近似近邻检索ANN论文总结
与存储相关的近邻检索(Approximate Nearest Neighbor Search,ANN)相关论文总结
本文将持续更新,最新更新时间:2024-11-13
本文主要是个人笔记,记录与存储相关的ANN(Approximate Nearest Neighbor Search)工作,想着写都写了不如发出来与大家分享,大多写得比较简单有些稍微详细一点,内容仅供参考。
[1]Cognitive SSD: A Deep Learning Engine for in-Storage Data Retrieval[C]. S. Liang, Y. Wang, Y. Lu, et al. //2019 USENIX annual technical conference (USENIX ATC 19). 2019: 395-410.


-
- 为了提高数据局部性,将节点的邻居节点保存在同一个闪存页中降低读放大。
- 但是,这种布局会导致存储中的顶点重复,并牺牲额外的存储空间以获得更好的数据访问性能
[2]Accelerating Large-Scale Graph-Based Nearest Neighbor Search on a Computational Storage Platform[J]. J. H. Kim, Y. R. Park, J. Do, et al. IEEE Transactions on Computers, 2022, 72(1): 278-290.
解决问题:
-
- 需要大内存和高性能CPU,扩展性差
- We observe that the time spent for IO accounts for more than 70% of the total latency
方案:
-
- 数据集过大无法放入内存->将图划分为可以放入盘内DRAM的大小。然后在每个子图上进行近邻检索后合并、筛选结果。
- 原始的索引结构会导致无用数据的读取->分离表的结构,一次能够读取更多的邻居(没怎么看懂)
- 传统缓存方案命中率低(16.3%)->只缓存上层因为每次访问一定会用到
更新:这里重新解释一下数据布局的部分。他用的是HNSW算法,图有很多层,具体的图结构参考《HNSW算法》那篇博客。这里只解释一下他是怎么做数据重布局的。原始图结构和重布局后的结构如下图所示,左侧是原始的HNSW,包含2个表,一个表主要存储上层的邻居关系,一个表主要存储原始向量和底层的邻居。
至于为什么原来的图结构不行,原文并没有说清楚。原文说的是这种图结构“在上层中需要额外的计算来索引目标点,并且在0层和上层都会进行非对齐的内存访问。在图遍历的时候会增加外存访问次数”。我个人理解,是因为原始的HNSW图是存储在内存中的,所以没有考虑外存访问开销的问题,数据按照节点为中心进行组织,每个节点占用的内存空间比较大,因此想要访问一系列点的某项信息会导致很多无效数据的读取。例如,我要在顶层检索距离查询向量最近的点,那么我就要从入口点出发依次查询他的邻居。虽然入口点的邻居的index号可以很容易查询到,但是首先根据index读取原始向量需要查询maxM次0层表;其次是计算出最近点后,查询最近点的邻居又需要查询上层表并且偏移到其最后一个元素才能获取邻居的ID,访存次数十分可观。
因此,重布局的核心思想就是解耦,每个表仅存储一种信息,因此一次IO可以读取很多点的相关信息。我认为解耦后。解耦后包含3种表:①首先是把原始数据按照数组的方式顺序存放的一张Raw data table表 ②然后是list table,list table存储的是每个层次中的邻居关系,有多少层就有多少张。因此除0层外,每张表的行数是不一样的,某个点在非0层list table中的位置是未知的,那么如何索引某个点非0层的邻居呢?这就是第③张表的作用,Index table存储了每个点在每个层的邻居信息的指针。如果某个点存在于某一层,那么可以直接通过Index table存储的指针找到list table中的那一行。
不过布局优化后的检索流程,文中并没有描述。根据我的理解,还是刚刚那个例子,当在顶层从入口点出发查找邻居时,仍然需要先在Index table查询到邻居表项的指针,然后访问顶层的list table后根据邻居的index号从Raw data table读取原始数据并计算,然后再从Index table读取最近的一个邻居的邻居表项,看起来并没有减少I/O次数。可能是我理解不到位吧。
但是解耦后是否会产生问题,例如更新的开销是否会急剧增加?(不过一般都没有考虑图更新的问题)其次这个是否还有可以优化的地方,例如每行之间是随机排布的吗,可以按照邻居关系对他进行排列提高读取数据的效率。

[3]CXL-ANNS: Software-Hardware Collaborative Memory Disaggregation and Computation for Billion-Scale Approximate Nearest Neighbor Search[C]. J. Jang, H. Choi, H. Bae, et al. //2023 USENIX Annual Technical Conference (USENIX ATC 23). 2023: 585-600.
Knowledge:
-
- Microsoft search engines (used in Bing/Outlook) require 100B+ vectors, each being explained by 100 dimensions, which consume more than 40TB memory space
- Alibaba’s e-commerce platforms need TB-scale memory spaces to accommodate their 2B+ vectors (128 dimensions)
解决问题:
传统的量化方案会导致精度损失,而非量化方案又会导致大量的内存占用,难以在单机上满足需求,CXL的出现使其成为了可能。然而CXL内存池的访问延迟比本地DRAM延迟高很多,如果单纯的将ANN部署在CXL内存池上会出现性能的严重下降(约3-5x,图8)。
方案:
为了提高在CXL扩展内存上执行ANN的性能,CXL-ANN做了以下工作:
-
- 分区缓存。因为许多ANN算法的入口点都是一样的,因此CXL-ANN将入口点附近N条的邻居缓存到本地内存中,而不是采用动态缓存替换。
- 预取邻居。CXL-ANN观察到(图18)有80%左右的后续访问都是候选列表更新前的节点。因此CXL-ANN在图遍历立即读取候选列表中前面的节点,而不是等主机更新候选列表后再发起读请求。提高命中率降低I/O开销。
- 在CXL设备上进行近存处理。因为主机只需要获取两个节点的距离,不需要读取完整的节点,因此在CXL设备上进行距离计算后返回结果,可以节约大量的I/O开销。
- 任务调度。候选列表的更新包含插入、排序、选取三个步骤。为了尽快发起图遍历请求,CXL-ANN优先执行节点选取操作,选出节点发起I/O请求后再进行耗时的插入和排序。
[4]Processing-In-Hierarchical-Memory Architecture for Billion-Scale Approximate Nearest Neighbor Search[C]. Z. Zhu, J. Liu, G. Dai, et al. //2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023: 1-6.
Knowledge:
-
- The memory capacity of main memory level NMC (e.g., 64GB) cannot meet the storage requirement of ANNS on billion-scale datasets (e.g., 800GB)
- The major performance bottleneck of CPU-based ANNS systems is the tremendous amount of data access that accounts for 80% of the total search time.
解决问题:
使用近存架构处理ANN时,近内存计算可能内存容量不足,近存储计算会由于不规则的I/O访问导致高I/O开销,读有效率和命中率分别只有39% 和16%。需要结合近内存和近存储的优势以提高性能。
方案:
-
- 所谓的充分利用近内存和近存储的优势,就是把节点聚类后,将中心点存到内存中便于索引图,然后这个聚类中的其他节点集中存到存储器中便于集中读取。
- 整体架构如下图。现在内存中读取到邻居,然后返回邻居的索引Nid。然后根据Nid获取到邻居的向量并且计算邻居和查询节点的距离,这一步用近内存计算加速计算。获取到最近的邻居后,根据最近的邻居的Cid去SSD中获取到该聚类中的所有向量,然后返回topK个节点,这一步用近存储计算做加速。

-
- 还有一些加速器的工作,例如近存计算的距离计算加速器、topK排序加速器和SSD中的每个通道上的距离计算加速器。
- 为了提高吞吐量,一批一批地处理查询以便于充分利用SSD的多通道并行性。(感觉这个不算一个设计点,因为并发地发起查询请求自然就能达到这个效果)。
问题:
-
-
- 需要将图划分得比较细然后建立索引,内存开销仍然很高。
-
[5]Spann: Highly-Efficient Billion-Scale Approximate Nearest Neighborhood Search[J]. Q. Chen, B. Zhao, H. Wang, et al. Advances in Neural Information Processing Systems, 2021, 34: 5199-5212.
相关资料:
[论文分享] SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search
终于把微软BING搜索-SPTAG算法的原理搞清了-腾讯云开发者社区-腾讯云
解决问题:单个磁盘访问粒度在几十到几百 KB 不等,且不具备访问的局部性,因此不能有效地利用外部存储器件的预读机制和操作系统的缓存机制,同时产生读放大。
Idea:针对大规模向量近似搜索场景,采用小内存和大硬盘混合存储的策略。SPANN 基于倒排索引(IVF)设计,能够有效地将相似的向量以小规模聚类集合的方式连续地存储在磁盘上,通过加载有限个数的聚类集合来减少磁盘访问。
挑战:
- 大量聚类数量下仍然保持每个posting list(i.e. IVF方法中的某个聚类下的向量列表)长度均衡,否则将导致某些聚类读取过多的向量增加开销;
- 某些质心距离查询点较远的聚类中的边缘点可能会被忽略。例如下图中的红点,虽然红点是距离查询点黄点最近的点,但是由于他的质心相比绿点的质心更远,所以就被忽略掉了;
- 每个查询需要访问的聚类数量是不一样的,如下图所示,81.78%的查询都只需要访问6个聚类就可以实现100%的召回了。如果总是访问同样数量的聚类可能导致某些查询造成不必要的访问有些查询访问不到所需的聚类

