ICCV2023 | SRFormer:基于置换自注意力的图像超分辨率
论文:https://arxiv.org/pdf/2303.09735.pdf代码:https://github.com/HVision-NKU/SRFormer先前的工作已经表明,增加基于Transformer的图像超分辨率模型的窗口大小(例如,SwinIR)可以显著提高模型性能,但计算开销也相当大。本文提出了一种简单而新颖的SRFormer方法,它可以享受大窗口自注意的好处,并且带来的计算负担
SRFormer: Permuted Self-Attention for Single Image Super-Resolution
文章目录
2、Permuted Self-Attention Block
1、Classical Image Super-Resolution
2、Lightweight Image Super-Resolution
前言
论文:https://arxiv.org/pdf/2303.09735.pdf
代码:https://github.com/HVision-NKU/SRFormer
一、Introduction
先前的工作已经表明,增加基于Transformer的图像超分辨率模型的窗口大小(例如,SwinIR)可以显著提高模型性能,但计算开销也相当大。
本文提出了一种简单而新颖的SRFormer方法,它可以享受大窗口自注意的好处,并且带来的计算负担更少。
SRFormer的核心是置换自我注意(PSA),它在自注意的渠道和空间信息之间取得了适当的平衡。我们的PSA是简单的,可以很容易地应用到现有的基于窗口自注意的超分辨率网络。在没有任何花哨的情况下,SRFormer在Urban100数据集上实现了33.86db的PSNR评分,比SwinIR高了0.46db,但使用的参数和计算更少。
全文总结创新点如下:
(1)提出了一种新的图像超分辨率置换自注意方法,通过将空间信息转移到通道维度上,实现大窗口自注意。通过利用它,首次在sr中以可接受的时间复杂度实现了24x24大窗口关注机制。
(2)基于提出的PSA和从频率角度(ConvFFN)改进的FFN,构建了一个新的基于Transformer的超分辨率网络,称为SRFormer。SRFormer在经典,轻量级和现实世界的图像SR任务中实现了最先进的性能。
二、Method
1. Network Architecture
我们的SRFormer也基于Transformer。与直接利用自我注意力建立模型的方法不同,我们的SRFormer主要针对自我注意力本身。我们的目的是研究如何在一个大的窗口中计算自我注意,以提高SR模型的性能,而不增加参数和计算成本。
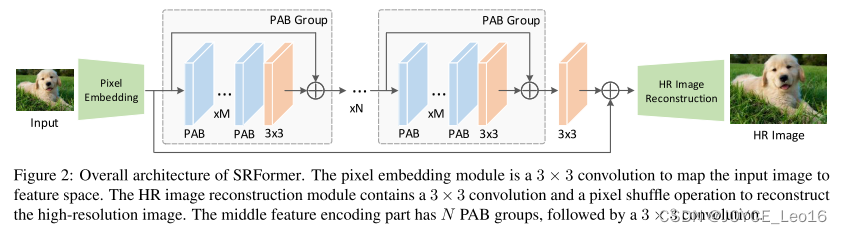
我们的SRFormer的整体架构如图2所示。由三部分组成:像素嵌入层、特征编码器
和高分辨率图像重构层
。根据以前的工作[33,77],像素嵌入层
是一个单一的3 × 3卷积,它将低分辨率RGB图像
转换为特征嵌入
。
然后将被发送到具有分层结构的特征编码器
中。它由N个置换的自注意组组成,每个组由M个置换的自注意块组成,然后是3 × 3卷积。在特征编码器的末尾添加3 × 3卷积,产生
。
和
的求和结果被送入
进行高分辨率图像重建,其中包含3 × 3卷积和子像素卷积层以重建高分辨率图像。我们计算高分辨率重建图像和地面真实HR图像之间的L1损失以优化我们的SRFormer。

Figure2:SRFormer的整体架构。像素嵌入模块是一个3 × 3卷积,将输入图像映射到特征空间。HR图像重建模块包含3×3卷积和像素混洗操作以重建高分辨率图像。中间特征编码部分具有N个PAB组,随后是3 × 3卷积。
2、Permuted Self-Attention Block
我们的SRFormer的核心是置换自我注意块(PAB),它由置换自我注意(PSA)层和卷积前馈网络(ConvFFN)组成。

