布尔表达式可满足性问题(SAT)与库克-列文定理(上)
布尔表达式可满足性问题是指对于一个布尔表达式(或者说命题公式),是否存在一组真值,使得该表达式的赋值为真。例如,A:¬p∨qA:\neg p\lor qA:¬p∨q(即“(非ppp)或qqq”)是可满足的,因为p=1,q=0p=1,q=0p=1,q=0时AAA为真;但B:p∧¬pB:p\land\neg pB:p∧¬p不是可满足的,因为“ppp”和“非ppp”显然不可能同时成立。事实上,这个问题解
下篇:布尔表达式可满足性问题(SAT)与库克-列文定理(下)。
下篇介绍库克-列文定理。
一、布尔表达式可满足性问题(Boolean Satisfiability Problem, SAT)
布尔表达式可满足性问题是指对于一个布尔表达式(或者说命题公式),是否存在一组真值,使得该表达式的赋值为真。
如果你没有学过数理逻辑,这是一些对基本概念的介绍:
命题:是指能判断真假的陈述句,常用 p , q , r , ⋯ p,q,r,\cdots p,q,r,⋯表示。例如“明天会下雨”是命题,“你给我把快递拿一下吧”不是命题。
命题的真值:命题所表示的判断结果,只能是真(T/ 1 1 1)或假(F/ 0 0 0)。例如命题“ 1 + 1 = 2 1+1=2 1+1=2”的真值为真,“方程 3 x + 4 x = 5 x 3^x+4^x=5^x 3x+4x=5x无整数解”的真值为假(显然 x = 2 x=2 x=2为方程的解)。
否定连接词 ¬ \neg ¬:相当于“无”“非”“没有”等。对于命题 p p p, ¬ p \neg p ¬p与 p p p的真值相反。如 p : 1 + 1 = 3 p:1+1=3 p:1+1=3为假, ¬ p : 1 + 1 ≠ 3 \neg p:1+1\ne3 ¬p:1+1=3为真。
合取连接词 ∧ \land ∧:相当于“且”“也”等。对于命题 p p p和 q q q, p ∧ q p\land q p∧q为真当且仅当 p p p和 q q q同时为真。
析取连接词 ∨ \lor ∨:相当于“或”。对于命题 p p p和 q q q, p ∨ q p\lor q p∨q为真当且仅当 p p p、 q q q至少有一个为真。
除此之外还有蕴含连接词 → \to →、等价连接词 ↔ \leftrightarrow ↔,但它们都可化为前三种连接词。
命题常项:简单命题的真值是确定的,因而又称为命题常项。例如 p : 1 + 1 = 2 p:1+1=2 p:1+1=2。
命题变项:例如“ q : x + y > 5 q:x+y>5 q:x+y>5”, q q q本身不是命题,但当 x , y x,y x,y给定之后就变成了命题,这种真值可以变化的简单陈述句称为命题变项。
命题公式:命题常项或命题变项由连接词连接而成的复合命题称为命题公式。例如 ¬ p ∧ ( q ∨ ¬ r ) \neg p\land(q\lor\neg r) ¬p∧(q∨¬r)就是将命题变项 p , q , r p,q,r p,q,r由 ¬ , ∧ , ∨ \neg,\land,\lor ¬,∧,∨连接而成的命题公式。在SAT问题中,命题公式是指仅由命题变项、否定连接词 ¬ \neg ¬、合取连接词 ∧ \land ∧、析取连接词 ∨ \lor ∨、括号 ( ) () ()连接而成的表达式。
赋值:设 A A A为一命题公式, p 1 , p 2 , ⋯ , p n p_1,p_2,\cdots,p_n p1,p2,⋯,pn是其中出现的所有命题变项,给 p 1 , p 2 , ⋯ , p n p_1,p_2,\cdots,p_n p1,p2,⋯,pn指定一组真值,则 A A A的真值唯一确定,称这一组真值为对 A A A的一个赋值或解释;若该赋值使 A A A为真,则称为成真赋值,否则称为成假赋值。例如对于 A : ( p ∨ ¬ q ) ∧ r A:(p\lor\neg q)\land r A:(p∨¬q)∧r,当 p = 1 , q = 0 , r = 1 p=1,q=0,r=1 p=1,q=0,r=1时 A A A为真,故 101 101 101为成真赋值;当 p = 0 , q = 1 , r = 1 p=0,q=1,r=1 p=0,q=1,r=1时 A A A为假,故 011 011 011为成假赋值。
命题公式分为:
- 重言式/永真式:命题公式 A A A在所有赋值下都是真的,例如 A : 1 A:1 A:1、 A : p ∨ ¬ p A:p\lor\neg p A:p∨¬p。
- 矛盾式/永假式: A A A在所有赋值下都是假的,例如 A : 0 A:0 A:0、 A : p ∧ ¬ p A:p\land\neg p A:p∧¬p。
- 可满足式:若 A A A至少存在一组成真赋值(包含重言式)。例如 A : p ∧ ¬ q A:p\land\neg q A:p∧¬q,当 p = 1 , q = 0 p=1,q=0 p=1,q=0时 A A A为真,故 A A A是可满足式。
因此SAT问题就是判断给定的命题公式是不是可满足式。
例如, A : ¬ p ∨ q A:\neg p\lor q A:¬p∨q(即“(非 p p p)或 q q q”)是可满足的,因为 p = 1 , q = 0 p=1,q=0 p=1,q=0时 A A A为真;但 B : p ∧ ¬ p B:p\land\neg p B:p∧¬p不是可满足的,因为“ p p p”和“非 p p p”显然不可能同时成立。
事实上,这个问题解决起来是极为困难的。诸如 p ∧ ¬ p p\land\neg p p∧¬p之类的式子固然容易判断,但有一些更复杂的,例如 ¬ ( ¬ p ∨ q ) ∧ ¬ ( ¬ ( ¬ q ∧ r ) ∨ ( p ∨ r ) ) \neg(\neg p\lor q)\land\neg(\neg(\neg q\land r)\lor(p\lor r)) ¬(¬p∨q)∧¬(¬(¬q∧r)∨(p∨r)),它事实上是矛盾式,然而我们并不容易看出来。因此,计算机是否能够有效地解决这个问题,就是我们要研究的。
二、形式语言与自动机
1.形式语言
字母表:非空的有穷集合,一般记作
Σ
\Sigma
Σ。
字符串:由
Σ
\Sigma
Σ的符号组成的有穷序列称为字母表
Σ
\Sigma
Σ上的字符串。例如字母表
Σ
=
{
a
,
b
,
c
,
d
}
\Sigma=\{a,b,c,d\}
Σ={a,b,c,d}上的字符串有
a
a
a、
a
a
aa
aa、
b
a
c
d
bacd
bacd、
a
c
a
a
d
d
c
b
b
d
c
acaaddcbbdc
acaaddcbbdc等。
注意:这里 a a a并不等同于字符
'a', a a a是一个数学上的抽象符号,它可以取任一字符,如 a = a= a='0',此时字符串 a a a = aaa= aaa="000"。
字符串的长度:字符串
ω
\omega
ω所含符号的个数称为
ω
\omega
ω的长度,记作
∣
ω
∣
|\omega|
∣ω∣。例如
∣
a
b
a
∣
=
3
|aba|=3
∣aba∣=3,
∣
a
c
b
d
d
c
b
a
∣
=
8
|acbddcba|=8
∣acbddcba∣=8。
空串:长度为
0
0
0的字符串,记作
ε
\varepsilon
ε。
设
a
∈
Σ
a\in\Sigma
a∈Σ,把
n
n
n个
a
a
a组成的字符串
a
a
⋯
a
aa\cdots a
aa⋯a记作
a
n
a^n
an,
n
∈
N
n\in\mathbb N
n∈N。特别地,
a
0
=
ε
a^0=\varepsilon
a0=ε。
Σ
\Sigma
Σ上字符串的全体记作
Σ
∗
\Sigma^*
Σ∗。若
ω
\omega
ω是
Σ
\Sigma
Σ上的字符串,则
ω
∈
Σ
∗
\omega\in\Sigma^*
ω∈Σ∗。
语言:
Σ
∗
\Sigma^*