方法:
- 针对挑战1,SPANN采用了一种叫做分层多约束平衡聚类技术(hierarchical multi-constraint balanced clustering technique)来平衡postling list的长度(没看懂。。。)。然后SPANN会把聚类分得特别细,按照另一篇博客的说法,SPANN中每个posting list仅包含数十个向量,因此聚类数量特别多。计算查询向量到每个聚类中心的距离开销特别大,因此SPANN把聚类中心更换为距离中心最近的向量,因此没有浪费掉计算这些中心的计算量。此外SPANN可以给聚类中心构建一个SPTAG加快查询。
- 针对挑战2,SPANN采用的点分配策略包含2部分。首先是他会把点分配到最近的几个cluster中提高访问到的几率,然而这样的话可能导致重复点的数量过多,因此他会根据RNG规则跳过某些聚类。跳过聚类的核心思想是认为把一个点反复存储在几个相邻的聚类中,不如把他存到相对较远的聚类中,因为相邻的聚类在检索的过程中本来就很可能被同时访问。因此当两个聚类中心cij与cij-1的距离还没有cij到查询点x的距离远时,就跳过聚类cij(这两个策略听起来其实是互相矛盾的,不知道我哪里理解错了)。
- 针对挑战3,SPANN 采用查询感知的剪枝方法来调整不同查询向量需要加载的候选聚类的数目。通常,在倒排文件的检索过程中,首先会找到相同个数个最近的聚类中心点,然后对固定个聚类进行全量的搜索。然后,由于查询向量具有差异,有的“容易”查询向量只需要检索少数的聚类就能够获得高召回,而有的“难”查询向量需要检索更多的聚类。倒排文件使用相同的查找聚类个数会导致“容易”的查询向量需要检索很多召回收益不高的聚类。SPANN 通过查询向量与聚类中心点的距离远近程度来确定对该聚类的搜索是否是高召回收益的。SPANN 利用查询向量x到与其最近的聚类中心点ci1的距离作为尺度,使用参数来控制动态剪枝的程度。当查询向量和某聚类中心点的距离大于参数,则认为是查询向量和中心点距离较远,对这一聚类进行进一步搜索的收益不高,可以进行剪枝,不对其进行搜索。剪枝策略如下所示:
![]()
实验部分,性能就不多说了反正没有哪篇论文性能不是爆炸好的。这里提一下他的实验设置。他设置每个向量最多冗余存放到8个聚类中,每个posting list最大长度48KB(float)或者12KB(int8),因此以SIFT1M为例他最多存储96个向量,那么聚类数量约有1万个,非常恐怖。
2024.7.10补充
该团队在SOSP'23上还发表一个后续工作SPFresh,主要关心的是SPANN上的增删问题,详情解析可参考:
SPFresh: Incremental In-Place Update for Billion-Scale Vector Search
[6] DF-GAS: A Distributed FPGA-as-a-Service Architecture towards Billion-Scale Graph-Based Approximate Nearest Neighbor Search[J]. S. Zeng, Z. Zhu, J. Liu, et al. 2023.
待补充.....
[7] 一种基于异步 I/O 的磁盘向量检索算法[J]. 吴松林, 田春岐, 毕枫林. Computer Science and Application, 2024, 14: 68.
主要思想就是把DiskANN中的I/O操作从阻塞读变成io_uring,并且在异步读时进行距离计算、更新候选列表等操作。
[8] Diskann: Fast Accurate Billion-Point Nearest Neighbor Search on a Single Node[J]. S. Jayaram Subramanya, F. Devvrit, H. V. Simhadri, et al. Advances in Neural Information Processing Systems, 2019, 32.
(本文解读来源于另一篇博客+一些个人补充)
一台只有 64G 内存的个人电脑连十亿原始数据都放不下,更别说建索引了。摆在我们面前的有两个问题:1. 如何用这么小的内存对这么大规模的数据集建索引?2. 如果原始数据内存放不下如何在搜索时计算距离?
本文提出的方法:
(3.1)对于第一个问题,先做全局 kmeans,将数据分成 k 个簇,然后将每个点分到距离最近的 I 个簇中,一般 I 取 2 就够了。对每个簇建基于内存的 Vamana 索引,最后将 k 个 Vamana 索引合并成一个索引,合并的方法就是两个图中相同的点就把边合并。
对于第二个问题,可以使用量化的方法,建索引时用原始向量,查询的时候用压缩向量。因为建索引使用原始向量保证图的质量,搜索的时候使用内存可以 hold 住的压缩向量距离计算。这时的压缩向量虽然有精度损失,但是建图的时候用的是全精度向量,能够把搜索方向带往正确的方向。
具体而言,DiskANN将包含全精度向量的图存在SSD上,PQ压缩后的向量(不包含图)存储在内存中。在检索图的时候,每次都需要去读SSD以获取邻居获取邻居id,然后读到邻居id后在内存中读取PQ向量进行距离计算。其实最开始看到这个方法的时候感觉有点奇怪,为什么不能把图存在内存中,避免每次获取邻居都要读SSD。我推测原因是首先图很大内存可能存不下(以bigann为例,10亿节点*4B(节点id)*50(假设平均50个邻居)=186.3GB);其次是获取邻居只需要一次IO因为一个点的邻居是集中存储的,但是原始向量无法集中存储,这样做的话反而读取向量会带来非常多的IO。
(3.2)关于索引的布局,论文中并没有介绍太多。3.2主要说的就是上面说的SSD存图+全精度向量,内存上存PQ向量。在磁盘上,对于每个点,先存储他的原始向量,然后存储他的后R个邻居的id。如果邻居小于R个那么用0填充。这样的话可以让每个点的占用空间都是一样的便于直接根据偏移量索引。(更新:关于索引布局的部分可以参考我的另一篇博客,详细分析了DiskANN生成的索引的数据格式:DiskANN数据布局-CSDN博客)
前面提到了,如果索引数据放在 SSD 上,为了保证搜索时延,尽可能减少磁盘访问次数和减少磁盘读写请求。因此 DiskANN 提出两种优化策略:
(3.3)Beam search: 简单的说就是批量读取。搜索 p 点时,如果 p 的邻居点不在缓存中,需要从磁盘加载 p 点的邻居点。由于一次少量的 SSD 随机访问操作和一次 SSD 单扇区访问操作耗时差不多,所以我们可以一次加载候选列表中W 个最相近的邻居信息,W 不能过大否则会浪费计算和 SSD 带宽让延迟变大。
(3.4)缓存热点:将起点开始 C 跳内的点常驻内存,C 取 3~4 就比较好。
(3.5)重排序:因为存储的时候全精度向量和邻居是存在一起的,所以可以一起读取上来而没有任何额外开销(因为闪存的读粒度通常为4KB,大于全精度向量+邻居的大小)。当读到原始向量后,DiskANN会根据原始向量重新计算该点的距离然后对候选列表进行重排序。
20240704更新:重看了关于建图算法的部分。我对建图不是很熟,如有错误欢迎指出。
DiskANN相比于其他建图方法,最大的改进就是加了一个系数α。传统的建图流程中,当我们要建立一个点p的邻居点集时,会先找到数据集P中离点p最近的点p*并加入p的邻居集,然后在p的邻居候选集中删除所有点p',p'满足d(p,p')≥d(p*,p')。直观来说就是,删除离p*更近的点。我画了个示意图如下。具体为什么要这么干还不是很懂。我猜测这样设计的动机就是,这些离p*更近的p'不应该加入p的邻居中,这些p'应该交由p*去到达。

至于DiskANN加了α后,这个排除条件就变成了d(p, p')≥α*d(p*, p')。因此加了α后,效果类似于让这根中垂线往上又挪了一点。因此只是离p*更近还不能轻易排除,要近到一定程度,近到离p*的距离乘了一个倍数后都还是离p*更近才行。那么这样做的效果就是未排除的点到p的平均距离会变长,就会增加一些长边,可以更快地跳到目标点。
具体到建图算法,先贴上论文中的算法:

