地址不存 | admin1@tynam.com | tynam123 | login fail | 邮箱或密码错误! |
测试用例插入数据库
根据测试用例设计思想中的分析,我们需要在数据库中创建一张含有用例标题、邮箱地址、密码、预期结果定位、预期结果,以及一个主键作为测试用例编号。
在第六次实验数据库的操作中,我们已经创建了一个数据库 test_case ,并且创建了一张表 LOGINCASE ,有 id、title、email、password、expected_location、expected_results 六个字段。并且将 id 设置成了主键。所以我们拿来直接用。
接下来在命令行中依次输入如下命令,进入数据库 test_case ,清除表 LOGINCASE 中的数据:
mysql -u root USE test_case; DELETE FROM LOGINCASE;
操作截图如下:

然后输入下面 SQL 语句,插入我们的设计好的测试用例:
INSERT INTO LOGINCASE(title, email, password, expected_location, expected_results) values
("登录成功", "admin@tynam.com", "tynam123", "login success", "登录成功!"),
("邮箱地址不输入", "", "tynam124", "email error", "邮箱地址不可为空"),
("邮箱地址输入空格", "t y", "tynam125", "email error", "邮箱地址中不能有空格"),
("邮箱地址长度小于6位", "a@t.c", "tynam126", "email error", "邮箱地址长度在 6~30 位"),
("邮箱地址长度大于30位", "adminadmadminadmincimin@adminadmin.comcom", "tynam127", "email error", "邮箱地址长度在 6~30 位"),
("邮箱格式错误1", "adminadm123", "tynam128", "email error", "邮箱地址格式不正确"),
("邮箱格式错误2", "@#$%^&@f.234$%", "tynam129", "email error", "邮箱地址格式不正确"),
("密码不输入", "admin@tynam.com", "", "password error", "密码不可为空"),
("密码长度小于6位", "admin@tynam.com", "tynam", "password error", "密码长度在 6~20 位"),
("密码长度大于20位", "admin@tynam.com", "tynam133tynam133tynam133tynam133", "password error", "密码长度在 6~20 位"),
("邮箱地址不存", "admin1@tynam.com", "tynam123", "login fail", "邮箱或密码错误!");
提示:在命令模式下进行数据库的操作,如果不能直接使用快捷键进行粘贴操作,则可通过右键菜单进行粘贴操作。
操作截图如下:

接下来我们使用 SELECT * FROM LOGINCASE; 语句查看插入的数据。操作截图如下:

可以看到,我们一共插入了 11 条数据。
数据驱动模型实战之测试代码
本系列实验会结合 pytest 框架实战练习数据驱动模型和关键字驱动模型。
本次实验进行数据驱动模型实战,会以一个登录页面为例,将数据存储在数据库中进行实战操作。
获取用例数据
在上节实验中我们将设计好的测试用例添加到了数据库,那么接下来我们就需要用代码从数据库中获取测试用例数据。对数据文件的读取我们可以采用一种灵活的方式,将读取方法进行封装,在使用的时候直接调用封装好的方法即可。
通过 VS Code 工具在 /home/shiyanlou/Code/DataDrivenModel/common/ 下新建文件 sql_execute.py ,编写如下内容:
import pymysql
class SqlExecute:
def __init__(self):
"""连接数据库"""
self.db = pymysql.connect(
host="localhost",
user="root",
password="",
database="test_case",
)
def close(self):
"""断开连接"""
self.db.close()
def get_data(self, data_table):
"""返回表 data_table 中的数据"""
cursor = self.db.cursor()
sql = "select * from %s" % data_table
cursor.execute(sql)
data_all = cursor.fetchall()
cursor.close()
return data_all
def get_case(self, data_table):
"""返回表 data_table 中的自动化测试用例数据"""
data_all = self.get_data(data_table)
case_all = []
for data in data_all:
case_all.append(data[2:])
return case_all
if __name__ == '__main__':
sql = SqlExecute()
login_case = sql.get_case('LOGINCASE')
sql.close()
print(login_case)
封装思路:我们先写了一个执行数据库操作的类 SqlExecute() ,在实例化时就执行 __init__() 构造函数,使其连接到数据库 test_case() 。有连接就有断开,所以我们紧接着就写了一个断开数据库连接的方法 close() 。接着就是我们对数据库操作的函数了,由于本次我们只使用到获取登录测试用例,所以只写了两个个方法 get_data(data_table) 和 get_case(data_table) ,当然也可写其他的操作,比如只获取第一条测试用例数据,获取前 n 条测试用例数据,测试用例更新等方法。
方法 get_data(data_table) 中参数 data_table 为数据表名,传入那张表就返回对应表中数据。在测试中,我们有很多个功能,测试用例表也会有很多张,所以参数化更会方便我们的使用。
而表中的 id 和用例标题两个字段是为了方便我们写测试用例时查看,辨别,在自动化测试中关注的是测试数据,所以需要剔除。因此写了方法 get_case(data_table) ,剔除 id 和用例标题两个字段。
在 if __name__ == '__main__': 下,我们对类 SqlExecute() 进行使用,查看结果。
点击 VS Code 工具右上角的执行按钮运行脚本。截图如下:

从结果中可以看到,获取的字段依次是:邮箱地址、密码、预期结果定位、预期结果。
编写测试步骤
对于登录页面的测试步骤设计,需要用到 Selenium 库,包括元素定位、元素操作等内容。在《Python Web 自动化测试入门实战》初级实验中已经做了详细解释,在此就不做解释了,直接使用。
在第七次实验中,对项目进行了解析,分析了自动化测试时执行的步骤,现在我们需要将步骤使用代码实现。
通过 VS Code 工具在 /home/shiyanlou/Code/DataDrivenModel/page/ 下新建文件 login.py ,编写如下内容:
import time
from selenium import webdriver
class Login:
def __init__(self, driver):
time.sleep(3)
self.driver = driver
def login(self, email, password):
"""登录操作"""
if email:
email_element = self.driver.find_element_by_id('ty-email')
email_element.clear()
email_element.send_keys(email)
time.sleep(1)
if password:
password_element = self.driver.find_element_by_id('ty-pwd')
password_element.clear()
password_element.send_keys(password)
time.sleep(1)
login_btn = self.driver.find_element_by_css_selector("input[value='登 录']")
login_btn.click()
if __name__ == '__main__':
driver = webdriver.Firefox()
driver.get("file:///home/shiyanlou/Code/DataDrivenModel/LoginProject/index.html")
Login(driver).login('admin@tynam.com', 'tynam123')
time.sleep(3)
driver.quit()
我们新建了一个 Login() 类,然后添加了一个 login() 方法,就是我们登录的操作步骤。操作步骤中我们依次实现了定位邮箱地址并且输入对应的值、定位密码输入框并且输入对应的值,然后点击登录按钮进行登录。如果邮箱或密码输入的值是 None ,也就是不输入,则对应的不会进行定位,也不会对其输入值。
在 if __name__ == '__main__': 下,我们对类 Login() 进行使用,对 login() 方法进行测试。
注意: 我们通过脚本启动火狐浏览器时需要火狐浏览器驱动,在《Python Web 自动化测试入门实战》初级实验中已经做了详细解释,在此就不做解释了,只说一下操作步骤。在命令行中依次执行如下命令,下载火狐浏览器驱动,然后解压压缩包,解压后将获得火狐浏览器驱动,将其移动到 Python 程序所在目录下,最后删除下载压缩包。
https://labfile.oss.aliyuncs.com/courses/3776/geckodriver.zip unzip geckodriver.zip rm -rf __MACOSX geckodriver.zip sudo mv geckodriver /usr/bin/
操作截图如下:

接下来点击 VS Code 工具右上角的执行按钮运行脚本。截图如下:


运行后会依次执行了打开火狐浏览器、访问登录页面、输入邮箱地址和密码、点击登录、提示登录成功,最后关闭了浏览器。
断言处理
因为预期结果所需要的提示信息会在不同的地方出现,所以需要分析预期结果出现的位置。
- 邮箱地址输出的错误提示信息如下截图所示。