Σ∗的任意子集称作字符串
Σ
\Sigma
Σ上的形式语言,简称语言。例如,
A
=
{
a
,
b
}
A=\{a,b\}
A={a,b},
B
=
{
a
n
∣
n
∈
N
}
=
{
a
,
a
a
,
a
a
a
,
⋯
}
B=\{a^n|n\in\mathbb N\}=\{a,aa,aaa,\cdots\}
B={an∣n∈N}={a,aa,aaa,⋯}就是
A
A
A上的形式语言,
C
=
{
a
n
b
m
∣
n
,
m
≥
1
}
=
{
a
b
,
a
a
b
,
a
b
b
,
a
a
a
b
,
a
a
b
b
,
a
b
b
b
,
⋯
}
C=\{a^nb^m|n,m\ge1\}=\{ab,aab,abb,aaab,aabb,abbb,\cdots\}
C={anbm∣n,m≥1}={ab,aab,abb,aaab,aabb,abbb,⋯}也是
A
A
A上的形式语言。
对于任何字母表
Σ
\Sigma
Σ,
∅
\emptyset
∅、
{
ε
}
\{\varepsilon\}
{ε}、
Σ
∗
\Sigma^*
Σ∗都是
Σ
\Sigma
Σ上的语言。
2.自动机
2.1 有穷自动机
有穷自动机(Finite Automaton, FA):是一有序五元组
M
=
(
Q
,
Σ
,
δ
,
q
0
,
F
)
M=(Q,\Sigma,\delta,q_0,F)
M=(Q,Σ,δ,q0,F),其中
(1)
Q
Q
Q是非空有穷的状态集合;
(2)
Σ
\Sigma
Σ是非空有穷的输入字母表;
(3)
δ
:
Q
×
Σ
→
Q
\delta:Q\times\Sigma\to Q
δ:Q×Σ→Q是状态转移函数;
(4)
q
0
∈
Q
q_0\in Q
q0∈Q是初始状态;
(5)
F
⊆
Q
F\subseteq Q
F⊆Q是终结状态集合。
有穷自动机可用状态转移图表示。状态转移图是一个有向图,每个顶点代表一个状态。初始状态( q 0 q_0 q0)用一个指向该顶点的箭头标明,终结状态用双圈标明。如果 δ ( q , a ) = q ′ \delta(q,a)=q' δ(q,a)=q′,则从 q q q到 q ′ q' q′有一条边,并在这条边旁标上符号 a a a。
例 下面给出一个自动机
M
1
M_1
M1,它能够判断一个输入的二进制串中含有奇数个
1
1
1还是偶数个
1
1
1。状态集合
Q
=
{
E
,
O
}
Q=\{E,O\}
Q={E,O}(
E
E
E=Even,
O
O
O=Odd),字母表
Σ
=
{
0
,
1
}
\Sigma=\{0,1\}
Σ={0,1},初始状态
q
0
=
E
q_0=E
q0=E,终结状态集合
F
=
{
E
}
F=\{E\}
F={E}。注意
E
E
E既是开始状态也是唯一的终结状态,因此下面的状态转移图中有一个指向它的箭头,而且用双圈标明。
状态转移函数
δ
\delta
δ满足:
δ
(
E
,
0
)
=
E
,
δ
(
E
,
1
)
=
O
,
δ
(
O
,
0
)
=
O
,
δ
(
O
,
1
)
=
E
\delta(E,0)=E,\delta(E,1)=O,\delta(O,0)=O,\delta(O,1)=E
δ(E,0)=E,δ(E,1)=O,δ(O,0)=O,δ(O,1)=E。可以看出,对于输入的每个字符
a
a
a,若
a
=
1
a=1
a=1,则
M
1
M_1
M1的状态在奇数(
O
O
O)和偶数(
E
E
E)之间来回转换;若
a
=
0
a=0
a=0,则该字符不影响结果,保持当前状态不变,因此
E
,
O
E,O
E,O标有
0
0
0的边都指向自己。

当
M
1
M_1
M1接受字符串
01011
01011
01011时,先置当前状态为
E
E
E,然后进行运算:
(1) 对于
0
0
0,由于
δ
(
E
,
0
)
=
E
\delta(E,0)=E
δ(E,0)=E,状态保持
E
E
E不变;
(2) 对于
1
1
1,由于
δ
(
E
,
1
)
=
O
\delta(E,1)=O
δ(E,1)=O,状态转为
O
O
O;
(3) 对于
0
0
0,由于
δ
(
O
,
0
)
=
O
\delta(O,0)=O
δ(O,0)=O,状态保持
O
O
O不变;
(4) 对于
1
1
1,由于
δ
(
O
,
1
)
=
E
\delta(O,1)=E
δ(O,1)=E,状态转为
E
E
E;
(5) 对于
1
1
1,由于
δ
(
E
,
1
)
=
O
\delta(E,1)=O
δ(E,1)=O,状态转为
O
O
O。
可以这么描述FA的执行过程:开始时,自动机处于状态 q 0 q_0 q0,然后读入输入字符串 ω \omega ω:每往后读一个符号 a a a(只能往后读,不能往前读),就根据状态转移函数 δ \delta δ将它的状态从 q q q转为 δ ( q , a ) \delta(q,a) δ(q,a),如此一步一步完成,直到读完 ω \omega ω为止。
推广的状态转移函数:定义函数 δ ^ : Q × Σ ∗ → Q \hat\delta:Q\times\Sigma^*\to Q δ^:Q×Σ∗→Q,使得 δ ^ ( q , ω ) \hat\delta(q,\omega) δ^(q,ω)表示自动机从状态 q q q开始读完 ω \omega ω后所处的状态。形式化地讲, ∀ q ∈ Q , x ∈ Σ ∗ , a ∈ Σ \forall q\in Q,x\in\Sigma^*,a\in\Sigma ∀q∈Q,x∈Σ∗,a∈Σ有 δ ^ ( q , ε ) = q \hat\delta(q,\varepsilon)=q δ^(q,ε)=q δ ^ ( q , x a ) = δ ( δ ^ ( q , x ) , a ) \hat\delta(q,xa)=\delta(\hat\delta(q,x),a) δ^(q,xa)=δ(δ^(q,x),a)对于例子中给出的 M 1 M_1 M1,有 δ ^ ( E , 01011 ) = O \hat\delta(E,01011)=O δ^(E,01011)=O, δ ^ ( E , 01100 ) = E , δ ^ ( O , 01110 ) = E , δ ^ ( O , 01001 ) = O \hat\delta(E,01100)=E,\hat\delta(O,01110)=E,\hat\delta(O,01001)=O δ^(E,01100)=E,δ^(O,01110)=E,δ^(O,01001)=O。
接受的语言:设有FA
M
=
(
Q
,
Σ
,
δ
,
q
0
,
F
)
M=(Q,\Sigma,\delta,q_0,F)
M=(Q,Σ,δ,q0,F),
ω
∈
Σ
∗
\omega\in\Sigma^*
ω∈Σ∗。若
δ
^
(
q
0
,
ω
)
∈
F
\hat\delta(q_0,\omega)\in F
δ^(q0,ω)∈F,则称
M
M
M接受字符串
ω
\omega
ω。
M
M
M接受的字符串的全体称作
M
M
M接受的语言,记作
L
(
M
)
L(M)
L(M),即
L
(
M
)
=
{
ω
∈
Σ
∗
∣
δ
^
(
q
0
,
ω
)
∈
F
}
L(M)=\{\omega\in\Sigma^*|\hat\delta(q_0,\omega)\in F\}
L(M)={ω∈Σ∗∣δ^(q0,ω)∈F}。
可以看出,所谓
M
M
M接受字符串
ω
\omega
ω,是指
M
M
M从初始状态读完
ω
\omega
ω后处于某一个终结状态。对于例子中的
M
1
M_1
M1,其接受的语言是所有含有偶数个
1
1
1的字符串。这是因为只有读完含有偶数个
1
1
1的字符串(例如
00101
00101
00101)后,
M
1
M_1
M1的状态才能从初始状态
E
E
E回到终结状态
E
E
E。而如果读完某字符串(例如
01011