首先第一行,先生成一张随机图。第二行是数据集P的中心点(不知道怎么来的,可能是随机指定?)。第三行是一个随机序列,作用就是使Xσ(i)代表一个随机点。
然后第四行开始遍历每个点。首先进行一次常规的搜索,获取到最终的候选列表L和访问过的点集V。然后第六行对这个随机点进行剪枝,候选集是之前检索时访问过的点。猜测这里用V而不是P的原因是减少计算量。
然后第七行这个for的目的就是把这个剪枝完成的随机点加入到该点的每个邻居的邻居表中,使他们能够互相找到。如果超出邻居点的邻居列表长度了就加入该点后对邻居进行剪枝。
[9] ES4D: Accelerating Exact Similarity Search for High-Dimensional Vectors via Vector Slicing and In-SSD Computation[C]. J. Kim, J. Seo, J. Park, et al. //2022 IEEE 40th International Conference on Computer Design (ICCD). IEEE, 2022: 298-306.
解决问题:精确匹配KNN检索中需要读取大量的向量数据,磁盘方案的I/O开销或者内存方案的内存开销都非常高。
核心思想:
因为是需要精确匹配,所以只能筛掉肯定不能匹配的向量。那么一个是可以把向量聚类,如果这个类别里面最近的向量都离查询点很远,这个聚类就可以不看了;其次是计算距离的时候,逐个特征计算,如果算到前几个特征的距离都已经超过当前的最近距离了,那么后面的特征也就没必要算了。
方案:
1. 聚类级别提前终止:如果一个聚类中,距离查询点最近的点,都超过了当前候选列表中最远的点,那么这整个聚类都没必要再计算了。具体做法是画两个圆,一个是该聚类中心为圆心,最远的点为半径的圆;另一个是查询点为圆心,聚类中心最远的点为半径,然后判断这两个圆是否相交即可。

这个工作还观察到,因为第二个以查询点为圆心的圆的半径是会随着查询的进行越来越短,那么尽早让半径缩短可以有助于筛选掉更多的聚类。因此他们在计算时先进行了一个排序,优先检索距离查询点q最近的聚类,进一步减少计算量。
2. 维度级别提前终止:由于L2距离是随特征数量单调递增的,那么前面几个特征的距离如果已经超过了当前候选列表的最长距离,后面的也不用算了距离只会越算越大。所以具体的做法就是,一个page只存储一批向量的前几个特征,然后读取一个page后可以提前筛选掉一些向量,然后继续读取下一个page。当被筛选光后,后面的page就可以不用读了。

但是这样做有个问题,因为闪存的读取粒度是Page,所以只要这一批向量里面还有一个没有被终止的,其他的向量还是被迫需要继续读取,浪费了读带宽。针对这一问题,本文提出了2个方法。第一个是二次聚类(sub-cluster),在一个聚类内部再聚类一个,离得比较近的当做一批向量一次存进一系列闪存里面,让他们尽量同时被筛选掉;第二个方法是维度重排序。因为维度的顺序其实没有什么意义,那么如果能把差距较大的维度放在前面先算,就能更早的筛选掉。那么怎么找到差距较大的维度,本文提出的一个简单方法是算一个所有向量的每个维度的平均值M,然后计算每个聚类中心中每个维度和M的距离d=ci-M,然后根据d的大小对特征进行排序存储,就可以以更大的概率优先计算到距离较大的特征维度提早筛选。
3. 当闪存通道数和一批特征需要的Page数相同时,每次检索的时候都是从同一个闪存通道开始,极大地降低了并发性,本文将一批特征的第一个Page均匀分布在不同闪存通道中避免这一问题。
[10] AiSAQ: All-in-Storage ANNS with Product Quantization for DRAM-free Information Retrieval. K. Tatsuno, D. Miyashita, T. Ikeda, K. Ishiyama, K. Sumiyoshi, and J. Deguchi. arXiv preprint arXiv:2404.06004, 2024.
Takeaway:这篇文章为了解决DiskANN内存消耗仍然很高的问题,在领接表中存储了每个邻居的PQ向量以避免在内存中存储PQ向量,极大地减少了内存开销并且不会引起过多的I/O次数,能够实现和DiskANN相近的性能。然而存储开销会放大很多倍,本文的方案很难在召回率和存储开销间实现tradeoff。
要解决的问题:
虽然DiskANN支持在内存不足的情况下进行检索,但是他仍然存在以下3个问题:
- 内存用量仍然很高。DiskANN将向量压缩后存储PQ向量在内存中以减少IO次数,但是他仍然需要O(n)级别的内存用量。例如在BigANN下如果每个向量使用32B进行量化,仍然需要使用32G的内存,约为原始数据集的1/4。
- DiskANN没有考虑局部性的问题。DiskANN在检索的时候使用到的向量仅占很小的一部分,但是仍然选择将所有向量都存储在内存中带来的高昂的内存开销。
- DiskANN加载模型的时间开销很高。在LLM快速发展的今天,需要在不同的向量数据库之间进行切换以支持针对不同领域的LLM语料库。在需要切换语料库时会带来高昂的时间开销,因为DiskANN需要加载所有向量的PQ向量,加载时间非常长;如果选择把所有语料库的索引都保存在内存中则将带来高昂的内存开销。
方法:
为了解决以上问题,AiSAQ的目标是实现极低内存开销的磁盘ANN检索。它将 PQ 向量数据从 DRAM 卸载到存储,并以几乎零内存使用量为目标,并且不引起显著的延迟增加。
至于AiSAQ所使用的方法其实很简单暴力,就是在邻居表中存储每个邻居的PQ向量。因为一个点的邻居列表通常不会很大(假设有30个邻居,邻居的id是uint32类型的,那么邻居表只需要30*4=120B),远小于一个磁盘Block的大小。因此AiSAQ将每个向量的PQ向量也存在邻居表里面(假设PQ向量为32B,那么30个邻居的PQ向量大小为32*30=960B)也不会引起额外的I/O开销。极大地降低了I/O的次数。
因为每次读取邻居表的时候都可以获取到邻居的PQ向量,因此内存中无需存储节点的PQ向量,计算距离后即可驱出内存。但是由于邻居表中只存储的邻居的id和PQ向量,并没有存储该节点的向量,因此需要保存入口点的向量,不过内存开销很低。(这部分存疑,没太看懂)
个人总结:
- 这篇文章的方法其实很暴力,是一个比较容易想到的减少IO次数的方法,也确实很有效能大幅降低IO次数并且能够适用于各种基于图的算法。但是这个方法并无太大实用价值,因为无法在存储开销和召回率间达到可以接受的平衡。具体而言,AiSAQ需要存储过多的额外邻居点的PQ向量。图的平均出度为多少,他就需要额外存多少倍的向量。例如,文中提到他面向的是10亿级别的向量规模,我们就还是以BigANN为例。BigANN中每个向量PQ压缩为32B(再低的话召回率将严重下降),每个节点30个邻居,那么每个节点就需要32*30=960B的空间。10亿个节点将需要10亿*960B=960GB的空间,相比与BigANN的原始数据集120G,存储空间开销增大了8倍。然而文中并没有谈到这个问题。当处理SIFT1M数据集时,空间会膨胀为
。应该可以接受?
- 不过这篇文章的故事讲得挺好的,一般就只想着讲“低内存开销的ANN”这个故事,可能从成本或者边端场景的角度去讲。这篇文章结合了现在爆火的LLM,从LLM语料库切换开销的这个角度去讲,很新颖。
[11] LM-DiskANN: Low Memory Footprint in Disk-Native Dynamic Graph-Based ANN Indexing[C]. Y. Pan, J. Sun, H. Yu. //2023 IEEE International Conference on Big Data (BigData). IEEE, 2023: 5987-5996.
这篇文章要解决的问题和方案都与AiSAQ很相似(按照AiSAQ的说法,LM-DiskANN是在AiSAQ提交时刚刚发布的),就不细讲了。
[12] Diskann++: Efficient Page-Based Search over Isomorphic Mapped Graph Index Using Query-Sensitivity Entry Vertex[J]. J. Ni, X. Xu, Y. Wang, et al. arXiv preprint arXiv:2310.00402, 2023.
Takeaway:DiskANN没有考虑入口点的选择问题,所有查询都从同一个顶点进入,导致路径过长。并且节点布局分散导致了大量的额外IO。针对这个问题这篇文章进行了:(1)入口点选择,对向量进行聚类后选择最近的聚类中心作为入口点开始搜索;(2)图索引的同构映射,传统的DiskANN图是分散布局的没有考虑节点之间的相关性,这篇文章将相邻的节点存在同一个闪存页上减少IO次数;(3)页面搜索,在I/O请求期间利用空闲的 CPU 资源来进一步在已经读取的闪存Page上继续搜索有没有更近的节点。
方案:
- 入口点选择上主要就是先聚类,然后找到距离聚类中心最近的点作为这个聚类的入口点。检索阶段与聚类中心逐一比对找到最近的聚类后从该聚类的入口点进入。因为比对聚类中心需要计算,当聚类数量过多时将会导致较大的延迟。因此当SSD速度快时可以设置较少的聚类中心。
- 同构映射我的理解是在保持原有图结构不变的情况下将图映射到另一个命名空间。具体到ANN中那就是给图的每个节点重新分配ID,目的是使得相邻的节点有相邻的ID(DiskANN中图的节点ID是随机的,相邻的点也会随机分布在SSD上)。具体流程在下图中已经展示得比较清楚了。同构映射包含两个阶段,Packing和Merging。Packing按我的理解,就是按照页面大小获取节点的邻居,然后给这些点重新分配ID使他们相邻;Merge的目的就是让没有填充满的页面合并。具体而言,Packing时先取出一个未访问的点,然后获取他最近的N个邻居放到一个虚拟Page中(如果没有这么多邻居就用0填充)。在Merge阶段,使用了首次适应递减算法,每次都取出空闲空间最少的虚拟Page和更小的页面合并,直到不能合并。不过我有一个比较疑惑的地方,ANN图的连接是很随机的,可能有很多连到远处节点的长边,通过这种方式的话开始遍历到的节点是可以比较集中的存放。但是到了后面的话遍历到的点的邻居已经作为其他点的邻居被遍历过了,剩下很多零散的点,检索时经过这些点时仍然会导致大量的随机IO。这种点有多少?对他们的存放是否还有优化空间?此外,他是按照点和该点的1-hop邻居进行存放的,那么在每次要获取邻居的邻居的时候仍然需要IO,是否可以考虑将邻居的邻居也存放进来?