- 密码错误提示信息如下截图所示。

- 登录后提示信息如下截图所示。

明确断言出现的位置后,需要根据传入的预期结果定位进行对应处理,因为登录操作方法和登录预期结果判断都是对登录功能的测试,所以将两者都放在同一个类 Login() 下。
在 /home/shiyanlou/Code/DataDrivenModel/page/login.py 下 Login() 类中添加 login_assert() 方法 ,编写如下内容:
def login_assert(self, assert_location, assert_message):
"""登录断言"""
time.sleep(1)
message = ''
if assert_location == 'email error':
message = self.driver.find_element_by_id('ty-email-error').text
elif assert_location == 'password error':
message = self.driver.find_element_by_id('ty-pwd-error').text
elif assert_location in ['login success', 'login fail']:
message = self.driver.switch_to.alert.text
else:
pass
assert message == assert_message
login_assert() 方法作为登录测试断言方法,使用时只需要传入两个参数 assert_location 和 assert_message,通过 assert_location 传入预期结果出现的位置(邮箱地址错误 email error、密码错误 password error、登录失败 login fail 和登录成功 login success)获取实际结果。然后通过参数 assert_message 传入预期结果,进而将预期结果与实际结果进行比较,若相等则测试通过,否则测试失败。
生成测试脚本
我们已经有了测试数据,也有了测试步骤,现在将使用测试数据对测试步骤进行参数化,生成可执行的测试用例脚本。
配置文件
在测试用例执行时我们需要先设置一些配置数据。
通过 VS Code 工具在 /home/shiyanlou/Code/DataDrivenModel/case/ 下新建文件 conftest.py ,编写如下内容:
import pytest from selenium import webdriver @pytest.fixture def open_login_page(): url = "file:///home/shiyanlou/Code/DataDrivenModel/LoginProject/index.html" driver = webdriver.Firefox() driver.implicitly_wait(10) driver.maximize_window() driver.get(url) yield driver driver.quit()
在此我们将启动浏览器,并且访问登录页面设置为 fixture。测试用例运行完成后我们使用 driver.quit() 关闭浏览器。
测试脚本文件
通过 VS Code 工具在 /home/shiyanlou/Code/DataDrivenModel/case/ 下新建文件 test_login.py ,编写如下内容:
import os, sys
import pytest
from selenium import webdriver
current_path = os.path.abspath(os.path.dirname(__file__))
autotest_path = os.path.join(current_path, os.path.pardir)
sys.path.append(autotest_path)
from common.sql_execute import SqlExecute
from page.login import Login
class TestLogin:
case = SqlExecute().get_case('LOGINCASE')
@pytest.mark.parametrize('email, password, assert_location, assert_message', case)
def test_login(self, email, password, assert_location, assert_message, open_login_page):
driver = open_login_page
login = Login(driver)
login.login(email=email, password=password)
login.login_assert(assert_location=assert_location, assert_message=assert_message)
if __name__ == '__main__':
pytest.main(['-v'])
这儿的代码大家应该很好理解,获取所有的测试用例数据,然后将数据依次传递给测试用例方法 test_login() 。测试用例方法依次执行登录测试步骤、登录测试断言。
接下来点击 VS Code 工具右上角的执行按钮运行脚本。截图如下:

从结果可以看到,总共运行了 11 条测试用例,测试都通过。
测试执行
测试用例脚本文件编写完成后,我们现在来编写 /home/shiyanlou/Code/DataDrivenModel/ 下的 run.py 执行文件。
测试执行是将所有的测试用例组织在一起统一执行,最终生成可视化测试报告。
编写内容如下:
# -*- coding: utf-8 -*- """ Created on 2021-4-4 Project: DataDrivenModel @Author: Tynam """ import os import pytest current_path = os.path.abspath(os.path.dirname(__file__)) case_path = os.path.join(current_path, 'case') def run_case(): pytest.main(['-v', case_path]) def create_report(): run_case = """ cd %s & pytest %s --alluredir ./report/result/ """ % (current_path, case_path) generate_report = """ cd %s & allure generate ./report/result/ -o ./report/report/ --clean """ % (current_path) os.system(run_case) os.system(generate_report) if __name__ == '__main__': # run_case() create_report()
我们定义了两个方法,run_case() 和 create_report() 。run_case() 是只执行测试用例脚本,但不生成测试报告。create_report() 是执行测试用例脚本后生成 Allure 测试报告。
下面我们在 run.py 文件中执行 create_report() 函数。
点击 VS Code 右上角的执行按钮进行运行。
点击后可以看到火狐浏览器不断的打开,执行登录操作,关闭。运行完毕后 VS Code 终端输出结果如下截图:

我们使用 Live Server 打开 /home/shiyanlou/Code/DataDrivenModel/report/report/index.html 。截图如下:

至此,我们数据驱动模型实验已经完成。
本次实验是对数据驱动模型的实战练习。通过本次实验的学习,希望大家可以自己搭建一个简单的数据驱动结构,在以后工作、学习中,将测试用例数据存放在其他地方,例如 Excel、CSV 等,也可以迎刃解决。
日志操作 logging
实验介绍
实验内容
在自动化测试中,我们经常会通过查看日志找到测试用例运行失败的原因。需要查看日志,那么首先就需要会写日志,本次实验将会大家介绍 Python 的日志操作模块 logging。 logging 模块为应用与库实现了灵活的事件日志系统的函数与类。
知识点
- 基本使用
- 日志级别
- 格式化输出
- 日志名称
- 写入文件
代码获取
你可以通过下面的命令下载本节实验的代码到虚拟环境中,作为参照对比:
# 下载代码 wget https://labfile.oss-internal.aliyuncs.com/courses/3776/90.zip # 解压缩代码 unzip 90.zip
基本使用
日志是对软件执行时所发生事件的一种追踪方式。一个事件通过一些包含变量数据的描述信息来描述。日志可以让我们监测程序运行的状态,如果运行过程中出现问题,日志可以帮助我们定位问题出现的位置和时间、了解问题出现的原因,让我们知道程序究竟发生了什么事情。
Python 程序中有一个标准库 logging,可以对程序运行过程进行记录。使用标准库提供的 logging API 可以使所有的 Python 模块都可能参与日志输出,包括自己的日志消息和第三方模块的日志消息。
下面我们来看一个简单的示例。
使用 VS Code 打开 /home/shiyanlou/test/ ,在 test 下新建文件 test_logging.py ,并编写如下内容:
# 导入 logging
import logging
# 简单的配置
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 输出内容
logging.info('start print log')
logging.debug('this is log test')
logging.warning('test log')
首先我们通过 logging.basicConfig() 对日志做了一个简单的配置,输出级别设置为 logging.INFO ,输出格式设置为 '%(asctime)s - %(name)s - %(levelname)s - %(message)s' 。然后通过 logging.info()、logging.debug() 和 logging.warning() 输出日志信息。
点击 VS Code 右上角的运行按钮,运行结果如下截图:

从结果可以看到,总共输出了两条记录。但是我们在输出内容中一共写了三条,这是由于日志级别设置造成的。下一小节我们将对日志级别进行实验。
日志级别
日志级别总共有 5 个级别,如下表所示:
| 级别 | 中文描述 | 含义 | 数值 |
|---|---|---|---|
| DEBUG | 调试 | 调试时期 | 10 |
| INFO | 提示 | 正常运行时 | 20 |
| WARINING | 警告 | 现在可运行,但未来可能发生错误时 | 30 |
| ERROR | 错误 | 当程序发生错误,无法执行某些功能时 | 40 |
| CRITICAL | 严重的、致命的 | 当程序发生严重错误,无法继续运行时 | 50 |
当我们指定一个输出级别后,只有该级别和级别更高(数值更大)的日志会输出,每个级别都对应一个输出函数。比如我们上一小节中将级别设置为 INFO ,在结果输出时就没有输出代码 logging.debug('this is log test') ,正是因为 DEBUG 级别小于 INFO 级别。
默认情况下只能输出 warning 及以上的级别。
接下来我们修改文件 /home/shiyanlou/test/test_logging.py 的输出级别。将 logging.basicConfig() 方法中的 level 参数删除,使用默认 warning 级别,然后添加 ERROR 级别内容输出,修改后的内容如下:
# 导入 logging
import logging
# 简单的配置
logging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 输出内容
logging.info('start print log')
logging.debug('this is log test')
logging.warning('test log')
logging.error('this is a error content')
点击 VS Code 右上角的运行按钮,运行结果如下截图:

从结果可以看到,只输出了大于 warning 及以上级别的内容。
格式化输出
在本次实验前面两个小节实验中,我们已经使用过了格式化,那就是 format 参数。 format 记录的属性字典用作字符串格式化操作的参数。返回结果字符串。例如格式化字符串包含 '(asctime)' 则调用 formatTime() 来格式化事件时间。如果有异常信息,则使用 formatException() 将其格式化并附加到消息中。
在 format 参数里面有一些固定用法,如下所示:
- %(asctime)s:表示当前时间。
- %(levelname)s:表示日志级别。
- %(message)s:表示日志内容。
- %(name)s:表示日志名称(未指定则为 roots)。
- %(lineno)d:表示输出日志的代码所在行数。
- %(levelno)s:表示数字形式的日志级别。
- %(pathname)s:表示程序执行路径,相当于 sys.argv[0] 。
- %(filename)s:表示所在文件名称。
- %(funcName)s:表示所在函数名称。
- %(thread)d:表示当前线程 ID。
- %(threadName)s:表示当前线程名称。
- %(process)d:表示当前进程 ID。
- %(processName)s:表示当前进程名称。
- %(module)s:表示当前模块名称。
- %(created)f:表示 UNIX 标准时间浮点数表示。
除此之外还可以使用 datefmt 对时间进行格式化。datefmt 的详情使用可以参考官网表格。下面列出一些常用的格式:
- %y:两位数的年份表示(00-99)
- %Y:四位数的年份表示(000-9999)
- %m:月份(01-12)
- %d:月内中的一天(0-31)
- %H:24 小时制小时数(0-23)
- %I:12 小时制小时数(01-12)
- %M:分钟数(00=59)
- %S:秒(00-59)
下面我们来修改文件 /home/shiyanlou/test/test_logging.py 中 logging.basicConfig() 方法。输出格式 format 中添加所在文件名称 %(filename)s 。然后添加时间输出格式 datefmt='%m/%d/%Y %I:%M:%S %p' 。修改后的内容如下:
# 导入 logging
import logging
# 简单的配置
logging.basicConfig(format='%(asctime)s - %(name)s - %(filename)s - %(levelname)s - %(message)s',
datefmt='%m/%d/%Y %I:%M:%S %p')
# 输出内容
logging.info('start print log')
logging.debug('this is log test')
logging.warning('test log')
logging.error('this is a error content')
点击 VS Code 右上角的运行按钮,运行结果如下截图:

结果所示,符合预期。
日志名称
我们可以通过 getLogger() 方法指定 logger 的名称,并且在 format 中可以使用 %(name)s 格式化输出。
logging.getLogger(name=None) 返回具有指定 name 的日志记录器,当 name=None 时则返回层级结构中作为根日志记录器的日志记录器。如果指定了 name,它通常是以点号分隔的带层级结构的名称如 a, a.b 或 a.b.c.d 。
下面我们注释掉文件 /home/shiyanlou/test/test_logging.py 中所有的代码,使用 getLogger() 重新写日志内容,内容如下:
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 设置日志名称
logger = logging.getLogger(name="TestLogger")
logger.info('test logger')
点击 VS Code 右上角的运行按钮,运行结果如下截图:

从结果中可以看到 %(name)s 输出的内容是我们设置的日志名称 TestLogger 。
写入文件
在项目运行中,日志记录需要保存到文件中,一旦出现问题,我们可以通过保存的日志文件迅速查找到问题点。
将日志写入文件
如果需要将日志写入文件,我们只需要在设置 logging 时创建一个 FileHandler ,并对输出消息的格式进行设置时将其添加到 logger ,然后将日志写入到指定的文件中,最后使用 removeHandler 移除 Handler 并关闭文件写入。
下面我们在 /home/shiyanlou/test/ 下新建文件 create_logging_file.py ,编辑内容如下:
import logging
import datetime
class CreateLoggingFile:
def __init__(self):
file_name = datetime.datetime.now().strftime("%y-%m-%d-%H:%M") + '.log'
self.file_formate = logging.Formatter('%(asctime)s - %(filename)s - %(levelname)s - %(message)s')
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.INFO)
# 将日志写入磁盘
self.file_handler = logging.FileHandler(file_name, 'a', encoding='utf-8')
self.file_handler.setLevel(logging.INFO)
self.file_handler.setFormatter(self.file_formate)
self.logger.addHandler(self.file_handler)
def get_log(self):
"""获取 logger"""
return self.logger
def close_handler(self):
"""关闭 handler"""
self.logger.removeHandler(self.file_handler)
self.file_handler.close()
if __name__ == '__main__':
logging_file = CreateLoggingFile()
logger = logging_file.get_log()
logger.info('this is a info content')
logger.error('this is a error content')
logging_file.close_handler()
我们新建了一个类 CreateLoggingFile ,在实例化对象时我们就让日志写入文件中,并且设置写入文件的日志级别为 INFO,格式为 %(asctime)s - %(filename)s - %(levelname)s - %(message)s 。文件名会取当前时间。
点击 VS Code 右上角的运行按钮,脚本执行完成后会在当前目录下生成一个以当前时间命名的 .log 文件,内容截图如下:

将日志写入文件同时输出到屏幕
如果想要将日志输出在命令行中,我们只需要在设置 logging 时创建一个 StreamHandler ,并对输出消息的格式进行设置时将其添加到 logger 即可。
下面我们在 /home/shiyanlou/test/create_logging_file.py 文件中 CreateLoggingFile() 类下添加方法 consloe_print() ,编辑如下内容:
def console_print(self): """控制台输出""" console = logging.StreamHandler() console.setLevel(logging.INFO) console.setFormatter(self.file_formate) self.logger.addHandler(console)
使用时调用即可。在 if __name__ == '__main__': 下 logging_file = CreateLoggingFile() 代码下方添加 logging_file.console_print() 。编辑后代码如下:
if __name__ == '__main__':
logging_file = CreateLoggingFile()
logging_file.console_print()
logger = logging_file.get_log()
logger.info('this is a info content')
logger.error('this is a error content')
logging_file.close_handler()
点击 VS Code 右上角的运行按钮,脚本执行时会在下方终端进行输出,同时也会在当前目录下生成一个以当前时间命名的 .log 文件,内容截图如下:

实验总结
实验知识点回顾:
- 基本使用
- 日志级别
- 格式化输出
- 日志名称
- 写入文件
日志模块 logging 使用起来很方便。通过本次实验的练习相信大家对日志已经有所了解,在自动化测试项目中大家要灵活使用,这样有利于问题的调查。
Excel 操作 OpenPYXL
实验介绍
实验内容
Excel 是一款功能强大的电子表格工具。在自动化测试中,我们可以将需要的数据存储在 Excel 中,提高数据管理的灵活性。在接下来的关键字驱动模型实战中会结合 Excel 进行练习。本次实验会给大家介绍 Excel 操作模块 OpenPYXL。
OpenPYXL 模块提供了 xlsx 文件创建、工作表操作、行和列操作、单元格操作,还可以对单元格样式设置,功能非常强大。本次实验我们进行一些常用的操作。
知识点
- 文件操作
- 工作表操作
- 单元格操作
- 行和列操作
- 其他操作
代码获取
你可以通过下面的命令下载本节实验的代码到虚拟环境中,作为参照对比:
# 下载代码 wget https://labfile.oss-internal.aliyuncs.com/courses/3776/100.zip # 解压缩代码 unzip 100.zip
创建文件
简介
OpenPYXL 是一个用于读/写 Excel2010 XLSX/XLSM/XLTX/XLTM 文件的 Python 库。是一个第三方库,我们可以使用 pip 安装 OpenPYXL。打开命令行工具,输入 sudo pip install openpyxl ,然后回车即可完成安装。
在 OpenPYXL 中,有三个关键的类,需要大家关注。三个关键的类如下所示:
openpyxl.workbook.workbook.Workbook openpyxl.worksheet.worksheet.Worksheet openpyxl.cell.cell.Cell
Workbook 类是对文件的操作, 包含 xlsx 文件的创建和保存。一个 xlsx 文件中可以包含多个工作表 sheet。 Worksheet 类是对工作表的操作,包含表名设置、表的获取、表中数据信息获取等。 Cell 类是对单元格的操作,包含单元格值设定、样式设置等。接下来会对大家简单的介绍这三个类中的一些操作。
由于虚拟环境中没有安装 Excel 工具,所以本次实验中,结果都会在石墨文档中进行查看。当然,你也可以将文件下载到本地进行查看。
使用石墨文档时需要大家先登录。
进入石墨文档后大家可以通过右侧【导入】菜单将文件导入,而后查看内容。如果想要下载文件,可以在需要下载的文件后面点击【设置】图标,选择【导出】即可。如下截图:

文件操作
使用 VS Code 工具打开 /home/shiyanlou/test/ ,并在其下新建文件 excel_operation.py,编写如下内容:
from openpyxl import Workbook
# 实例化一个 xlsx 文件对象
wb = Workbook()
# 保存文件
wb.save("sample.xlsx")
通过 VS Code 工具右上角的运行按钮执行脚本,操作完成后会在当前目录下生成一个 sample.xlsx 文件。截图如下:

加载已有的文件
如果文件已经存在,我们只是打开获取或编写内容,则可以使用 load_workbook() 方法进行加载已有的文件。代码如下:
from openpyxl import load_workbook
# 加载已存在的文件
wb = load_workbook('文件名称.xlsx')
工作表操作
-
可以通过 Workbook().active 获取当前活动的工作表。
-
可以通过 Workbook()[工作表名] 获取当前活动的工作表。通过工作表名激活工作表。
-
可以通过 create_sheet(title=None, index=None) 创建一个新的工作表。
-
可以通过 Workbook().index[工作表] 获取工作表索引。
-
可以通过 Workbook().remove[工作表] 删除一个工作表。
-
可以通过 Workbook()..sheetnames 获取所有工作表名。
下面我们来做实验。
实验一
修改 /home/shiyanlou/test/excel_operation.py 文件,修改要求如下:
-
创建一个文件 sample.xlsx 。
-
创建两个工作表,名称分别是“test1”和“test2”。
-
通过 Workbook().active 激活工作表,并且在 D3 单元格写入内容“active”。
-
通过工作表名激活工作表“test2”,然后在 A1 单元格写入内容“test2”。
编辑 /home/shiyanlou/test/excel_operation.py 文件内容如下:
from openpyxl import Workbook
wb = Workbook()
# 创建工作表
wb.create_sheet("test1")
wb.create_sheet("test2")
# 通过 active 激活工作表
ws = wb.active
ws["D3"] = "active"
# 通过工作表名获取工作表
ws = wb["test2"]
ws["A1"] = "test2"
wb.save("sample.xlsx")
通过 VS Code 工具右上角的运行按钮执行脚本,在 /home/shiyanlou/test/ 下会重新生成一个 sample.xlsx 文件。然后在石墨文档中打开 sample.xlsx 文件。Sheet 和 test2 工作表截图如下所示。
Sheet 工作表截图:

test2 工作表截图:

从结果中可以看到,成功创建了工作表 test1 和 test2。并在对应的位置写入了内容。
实验二
-
加载实验一中创建的文件 /home/shiyanlou/test/sample.xlsx 。
-
打印所有的工作表名。
-
删除工作表“test1”。
-
获取工作表“test2”的索引,并且打印。
注释掉 /home/shiyanlou/test/excel_operation.py 文件中内容,重新编写如下内容:
wb = load_workbook("sample.xlsx")
# 获取所有工作表名
names = wb.sheetnames
print("工作表名列表是:" + str(names))
# 删除工作表 test1
wb.remove(wb["test1"])
# 获取工作表 test2 索引
index = wb.index(wb["test2"])
print("test2 工作表的索引是:" + str(index))
wb.save("sample.xlsx")
通过 VS Code 工具右上角的运行按钮执行脚本,操作截图如下所示:

从结果中可以看到一共有三个工作表,分别是 Sheet、test1 和 test2。删除 test1 工作表后,test2 工作表的 index 是 1。
代码执行完成后,在石墨文档打开中重新打开 /home/shiyanlou/test/sample.xlsx 文件。截图如下所示:

从截图中可以看到,test1 工作表成功删除。
单元格操作
-
可以通过 worksheet[单元格] = 值 对单元格进行值设置。
-
可以通过 worksheet[单元格].value 获取单元格的值。
-
可以通过 worksheet.cell(row, column, value) 对单元格进行值设置。
-
可以通过 worksheet.merge_cells(range_string=None, start_row=None, start_column=None, end_row=None, end_column=None) 合并单元格。
-
也可以对单元格使用公式进行某些计算。例如求和就可以写成 worksheet[单元格]="=SUM(开始单元格:结束单元格)" 。
下面我们来进行实验。
实验
修改 /home/shiyanlou/test/excel_operation.py 文件,修改要求如下:
-
加载 /home/shiyanlou/test/sample.xlsx 文件。
-
获取 Sheet 表 D3 单元格的值,并打印。
-
通过 worksheet[单元格] = 值 将 B3 单元格的值设置为 3。
-
通过 worksheet.cell(row, column, value) 将 B4 单元格的值设置为 4。
-
将单元格 B1 和 B2 进行合并,值设置为“求和”。
-
求 B3 和 B4 单元格的和,将其写入单元格 B5。
注释掉 /home/shiyanlou/test/excel_operation.py 文件中内容,编写如下内容:
wb = load_workbook("sample.xlsx")
ws = wb.active
# 获取单元格值
print(ws["D3"].value)
# 设置值
ws["B3"] = 3
ws.cell(4, 2, 4)
# 合并单元格
ws.merge_cells("B1:B2")
ws["B1"] = "求和"
# 求和计算
ws["B5"]="=SUM(B3:B4)"
wb.save("sample.xlsx")
通过 VS Code 工具右上角的运行按钮执行脚本,操作截图如下所示:
![]()
代码执行完成后,在石墨文档打开中重新打开 /home/shiyanlou/test/sample.xlsx 文件。截图如下所示:

结果与预期一致。
行和列操作
-
可以通过 worksheet.append(list) 进行行插入数据。是在数据的最后一行进行追加。
-
可以通过 worksheet.max_row 获取最大行数。
-
可以通过 worksheet.max_column 获取最大列数。
实验
-
加载 /home/shiyanlou/test/sample.xlsx 文件。
-
创建一个工作表 test3 。
-
通过 worksheet.append(list) 在 test3 工作表,从 A1 单元格开始插入如下数据:
data = [ ['id', 'name', 'score'], [2, "张三", 98], [3, "老刘", 95], [4, "李老头", 90], [5, "王五", 80], [6, "铁老大", 56], [7, "张老太", 79], ]
4. 获取 test3 工作表的最大行数,并打印。
5. 获取第 test3 工作表的最大列数,并打印。
注释掉 /home/shiyanlou/test/excel_operation.py 文件中内容,编写如下内容:
wb = load_workbook("sample.xlsx")
data = [
['id', 'name', 'score'],
[2, "张三", 98],
[3, "老刘", 95],
[4, "老李头", 90],
[5, "王五", 80],
[6, "铁老大", 56],
[7, "张老太", 79],
]
wb.create_sheet("test3")
ws = wb["test3"]
# 行写入数据
for row in data:
ws.append(row)
# 获取最大行
max_row = ws.max_row
# 获取最大列
max_column = ws.max_column
print("test3 最大行数是:" + str(max_row))
print("test3 最大列数是:" + str(max_column))
wb.save("sample.xlsx")
通过 VS Code 工具右上角的运行按钮执行脚本,操作截图如下所示:

代码执行完成后,在石墨文档打开中打开 /home/shiyanlou/test/sample.xlsx 文件。test3 工作表截图如下所示:

其他操作
-
可以通过 worksheet.sheet_properties.tabColor = 颜色 改变 sheet 标签颜色。
-
可以通过 worksheet[单元格].font = Font(name, size, italic, color, bold) 改变单元格字体样式。
-
可以通过 worksheet[单元格].alignment = Alignment(horizontal, vertical) 设置单元格文字对齐样式。
实验
-
加载 /home/shiyanlou/test/sample.xlsx 文件。
-
将工作表 test3 标签颜色设置红色。
-
将工作表 test3 的 B2 单元格字体设置为 Arial,大小设置为 15,斜体,颜色设置为绿色,并且加粗。
-
将工作表 test3 的 B2 单元格文字设置为上下居中、左右居中。
注释掉 /home/shiyanlou/test/excel_operation.py 文件中内容,编写如下内容:
from openpyxl.styles import Font, colors, Alignment
from openpyxl.styles.colors import Color
wb = load_workbook("sample.xlsx")
ws = wb["test3"]
# 设置 sheet 标签颜色
ws.sheet_properties.tabColor = Color("fe2c23")
# 设置字体样式
ws["B2"].font = Font(name="Arial", size=15, italic=True, color="1C7231", bold=True)
# 设置对齐样式
ws["B2"].alignment = Alignment(horizontal="center", vertical="center")
wb.save("sample.xlsx")
通过 VS Code 工具右上角的运行按钮执行脚本。然后在石墨文档打开中打开 /home/shiyanlou/test/sample.xlsx 文件。test3 工作表截图如下所示:

实验总结
实验知识点回顾:
- 文件操作
- 工作表操作
- 单元格操作
- 行和列操作
- 其他操作
本次实验我们对 Excel 的操作库 OpenPYXL 做了基本的操作练习。通过本次实验基本用法的学习,在以后的工作中,就可以充分利用 Excel 工具对数据进行处理,会很大地提高工作效率。
关键字驱动模型简介
实验介绍
实验内容
在《Python Web 自动化测试入门实战》初级实验中给大家介绍过五种测试模型,其中线性模型、模块化驱动模型和行为驱动模型以实例给大家做了介绍。在本系列第七次和第八次实验给大家介绍了数据驱动模型。接下来会使用 pytest 框架实战关键字驱动模型。
本此实验给大家简单的介绍关键字驱动模型以及搭建项目结构和设计测试用例。
知识点
- 关键字驱动简介
- 设计思想
- 结构搭建
- 用例设计
- 获取测试数据
代码获取
你可以通过下面的命令下载本节实验的代码到虚拟环境中,作为参照对比:
# 下载代码 wget https://labfile.oss-internal.aliyuncs.com/courses/3776/100.zip # 解压缩代码 unzip 100.zip
关键字驱动模型简介
概念
关键字驱动模型是通过关键字的改变引起测试结果改变的一种功能自动化测试模型,也称为表驱动测试或基于动作词的测试。关键字驱动模型将测试用例分为四个不同的部分:测试步骤、测试对象、测试对象操作和测试对象数据。
- 测试步骤:对测试步骤的一个动作描述,或者说是在测试对象上执行的动作描述。就像是测试用例标题,本身对测试不产生实质性的影响。
- 测试对象:页面中元素对象的名称,例如邮箱、密码和登录等。
- 测试对象操作:测试对象上执行的动作名称,例如单击、打开浏览器、输入等。
- 测试对象数据:数据是指对测试对象执行操作所需的值,例如“邮箱”字段的值为“tynam@test.com”。
Robot Framework 工具就是遵循关键字驱动模型开发的一个功能强大的测试工具,其封装了底层的代码,提供给用户独立的图像界面,以“填表格”形式编写测试用例,降低了脚本的编写难度。
优缺点
关键字驱动模型中当底层代码封装好后,手动测试人员或非技术测试人员都可以轻松地编写自动化测试脚本,降低了自动化测试用例的编写难度,提高了工作效率,也降低了维护门槛。但是在关键字驱动模型中如果需要对底层代码进行开发,则需要高技能水平的测试人员,且代码质量要有所保证。
主要优点有:
- 一般都提供图形化界面,门槛低、容易上手。
- 不需要掌握脚本语言,懂得基本填写规则,熟悉业务逻辑也可以写测试用例。
- 界面化、掌握规则就可以使用,效率高。
主要缺点有:
- 对于一些不常用的测试场景,就需要创建自定义测试功能,需要对底层逻辑熟悉,语言功底比较好,否则将难以完成。
- 适合简单的业务场景,对于复杂的测试场景不太适用。
设计思想
关键字驱动模型的设计上我们主要是设计测试用例和对象执行,然后在测试用例操作时将测试用例与对象执行联系在一起,使测试用例中的每一条数据都可以通过对象执行进行完成。
本次实验的设计思路如下图所示:

总共分五个部分,测试数据、对象执行、测试用例操作、公共模块和测试执行。
首先我们会设计测试数据,然后通过公共模块下 Excel 操作对测试数据进行处理,产生我们需要的数据。再使用 pytest 框架进行参数化,将测试数据添加到对象执行上,完成数据执行操作。
接着我们需要添加日志记录,记录整个测试过程。如果在测试过程中发生意外,我们可以通过日志进行定位出现错误的位置。
最后对测试进行执行,生成 Allure 测试报告。
本次关键字驱动模型实战会以一个登录页面为例,详细讲解设计思路图中五个部分以及五大部分下的各个文件内容处理。
与数据驱动设计对比
可能有人会与数据驱动模型设计思想做联系,都是写测试数据,操作步骤,然后将两个联系在一起进行执行,并没有什么区别。在此做稍微的解释。
流程都是这样的流程,没有错。两者最大区别在于对象不一样。
数据驱动中参数化的对象是测试功能用例,功能用例中包括许多对象的操作。例如登录功能,里面包括打开浏览器、访问登录页面、输入用户名、数据密码、点击登录等一些操作。
关键字驱动中参数化的对象是单一对象的一个操作。例如浏览器打开操作,就是单一的一个操作,对象是浏览器,执行的是启动操作。
结构搭建
了解了关键字驱动模型概念和设计思想,现在我们来搭建一个简单的项目结构。
结构设计
在 /home/shiyanlou/Code/ 下创建一个文件夹,并且命名为 KeywordDrivenModel 。用以存放我们本次关键字驱动实战项目的相关文件。然后使用 VS Code 打开 /home/shiyanlou/Code/KeywordDrivenModel 文件夹。
接下来将我们对项目进行分类管理,创建相关的文件夹。在 /home/shiyanlou/Code/KeywordDrivenModel/ 下创建文件夹 action、common、data、log、case、report 。然后创建文件 run.py 和 readme.md 。最后在除过 log 文件夹外的所有文件夹下添加一个 __init__.py 文件,包括 KeywordDrivenModel 文件夹。这样就可以将所在的文件夹变成一个可以被导入的 Python 包。创建完成后打开 VS Code 工具的终端,使用 tree 命令查看 /home/shiyanlou/Code/KeywordDrivenModel 下目录结构,操作截图如下:

下面对我们创建的文件做以下说明:
- action:对象执行目录,包括浏览器操作、元素操作等。
- case:测试用例操作目录。
- common:公共层,存放数据文件的读写、日志写入等公共文件。
- data:数据目录,存放本次使用 Excel 写入的测试数据。
- log:日志目录,测试执行后产生的日志文件保存在此目录。
- report:存放测试报告。
- run.py:运行脚本并生成测试报告。
- readme.md:对项目的详细描述,遵循的规则说明。
登录项目
在第七次实验数据驱动模型实战中我们使用了一个登录页面,页面存放在 /home/shiyanlou/Code/DataDrivenModel/ 下的 LoginProject 。本次实验我们同样使用该登录页面进行演示。
在命令行模式下使用 cp 命令将登录页面所在的文件夹 /home/shiyanlou/Code/DataDrivenModel/LoginProject 拷贝一份到 /home/shiyanlou/Code/KeywordDrivenModel/ 文件夹下。在命令行模式下执行如下命令:
cd /home/shiyanlou/Code/KeywordDrivenModel cp -r /home/shiyanlou/Code/DataDrivenModel/LoginProject .
然后使用 tree 命令查看 /home/shiyanlou/Code/KeywordDrivenModel/ 下文件,操作截图如下所示:

接下来我们对 /home/shiyanlou/Code/KeywordDrivenModel/LoginProject/index.html 文件中标签 title 和标签 body 下的 h1 标签内容进行修改,修改为“关键字驱动模型实战”。修改后的 index.html 文件内容如下:
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>关键字驱动模型实战</title>
<link href="./index.css" rel="stylesheet" type="text/css" />
</head>
<body>
<h1>关键字驱动模型实战</h1>
<div class="login box">
<!-- form starts-->
<div id="login-form">
<div class="txt">
<input placeholder="请输入您的邮箱" id="ty-email" />
<div class="msg" id="ty-email-error"></div>
</div>
<div class="txt">
<input type="password" placeholder="请输入密码" id="ty-pwd" />
<div class="msg" id="ty-pwd-error"></div>
</div>
<div class="login-btn">
<input type="button" οnclick="login()" value="登 录" />
</div>
<div class="account">
<p>账号: admin@tynam.com; 密码: tynam123</p>
</div>
</div>
</div>
<!-- form ends -->
<!--copyright-->
<div class="copyright">
<p>Copyright © 2021 Tynam</p>
</div>
<!--copyright-->
<script type="text/javascript">
var emailMsg = document.getElementById("ty-email-error");
var pwdMsg = document.getElementById("ty-pwd-error");
var email = document.getElementById("ty-email");
var pwd = document.getElementById("ty-pwd");
var regex_mail = /^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/;
function login() {
emailMsg.innerHTML = "";
pwdMsg.innerHTML = "";
if (email.value == "") {
emailMsg.innerHTML = "邮箱地址不可为空";
return false;
} else if (email.value.indexOf(" ") != -1) {
emailMsg.innerHTML = "邮箱地址中不能有空格";
return false;
} else if (email.value.length < 6 || email.value.length > 30) {
emailMsg.innerHTML = "邮箱地址长度在 6~30 位";
return false;
} else if (!regex_mail.test(email.value)) {
emailMsg.innerHTML = "邮箱地址格式不正确";
return false;
}
if (pwd.value == "") {
pwdMsg.innerHTML = "密码不可为空";
return false;
} else if (pwd.value.length < 6 || pwd.value.length > 20) {
pwdMsg.innerHTML = "密码长度在 6~20 位";
return false;
}
if (email.value == "admin@tynam.com" && pwd.value == "tynam123") {
email.value = "";
pwd.value = "";
alert("登录成功!");
return true;
} else {
alert("邮箱或密码错误!");
return false;
}
}
</script>
</body>
</html>
然后在火狐浏览器中打开 /home/shiyanlou/Code/KeywordDrivenModel/LoginProject/index.html 文件,截图如下所示:

用例设计
既然是对象操作,我们在设计测试用例时就要针对对象设计。在关键字驱动模型概念小节中介绍过测试用例的四部分,分别是测试步骤、测试对象、测试对象操作和测试对象数据。根据这四部分我们来设计测试用例。
我们将测试用例分为步骤、对象、操作、数据四个部分。然后根据我们对登录功能测试的步骤进行填写用例内容。
本次实验我们写两个简单的功能测试,密码没输入进行登录和成功登录。
根据手工功能测试的步骤,我们将上面两个功能测试进行合并,一起进行。所以步骤应该是:
- 打开浏览器。
- 浏览器最大化。
- 访问登录页面。
- 输入正确的用户名。
- 点击登录。
- 密码没有输入提示判断。
- 输入正确的密码。
- 点击登录。
- 登录成功判断。
- 关闭浏览器。
在使用 pytest 进行自动化测试时,我们可以将打开浏览器和关闭浏览器放在共享 fixture 功能 conftest.py 文件中。
在自动化测试中,我们还需要添加一些时间等待,减少由于加载缓慢造成的测试失败。
所以我们最终设计的测试数据如下:
| 步骤 | 对象 | 操作 | 参数 |
|---|---|---|---|
| browser | max | ||
| 访问登录页面 | browser | open | file:///home/shiyanlou/Code/ KeywordDrivenModel/LoginProject/index.html |
| 等待 3s | time | sleep | 3 |
| 输入用户名 | #ty-email | input | admin@tynam.com |
| 点击登录 | input[value='登 录'] | click | |
| time | sleep | 1 | |
| 密码不输入判断 | id:ty-pwd-error | assert | 密码不可为空 |
| 输入密码 | #ty-pwd | input | tynam123 |
| 点击登录 | input[value='登 录'] | click | |
| time | sleep | 1 | |
| 登录成功判断 | alert | assert | 登录成功! |
对于上面的对象、操作、参数三列中的关键字大家可能不太理解,不要着急,先按照这样的关键字来写。学完下一节《关键字驱动模型实战(中)》实验后,回过头来再进行理解,就会容易的多。
当对象是元素时我们直接写 Selenium 定位到的元素,默认采用的是 CSS 定位,如果需要其他方式定位,则可写成”定位方式 + 英文冒号 + 定位字符串“。例如上面密码不输入判断中的元素定位。
进入石墨文档,我们新建一个 Excel 文档,并且取名为“casedata”,将第一个工作表取名为“login”。将上面的测试数据填入,填入数据后截图如下:

然后将其导出。默认导出的位置是 /home/shiyanlou/下载/ 。我们需要将导出的 /home/shiyanlou/下载/casedata.xlsx 文件移动到 /home/shiyanlou/Code/KeywordDrivenModel/data/ 下。在命令行执行如下命令进行文件移动:
cd /home/shiyanlou/Code/KeywordDrivenModel/ mv /home/shiyanlou/下载/casedata.xlsx .
提示:命令行下中文不能输入,可以使用 tab 键进行选择。
获取测试数据
获取测试数据比较简单,在数据驱动模型中我们从数据库中读取数据,现在我们从 Excel 中读取数据,思路都是相同的。在此做简单的介绍。
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/common/ 下新建文件 excel_util.py ,编写如下内容:
# -*-coding:utf-8-*-
import os
from openpyxl import load_workbook
class ExcelUtil:
def __init__(self, excel_path=None, sheet_name=None):
"""获取 excel 工作表"""
if excel_path is None:
current_path = os.path.abspath(os.path.dirname(__file__))
self.excel_path = current_path + '/../data/casedata.xlsx'
else:
self.excel_path = excel_path
if sheet_name is None:
self.sheet_name = "Sheet"
else:
self.sheet_name = sheet_name
# 打开工作表
self.workbook = load_workbook(self.excel_path)
self.sheet = self.workbook[self.sheet_name]
def get_data(self):
"""
获取文件数据
每一行数据一个 list,所有的数据一个大 list
"""
rows = self.sheet.rows
row_num = self.sheet.max_row
col_num = self.sheet.max_column
if row_num <= 1:
print("总行数小于1,没有数据")
return
else:
case_all = []
for row in rows:
case = []
for i in range(col_num):
case.append(row[i].value)
case_all.append(case)
return case_all
def get_case(self):
"""
获取测试数据
得到有用的数据,并且使数据以对象、操作、参数的顺序返回
:return: [[element, action, par],[element, action, par]...]
"""
data = self.get_data()
# 得到所需要数据的索引,然后根据索引获取相应顺序的数据
obj_index = data[0].index("对象")
action_index = data[0].index("操作")
parameter_index = data[0].index("参数")
all_case = []
# 去除header行,和其他无用的数据
for i in range(1, len(data)):
case = []
case.append(data[i][obj_index])
case.append(data[i][action_index])
case.append(data[i][parameter_index])
all_case.append(case)
return all_case
if __name__ == '__main__':
sheet_name = 'login'
worksheet = ExcelUtil(sheet_name=sheet_name)
print(worksheet.get_data())
print("========================================")
print(worksheet.get_case())
封装思路:我们先写了一个执行 Excel 操作的类 ExcelUtil() ,在实例化时就执行 __init__() 构造函数, 获取所需读取的 Excel 文件和工作表。
接着定义了一个方法 get_data() 获取工作表中所有的数据。并且将数据按照一行一个 list,所有的数据一个大 list 的形式返回。
最后定义了一个方法 get_case() ,对 get_data() 方法返回的数据进行处理。去除 list 中第一条标题 list 数据和每一个小 list 中第一个操作步骤数据。并将所有的数据以一个大 list 包含多个测试用例小 list 的形式返回。每一个小 list 中以对象、操作、参数的顺序进行排列。
在 if __name__ == '__main__': 下,我们对类 ExcelUtil() 下两个方法 get_data() 和 get_case() 返回的数据进行打印,查看结果。
点击 VS Code 工具右上角的执行按钮运行脚本。截图如下:

实验总结
实验知识点回顾:
- 关键字驱动简介
- 设计思想
- 结构搭建
- 用例设计
- 获取测试数据
本次实验是对关键字驱动模型的简单介绍。通过本次实验的学习,了解关键字驱动模型是什么,主要设计思想是什么。当掌握其设计思想后,可以动手搭建一个合理的项目结构,并且对测试用例结构进行设计。
关键字驱动模型实战之对象封装
实验介绍
实验内容
在《Python Web 自动化测试入门实战》初级实验中给大家介绍过五种测试模型,其中线性模型、模块化驱动模型和行为驱动模型以实例给大家做了介绍。在本系列第七次和第八次实验给大家介绍了数据驱动模型。接下来会使用 pytest 框架实战关键字驱动模型。
本次实验我们来实现通过关键字来执行对应的操作。
知识点
- 浏览器操作设计
- 元素定位设计
- 元素动作设计
- 断言设计
- 时间操作设计
- 对象操作设计
代码获取
你可以通过下面的命令下载本节实验的代码到虚拟环境中,作为参照对比:
# 下载代码 wget https://labfile.oss-internal.aliyuncs.com/courses/3776/120.zip # 解压缩代码 unzip 120.zip
浏览器操作设计
浏览器操作设计是当对象关键字是浏览器时就进入浏览器对象类,然后根据操作关键字进行相应的操作。
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/action/ 下新建文件 browser.py ,编写如下内容:
from selenium import webdriver class Browser: def __init__(self, driver): self.driver = driver def browser_operate(self, action, parameter=None): """ 浏览器操作 :param action: :param parameter: :return: """ action = action.lower() if action == "open" and parameter: self.driver.get(parameter) elif action == "max": self.driver.maximize_window() elif action == "close": self.driver.close() elif action == "quit": self.driver.quit() else: pass return
在此我们根据传入的操作关键字,浏览器执行相应的操作。
我们定义了一个 Browser() 类,在实例化时传入 driver。然后定义了一个方法 browser_operate() ,根据传入的操作关键字进行不同的操作。
当 action == "open" 时就认为是访问页面,访问页面的地址是传入的参数 parameter ;
当 action == "max" 时就认为是浏览器最大化;
当 action == "close" 时就认为是关闭当前浏览器 tab ;
当 action == "quit" 时就认为是结束浏览器进程。
元素定位设计
元素定位设计是当传入的对象是一个定位字符串时,我们需要根据定位字符串在页面中找到对应的元素,然后将其返回。
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/action/ 下新建文件 element.py ,编写如下内容:
from selenium.webdriver.common.by import By
class Element:
def __init__(self, driver):
self.driver = driver
def __local_element(self, local):
"""
默认使用 CSS 定位,如果需要其他定位方式使用英文冒号(:)分割,例如:id:password
:param local:
:return:
"""
if local.lower() == "alert":
return local.lower()
elif ":" in local:
[by, location] = local.split(":")
return self.__element_find(by, location)
else:
return self.__element_find("css", local)
def __element_find(self, by, location):
"""
定位元素
:param by:
:param location:
:return:
"""
by = by.lower()
if by == "css":
return self.driver.find_element(By.CSS_SELECTOR, location)
elif by == "id":
return self.driver.find_element(By.ID, location)
elif by == "class":
return self.driver.find_element(By.CLASS_NAME, location)
elif by == "name":
return self.driver.find_element(By.NAME, location)
elif by == "tag":
return self.driver.find_element(By.TAG_NAME, location)
elif by == "link":
return self.driver.find_element(By.LINK_TEXT, location)
elif by == "xpath":
return self.driver.find_element(By.PARTIAL_LINK_TEXT, location)
else:
return
我们定义了一个 Element() 类,在实例化时传入 driver。然后定义了两个方法 __local_element() 和 __element_find() 。
__element_find() 方法是返回定位到的元素。使用时需要传入两个参数,元素定位方式 by 和定位字符串 location ,然后根据定位方式和定位字符串进行定位元素,并将定位到的元素进行返回。
__local_element() 方法是获取传过来的定位字符串,如果定位字符串传入的是“alert”关键字,则将其直接返回;如果定位字符串中含有英文冒号(:)则认为是”定位方式 + 英文冒号 + 定位字符串“的形式。然后将定位方式和定位字符串传入 __element_find() 方法,并且返回定位到的元素;如果定位字符串中没有英文冒号(:)则认为采用的是 CSS 定位,然后将 CSS 定位方式和定位字符串传入 __element_find() 方法,并且返回定位到的元素。
元素动作设计
元素定位设置完成后,我们接下来需要对元素的操作进行设计。
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/action/element.py 文件中 Element() 类下添加 element_operate() 方法,编写如下内容:
def element_operate(self, local, action, parameter=None): """ 元素操作 :param local: :param action: :param parameter: :return: """ element = self.__local_element(local) if action == "input" and parameter: element.send_keys(parameter) elif action == "click": element.click() elif action == "assert": AssertText(self.driver, element, parameter).equal() else: return
在使用 element_operate() 方法时,我们需要传入三个参数,元素定位字符串(即我们在测试数据中写的对象),操作和参数。
首先通过元素字符串得到需要操作的元素,然后根据操作关键字进行下一步操作。
当 action == "input" 时就认为是输入框,并且将参数作为值输入到输入框中;
当 action == "click" 时就认为是对元素进行点击;
当 action == "assert" 时就认为是断言,我们调用 AssertText() 类进行断言。
断言设计
在元素动作设计小节实验中我们调用 AssertText() 类进行断言,本小节实验我们来实现。
我们通过字符串进行断言。
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/action/element.py 文件中添加 AssertText() 类,编写如下内容:
class AssertText: def __init__(self, driver, element, expectText): self.driver = driver self.element = element self.expectText = expectText def equal(self): """文本内容相等判断""" assert self.get_text() == self.expectText def no_equal(self): """文本内容不相等判断""" assert self.get_text() != self.expectText def get_text(self): """获取元素文本内容""" if self.element == "alert": return self.driver.switch_to.alert.text else: return self.element.text
在 AssertText() 类下定义了三个方法 equal() 、 no_equal() 和 get_text() 。
get_text() 方法根据传入的元素获取元素文本值,如果传入的元素是关键字 alert ,则认为是浏览器弹窗,返回弹窗文本内容。如果是定位到的元素则获取元素文本内容并且返回。
equal() 方法是将 get_text() 方法返回的文本值与传入的预期文本值进行比较,如果相等则断言成功。
no_equal() 方法与 equal() 方法相反,如果 get_text() 方法返回的文本值与传入的预期文本值不相等则断言成功。
时间操作设计
在自动化测试中,我们需要设置一些时间使得程序可以更稳健的运行。
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/action/ 下新建文件 time_set.py ,编写如下内容:
import time class TimeSet: def __init__(self): pass def time_operate(self, action, parameter=None): """ 时间操作 :param action: :param parameter: :return: """ if action == "sleep" and isinstance(parameter, int): time.sleep(parameter) return else: return
我们新建了一个类 TimeSet() ,并且定义了一个方法 time_operate() ,当操作行为是关键字“sleep”时则认为是时间等待,等待的长度是传入参数 parameter 值。
对象操作设计
上面我们对各个对象的操作做了设计,并且进行了封装。下面我们需要对传入的对象进行判断,根据传入的对象来进入相应的对象类,而后进行对象操作。
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/action/ 下新建文件 operation.py ,编写如下内容:
import os, sys current_path = os.path.abspath(os.path.dirname(__file__)) autotest_path = os.path.join(current_path, os.path.pardir) sys.path.append(autotest_path) from action.browser import Browser from action.time_set import TimeSet from action.element import Element class Operation: def __init__(self, driver): self.driver = driver def operate(self, obj, action, parameter=None): """ 对象操作 :param obj: :param action: :param parameter: :return: """ obj = obj.lower() if obj in ["browser", "driver", "webdriver"]: return Browser(self.driver).browser_operate(action, parameter) elif obj == "time": return TimeSet().time_operate(action, parameter) elif obj is None or obj == "": return # 如果不是其他的关键字对象,则就认为是元素对象 else: return Element(self.driver).element_operate(obj, action, parameter)
我们新建了一个类 Operation() ,并且定义了一个方法 operate() ,当操作对象关键字是 browser 或 driver 或 webdriver 时则认为是浏览器对象,进入浏览器的操作;当操作对象关键字是 time 时则认为是时间对象,进入时间的操作;当操作对象关键字不是浏览器对象关键字,不是时间关键字对象,也不为 None 或空时,则认为是元素对象,进入元素的操作。
实验总结
实验知识点回顾:
- 浏览器操作设计
- 元素定位设计
- 元素动作设计
- 断言设计
- 时间操作设计
- 对象操作设计
本次实验是对关键对象(浏览器、元素、时间)的封装设计。当我们在测试用例中写入一个对象、操作及相关参数后,需要作出对应的操作,本次实验就是实现这些操作。
关键字驱动模型实战之测试运行
实验介绍
实验内容
在《Python Web 自动化测试入门实战》初级实验中给大家介绍过五种测试模型,其中线性模型、模块化驱动模型和行为驱动模型以实例给大家做了介绍。在本系列第七次和第八次实验给大家介绍了数据驱动模型。接下来会使用 pytest 框架实战关键字驱动模型。
在第十一次和第十二次中,我们分别对数据测试数据和对象操作进行了设计,本次实验我们将两者联系在一起,并且给测试项目添加日志,然后运行生成测试报告。
知识点
- 添加自动化测试用例
- 添加日志
- 日志深入记录
- 自动化项目运行
- 添加项目说明
代码获取
你可以通过下面的命令下载本节实验的代码到虚拟环境中,作为参照对比:
# 下载代码 wget https://labfile.oss-internal.aliyuncs.com/courses/3776/130.zip # 解压缩代码 unzip 130.zip
添加自动化测试用例
本节实验我们来收集测试用例,并且使用 pytest 框架的参数化功能,将测试用例添加到对象执行上。
添加共享 Fixture
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/case/ 下新建文件 conftest.py ,编写如下内容:
import pytest from selenium import webdriver @pytest.fixture(scope='session') def setup_teardown(): driver = webdriver.Firefox() yield driver driver.quit()
我们将浏览器的启动和关闭设置为前置条件和后置条件,作用域设置为 session 级别。整个自动化测试中只启动一次浏览器。
测试用例执行
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/case/ 下新建文件 test_case.py ,编写如下内容:
# -*-coding:utf-8-*- import pytest import os, sys current_path = os.path.abspath(os.path.dirname(__file__)) autotest_path = os.path.join(current_path, os.path.pardir) sys.path.append(autotest_path) from common.excel_util import ExcelUtil from action.operation import Operation def case(excel=None, sheet=None): return ExcelUtil(excel, sheet).get_case() @pytest.fixture(params=case(sheet='login')) def fixture_params(request): return request.param def test_run(setup_teardown, fixture_params): driver = setup_teardown Operation(driver).operate(fixture_params[0], fixture_params[1], fixture_params[2]) if __name__ == '__main__': pytest.main(['-s','case/test_case.py'])
在文件 test_case.py 下我们定义了三个函数,case() 函数是返回测试用例; fixture_params() 是代码在执行时会使用 pytest 内置的固件 request,并通过 request.param 来获取参数; test_run() 是使用我们在 /home/shiyanlou/Code/KeywordDrivenModel/action/operation.py 文件中定义的 Operation() 类中的 operate() 方法执行测试。
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下:

从结果中可以看到,一共执行了 12 条测试用例,与我们 Excel 表格中 12 条测试数据数量相吻合。
添加日志
日志是对软件执行时所发生事件的一种追踪方式。在本系列实验第九次实验中已经给大家介绍过了日志的使用。在此就直接上代码,不做介绍了。因为代码和第九次实验最后产生的 /home/shiyanlou/test/create_logging_file.py 文件代码相同。
添加创建日志代码
通过 VS Code 工具在 /home/shiyanlou/Code/KeywordDrivenModel/common/ 下新建文件 log_util.py ,编写如下内容:
import logging
import datetime
import os
class LogUtil:
def __init__(self):
current_path = os.path.abspath(os.path.dirname(__file__))
autotest_path = os.path.join(current_path, os.path.pardir)
file_name = datetime.datetime.now().strftime(autotest_path + "/log/%y-%m-%d-%H:%M") + '.log'
self.file_formate = logging.Formatter('%(asctime)s - %(filename)s - %(levelname)s - %(message)s')
self.logger = logging.getLogger(__name__)
self.logger.setLevel(logging.INFO)
# 将日志写入磁盘
self.file_handler = logging.FileHandler(file_name, 'a', encoding='utf-8')
self.file_handler.setLevel(logging.INFO)
self.file_handler.setFormatter(self.file_formate)
self.logger.addHandler(self.file_handler)
def get_log(self):
"""获取 logger"""
return self.logger
def close_handler(self):
"""关闭 handler"""
self.logger.removeHandler(self.file_handler)
self.file_handler.close()
def console_print(self):
"""控制台输出"""
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(self.file_formate)
我们以运行时间命名日志文件,并且将其保存在 /home/shiyanlou/Code/KeywordDrivenModel/log/ 下。
修改 conftest.py
添加创建日志文件代码完成后,我们需要将日志在项目运行中使用。
修改 /home/shiyanlou/Code/KeywordDrivenModel/case/conftest.py 文件,添加日志写入,并且将 logger 和浏览器 driver 一样以参数的形式传入到测试用例执行中。
修改后的 /home/shiyanlou/Code/KeywordDrivenModel/case/conftest.py 文件内容如下:
import pytest
import os, sys
import logging
from selenium import webdriver
current_path = os.path.abspath(os.path.dirname(__file__))
autotest_path = os.path.join(current_path, os.path.pardir)
sys.path.append(autotest_path)
from common.log_util import LogUtil
@pytest.fixture(scope='session')
def setup_teardown():
driver = webdriver.Firefox()
logging_file = LogUtil()
logger = logging_file.get_log()
logging_file.console_print()
logger.info('START ---- browser')
yield driver, logger
driver.quit()
logger.info('END ---- browser')
logging_file.close_handler()
在浏览器启动成功后添加浏览器启动日志信息,浏览器关闭后添加浏览器运行结束的日志信息。
修改 test_case.py
接下来修改 /home/shiyanlou/Code/KeywordDrivenModel/case/test_case.py 文件中的 test_run() 函数。修改后的内容如下:
def test_run(setup_teardown, fixture_params):
driver, logger = setup_teardown
try:
Operation(driver).operate(fixture_params[0], fixture_params[1], fixture_params[2])
logger.info("FINISHED ---- {} -- {} -- {}".format(fixture_params[0], fixture_params[1], fixture_params[2]))
except:
logger.exception("ERROR ---- {} -- {} -- {}".format(fixture_params[0], fixture_params[1], fixture_params[2]))
我们在对象操作运行结束后添加此条测试数据运行完成的日志信息,如果此条测试数据对象操作运行失败,则添加出错的日志信息。
然后点击 VS Code 工具右上角的执行按钮执行文件 /home/shiyanlou/Code/KeywordDrivenModel/case/test_case.py 。
代码执行结束后会在 /home/shiyanlou/Code/KeywordDrivenModel/log/ 下产生一个以时间命名且是 .log 格式的日志文件。我们来查看此文件内容,截图如下:

日志深入记录
在上小节添加日志中,大家有没有发现在修改 /home/shiyanlou/Code/KeywordDrivenModel/case/test_case.py 文件中 test_run() 函数时我们添加了一个 try...except... 语句,这是一个非常不合理的做法。如果当我们的测试数据在对象操作 Operation(driver).operate(fixture_params[0], fixture_params[1], fixture_params[2]) 中运行失败,那么此时程序会走 except,也就是说我们的测试函数 test_run() 依旧是成功的,在测试结果中展示的永远是成功,如果想要查看失败的测试用例只能在日志中查看,这显然是不明智的。
修改 test_case.py
接下来我们重新修改 /home/shiyanlou/Code/KeywordDrivenModel/case/test_case.py 文件中的 test_run() 函数。修改后的内容如下:
def test_run(setup_teardown, fixture_params):
driver, logger = setup_teardown
logger.info("START RUN ---- {} -- {} -- {}".format(fixture_params[0], fixture_params[1], fixture_params[2]))
Operation(driver, logger).operate(fixture_params[0], fixture_params[1], fixture_params[2])
logger.info("FINISH ---- {} -- {} -- {}".format(fixture_params[0], fixture_params[1], fixture_params[2]))
我们在对象操作 Operation(driver, logger).operate(fixture_params[0], fixture_params[1], fixture_params[2]) 前添加开始执行的日志信息,运行结束后添加执行完成的日志信息。并且将 logger 以参数的形式传入 Operation() 类。
修改 operation.py
接着修改 /home/shiyanlou/Code/KeywordDrivenModel/action/operation.py 文件。
logger 传入后就需要接收,我们先来接收,然后将其继续传入 Browser() 类、 TimeSet() 类、 Element() 类。
在此只做 Element() 类的传入,其他的类似,大家可自行照此深入写入。
修改后的 /home/shiyanlou/Code/KeywordDrivenModel/action/operation.py 文件内容如下:
import os, sys
current_path = os.path.abspath(os.path.dirname(__file__))
autotest_path = os.path.join(current_path, os.path.pardir)
sys.path.append(autotest_path)
from action.browser import Browser
from action.time_set import TimeSet
from action.element import Element
class Operation:
def __init__(self, driver, logger):
self.driver = driver
self.logger = logger
def operate(self, obj, action, parameter=None):
"""
对象操作
:param obj:
:param action:
:param parameter:
:return:
"""
obj = obj.lower()
if obj in ["browser", "driver", "webdriver"]:
return Browser(self.driver).browser_operate(action, parameter)
elif obj == "time":
return TimeSet().time_operate(action, parameter)
elif obj is None or obj == "":
self.logger.warning("obj keyword is none or empty ---- {} -- {} -- {}".format(obj, action, parameter))
return
# 如果不是其他的关键字对象,则就认为是元素对象
else:
return Element(self.driver, self.logger).element_operate(obj, action, parameter)
修改 element.py
我们接着修改 /home/shiyanlou/Code/KeywordDrivenModel/action/element.py 文件。
首先修改 Element() 类下的构造函数 __init__() 。修改后的代码如下:
def __init__(self, driver, logger): self.driver = driver self.logger = logger
然后修改 element_operate() 方法,修改后的代码如下:
def element_operate(self, local, action, parameter=None):
"""
元素操作
:param local:
:param action:
:param parameter:
:return:
"""
self.logger.info("element action start ---- {} -- {} -- {}".format(local, action, parameter))
element = self.__local_element(local)
if element:
self.logger.info("element local finished ---- {} -- {} -- {}".format(local, action, parameter))
else:
self.logger.exception("element local fail ---- {} -- {} -- {}".format(local, action, parameter))
if action == "input" and parameter:
element.send_keys(parameter)
self.logger.info("element input finished ---- {} -- {} -- {}".format(local, action, parameter))
return
elif action == "click":
element.click()
self.logger.info("element click finished ---- {} -- {} -- {}".format(local, action, parameter))
return
elif action == "assert":
AssertText(self.driver, element, parameter).equal()
self.logger.info("element assert finished ---- {} -- {} -- {}".format(local, action, parameter))
return
else:
self.logger.exception("element action fail ---- {} -- {} -- {}".format(local, action, parameter))
return
给每一步都添加日志记录信息。
下面点击 VS Code 工具右上角的执行按钮,执行文件 /home/shiyanlou/Code/KeywordDrivenModel/case/test_case.py 。
代码执行结束后会在 /home/shiyanlou/Code/KeywordDrivenModel/log/ 下产生一个新的日志文件。我们来查看此文件内容,截图如下:

从日志信息中可以,记录的内容更丰富,更详细。在后期的问题定位中会更容易。
自动化项目运行
下面我们来编辑 /home/shiyanlou/Code/KeywordDrivenModel/run.py 文件,内容与第八次实验数据驱动模型中的执行文件 /home/shiyanlou/Code/DataDrivenModel/run.py 内容类似,就不做解释,直接写代码。
编辑 /home/shiyanlou/Code/KeywordDrivenModel/run.py 文件内容如下:
# -*- coding: utf-8 -*- """ Created on 2021-4-20 Project: KeywordDrivenModel @Author: Tynam """ import os import pytest current_path = os.path.abspath(os.path.dirname(__file__)) case_path = os.path.join(current_path, 'case') def run_case(): pytest.main(['-v', case_path]) def create_report(): run_case = """ cd %s & pytest %s --alluredir ./report/result/ """ % (current_path, case_path) generate_report = """ cd %s & allure generate ./report/result/ -o ./report/report/ --clean """ % (current_path) os.system(run_case) os.system(generate_report) if __name__ == '__main__': # run_case() create_report()
然后点击 VS Code 工具右上角的执行按钮执行文件,截图如下:

我们在 VS Code 工具中使用 Live Server 打开 /home/shiyanlou/Code/DataDrivenModel/report/report/index.html。截图如下:

至此,我们关键字驱动模型实验已经完成。
添加项目说明
编辑 /home/shiyanlou/Code/KeywordDrivenModel/readme.md 文件,添加项目说明,编写规则。
内容如下:
## 目录结构 - action:对象执行目录,包括浏览器操作、元素操作等。 - case:测试用例操作目录。 - common:公共层,存放数据文件的读写、日志写入等公共文件。 - data:数据目录,存放使用 Excel 写入的测试数据。 - log:日志目录,测试执行后产生的日志文件保存在此目录。 - report:存放测试报告。 - `run.py`:运行脚本并生成测试报告。 ## Excel 编写规则 ####浏览器操作 | 描述 | 对象 | 操作 | 参数 | | ------------ | ------- | ----- | ---- | | 最大化 | browser | max | | | 访问网页 | browser | open | url | | 关闭当前 tab | browser | close | | | 结束进程 | browser | quit | | ### 时间操作 | 描述 | 对象 | 操作 | 参数 | | -------- | ---- | ----- | -------------------- | | 时间等待 | time | sleep | 等待时间值(单位秒) | ### 元素操作 | 描述 | 对象 | 操作 | 参数 | 备注 | | ------------------------ | ------------- | ------ | ------------ | ------------------------------------------------------------- | | 元素定位 | 定位字符串 | | | 默认 CSS 定位 | | 其他方式定位 | by:定位字符串 | | | by 是定位方式,可选值:css、id、class、name、tag、link、xpath | | 输入框输入内容 | 定位字符串 | input | 输入的字符串 | | | 点击 | 定位字符串 | click | | | | 断言 | 定位字符串| assert | 预期字符串 | 只支持文本内容断言 | | Alert 弹窗文本字符串断言 | alert | assert | 预期字符串 | |
写入后在 VS Code 中预览,截图如下所示:

实验总结
实验知识点回顾:
- 添加自动化测试用例
- 添加日志
- 日志深入记录
- 自动化项目运行
- 添加项目说明
本次实验是对关键字驱动模型的实战练习。大家在以后的学习、工作中,需要灵活运用。思路,解决方案都是类似的,面对不同的项目测试、不同的测试场景都可以变通无碍。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)