01011
01011)后处于状态
O
O
O,则因为
O
O
O不是终结状态,
M
1
M_1
M1不接受该字符串。
2.2 非确定型有穷自动机
对于有穷自动机而言,对每个 q ∈ Q q\in Q q∈Q和 a ∈ Σ a\in\Sigma a∈Σ, δ ( q , a ) \delta(q,a) δ(q,a)有确定的值,因此给定输入字符串后有穷自动机的动作是完全确定的,所以也被称为确定型有穷自动机(Deterministic Finite Automaton),记作DFA。如果 δ ( q , a ) \delta(q,a) δ(q,a)不是一个状态,而是 Q Q Q的一个子集,表示自动机可以转移到这个子集中的任一个状态(而不是仅仅一个状态),那么 δ \delta δ不再是 Q × Σ Q\times\Sigma Q×Σ到 Q Q Q的一个函数,而是 Q × Σ Q\times\Sigma Q×Σ到 Q Q Q的幂集 P ( Q ) P(Q) P(Q)的函数。这样的自动机动作不确定,称为非确定型有穷自动机(Nondeterministic Finite Automaton, NFA)。
非确定型有穷自动机的定义:NFA是一个有序五元组 M = ( Q , Σ , δ , q 0 , F ) M=(Q,\Sigma,\delta,q_0,F) M=(Q,Σ,δ,q0,F),其中 Q , Σ , q 0 , F Q,\Sigma,q_0,F Q,Σ,q0,F的含义与FA的定义相同,而 δ : Q × Σ → P ( Q ) \delta:Q\times\Sigma\to P(Q) δ:Q×Σ→P(Q)。
NFA的状态转移图与DFA的区别:对于每个 q ∈ Q q\in Q q∈Q和 a ∈ Σ a\in\Sigma a∈Σ,DFA恰好有一条从节点 q q q出发标有 a a a的边,而NFA可能有一条或多条这样的边,也可以没有这样的边。
推广的状态转移函数:定义函数 δ ^ : Q × Σ ∗ → P ( Q ) \hat\delta:Q\times\Sigma^*\to P(Q) δ^:Q×Σ∗→P(Q),使得 δ ^ ( q , x ) \hat\delta(q,x) δ^(q,x)表示读完字符串 x x x后所处的状态集合。形式化的定义为 δ ^ ( q , ε ) = { q } \hat\delta(q,\varepsilon)=\{q\} δ^(q,ε)={q} δ ^ ( q , x a ) = ⋃ r ∈ δ ^ ( q , x ) δ ( r , a ) \hat\delta(q,xa)=\bigcup\limits_{r\in\hat\delta(q,x)}\delta(r,a) δ^(q,xa)=r∈δ^(q,x)⋃δ(r,a)直观地讲,它是走所有可能的路线后结果的并集。
接受的语言:设NFA
M
=
(
Q
,
Σ
,
δ
,
q
0
,
F
)
M=(Q,\Sigma,\delta,q_0,F)
M=(Q,Σ,δ,q0,F),
ω
∈
Σ
∗
\omega\in\Sigma^*
ω∈Σ∗。如果
δ
^
(
q
0
,
ω
)
∩
F
≠
∅
\hat\delta(q_0,\omega)\cap F\ne\emptyset
δ^(q0,ω)∩F=∅,则称
M
M
M接受
ω
\omega
ω。
M
M
M接受的字符串的全体称作
M
M
M接受的语言,记作
L
(
M
)
L(M)
L(M),即
L
(
M
)
=
{
ω
∈
Σ
∗
∣
δ
^
(
q
0
,
ω
)
∩
F
≠
∅
}
L(M)=\{\omega\in\Sigma^*|\hat\delta(q_0,\omega)\cap F\ne\emptyset\}
L(M)={ω∈Σ∗∣δ^(q0,ω)∩F=∅}。
即:只要读完一条字符串有一种可能到达某个终结状态,
M
M
M就接受这个字符串。
3. 图灵机
3.1 图灵机的定义
设想图灵机是由一个控制器和一条无穷长的带组成。
- 带被分成许多小方格,两头是无限的。每个方格内可以存放字母表 Γ \Gamma Γ中的一个符号。
- 控制器具有:
- 有穷个内部状态
- 一个读写头
在计算的每一步,控制器处于某个内部状态,读写头扫描带的某个方格,并且根据它当前的状态和扫描的方格内的内容决定下一步动作:
(1) 把正在扫描的方格内的内容改写成
Γ
\Gamma
Γ中的某个符号;
(2) 读写头向左或者向右移动一格;
(3) 控制器转移到某个状态。
计算开始时,输入字符串存放在带上,带的其余部分均为空白。控制器处于初始状态
q
0
q_0
q0,读写头扫描输入串左端的第一个符号。如果对于当前的状态和扫描的符号没有下一个动作,则停机。定义如下。

图灵机(Turing Machine, TM):是一个有序七元组
M
=
(
Q
,
Σ
,
Γ
,
δ
,
q
0
,
B
,
A
)
M=(Q,\Sigma,\Gamma,\delta,q_0,B,A)
M=(Q,Σ,Γ,δ,q0,B,A),其中
(1)
Q
Q
Q是非空有穷的状态集合;
(2)
Σ
\Sigma
Σ是非空有穷的输入字母表;
(3)
Γ
\Gamma
Γ是非空有穷的带字母表且
Σ
⫋
Γ
\Sigma\subsetneqq\Gamma
Σ⫋Γ;
(4)
q
0
∈
Q
q_0\in Q
q0∈Q是初始状态;
(5)
B
∈
Γ
−
Σ
B\in\Gamma-\Sigma
B∈Γ−Σ是空白符;
(6)
A
⊆
Q
A\subseteq Q
A⊆Q是接受状态集合;
(7)
δ
\delta
δ是动作函数,它定义在
Q
×
Γ
Q\times\Gamma
Q×Γ的一个子集上,取值于
Γ
×
{
L
,
R
}
×
Q
\Gamma\times\{L,R\}\times Q
Γ×{L,R}×Q,即
dom
δ
⊆
Q
×
Γ
\text{dom}\ \delta\subseteq Q\times\Gamma
dom δ⊆Q×Γ,
range
δ
⊆
Γ
×
{
L
,
R
}
×
Q
\text{range}\ \delta\subseteq\Gamma\times\{L,R\}\times Q
range δ⊆Γ×{L,R}×Q。
δ
(
q
,
s
)
=
(
s
′
,
L
/
R
,
q
′
)
\delta(q,s)=(s',L/R,q')
δ(q,s)=(s′,L/R,q′)表示在当前状态是
q
q
q、读写头扫描的符号为
s
s
s时,下一步把这个
s
s
s改写成
s
′
s'
s′,读写头往左/右移一格。
例 图灵机 M = ( { q 0 , q 1 , q 2 , q 3 } , { 0 , 1 } , { 0 , 1 , B } , δ , q 0 , B , { q 3 } ) M=\left(\{q_0,q_1,q_2,q_3\},\{0,1\},\{0,1,B\},\delta,q_0,B,\{q_3\}\right) M=({q0,q1,q2,q3},{0,1},{0,1,B},δ,q0,B,{q3}),其中 δ \delta δ如下表所示:
| δ \delta δ | 0 0 0 | 1 1 1 | B B B |
|---|---|---|---|
| q 0 q_0 q0 | ( 0 , R , q 0 ) (0,R,q_0) (0,R,q0) | ( 1 , R , q 0 ) (1,R,q_0) (1,R,q0) | ( B , L , q 1 ) (B,L,q_1) (B,L,q1) |
| q 1 q_1 q1 | ( B , L , q 2 ) (B,L,q_2) (B,L,q2) | ( 1 , R , q 0 ) (1,R,q_0) (1,R,q0) | ( B , R , q 0 ) (B,R,q_0) (B,R,q0) |
| q 2 q_2 q2 | ( B , R , q 3 ) (B,R,q_3) (B,R,q3) | 未定义 | 未定义 |