- 页面搜索就是把读取过的页面缓存起来,然后用其中的顶点构建一个最小堆。在异步IO读取的期间,CPU从最小堆里面取出距离查询向量最近的顶点进行距离计算,以试图找到更近的顶点,然后异步IO读取完成后即结束计算。这个方法有效的依据应该是读取到的page中有许多未被访问到的点(因为不是候选列表中的点的邻居)。根据实验结果表明该方法可以降低许多IO次数,但是一个奇怪的地方是这个页面搜索方法只能降低同一page被重复访问时的IO,并不能直接减少IO次数,因此我认为能够降低IO次数的原因可能是能够更快地迭代收敛。
个人总结:
如上面所示的疑惑,图的盘上布局是否还有改进空间?不过这篇文章动机明确,方案合理,写作和图表通俗易懂,相信很快就会被顶会录用。
[13] Hm-Ann: Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory[J]. J. Ren, M. Zhang, D. Li. Advances in Neural Information Processing Systems, 2020, 33: 10672-10684.
Takeaway:针对DRAM+NVM的混合内存场景下的ANN检索,由于NVM延迟较高因此应该减少访问次数。针对混合内存,HM-ANN认为HNSW的分层结构天然适用于该场景,具体的改进还包括:(1)构建高质量的上层:HM-ANN将HNSW中的底层放在NVM中,其余上层都放在DRAM中。为了尽量减少NVM的访问,因此要在DRAM中就定位到更精确的向量区域。HM-ANN通过选择度数更大的节点到上层和使上层更密集的方式,提高上层节点的定位能力;(2)在搜索阶段的优化包括:①HM-ANN先在L1层进行搜索(L1层的Candidate List长度由efSearchL1参数控制),以进一步精确定位;②HNSW只有一个入口点,HM-ANN使用多个入口点同时搜索以充分利用NVM的带宽;③在搜索L1层时,将 efSearchL1中的那些 candidates 的邻居元素及其在第 1 层的连接从 PMem 复制到 buffer。当第 0 层的搜索发生时,一部分数据已经在 DRAM 中被 prefetched 了,隐藏了访问 NVM的延迟(这部分没太读懂,原文也没写清楚)。
具体细节的话,可以参考这篇解析,写得足够清楚:论文赏析:极致性价比,非易失性内存在向量检索的应用
[14] Grip: Multi-Store Capacity-Optimized High-Performance Nearest Neighbor Search for Vector Search Engine[C]. M. Zhang, Y. He. //Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1673-1682.
部分参考自:面向大规模向量搜索引擎的内存-硬盘优化的近似最近邻搜索算法(GRIP)_hnsw 内存消耗-CSDN博客
Takeaway:Grip的目的是构建一个使用DRAM+SSD的ANN检索系统(这篇文章和DiskANN是同时发表的)。在建图阶段,Grip采用了HNSW+IVFPQ,先对向量进行聚类然后在内存中用HNSW在聚类中心上进行建图,以避免线性扫描聚类中心;在检索阶段,Grip采用两阶段方式,现在内存中通过图定位到聚类中心,获取粗略的候选列表,然后分批异步地读SSD以精确地重新排序候选列表。
要解决的问题:
- 基于图的方法内存消耗非常高,如果传统基于图的检索会产生大量的随机存储访问,对SSD不友好
- SSD的延迟很高,如何利用好SSD是一项挑战
- 为了减少内存占用,Grip对向量进行了PQ压缩。可是数据压缩会对召回率产生影响
方法:
1. 本文先对IVFPQ的簇大小设置进行了分析。首先是可以通过增加候选列表的长度提高召回率(图1里的hit ratio我认为就是召回率),如图1a所示;其次是探究了簇大小对延迟的影响,如图1b所示。当选择进行搜索的簇越多时簇内检查时间Tc将会变长(这里其实不是很理解这个图为什么是这个趋势,可能是对selected cluster的理解有误);然后分析了聚类数量对召回率的影响,如图2a所示。例如在召回率都会0.6时,NC=1K(设置1000个聚类)相比NC=4K时可以少检查一半的聚类。然而NC=4K时每个聚类里面向量的数量只有=1K时的1/4,=16K时也展现出了类似的结果。因此聚类数量越多可以减少需要检查的向量数。


2. Grip和DiskANN类似,都将PQ向量存在内存中全精度向量存在SSD上。索引阶段分为2步,preview和validation。我理解的就是现在内存中用PQ向量确定候选列表,然后通过读SSD的全精度向量来进行二次验证。架构如图3所示,分为DRAM(被称为预览层)和SSD两个部分。DRAM先将PQ向量(图中成为short code)聚类,然后用中心节点建图,用图路由到最近的聚类中心。如果聚类中心接近查询节点那么这组向量会被一起选择。
![]()
3. 为了克服SSD延迟高的问题,Grip引入了3个技术:
- 图路由索引(GRI):图路由索引返回少量集群,这些集群更好地定位在查询点周围,具有低延迟、高精度和可达性保证。GRI是由HNSW算法构建的,针对HNSW的孤立节点(isolated nodes)问题做了优化增强了连通性。
- PQ*:PQ 的一种变体,通过为每个向量存储一个小的部分距离值(partial-distancevalue,PDV)值,进一步将检查向量的成本降低一半。PDV降低的是PQ计算过程中内存查表的次数,将表中的两项需要读出来求和的、和查询向量无关的数据预先求和并存下来,具体原理不是很懂,和PQ的具体计算原理有关。
- Lab-SSD-Val:它通过异步和多候选批处理(multi-candidate batching)技术在 SSD 上执行轻量级验证。通过将查询分成多个批次并异步加载每个批次,将候选列表 R 中的 B 个候选向量合并为一大批,并向 SSD 提交 S = ⌈R/B⌉ 批量请求以覆盖整个列表。然后,一旦候选向量的全精度向量从 SSD 加载到 DRAM 中,我们就会对其进行验证。批量请求使 GRIP 能够利用 SSD 的内部并行性并做出性能更好的 I/O 请求调度决策。异步 IO 解除了 GRIP 搜索过程的阻塞,并允许距离计算与 I/O 重叠并隐藏 SSD 访问延迟。(前面这段是直接翻译的原文,感觉说白了就是读原始向量的时候分批读,读上来一批计算一批,提高闪存的并发度和计算和SSD间的并发度)
[15] Manu: A Cloud Native Vector Database Management System[J]. R. Guo, X. Luan, L. Xiang, et al. arXiv preprint arXiv:2206.13843, 2022.
详细解析可参考,写得很详细:我的七周七数据库 -- Manu: A Cloud Native Vector Database Management System - 知乎
Takeaway:Manu是一个云原生数据库,主要考虑的是实际环境中的可伸缩、高可用、一致性问题。文章描述的主要是和数据库架构如下图所示,关注的是可伸缩、一致性和高可用相关的内容,没有太多与存储性能相关的内容。