Permuted self-attention
如图3(b),给定输入特征图Xin ∈ RH×W×C和令牌缩减因子r,我们首先将Xin分成N个不重叠的正方形窗口X ∈ RNS 2 ×C,其中S是每个窗口的边长。然后,我们使用三个线性层LQ、LK、LV来获得Q、K和V:
![]()
这里,Q保持与X相同的信道维数,而LK和LV将信道维数压缩为C/r2,从而得到K ∈ RNS 2 ×C/r2和V ∈ RNS 2 ×C/r2。然后,为了使更多的令牌参与自注意计算,避免计算量的增加,我们提出将K和V中的空间令牌置换到信道维度,得到置换令牌Kp ∈ RNS 2/r2×C和Vp ∈ RNS 2/r2×C。
我们使用Q和收缩的Kp和Vp来执行自我注意操作。通过这种方式,Kp和Vp的窗口大小将减少到Sr × Sr,但它们的通道尺寸仍然不变,以保证每个注意力头生成的注意力图的表达能力。拟定PSA的公式可写成如下:

其中B是对齐的相对位置嵌入,可以通过对[37]中定义的原始位置嵌入进行插值来获得,因为Q的窗口大小与Kp的窗口大小不匹配。是如[11]中定义的标量。注意,通过将通道分成多个组,可以容易地将上述等式转换成多头版本。我们的PSA将空间信息转移到通道维度。
它确保以下两个关键设计原则:i)我们不像[65,58]中那样首先对令牌进行下采样,而是允许每个令牌独立地参与自我注意力计算。
ii)与图中所示的原始自我注意相反。如图3(a)所示,PSA可以在大窗口(例如,24 × 24)使用比SwinIR更少的计算,同时获得更好的性能。
ConvFFN
先前的研究表明自我注意力可以被视为一个低通滤波器。为了更好地恢复高频信息,通常在每组变压器的末尾添加3 × 3卷积,如SwinIR中所做。
与SwinIR不同的是,在我们的PAB中,我们建议在FFN块的两个线性层之间添加一个局部深度卷积分支,以帮助编码更多的细节。我们将新块命名为ConvFFN。
我们经验发现,这样的操作几乎没有增加计算量,但可以弥补图4所示的自我注意引起的高频信息损失。我们简单地用FFN和ConvFFN计算SRFormer产生的特征图的功率谱。通过对比两幅图可以看出,ConvFFN可以明显增加高频信息,从而得到更好的结果,如表1所示。


三、Experiments
1、Classical Image Super-Resolution
对于经典的图像SR任务,我们将我们的SRFormer方法与一系列基于CNN和基于Transformer的SR方法进行了比较:RCAN、RDN、SAN、IGNN、HAN、NLSA、IPT、SwinIR、EDT和ELAN。

2、Lightweight Image Super-Resolution
为了证明我们模型的可扩展性,并进一步证明SRFormer的效率和有效性,我们训练SRFormer-light,并将其与一系列最先进的轻量级SR方法进行比较:EDSR-baseline、CARN、IMDN、LAPAR-A、LatticeNet、ESRT、SwinIR-light和ELAN。

3、Real-World Image Super-Resolution
由于图像SR的最终目标是处理丰富的真实世界退化,并产生视觉上令人愉悦的图像,我们遵循SwinIR,使用与BSRGAN相同的退化模型对SRFormer进行再训练,结果如图7所示。在面对真实世界的图像时,SRFormer仍然可以产生更逼真和视觉上令人愉悦的纹理,而不会出现伪影,这证明了我们方法的鲁棒性。

4、LAM Comparison
为了观察 SR 重建所使用的像素范围,我们将我们的模型与使用 LAM [15] 的 SwinIR 进行比较,如图 8 所示。基于极大的注意力窗口,SRFormer 推断出的 SR 图像的像素范围明显比 SwinIR 更宽。实验结果与我们的动机非常一致,并从可解释性的角度证明了我们方法的优越性。

四、Conclusion
在本文中,我们提出了 PSA,一种有效的自注意力机制,可以在大窗口内有效地构建成对相关性。基于我们的 PSA,我们设计了一个简单而有效的基于 Transformer 的单图像超分辨率模型,称为 SRFormer。
由于极大的注意力窗口和高频信息增强,SRFormer 在经典、轻量级和现实世界的 SR 任务上实现了最先进的性能。我们希望我们的排列自注意力可以成为大窗口自注意力的范例,并作为未来超分辨率模型设计研究的有用工具。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)