| q 3 q_3 q3 | 未定义 | 未定义 | 未定义 |
在这个例子中,状态集合 Q = { q 0 , q 1 , q 2 , q 3 } Q=\{q_0,q_1,q_2,q_3\} Q={q0,q1,q2,q3},其中 q 0 q_0 q0是初始状态。 Σ = { 0 , 1 } \Sigma=\{0,1\} Σ={0,1}是输入字母表, Γ = { 0 , 1 , B } \Gamma=\{0,1,B\} Γ={0,1,B}是带字母表, Γ \Gamma Γ与 Σ \Sigma Σ的差集 { B } \{B\} {B}包含了空白符。 A = { q 3 } A=\{q_3\} A={q3}是接受状态集合。
与有穷自动机类似,也可以用状态转移图来表示图灵机。在每条边旁标上
s
/
s
′
s/s'
s/s′,
R
R
R或
L
L
L,以标明图灵机的动作。例子的状态转移图如图所示。

在计算的每一步,带上只有有限个方格的内容是非空白符。因此,带的内容总可以表示成
B
a
1
a
2
⋯
a
n
B
Ba_1a_2\cdots a_nB
Ba1a2⋯anB其中
a
1
a
2
⋯
a
n
a_1a_2\cdots a_n
a1a2⋯an是输入字符串,两端的其余部分全是空白符。带的内容其实是
⋯
B
B
B
a
1
a
2
⋯
a
n
B
B
B
⋯
\cdots BBBa_1a_2\cdots a_nBBB\cdots
⋯BBBa1a2⋯anBBB⋯,左边和右边都有无穷个
B
B
B,只不过我们当只有一个
B
B
B对待。当然,这里也允许某些
a
i
a_i
ai是空白符。注意,
a
i
∈
Γ
a_i\in\Gamma
ai∈Γ。为了描述计算中的一步,还需要指明当前控制器所处的状态和读写头扫描的带方格,可把它表示成
a
1
a
2
⋯
a
i
↑
q
⋯
a
n
−
1
a
n
a_1a_2\cdots \underset{\large{q}}{\underset{\large\uparrow}{a_i}}\cdots a_{n-1}a_n
a1a2⋯q↑ai⋯an−1an或
a
1
⋯
a
i
−
1
q
a
i
⋯
a
n
a_1\cdots a_{i-1}q a_i\cdots a_n
a1⋯ai−1qai⋯an格局:带上的内容、控制器的状态和读写头扫描的带方格称为
M
M
M的一个格局,记作
α
1
q
α
2
\alpha_1q\alpha_2
α1qα2,其中
α
1
=
a
1
a
2
⋯
a
i
−
1
\alpha_1=a_1a_2\cdots a_{i-1}
α1=a1a2⋯ai−1,
α
2
=
a
i
a
i
+
1
⋯
a
n
\alpha_2=a_ia_{i+1}\cdots a_n
α2=aiai+1⋯an,
α
1
,
α
2
∈
Γ
∗
,
q
∈
Q
\alpha_1,\alpha_2\in\Gamma^*,q\in Q
α1,α2∈Γ∗,q∈Q。它表示带的内容(除了左边和右边的无穷多个空白符)是
ω
=
α
1
α
2
\omega=\alpha_1\alpha_2
ω=α1α2,当前状态为
q
q
q,读写头正在扫描
α
2
\alpha_2
α2的第一个符号
a
i
a_i
ai。如果
α
2
\alpha_2
α2是空串,则读写头扫描紧挨在右边的空白符。
M
M
M的初始格局为
q
0
ω
q_0\omega
q0ω,这里
ω
∈
Σ
∗
\omega\in\Sigma^*
ω∈Σ∗是输入字符串。
设
σ
1
,
σ
2
\sigma_1,\sigma_2
σ1,σ2是两个格局,若从
σ
1
\sigma_1
σ1能够经过一步到达
σ
2
\sigma_2
σ2,则记作
σ
1
⊢
σ
2
\sigma_1\vdash\sigma_2
σ1⊢σ2。
若从
σ
1
\sigma_1
σ1能够经过有限步(可以是零步)到达
σ
2
\sigma_2
σ2,记作
σ
1
⊢
∗
σ
2
\sigma_1\overset*\vdash\sigma_2
σ1⊢∗σ2。
接受格局和停机格局:
如果格局
σ
=
α
1
q
α
2
\sigma=\alpha_1q\alpha_2
σ=α1qα2中的
q
q
q是接受状态,即
q
∈
A
q\in A
q∈A,则称
σ
\sigma
σ是接受格局。
如果
σ
\sigma
σ之后没有任何动作(即
δ
(
q
,
s
)
\delta(q,s)
δ(q,s)没有定义,其中
s
=
a
i
s=a_i
s=ai是读写头正在扫描的内容,是
α
2
\alpha_2
α2的第一个字符),则称
σ
\sigma
σ是停机格局。
计算:设
σ
1
,
σ
2
,
⋯
,
σ
n
,
⋯
\sigma_1,\sigma_2,\cdots,\sigma_n,\cdots
σ1,σ2,⋯,σn,⋯是一个格局序列,它可以是有穷的,也可以是无穷的。如果对每个
i
i
i都有
σ
i
⊢
σ
i
+
1
\sigma_i\vdash\sigma_{i+1}
σi⊢σi+1,则称这个序列是一个计算。
任给一个输入字符串
ω
∈
Σ
∗
\omega\in\Sigma^*
ω∈Σ∗,从初始格局
σ
0
=
q
0
ω
\sigma_0=q_0\omega
σ0=q0ω开始,
M
M
M在
ω
\omega
ω上的计算有以下
3
3
3种可能:
(1) 停机在接受状态,即计算是以接受格局结束的有穷序列
σ
0
,
σ
1
,
⋯
,
σ
n
\sigma_0,\sigma_1,\cdots,\sigma_n
σ0,σ1,⋯,σn,其中
σ
n
\sigma_n
σn是接受的停机格局。
(2) 停机在非接受状态,即计算是以非接受格局结束的有穷序列
σ
0
,
σ
1
,
⋯
,
σ
n
\sigma_0,\sigma_1,\cdots,\sigma_n
σ0,σ1,⋯,σn,其中
σ
n
\sigma_n
σn是停机格局,但不是接受格局。
(3) 永不停机,即计算是一个无穷序列
σ
0
,
σ
1
,
⋯
\sigma_0,\sigma_1,\cdots
σ0,σ1,⋯(死循环就是一种永不停机的情况)。
如果是第一种情况,就说图灵机
M
M
M接受字符串
ω
\omega
ω。
如果是第二或第三种情况,就说图灵机
M
M
M不接受字符串
ω
\omega
ω,或拒绝
ω
\omega
ω。
即:
{
M
接受
ω
→
停机在接受状态
M
拒绝
ω
→
{
停机在非接受状态
永不停机
\begin{cases}M\text{接受}\omega\to\text{停机在接受状态}\\M\text{拒绝}\omega\to\begin{cases}\text{停机在非接受状态}\\\text{永不停机}\end{cases}\end{cases}
⎩
⎨
⎧M接受ω→停机在接受状态M拒绝ω→{停机在非接受状态永不停机
接受的语言:图灵机
M
=
(
Q
,
Σ
,
Γ
,
δ
,
q
0
,
B
,
A
)
M=(Q,\Sigma,\Gamma,\delta,q_0,B,A)
M=(Q,Σ,Γ,δ,q0,B,A)接受的语言
L
(
M
)
L(M)
L(M)是
M
M
M接受的字符串的全体,即
L
(
M
)
=
{
ω
∈
Σ
∗
∣
M
接受
ω
}
L(M)=\{\omega\in\Sigma^*|M\text{接受}\omega\}
L(M)={ω∈Σ∗∣M接受ω}。
例 继续考察上面给出的例子。考虑输入字符串
ω
=
10100
\omega=10100
ω=10100,那么带的内容是
⋯
B
B
B
10100
B
B
B
⋯
\cdots BBB10100BBB\cdots
⋯BBB10100BBB⋯。图灵机
M
M
M在输入
ω
=
10100
\omega=10100
ω=10100上的计算是这样的:
B
1
↑
q
0
0100
B
⊢
B
1
0
↑
q
0
100
B
⊢
B
10
1
↑
q
0
00
B