[16] Milvus: A Purpose-Built Vector Data Management System[C]. J. Wang, X. Yi, R. Guo, et al. //Proceedings of the 2021 International Conference on Management of Data. 2021: 2614-2627.
详细解析参考,主要就是照着原文翻译的:Milvus:A Purpose-Built Vector Data Management System - 知乎
Takeaway:Milvus和Manu都是Zilliz的产品,Milvus是初代产品。Milvus是一个比较完善的向量数据库产品,关注的点主要包括数据更新、AVX指令集加速、GPU加速和CPU协同、属性过滤检索和多向量检索、快照隔离等方面。存储优化方面,首先是向量存储优化,Milvus采用了单个向量行存储、多向量间列存储的模式,以加快多向量检索;其次是CPU缓存优化,主要是针对多线程检索的情况优化的,因为他们观察到每个线程都是独立检索整张图,那么每个线程在检索每个向量的时候都要把图读一遍,导致读内存频繁。Milvus的思路大概就是把向量分批,读上来一批向量后提供给所有线程进行检索,然后再集中读下一批向量(这个思路感觉可以扩展到基于SSD的ANN检索上)。

[17] GLIST: Towards in-Storage Graph Learning[C]. C. Li, Y. Wang, C. Liu, et al. //2021 USENIX annual technical conference (USENIX ATC 21). 2021: 225-238.
Takeaway:这篇文章其实是针对Graph learning的,虽然和ANN一样都是图,但是差别还是挺大的。这里只描述一下他在图重构方面的思路,可能对ANN图的重构有帮助。GLIST进行图重构的动机是提高节点存储的局部性,降低读的次数。做法是重新编排节点的ID,相邻的节点有相邻的ID,这样的话读到一个点时他的邻居也大概率存在同一个闪存页中。
具体的重编排算法是,他设置了一个阈值T,将度数低于T的节点进行排序(文中说因为度数过高的点一个page也存不下。不过我对这种做法持怀疑态度,因为度数高的点反而应该有更高的局部性,并且取到该点的概率也更高,集中存放的收益并不低),取前C个顶点作为重要顶点,对重要顶点进行采样(也就是取他们的h跳邻居。为了降低开销,采样时随机取一小部分就可以了)。然后根据与其他顶点重叠的大小对重要顶点进行排序,以便在顶点序列中保留与顶点相关的潜在空间局部性。最后,为选定的重要顶点及其相应的 h 跳邻居按顺序分配新的 ID。

[18] Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment[J]. M. Wang, W. Xu, X. Yi, et al. Proc. ACM Manag. Data, 2024, 2(1).
Takeaway:面向的是内存、存储都受限的单机下的分段ANN检索。方法1是数据重布局提高局部性,以缩短搜索路径提高一次I/O中有效数据的比例;方法2是在内存中对一小批向量建图,以快速接近目标点;方法3是在读上来的块中找到最近的向量加入搜索中。这篇文章的方法其实没有很多特别之处,基本在之前被人提过了,例如和DiskANN++的点有挺多类似的(不过他们的作者列表有重合,不知道是否可以算作是DiskANN++的正式版?)。不过这篇文章进行了更细致的研究,例如提出了多种图重构算法、多种计算优化策略,并且对很多参数和问题进行了形式化的定义。
背景:
矢量数据库将大规模数据划分为多个段并将它们分布在服务器上。每个服务器可以管理多个段,通过查询协调器并行或串行处理向量查询。通常,每个段在严格的内存和磁盘空间限制内运行,通常拥有小于 2GB 的内存和小于 10GB 的磁盘容量。该文的目标是在这些空间限制内实现高搜索精度和效率。这就需要在 HVSS 的搜索性能和空间成本之间取得微妙的平衡。
至于为什么现有的基于磁盘的ANN不行,这方面的工作主要包括SPANN和DiskANN。SPANN 实现了较高的搜索精度和效率,但代价是大量的存储空间。它可能会将每个向量复制多达八次(这个推断的来源在SPANN的第4.2节),从而导致大量的磁盘开销,在管理数千万个向量时远远超过数据段的容量。另一方面,DiskANN遵循图索引算法,以更少的磁盘容量实现了优越的搜索性能。它已作为磁盘上 HVSS 的基线。然而,它的数据布局和搜索策略仍然与基于内存的解决方案的范式保持一致,每个顶点访问都需要磁盘 I/O。基于磁盘的图搜索当驻留在内存中时准确性和效率方面表现出色。然而,一旦放置在磁盘上,由于搜索路径长和数据局部性差,它们会产生大量 I/O。
问题:

本文通过一个实验例子展示了IO开销的问题,上图为BIGANN 上 DiskANN 的搜索时间成本,很明显 TI/O 占 Ttotal 的 92.5%,而 Tcomp 和 Tother 总共占不到 7.5%。这凸显了效率瓶颈,即磁盘驻留图索引上 HVSS 的磁盘 I/O 成本。因此,本文的目标是通过最小化 TI/O 来提高搜索效率。
本文认为基于磁盘的ANN的性能瓶颈在于两方面:顶点利用率和搜索路径的长度。前者表示在给定块中加载有用顶点的程度,而后者表示从入口点到结果点所需的跳数。这两个因素都会影响磁盘 I/O 的数量,从而决定 I/O 时间。顶点利用率越高(i.e. 局部性越强),意味着每次磁盘 I/O 中加载的相关信息越多,从而可以更有效地利用磁盘带宽,并且每次查询所需的磁盘 I/O 更少。根据对 BIGANN 的评估,从磁盘读取的数据高达94%被浪费(如图2a);较长的搜索路径意味着搜索过程中磁盘 I/O 的数量增加,如果入口点固定那么可能离目标点很远需要很多次IO(如图2b)。
方法:

Starling 架构如图2cd所示,Starling①保留了图的拓扑结构,同时优化了数据布局,以提高顶点利用率并减少搜索路径长度;②此外,它采用了旨在减少磁盘 I/O 的块搜索策略。
图布局:1)磁盘布局。Starling 通过根据图拓扑打乱数据块来提高数据局部性(图 2(c) 左)。Starling 努力将顶点及其邻居存储在同一块中,从而使单个磁盘读取不仅可以获取目标顶点,还可以获取其他可能的候选顶点。2)内存布局。 Starling 使用内存中导航图识别基于磁盘的图的查询感知入口点(图 2(c) 右)。这种方法结合了多层图的概念,并涉及从基于磁盘的图中采样一小部分向量来构建导航图。给定一个查询,Starling 首先探索内存中的导航图以获取查询关闭顶点作为入口点。随后从这些识别的点开始基于磁盘的图形搜索。这种方法有效地减少了基于磁盘的图上的搜索路径长度。
为了衡量局部性,本文提出了一个参数OR(G)。OR(G)定义的是整张图的局部性,是每个顶点的局部性OR(u)的平均,OR(u)定义如下。简单来说OR(u)就是顶点u所在的块中,u的邻居点的数量占这个块的总数B(u)的比例。B(u)是点u所在块的顶点,N(u)是u的邻居点。
![]()
搜索策略:Starling 使用块搜索策略来利用数据局部性(图 2(d))。与基于顶点探索数据的方法不同,该策略按块处理数据。这样,它就可以受益于优化的数据布局。对于每个加载到内存的块,Starling 计算所有顶点到查询的距离。然后,它选择接近查询的顶点并检查它们的邻居是否有新的搜索候选。该策略通过探索每个块更多相关数据来降低磁盘操作成本,但增加了计算成本。本文通过三个计算优化方法进一步优化性能。
搜索策略中有2个优化点,一个是pipeline,为了将距离计算和块读取并行化,Starling首先对当前加载块中的目标顶点 u 执行距离计算(算法2第 6-7 行)。然后,它立即进行下一个块读取,同时还对包含 u 的块中的其他顶点执行计算(感觉没有写得很清楚?个人感觉是和CXLANN类似,在更新候选列表之前就继续读下一个);另一个是向量压缩。为了减少IO数量,Starling也使用了PQ压缩的方式在内存中驻留PQ向量,用于进行下一跳决策,和DiskANN类似。
总结:
-
- 实际上这个工作大概就是DiskANN加上了数据重布局和一些检索策略上的优化。他们假设的是可用内存为数据集的20%,可能在真实场景下做不到。
- 我认为他们把背景套成数据分段的目的是为了引出内存和存储资源受限的这个场景,让问题更成立。不过我认为这个故事也不是特别合适?因为感觉向量分段和资源受限并没有什么很直接的关系。而且我认为向量分段的一个重要研究内容是向量和图的分割,以及多分段直接的并行查询?然而这个工作并没有提及
- 有些形式化的定义可以参考,例如局部性参数OR(u)。
- 实验比之前的工作更加详尽,例如测试了搜索路径长度、顶点利用率、IO开销占比等参数。
- Starling是开源的。地址:https://github.com/zilliztech/starling。
[19] Scalable Billion-point Approximate Nearest Neighbor Search Using SmartSSDs. Bing Tian, Haikun Liu, Zhuohui Duan, Xiaofei Liao, Hai Jin, and Yu Zhang. ATC'24.
Takeaway: 现有的ANN算法在检索十亿级别向量的时候需要TB级别的内存,成本过高->可以用NDP进行检索,但是现有的算法难以直接应用在NDP中->基于SmartSSD的层次化索引架构方案SmartANNS,以实现近似线性的性能扩展能力->首先,提出了host+CSD协同架构,辅以多层级索引,减少数据访问以及SmartSSD的计算量;其次提出了基于优化数据布局的动态任务调度,以实现多CSD间的负载均衡和数据重用;最后提出了一种基于学习的分片剪枝算法,以消除SmartSSD上不必要的计算。实验表明QPS提升了10.7x。
问题:
现有的基于存储的ANN工作中,IO开销占据70%以上。更糟糕的是,PCIe带宽不仅难以扩展,而且ANN通常不是孤立运行的而是和其他应用一起运行抢占PCIe带宽,ANN的性能因此受限。因此提出使用近存计算的方式,使得性能可以线性扩展。虽然现在已有基于SmartSSD的ANN检索工作(i.e.本文档的第2篇),然而他需要为每个查询扫描所有分片,并且由于CSD的算力弱无法达到最优的性能。因此,使用CSD计算ANN还存在以下挑战:
挑战:
- 多CSD间缺乏通信机制,导致每个CSD必须各自检索TopK,需要检索到更多的分片(shard),引起额外的计算开销。
- 负载均衡问题。不同分片之间的访问可能不均衡(这点持保留意见,ANN查询的随机性应该很强,并且查询的batch size上去之后应该挺平衡的),调度不当可能导致系统扩展性受限。本文后面举了个例子,可以看到SmartSSD2的负载最轻,1的负载最重。

