基于土壤数据与机器学习算法的农作物推荐算法代码实现
近年来,机器学习方法在农业领域的应用取得巨大成功,广泛应用于科 学施肥、产量预测和经济效益预估等领域。根据土壤信息进行数据挖掘,并在此基础上提出区域性作物的种植建议,不仅可以促进农作物生长从而带来经济效益,还可以改善土壤肥力,促进可持续发展。本文根据土土 壤养分元素[如:氮(N)、磷(P)、钾(K)等]的含量建立模型分析并且给出精准预测,可以实现了几种机器学习分类算法形成科学的种植方案,最终还实现
1.摘要
近年来,机器学习方法在农业领域的应用取得巨大成功,广泛应用于科 学施肥、产量预测和经济效益预估等领域。根据土壤信息进行数据挖掘,并在此基础上提出区域性作物的种植建议,不仅可以促进农作物生长从而带来经济效益,还可以改善土壤肥力,促进可持续发展。本文根据土土 壤养分元素[如:氮(N)、磷(P)、钾(K)等]的含量建立模型分析并且给出精准预测,可以实现了几种机器学习分类算法形成科学的种植方案,最终还实现了应用界面的实现。
2.数据介绍
该数据共有2200条土壤数据,其中每条数据包括土壤中液态氮、速效磷、速效钾、温度、湿度、ph、降雨和作物种类。作物种类包含中国中部以及东部常见耕地作物 8 种:小麦、水稻、玉米、糜子、黄豆等8种。数据显示如下:

数据读取代码实现如下:
features = df[['N', 'P','K','temperature', 'humidity', 'ph', 'rainfall']]
target = df['label']
labels = df['label']3.模型实现
决策树模型:
DecisionTree = DecisionTreeClassifier(criterion="entropy",random_state=2,max_depth=5)
DecisionTree.fit(Xtrain,Ytrain)
predicted_values = DecisionTree.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('Decision Tree')
print("DecisionTrees's Accuracy is: ", x*100)测试结果输出的混淆矩阵如下:

朴素贝叶斯模型:
from sklearn.naive_bayes import GaussianNB
NaiveBayes = GaussianNB()
NaiveBayes.fit(Xtrain,Ytrain)
predicted_values = NaiveBayes.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('Naive Bayes')
print("Naive Bayes's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))支持向量机模型:
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
norm = MinMaxScaler().fit(Xtrain)
X_train_norm = norm.transform(Xtrain)
X_test_norm = norm.transform(Xtest)
SVM = SVC(kernel='poly', degree=3, C=1)
SVM.fit(X_train_norm,Ytrain)
predicted_values = SVM.predict(X_test_norm)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('SVM')
print("SVM's Accuracy is: ", x)逻辑回归模型:
from sklearn.linear_model import LogisticRegression
LogReg = LogisticRegression(random_state=2)
LogReg.fit(Xtrain,Ytrain)
predicted_values = LogReg.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('Logistic Regression')
print("Logistic Regression's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))随机森林模型:
from sklearn.ensemble import RandomForestClassifier
RF = RandomForestClassifier(n_estimators=20, random_state=0)
RF.fit(Xtrain,Ytrain)
predicted_values = RF.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('RF')
print("RF's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))XGBoost模型:
import xgboost as xgb
XB = xgb.XGBClassifier()
XB.fit(Xtrain,Ytrain)
predicted_values = XB.predict(Xtest)
x = metrics.accuracy_score(Ytest, predicted_values)
acc.append(x)
model.append('XGBoost')
print("XGBoost's Accuracy is: ", x)
print(classification_report(Ytest,predicted_values))上述机器学习的代码类似,以上述XGBoost模型为例,我们对代码逻辑进行了解释:
首先,代码导入了名为xgboost的Python模块,并将其简写为xgb。然后,通过实例化xgb.XGBClassifier()创建了一个XGBoost分类器对象,并将其分配给变量XB。
接下来,使用XB.fit()方法对训练数据Xtrain和Ytrain进行拟合(即训练)。
然后,使用XB.predict()方法对测试数据Xtest进行预测,并将预测结果存储在变量predicted_values中。
最后,使用sklearn.metrics模块中的metrics.accuracy_score()函数计算了模型在测试集上的准确度,其中Ytest是真实标签,predicted_values是模型预测的标签,结果存储在变量x中。
综上所述,这段代码的作用是使用XGBoost分类器对给定的训练集和测试集进行拟合和预测,并计算模型在测试集上的准确度。
为了方便比较,我们绘制出了上述几种机器学习模型进行农作物预测的准确率对比图:

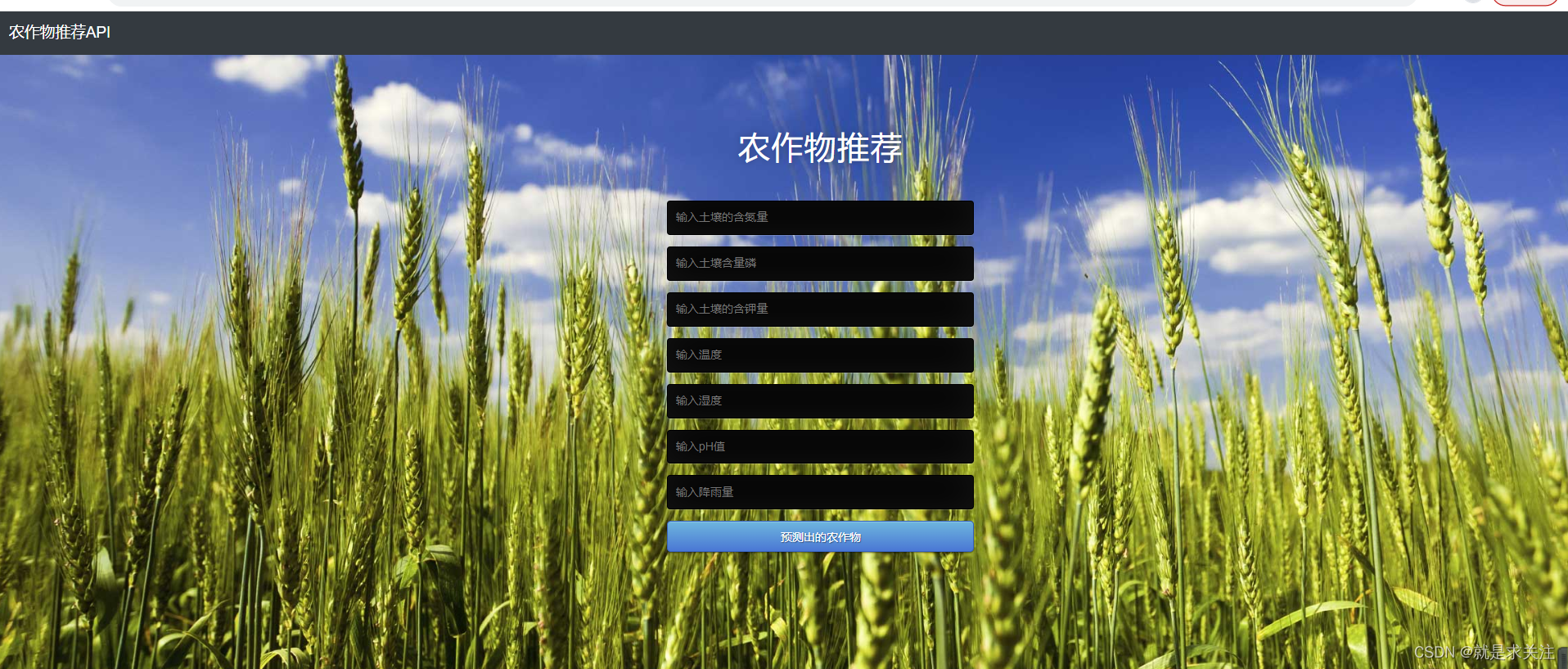
4.应用实现
Flask是一个基于Python编写的Web框架,它可以用来开发Web应用程序。同时,由于Python拥有强大的机器学习和数据处理库,因此Flask框架也可以用来开发基于机器学习算法的Web应用程序。实现界面如下:


5.总结
本文主要实现了简单的机器学习模型,下一步,对土壤数据进行增强,获得更为均衡的土壤数据作为模型的输入;改进多分类的激活函数,使二分类推荐模型能应用于土壤作物推荐领域。
代码下载链接:

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)