⊢
B
101
0
↑
q
0
0
B
⊢
B
1010
0
↑
q
0
B
⊢
B
10100
B
↑
q
0
⊢
B
1010
0
↑
q
1
B
⊢
B
101
0
↑
q
2
B
B
⊢
B
101
B
B
↑
q
3
B
B\underset{\large{q_0}}{\underset{\large\uparrow}1}0100B\quad\vdash\quad B1\underset{\large{q_0}}{\underset{\large\uparrow}0}100B\quad\vdash\quad B10\underset{\large{q_0}}{\underset{\large\uparrow}1}00B\quad\vdash\quad B101\underset{\large{q_0}}{\underset{\large\uparrow}0}0B\quad\vdash\quad B1010\underset{\large{q_0}}{\underset{\large\uparrow}0}B\quad\vdash\quad B10100\underset{\large{q_0}}{\underset{\large\uparrow}B}\quad\vdash\quad B1010\underset{\large{q_1}}{\underset{\large\uparrow}0}B\quad\vdash\quad B101\underset{\large{q_2}}{\underset{\large\uparrow}0}BB\quad\vdash\quad B101B\underset{\large{q_3}}{\underset{\large\uparrow}B}B
Bq0↑10100B⊢B1q0↑0100B⊢B10q0↑100B⊢B101q0↑00B⊢B1010q0↑0B⊢B10100q0↑B⊢B1010q1↑0B⊢B101q2↑0BB⊢B101Bq3↑BB这个图灵机
M
M
M计算的一般过程:
(1) 在状态
q
0
q_0
q0下,因为
δ
(
q
0
,
0
)
=
(
0
,
R
,
q
0
)
\delta(q_0,0)=(0,R,q_0)
δ(q0,0)=(0,R,q0),
δ
(
q
0
,
1
)
=
(
1
,
R
,
q
0
)
\delta(q_0,1)=(1,R,q_0)
δ(q0,1)=(1,R,q0),相当于读写头不断右移且不对带做任何更改,扫描整个输入
ω
\omega
ω,直到遇到一个空白符
B
B
B为止。此时
ω
\omega
ω已经被读完(因为
ω
\omega
ω中本身不含空白字符),读写头指向
ω
\omega
ω右边的第一个空白字符。
(2) 由于
δ
(
q
0
,
B
)
=
(
B
,
L
,
q
1
)
\delta(q_0,B)=(B,L,q_1)
δ(q0,B)=(B,L,q1),故状态转到
q
1
q_1
q1,不对带做更改,读写头左移。
(3)
- 如果
ω
\omega
ω以
0
0
0结尾,因为
δ
(
q
1
,
0
)
=
(
B
,
L
,
q
2
)
\delta(q_1,0)=(B,L,q_2)
δ(q1,0)=(B,L,q2),所以把
0
0
0改成
B
B
B,向左移一格,状态转到
q
2
q_2
q2;
- 如果 ω \omega ω的倒数第二个字符为 0 0 0,则因为 δ ( q 2 , 0 ) = ( B , R , q 3 ) \delta(q_2,0)=(B,R,q_3) δ(q2,0)=(B,R,q3),所以把 0 0 0改成 B B B,向右移一格,停机在接受状态 q 3 q_3 q3(注意 δ ( q 3 , B ) \delta(q_3,B) δ(q3,B)没有定义)。
- 如果 ω \omega ω的倒数第二个字符为 1 1 1,或者 ω \omega ω仅有一个字符 0 0 0(这使得现在读写头指向 B B B),则因为 δ ( q 2 , 1 ) \delta(q_2,1) δ(q2,1)和 δ ( q 2 , B ) \delta(q_2,B) δ(q2,B)都没有定义,所以 M M M停机在非接受状态 q 2 q_2 q2。
- 如果 ω \omega ω以 1 1 1结尾,则由于 δ ( q 1 , 1 ) = ( 1 , R , q 0 ) \delta(q_1,1)=(1,R,q_0) δ(q1,1)=(1,R,q0),不对带做更改,向右移一格,状态转回 q 0 q_0 q0。这会导致状态在 q 0 q_0 q0和 q 1 q_1 q1之间不断来回变动,读写头一左一右来回移动, M M M永不停机。在状态转移图上的表现为 q 0 q_0 q0和 q 1 q_1 q1之间的圈。
- 如果 ω = ε \omega=\varepsilon ω=ε,则由于 δ ( q 1 , B ) = ( B , R , q 0 ) \delta(q_1,B)=(B,R,q_0) δ(q1,B)=(B,R,q0),结果和以 1 1 1结尾类似。
因此, M M M接受所有以 00 00 00结尾的 0 , 1 0,1 0,1字符串,即 L ( M ) = { S 00 ∣ S ∈ Σ ∗ } L(M)=\{S00|S\in\Sigma^*\} L(M)={S00∣S∈Σ∗}。
注意:图灵机的状态个数是有限的!如果状态个数是无限的,那么它可以在线性时间内解决任何问题,因为每个状态可以表示任何信息,可以为每个输入字符串给定一个对应的状态,并把在需要判定的语言中的字符串连接到接受状态,那就可以不费吹灰之力地判定一个语言了!事实上,这种图灵机是无法实现的。
按照我的理解,若图灵机不接受某个语言,代入C++就像是会抛异常或无限循环/无穷递归。如果停机在接受状态,就好像函数正常返回一个值。
图灵机是现代计算机的理论基石,它是一个抽象模型,它的出现决定了现代计算机可以被实现。事实上,细胞中核糖体翻译的过程就酷似图灵机的运作过程(只不过核糖体只能单向移动)。
3.2 图灵停机问题(Turing’s Halting Problem)
假设算力、存储空间、时间都足够,是不是所有的问题都可以编程解决呢?你可能认为是这样,因为我们在生活中似乎没有见到过计算机算不出来的问题。但是,有一个问题是永远不可能算出来的,它就是图灵停机问题。
如果给你这样一串代码:
while(true);
显然它是永远不会结束执行的,因为它是一个死循环,就像图灵机永不停机。对于这个例子,我们很容易看出它不会停机。但下面这一串呢?
double x = 3;
while(x <= 3)
{
x = (x + 3 / x) / 2;
}
事实上它也是死循环,因为 x x x的值其实是趋于 3 \sqrt3 3的递减数列,所以 x ≤ 3 x\le3 x≤3恒成立,而且不会出现溢出的情况,所以它会永远执行下去。对于这串代码我们就不那么容易看出来它不会停机了。于是产生了一个问题:是否存在一个算法,使得我给它一串代码和该代码的输入数据,使得它更够判断这串代码在这个输入数据下是不是死循环,或者说这个图灵机会不会停机呢?这就是图灵停机问题。
假设存在这样的一个算法,它的实现如下:
bool 是否会停机(待测函数, 输入数据) // 判断待测函数在输入数据下是否会停机
{
if(待测函数(输入数据)会在有限时间内停机) return true;
else return false;
}
那么我们巧妙地构造出一个函数:
void 巧妙的函数(某函数)
{
if(是否会停机(某函数, 某函数) == false) return; // 立即停机
else while(true); // 进入死循环
}
可以看出,巧妙的函数的运作过程如下:
(1) 当函数是否会停机判断某函数以某函数本身为输入不能停机时,立即停机;
(2) 当判断可以停机时,则进入死循环,永不停机。就是对着干。
那么,是否会停机(巧妙的函数, 巧妙的函数)会返回什么呢?