- 需要访问的分片数量难以确定。
机会:
关于如何解决这些问题,本文发现了两个访存特征,可以从这些方面着手进行优化:

- 如图(a)所示,当提高batch size时,共享分片的比例逐渐提高。例如当batch size=15时,有80%的分片会被2个及以上的查询访问到,这意味着可以通过任务调度的方式来探索数据局部性,以实现内存上分片数据的重用。
- 如图(b)所示,图b将ShardID根据访问频率重排,可以观察到分片的访问频率差异很大(如果访问频率差不多的话应该是一条水平的线)。大约10%的分片热度很高,10%的分片热度很低。因此应该探索数据布局策略,将热度高的分片均匀存储在不同CSD上。
应对思路:
- 针对问题1,思路是使用host+CSD协同处理的架构。中心点存储在主存,每个分片的HNSW索引存在CSD中。
- 针对问题2,思路是通过任务调度+数据布局来负载均衡。首先在离线采样过程中确定每个分片的热度,然后将热分片均匀地放置在各个CSD中;然后在调度查询时,可以基于数据局部性和负载均衡的考量,在有重叠的分片中进行调度。
- 针对问题3,提出了基于学习的分片剪枝以降低计算量。在离线训练阶段构建查询到检索视野的映射,然后在在线检索阶段确定需要查询的最少分片。
方法:
与其他论文一样,SmartANNS依旧包含离线建图和在线检索两个步骤:
- 离线建图时,首先采用HBC算法将数据集尽量均衡地分配到各个分片中。然后在每个分片上构建HNSW图,并将分片的中心点存在主机内存、分片存在CSD。SmartANNS采样一部分查询向量用来训练一个梯度提升决策树(gradient boosting decision trees,GBDT),用来决定每个查询向量需要访问的分片数量。同时SmartANNS还会统计每个分片的访问热度以进行数据布局。
- 在线检索时,首先在主机内存中计算查询点到每个聚类中心的距离,然后基于这些距离,使用GBDT来决定查询分片数量。然后使用任务调度机制来分发查询到各个SmartANNS中。
具体到每个技术点:
- 分层索引(对应挑战1)。首先根据CSD的容量划定好分片大小,在聚类的过程中保持不超过分片大小,并且也和SPANN一样将边缘点划分到多个聚类中,划分策略也和SPANN很相似。划分好之后在分片上面构建HNSW图,图构建采用增量更新的方式(不太理解为什么要这样构建,因为动态增量更新的开销很大)。为了解决其他方法中,由于CSD间无法通信导致的额外检索问题(即挑战1),SmartANNS使用主机作为协调器,在主机内存中存储所有分片的质心。它使用KV存储来记录SmartSSD中每个分片的地址。当确定了与查询关联的分片数量时,主机CPU根据这些键值对从SmartSSD中检索对应的分片。然后根据任务调度机制将任务分配给SmartSSD。(这段没怎么看懂,为什么这样就能解决无法通信和冗余检索的问题?)
- 分片剪枝(对应挑战3)。为了降低主机的工作量,SmartANNS没有像其他基于IVF的工作那样划分大量的分片,避免主机会花费大量的时间用来确定要检索的分片(其实这里不是很懂,主机的算力强大很多,并且划分大量分片可以显著降低检索的IO量和计算量)。因此SmartANNS中的每个分片会包含大量的向量,需要仔细决定需要检索的分片数量避免无效的检索。因此SmartANNS采用了GBDT,一种类似随机森林的决策器,来决定每个查询所需的分片。GBDT分类器的输入参数如下图所示。其中Dk表示查询与top-k最近分片之间的距离,使用Dk与D1的比率作为关键特征来训练决策树。(我认为最有用的feature可能就是F1了)

- 3. 任务调度(对应挑战2)。设计了一个基于优化数据布局的任务调度器。当构建 GBDT 的训练数据时,对每个分片的热度进行采样记录。当将分片放入 SmartSSD 时,根据热度对分片进行排序。通过迭代地将热度最高的分片放置到热度总和最低的SmartSSD中实现热度均衡。此外,SmartANNS还会将分片冗余放置在多个CSD中,如下图所示,为负载平衡提供了更大的灵活性。

- 在任务调度SmartANNS还提出了一种任务调度算法,该算法的目的是平衡每个CSD的工作量。调度算法会根据加载和计算分片的开销来估计每个CSD的计算时间,并且会考虑到局部性(即多个查询访问同一分片只计算一次加载开销)。调度算法也比较好理解,我理解的就是1个原则,插入每个任务的时候,总是插入到当前负载最低的CSD中。(我有个疑惑是这种算法能保证全局最优吗?是否还存在全局更优的方案?)
- 4. 这篇文章还简单介绍了所用硬件加速器的架构,包括层监视器、距离计算模块、排序模块和数组更新模块。为了提高FPGA的效率,对搜索内核进行了多项优化:①当内核遍历候选向量时,它并行读取所有邻居,并配置单独的接口来并行加载向量数据和相应的链表;②为了节省片上内存空间用bitmap代替原来HNSW算法使用的布尔数组来实现访问列表;③实现了硬件高效的双调排序算法更新候选列表和最终列表;④在距离计算模块中利用HLS的循环展开和流水线优化;⑤由于每个分片都可以独立处理在板载 DRAM 中建立数据池,在 FPGA 中建立内核池,以提高任务并行性。一旦分片被加载到数据池中,内核池中的内核就可以并行处理与该分片相关的任务。此外,当内核搜索另一个分片时,SmartSSD 可以将一个分片加载到数据池中。这种池化机制可以有效地重叠分片加载和向量搜索,从而隐藏数据访问的延迟。
思考:
- 这篇文章主要场景是分布式CSD的ANN检索,对于CSD单盘下的优化不多。本文的工作最大的创新点就在于使用了学习的方法来决定访问的聚类数量,这种方法的开销以及和SPANN的剪枝策略相比究竟有多大提升可能还需要进一步的检验。
- 对于不同聚类访问热度不均衡这一点持保留态度,在我的理解中不同聚类的访存热度应该类似因为建图和检索一般是完全随机的,文中只给了现象也没有给出解释。如果真的有访存热度的差异,那主机内存只是用来存聚类中心就有点浪费了,可以缓存部分热度高的节点。
[20] VStore: In-Storage Graph Based Vector Search Accelerator[C]. S. Liang, Y. Wang, Z. Yuan, et al. //Proceedings of the 59th ACM/IEEE Design Automation Conference. New York, NY, USA: Association for Computing Machinery, 2022: 997-1002.
相关解读:可计算存储结构加速大规模数据检索
Takeaway: VStore是一种基于图的存内向量检索加速器。首先,VStore通过优化数据路径和计算逻辑定制了基于图的矢量搜索加速器,以提供低延迟和高精度;然后提出了查询编排和结果重用优化,以利用查询之间的数据可重用性,消除向量访问和计算开销;其次由于之前的系统优化忽略了数据移动问题,VStore重新架构了矢量搜索加速器,在节省存储设备预算的情况下将加速器放入SSD设备中。通过这种方式,VStore消除了存储和计算节点之间的所有向量传输。
问题:
Motivation可以由下面两图来说明。IVS=initial vertices selection即入口点选择,GR=graph routing即图路由。DC=distance computing,VI=vertex insert,CF=control flow。实验设置中好像没有提及这是基于DRAM的还是基于Flash的。
从下面的图中可以得出如下结论:
- 图3(a)中可以看出,图路由占据的绝大多数时间(>90%)。进一步分解这两个阶段,可以看出距离计算在里面占据了绝大多数时间(80%-90%)。因此需要优化距离计算和数据流(图3(b)中的CF)提高搜索性能。
- 图4(a)展示了两个查询向量之间的距离与路径重复度之间的关系。可以看出当向量距离很近时重复度可以高达70%。因此可以利用前置查询的结果作为导航顶点,甚至作为没有遍历的最终结果,以进一步提高系统性能。(这一点感觉挺妙的,但是感觉实际查询可能很少有距离这么近的向量?)
- 图4(b)展示了能耗的开销比例。大约75%的总能源成本是由数据在NAND闪存芯片和I/O接口上的移动产生的。