(1) 假如返回true,表示巧妙的函数能停机,可是如果返回true的话巧妙的函数就会进入死循环,不会停机;
(2) 假如返回false,表示巧妙的函数不能停机,可是此时巧妙的函数应该立即停机才对。
综上,我们推出了矛盾,证明了能解决停机问题的函数是否会停机不存在。这个问题与罗素悖论(
S
=
{
x
∣
x
∉
S
}
S=\{x|x\notin S\}
S={x∣x∈/S})有异曲同工之妙。
我们构造问题的方式是“自指”,就如同左脚踩右脚上天一样触发了矛盾。这表明数学是不确定的(Undecidable)。这个问题表明,即使在最严谨的数学中,也不是每个判定问题都可以判定。
还有一种理解方式:如果函数是否会停机真的存在的话,那它势必能判断这个函数是否能停机:
bool 验证哥德巴赫猜想()
{
for(大整数 i = 4; ; i += 2) // 枚举所有大于等于4的偶数
{
if(不能找到两个质数的和为i) return false; // 哥德巴赫猜想不成立,i是反例
}
return true; // 哥德巴赫猜想成立(其实永远不会执行到这一步)
}
函数验证哥德巴赫猜想枚举每个大于等于4的偶数,如果所有这些偶数都能表示成两个质数之和,那它就永远不会返回;否则,它将在有限步之内返回,并找出反例。假如是否会停机存在的话,它说验证哥德巴赫猜想不会停机,那么哥德巴赫猜想成立;如果说会停机,那么哥德巴赫猜想不成立。也就是说,是否会停机强大到能够判断哥德巴赫猜想成不成立。如果把哥德巴赫猜想换成黎曼猜想,那就能判断黎曼猜想成不成立。能实现是否会停机的人也一定能证明这么多的数学猜想。所以,是否会停机当然不可能存在啦。
3.3 丘奇-图灵论题(Church-Turing Thesis)
丘奇-图灵论题是指“任何算法都可以由一个图灵机来描述”(Every effective computation can be carried out by a Turing machine)。无数的事实证明这个论题是正确的。尽管“Effective Computation”并没有准确定义,但是一般还是把该论题假定为真。
3.4 通用图灵机(Universal Turing Machine, UTM)
通用图灵机也是一种图灵机,不过它是用来模拟图灵机的图灵机。它的输入是对一个图灵机 T M T_M TM的描述和一个字符串 ω \omega ω,这个字符串 ω \omega ω是 T M T_M TM的输入。它能够根据对 T M T_M TM的描述构建出 T M T_M TM并将 ω \omega ω输入 T M T_M TM,最后返回 T M T_M TM运行的结果。 T M T_M TM就像是一个程序,而通用图灵机是一种“可编程图灵机”,它解释执行这个程序。就比如说一个Python脚本就相当于 T M T_M TM,而Python解释器就相当于一个通用图灵机,它读入Python脚本(即对 T M T_M TM的描述)和一个用户输入 ω \omega ω,以 ω \omega ω为输入执行脚本,最后返回执行结果。
3.5 图灵完备性(Turing Completeness)
如果一系列操作数据的规则(如指令集、编程语言、元胞自动机)可以用来模拟单带图灵机(只有一个带的图灵机),那么它是图灵完备的。图灵完备性被用来表示这种数据操作规则的能力。
要证明一个系统是图灵完备的,只需要用它模拟另一个图灵完备的系统。虽然没有任何物理系统可以具有无限的内存,但如果忽略内存大小的限制,大多数编程语言都将是图灵完备的。
一篇python-course.eu的文章用Python模拟了图灵机,表明Python是图灵完备的。而因为Python解释器是C语言写的,所以C语言也是图灵完备的。又因为C程序是先编译成汇编语言再变成机器语言的,因此汇编语言、机器语言也是图灵完备的。
一个极简单的图灵完备语言是由Urban Müller在1993年创建的Brainfuck,它仅由8种字符构成。例如下面这串代码的功能是输出"Hello World!"。
>+++++++++[<++++++++>-]<.>+++++++[<++++>-]<+.+++++++..+++.>>>++++++++[<++++>-]
<.>>>++++++++++[<+++++++++>-]<---.<<<<.+++.------.--------.>>+.>++++++++++.
如果一个语言能够实现它的解释器(这并不困难),那么这个语言也是图灵完备的。
值得一提的是,游戏《Minecraft》中的红石作为一门语言也是图灵完备的,不过Minecraft本身并不是图灵完备的。
三、P、NP、NP-Complete、NP-Hard
你可能知道,P问题是可以在多项式时间内解决的问题,NP问题是指不知道能否再多项式时间内求解,但可以在多项式时间内验证结果的问题。那么这些问题的严格定义是什么呢?这里我查阅了Wikipedia的表述、美国Clay数学研究所对P=NP?问题的描述以及《算法导论》中的表达,给出数学上对P、NP等问题的定义。
1. 决定性问题(Decision Problem)和最优化问题(Optimization Problem)
1.1 决定性问题
决定性问题是一个对输入数据回答“是”或“否”的问题。(A decision problem is a problem that can be posed as a yes–no question of the input values.)比如:“给定一个数
x
x
x,
x
x
x是不是质数?”“给定两个数
x
x
x和
y
y
y,
x
x
x能整除
y
y
y吗?”“给定一个图
G
G
G,它的最小生成树的权重是
114
114
114吗?”

1.2 最优化问题
最优化问题是指从从所有可行的解(feasible solutions)中找出一个最优解(best solution)的问题。比如求节点
u
u
u到
v
v
v的最短路径的问题,可行解就是
u
u
u到
v
v
v所有的路径,最优解就是其中边权之和最小的路径。
为了简单起见,NP完全性理论把注意力集中在判定问题上。虽然我们的目光集中在判定问题,但我们的研究对最优化问题也有重要的意义。这是因为,最优化问题通常必判定问题更难,或者至少不会更简单。例如求节点
u
u
u到
v
v
v的最短路径的问题,这是一个最优化问题,但是我可以把问题转化成一个判定问题:“给定节点
u
u
u、节点
v
v
v和实数
k
k
k,问节点
u
u
u和
v
v
v之间是否存在长度至多为
k
k
k的路径?”显然原来的最优化问题不比这个判定问题简单。如果我们解决了最优化问题,知道了
u
u
u到
v
v
v的最短路径长度是
l
l
l,那么我们就能轻而易举地解决判定问题:
k
≥
l
k\ge l
k≥l时路径存在,
k
<
l
k<l
k<l时不存在。所以,如果我们证明判定问题是困难的,就能表明其对应的最优化问题也是困难的。
2. 归约(Reduction)
在研究NP完全性时常常需要比较两个问题谁更难,这时候就要用到归约。所谓归约就是把一个问题转化为另一个问题。如果一个问题能够转化为另一个问题,并且转化足够高效(比如转化的时间复杂度较低),那么这可能表明第二个问题不会难于第一个问题。
这里我们只考虑“多项式归约”。考虑两个判定问题
A
A
A和
B
B
B,其中
B
B
B能在多项式时间内解决,我们希望证明
A
A
A也可以在多项式时间内解决。假设有一个归约算法(reduction algorithm),可以将问题
A
A
A的任何实例(instance,是指某个特定问题的输入)
α
\alpha
α转化为问题
B
B
B的实例
β
\beta
β,且满足:
(1) 转化操作只需要多项式时间;
(2) 两个实例的解是相同的,即
α
\alpha
α的解是“是”当且仅当
β
\beta
β的解是“是”;
那么我们就获得了一个在多项式时间内解决
A
A
A问题的方法,其伪代码如下:
bool B(β); // 解决问题B的函数
bool A(α) // 解决问题A的函数
{
用归约算法把α转化为β; // 只花费多项式时间
return B(β);
}
有了这个技术,我们就可以证明一个问题能否在多项式时间内解决。假设 A A A能在多项式时间内解决,而 A A A又能在多项式时间内归约到 B B B,那么可以用反证法证明 B B B也不能在多项式时间内解决。(如果 B B B能在多项式时间内解决的话,根据上面的讨论,那 A A A也能在多项式时间内解决。)于是我们有了这样一个结论:
命题 如果一个问题
A
A
A可以在多项式时间内归约到问题
B
B
B,则:
(1) 若
A
A
A不能在多项式时间内解决,则
B
B
B也不能在多项式时间内解决;
(2) 若
B
B
B能在多项式时间内解决,则
A
A
A也能在多项式时间内解决(与(1)互为逆否)。
注意,如果 B B B不能在多项式时间内解决,不代表 A A A也不能再多项式时间内解决。因为你完全可以把一个问题归约成一个更难的问题,比如把求一元一次方程 a x + b = 0 ax+b=0 ax+b=0的解归约成求一元六次方程 0 x 6 + 0 x 5 + 0 x 4 + 0 x 3 + 0 x 2 + a x + b = 0 0x^6+0x^5+0x^4+0x^3+0x^2+ax+b=0 0x6+0x5+0x4+0x3+0x2+ax+b=0的解,而一元六次方程没有求根公式。
3. 抽象问题
二元关系:如果一个集合为空集或者它的元素都是有序对,则称这个集合是一个二元关系,一般记作 R R R。对于二元关系 R R R,如果 ( x , y ) ∈ R (x,y)\in R (x,y)∈R,则记作 x R y xRy xRy或 R ( x , y ) R(x,y) R(x,y)。
集合的二元关系:设 A A A、 B B B是两个集合, A × B A\times B A×B的任何子集上所定义的二元关系称作从 A A A到 B B B的二元关系,特别当 A = B A=B A=B时,称作 A A A上的二元关系。
定义抽象问题 Q Q Q为在问题实例集合 I I I和问题解集合 S S S上的一个二元关系。为什么不是函数?因为有些问题实例是没有解的,而且一个问题实例不一定只有一个解,不符合函数的定义。比如上面提到的最短路问题,它的一个实例(输入)是一个图和两个顶点组成的三元组 ( G , u , v ) (G,u,v) (G,u,v),解是图中的一个顶点序列。解可能有零个(从 u u u不能到达 v v v),也可能有多个(有多条长度相同的最短路径)。
对于我们所关注的判定问题,其解集一定是 S = { 0 , 1 } S=\{0,1\} S={0,1},而且解是存在的、唯一的(不考虑图灵停机问题这种不可解的判定问题),那么判定问题就是从实例集 I I I到解集 S = { 0 , 1 } S=\{0,1\} S={0,1}的一个函数 Q : I → { 0 , 1 } Q:I\to\{0,1\} Q:I→{0,1}。即: ∀ i ∈ I , Q ( i ) ∈ { 0 , 1 } \forall i\in I,Q(i)\in\{0,1\} ∀i∈I,Q(i)∈{0,1}。
4. 编码与具体问题
计算机程序求解一个抽象问题,并不是直接将实例本身作为输入,而是以一种程序所能理解的方式(比如二进制)作为输入。例如我们要求最短路,实例 ( G , u , v ) (G,u,v) (G,u,v)并不能直接输入电脑,而是要将 ( G , u , v ) (G,u,v) (G,u,v)变成计算机能理解的东西( G G G变成邻接矩阵或邻接表,每个顶点的编号以及边权都要使用二进制)。因此我们需要编码来进行转换。
抽象对象集合 A A A的编码是从 A A A到二进制串集合的映射 e e e。例如对于自然数 11 4 ( 10 ) 114_{(10)} 114(10),我们将它转化为二进制 e ( 11 4 ( 10 ) ) = 111001 0 ( 2 ) e\left(114_{(10)}\right)=1110010_{(2)} e(114(10))=1110010(2)。除了自然数,浮点数、字符、图、函数、有序对、程序、图像、音频、视频等都有对应的编码将它们转化为二进制。
真正输入计算机程序的其实是某个问题的编码,我们把这种以二进制串集合为实例集的问题称为具体问题。

5. P问题
5.1 抽象问题
设有有穷字母表
Σ
\Sigma
Σ,其至少含有两个元素。设
Σ
∗
\Sigma^*
Σ∗是
Σ
\Sigma
Σ上有穷字符串的集合,语言
L
⊆
Σ
∗
L\subseteq \Sigma^*
L⊆Σ∗。令
Σ
\Sigma
Σ是图灵机
M
M
M的输入字母表,
M
M
M接受的语言为
L
(
M
)
=
{
ω
∈
Σ
∗
∣
M
接受
ω
}
L(M)=\{\omega\in\Sigma^*|M\text{接受}\omega\}
L(M)={ω∈Σ∗∣M接受ω}。
设
t
M
(
ω
)
t_M(\omega)
tM(ω)是
M
M
M对于输入
ω
\omega
ω所进行的计算的步数。如果图灵机永不停机,则
t
M
(
ω
)
=
∞
t_M(\omega)=\infty
tM(ω)=∞。
定义
M
M
M的最坏运行时间
T
M
(
n
)
=
max
{
t
M
(
ω
)
∣
ω
∈
Σ
n
}
T_M(n)=\max\{t_M(\omega)|\omega\in\Sigma^n\}
TM(n)=max{tM(ω)∣ω∈Σn},其中
Σ
n
\Sigma^n
Σn是
Σ
\Sigma
Σ上所有长度为
n
n
n的字符串的集合。即:
T
M
(
n
)
T_M(n)
TM(n)是所有长度为
n
n
n的输入中最坏情况下计算的步数。
若
∃
k
\exists k
∃k使得
∀
n
\forall n
∀n,
T
M
(
n
)
≤
n
k
+
k
T_M(n)\le n^k+k
TM(n)≤nk+k,则称
M
M
M在多项式时间内运行(runs in polynomial time)。我们定义复杂类
P
\bold P
P,它是语言的集合:
P
=
{
L
∣
L
=
L
(
M
)
,
其中
M
是某个在多项式时间内运行的图灵机
}
\bold P=\{L|L=L(M), \text{其中}M\text{是某个在多项式时间内运行的图灵机}\}
P={L∣L=L(M),其中M是某个在多项式时间内运行的图灵机}即:对于一个语言
L
L
L,如果存在图灵机
M
M
M,使得
L
L
L是
M
M
M接受的语言,而且
M
M
M是在多项式时间内运行的,则
L
L
L是一个
P
\bold P
P问题的实例集,或
L
∈
P
L\in\bold P
L∈P。语言是问题的实例集,语言的每个元素/字符串
ω
\omega
ω是问题的实例。
例1 判断若干个正整数是否互质问题,其中每个正整数不大于 U U U。字母表 Σ = { x ∣ x ∈ N + , x ≤ U } \Sigma=\{x|x\in \mathbb N^+,x\le U\} Σ={x∣x∈N+,x≤U}。 Σ \Sigma Σ上的长度为 n n n的字符串 ω \omega ω是 n n n个不大于 U U U的正整数的序列。语言 L = Σ ∗ L=\Sigma^* L=Σ∗是所有不大于 U U U的正整数的序列。我们可以构造出一个图灵机 M M M(主要采用欧几里得算法),使得 M M M接受语言 L L L且 T M ( n ) = O ( n log U ) = O ( n ) T_M(n)=O(n\log U)=O(n) TM(n)=O(nlogU)=O(n),所以 M M M是在多项式时间内运行的,于是语言 L L L属于 P \bold P P。
例2 判断回文串的问题,这里字符串是小写字母构成的。字母表 Σ = { a , b , c , ⋯ , z } \Sigma=\{a,b,c,\cdots,z\} Σ={a,b,c,⋯,z}。语言 L = { ω ∈ Σ ∗ ∣ ω 是回文串 } L=\{\omega\in\Sigma^*|\omega\text{是回文串}\} L={ω∈Σ∗∣ω是回文串}。显然存在图灵机 M M M接受 L L L且 T M ( n ) = O ( n ) T_M(n)=O(n) TM(n)=O(n)。因此语言 L ∈ P L\in\bold P L∈P。
5.2 具体问题
对于抽象判定问题 Q : I → { 0 , 1 } Q:I\to\{0,1\} Q:I→{0,1},我们可以利用编码 e : I → { 0 , 1 } ∗ e:I\to\{0,1\}^* e:I→{0,1}∗导出与该问题相关的具体判定问题,记作 e ( Q ) e(Q) e(Q)。如果一个抽象问题实例 i ∈ I i\in I i∈I的解为 Q ( i ) ∈ { 0 , 1 } Q(i)\in\{0,1\} Q(i)∈{0,1},则该具体问题实例 e ( i ) ∈ { 0 , 1 } ∗ e(i)\in\{0,1\}^* e(i)∈{0,1}∗的解也是 Q ( i ) Q(i) Q(i)。一个具体实例 e ( i ) e(i) e(i)的规模为 n = ∣ e ( i ) ∣ n=|e(i)| n=∣e(i)∣。对于二进制编码的具体问题,一定有 Σ = { 0 , 1 } \Sigma=\{0,1\} Σ={0,1},即图灵机的带一定是 0 , 1 0,1 0,1构成的。下面对具体问题讨论 P \bold P P的定义。