方案:
VStore的目的是减少内存占用和数据移动开销,是一种基于 NDP的图向量搜索解决方案。图 5 显示了 VStore 的架构。VStore 内置于 SSD 控制器中,并利用了可用的全部 SSD 内部带宽。它包括四个主要模块:查询编排、向量搜索、地址生成器和请求重排序。

- 查询编排:负责根据语义距离重新组织传入查询的执行顺序,旨在尽可能多地重用以缓存的向量。它首先捕获定义的时间窗口内的所有传入查询,然后选择与加速器中正在执行的查询相似的查询。之后通过评估所选查询与其余传入查询之间的距离来确定它们之间的相似度。如果距离小于定义的阈值 T ,则认为查询是相似的。然后将这些查询分组在一起并顺序发送给矢量搜索引擎,以实现更好的搜索效率和带宽利用率。
- 向量搜索:通过抽象两个阶段的公共执行模式来同时支持初始顶点选择和图路由阶段。这个硬件加速器的部分不是我关注的重点就不多介绍了我也介绍不明白,有需要的可以参考原文。他的优化点主要包含:①为了降低使用Bitmap作为visited list带来的巨额开销,使用布隆过滤器进行大规模数据下的过滤,代价是精度损失;②为了解决距离计算和下一顶点读取之间的依赖关系导致的阻塞,当他计算到某个邻居点的距离小于了Candidate List中最靠前的未访问点时,直接开始读取该点;③结果重用:提出了以相似缓存查询的搜索结果作为导航顶点进行图遍历的结果重用方法(与图4(a)中的结论对应)。为了避免局部最优也会将默认入口点加入其中(怀疑这个操作的意义)。
- 地址生成器:是向量搜索引擎和NAND闪存芯片之间的桥梁。当NAND闪存读取时,请求以页粒度而不是字节粒度执行,地址生成器旨在识别向量数据和邻居列表的物理闪存页地址。当向量搜索引擎请求的向量数据或邻居列表在DRAM中丢失时,地址生成器利用顶点id来计算相应的物理页地址。在调用地址生成器之前,使用地址缓冲器来检测所请求的顶点是否存在于DRAM中。这种机制起作用的原因是VStore使用固定度数图来避免额外的查找开销,并且对于指定数据集向量的维度也是固定的。最后,向请求重排序引擎发出NAND闪存访问请求。

- 4. 请求重排序:如图6邮编所示。请求重排序引擎分配了两个主要任务:(1)合并请求。将访问同一个闪存页面的请求合并; (2)分发请求。为了利用通道级并行性,请求重新排序不是按照接收顺序发出 NAND 闪存读取操作,而是利用哈希函数来识别其目标闪存通道,然后将请求分派到对应通道的先进先出队列。多通道FIFO队列并发发出NAND闪存读操作,从而提高VStore的通道级并行性。(这好像就是SSD里面常见的请求分发机制?)
疑惑:
- 可能是受限于篇幅,很多东西都没有讲清楚。例如Motivation实验中的实验设置、图3中的CF是什么、以及图4中Distance的单位以及重用率的定义。
[21] "NDSEARCH: Accelerating Graph-Traversal-Based Approximate Nearest Neighbor Search through Near Data Processing." Wang, Yitu, et al. 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024.
问题:
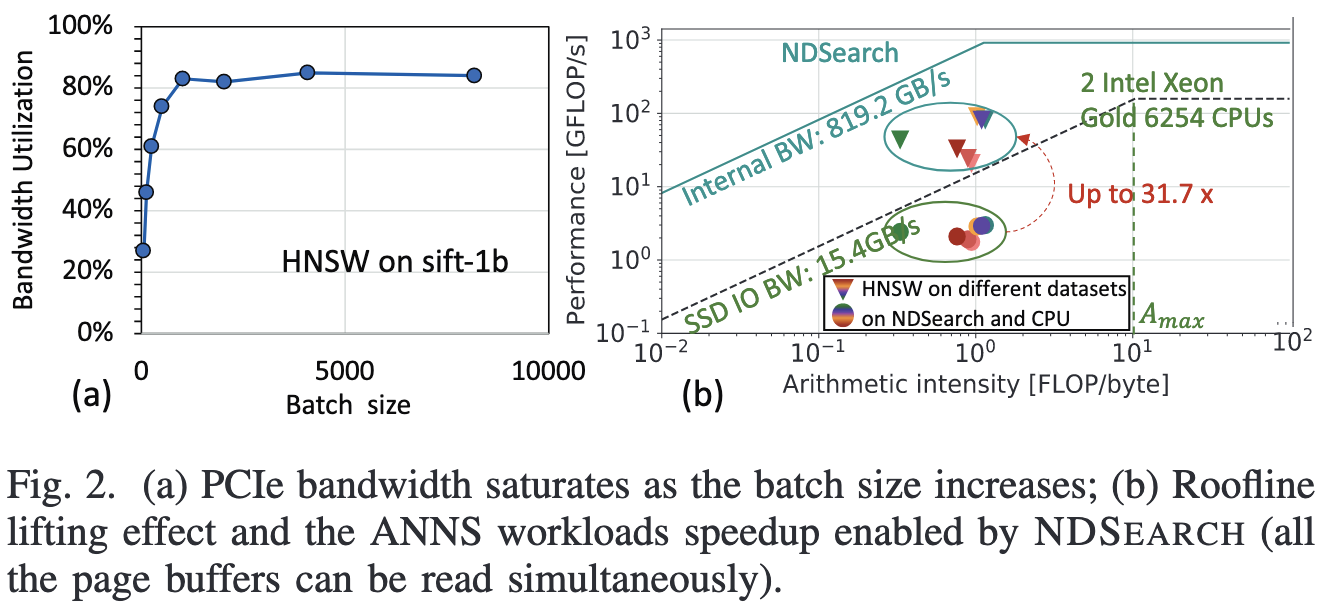
现有的ANN检索方法对内存的需求很高。为了满足需求,现有工作主要有3种方法:1)数据分片,分片读到内存后分别检索后合并;2)设计面向SSD的索引结构并在检索时按需读到内存中;3)氪金,将数据集读到大内存的机器或者GPU上。然而这些方法的性能都被SSD的性能限制,如图1所示,SSD读取开销占比最高可到75%。同时通过与图2a结合来看,可以看到SSD的读开销来自于受限的存储带宽(这点有疑惑,感觉说服力不强,SSD的带宽利用率没有100%感觉不能说明PCIe带宽是瓶颈)。因此提出了使用NDP的方式检索。

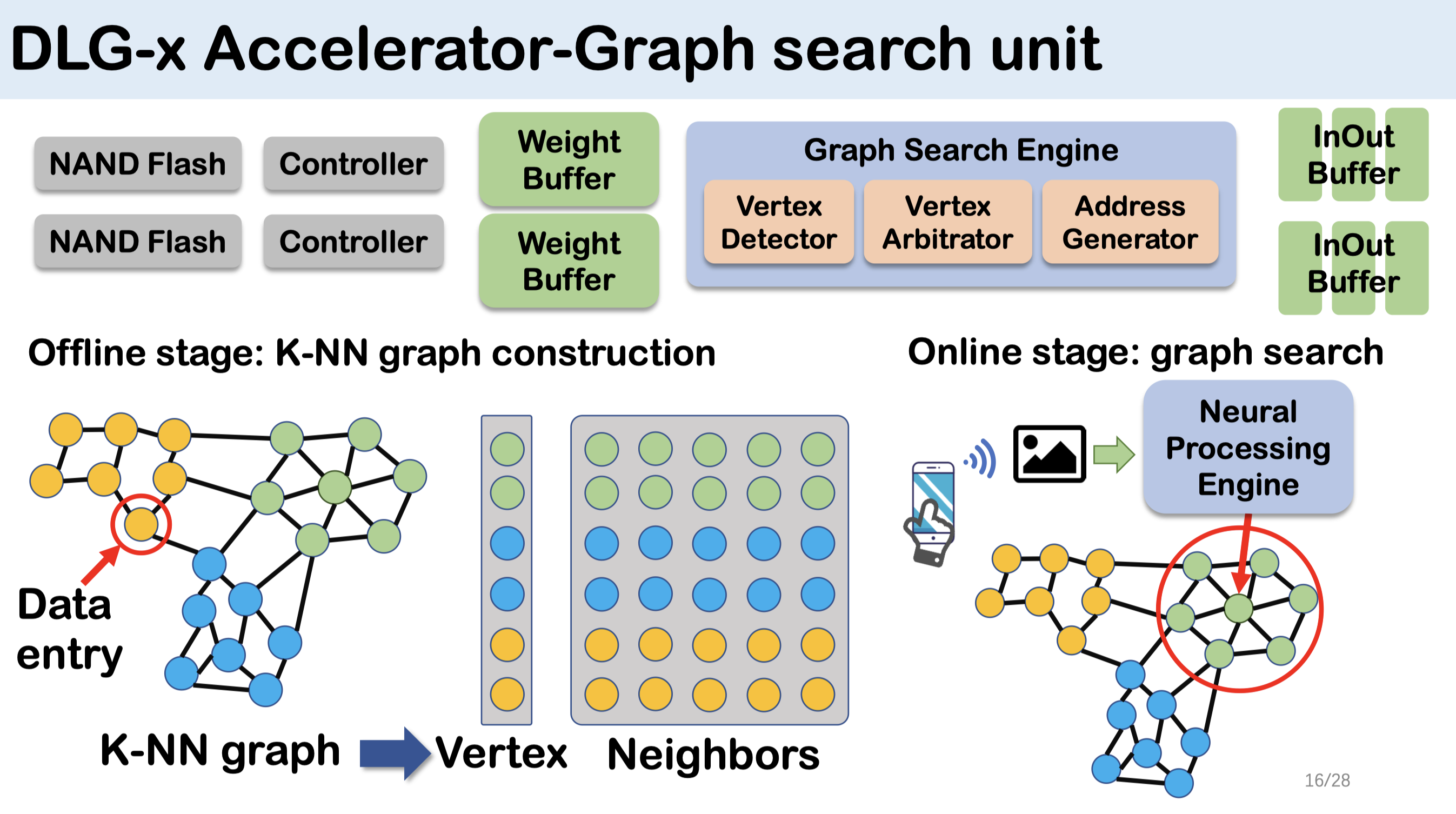
Motivation:
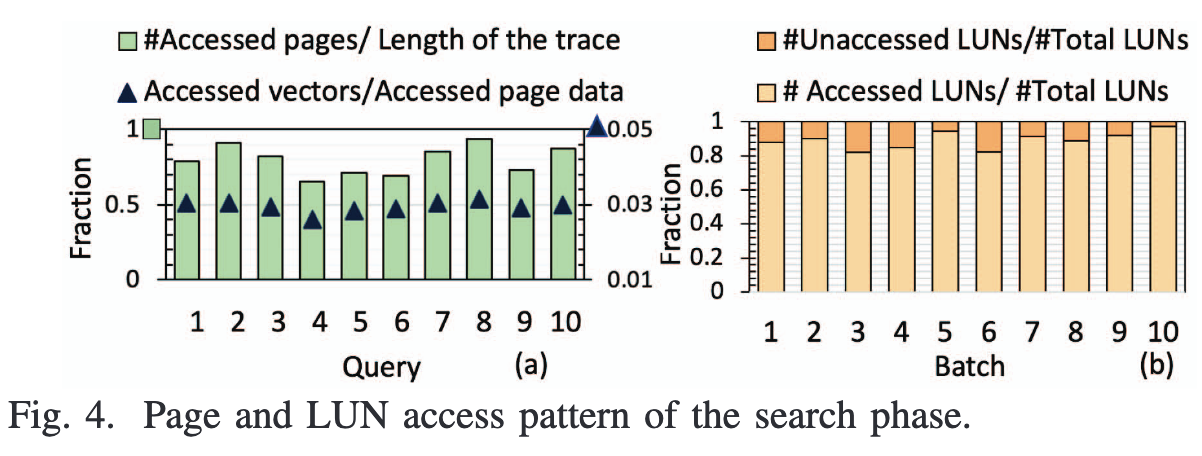
动机主要是下面两个图来体现。图4a说明了图访问的随机性很强,局部性很弱,因此需要进行图重排序以增强局部性;图4b展示了每批(2048个)查询会访问到的LUN比例,可以看到会被访问到的LUN比例相当高,说明访问模式非常分散,因此该文采用在LUN上加计算单元的方式充分提升性能,避免了将数据移出闪存芯片的开销。
设计:
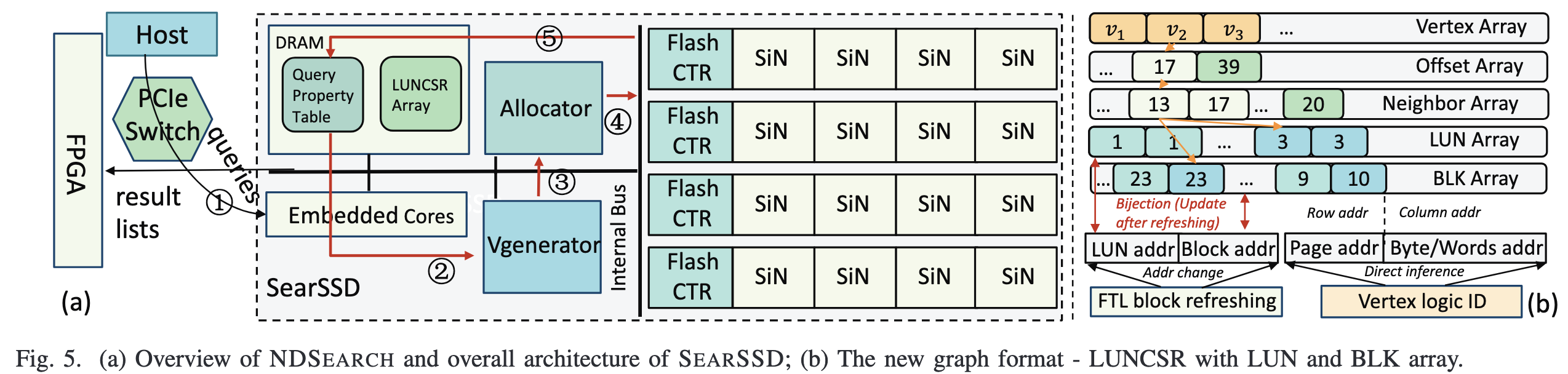
- 针对图结构的随机性在存储器的大粒度IO特性上导致的读放大率问题,提出了一种新的图存储结构LUNCSR,如图5b所示。这个图的结构我没有很理解,首先是他如何做到不读无用数据的?因为这些array都存在内存中的吗。但是如果能存在内存中,那就不需要这种结构了呀,传统的填0对齐的方法中直接根据ID加偏移量的方式就能算出物理位置,根本不需要索引。文中给出的理由是填0的方式会浪费空间,但是浪费一点存储空间获得了索引性能和开销的巨大提升我认为很值得,而且浪费的空间大小还有待商榷。
- 为了提高图存储的密集度,该文设计了一个评估函数用来表示相邻两个点的平均距离。如下图所示。更低的β代表了相邻两个点的物理距离更近(但是并不能保证他们存储在同一个块上,我觉得DiskANN++里面的评估函数更合理一些)。映射到页面时,采用plane优先的分布策略,即写入一个plane中的某个page后,紧接着的下一个page写入下一个plane中。为了避免数据刷新的影响,新页面的分配限制在同一个plane中。
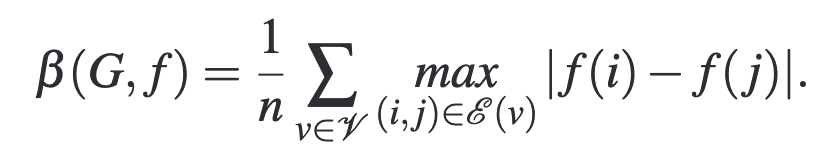
- 本文观察到,当前迭代中入口顶点的二阶邻居是下一次搜索迭代中访问的潜在候选项。因此提出了推测性搜索机制。提前获取每个入口点的二阶领居,同时为了降低二阶邻居的数量只选取与一阶领居有更多连接的领居。当搜索阶段完成进入聚合阶段时,提前开始推测搜索以实现延迟的overlap。(不过我觉得当请求足够多的时候,存储会被充分利用,带宽本就很紧张。这时候还发起这些可能无用的请求会浪费带宽)
实验:
- 实验配置:实验通过模拟器进行,SSD部分通过SSDSim实现。然后在DiskANN和HNSW上采集到了内存trace然后喂给模拟器运行获取结果。还有一部分和硬件、电路相关的模拟。不过我没搞懂,SSD既然是用SSDSim模拟实现的,为什么还能和FPGA相连接?

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)