设有图灵机 M M M和输入字符串 ω ∈ { 0 , 1 } ∗ \omega\in\{0,1\}^* ω∈{0,1}∗。若 M M M对输入 ω \omega ω输出 1 1 1(即回答“是”),则称 M M M接受 ω \omega ω。若 M M M对输入 ω \omega ω输出 0 0 0,则称 M M M拒绝 ω \omega ω。 M M M接受的语言 L ( M ) = { ω ∈ { 0 , 1 } ∗ ∣ M 对 ω 输出 1 } L(M)=\{\omega\in\{0,1\}^*|M\text{对}\omega\text{输出}1\} L(M)={ω∈{0,1}∗∣M对ω输出1}。
语言 L ( M ) L(M) L(M)被 M M M所接受,并不意味着它对 ω ′ ∉ L ( M ) \omega'\notin L(M) ω′∈/L(M)输出 0 0 0,因为陷入无限循环也属于不接受的范畴。如果 L L L中每个二进制串只是被 M M M接受或拒绝,而不会陷入无限循环,则称语言 L L L由 M M M判定。
若
∃
k
\exists k
∃k,使得对于任意长度为
n
n
n的字符串
ω
∈
L
(
M
)
\omega\in L(M)
ω∈L(M),
M
M
M可以在
O
(
n
k
)
O\left(n^k\right)
O(nk)的时间内接受
ω
\omega
ω,则称语言
L
L
L在多项式时间内被
M
M
M所接受。
若
∃
k
\exists k
∃k,使得对于任意长度为
n
n
n的字符串
ω
∈
{
0
,
1
}
∗
\omega\in \{0,1\}^*
ω∈{0,1}∗,
M
M
M可以在
O
(
n
k
)
O\left(n^k\right)
O(nk)的时间内正确地判定
ω
∈
L
\omega\in L
ω∈L,则称语言
L
L
L在多项式时间内被
M
M
M所判定。
因此,要接受一个语言,
M
M
M只需要对
L
(
M
)
L(M)
L(M)中的字符串给出一个答案。
但要判定某一语言,
M
M
M不仅要判断
L
(
M
)
L(M)
L(M)中的串,还必须正确地接受或拒绝
{
0
,
1
}
∗
\{0,1\}^*
{0,1}∗中的每一个串。因此,判定比接受更难。
对采用二进制编码的具体问题, P \bold P P的定义是: P = { L ⊆ { 0 , 1 } ∗ ∣ 存在图灵机 M 可以在多项式时间内判定 L } \bold P=\{L\subseteq\{0,1\}^*|\text{存在图灵机}M\text{可以在多项式时间内判定}L\} P={L⊆{0,1}∗∣存在图灵机M可以在多项式时间内判定L}事实上,对于抽象问题的定义在这里也是适用的,即 P \bold P P也可以定义为能在多项式时间内被接受的语言类。我们有:
定理 P = { L ⊆ { 0 , 1 } ∗ ∣ 存在图灵机 M 可以在多项式时间内接受 L } \bold P=\{L\subseteq\{0,1\}^*|\text{存在图灵机}M\text{可以在多项式时间内接受}L\} P={L⊆{0,1}∗∣存在图灵机M可以在多项式时间内接受L}。
证明:设 P 1 = { L ⊆ { 0 , 1 } ∗ ∣ 存在图灵机 M 可以在多项式时间内判定 L } \bold P_1=\{L\subseteq\{0,1\}^*|\text{存在图灵机}M\text{可以在多项式时间内判定}L\} P1={L⊆{0,1}∗∣存在图灵机M可以在多项式时间内判定L}, P 2 = { L ⊆ { 0 , 1 } ∗ ∣ 存在图灵机 M 可以在多项式时间内接受 L } \bold P_2=\{L\subseteq\{0,1\}^*|\text{存在图灵机}M\text{可以在多项式时间内接受}L\} P2={L⊆{0,1}∗∣存在图灵机M可以在多项式时间内接受L},即证 P 1 ⊆ P 2 ∧ P 2 ⊆ P 1 \bold P_1\subseteq \bold P_2\land\bold P_2\subseteq\bold P_1 P1⊆P2∧P2⊆P1。
P 1 ⊆ P 2 \bold P_1\subseteq\bold P_2 P1⊆P2:因为若图灵机 M M M能正确判定字符串 ω \omega ω,它一定能接受 ω \omega ω,所以 P 1 ⊆ P 2 \bold P_1\subseteq\bold P_2 P1⊆P2是显然成立的。
P 2 ⊆ P 1 \bold P_2\subseteq\bold P_1 P2⊆P1:设语言 L ( M ) L(M) L(M)能够被图灵机 M M M在多项式时间内所接受。我们需要构造出另一个图灵机 M ′ M' M′使得 M ′ M' M′能在多项式时间内判定 L ( M ) L(M) L(M)。因为 ∃ k \exists k ∃k使得 M M M能在 O ( n k ) O(n^k) O(nk)的时间内接受 L ( M ) L(M) L(M),所以也存在一个常数 c c c使得 M M M至多在 c n k cn^k cnk步内接受 L ( M ) L(M) L(M)(根据大 O O O符号的定义)。对任意输入的串 ω \omega ω,图灵机 M ′ M' M′先模拟 M M M在 c n k cn^k cnk步以内的操作状态。在 c n k cn^k cnk步后,如果 M M M已经给出了答案(接受或拒绝),那么就输出 M M M给出的结果。如果 c n k cn^k cnk步后 M M M还没有接受或拒绝 L ( M ) L(M) L(M),那么它可能陷入了死循环,也可能需要更多的时间来计算。不过此时计算的结果一定是拒绝,因为我们的前提是 M M M可以在多项式时间内接受 L ( M ) L(M) L(M),如果此时计算出接受就违背了这个前提条件。不论如何, c n k cn^k cnk步后还没有结果一定意味着 M M M不接受 L ( M ) L(M) L(M),此时给出拒绝的结果就好了。因为 M ′ M' M′模拟 M M M的过程中需要额外的运行时间不会大于一个多项式因子,所以 M ′ M' M′运行的时间也是多项式时间,故 M ′ M' M′可以在多项式时间内判定 L ( M ) L(M) L(M)。
5.3 编码的影响
对一个抽象问题如何编码,对理解多项式时间是相当重要的。考虑判断质数的问题,采用朴素算法,对于正整数 k k k判断它是不是质数的复杂度为 O ( k ) O\left(\sqrt k\right) O(k)。如果采用二进制编码数 k k k,则输入长度 n = ⌊ lg k ⌋ + 1 n=\left\lfloor\lg k\right\rfloor+1 n=⌊lgk⌋+1,此时算法的运行时间为 O ( k ) = O ( 2 n 2 ) O\left(\sqrt k\right)=O\left(2^\frac n2\right) O(k)=O(22n),为指数级时间;但如果我们采用“一元编码”,用 k k k个 1 1 1表示整数 k k k,即 1 1 1表示 1 1 1, 11 11 11表示 2 2 2, ⋯ \cdots ⋯, 1111111 1111111 1111111表示 7 7 7,则运行时间为 O ( k ) = O ( n ) O\left(\sqrt k\right)=O\left(\sqrt n\right) O(k)=O(n),为多项式时间。因此,对于一个问题,指定不同的编码,求解的困难程度是不同的。不过,接下来我们将证明,如果不采用像一元编码这种代价高昂的编码,则问题的实际编码形式与其能否在多项式时间内求解的影响是微不足道的,例如用二进制和三进制表示整数对问题能否在多项式时间内解决没有任何影响。
多项式时间可计算的函数:对于一个函数 f : { 0 , 1 } ∗ → { 0 , 1 } ∗ f:\{0,1\}^*\to\{0,1\}^* f:{0,1}∗→{0,1}∗,如果存在一个多项式时间的算法 A A A,使得对于任意给定的输入 x ∈ { 0 , 1 } ∗ x\in\{0,1\}^* x∈{0,1}∗,都能产生输出 f ( x ) f(x) f(x),则称该函数是一个多项式时间可计算的函数。
编码的多项式相关性:对于某个问题实例集 I I I和编码 e 1 e_1 e1、 e 2 e_2 e2,如果存在两个多项式时间可计算的函数 f 12 f_{12} f12和 f 21 f_{21} f21满足对任意 i ∈ I i\in I i∈I,有 { f 12 ( e 1 ( i ) ) = e 2 ( i ) f 21 ( e 2 ( i ) ) = e 1 ( i ) \begin{cases}f_{12}(e_1(i))=e_2(i)\\f_{21}(e_2(i))=e_1(i)\end{cases} {f12(e1(i))=e2(i)f21(e2(i))=e1(i),则称这两种编码是多项式相关的(事实上还要求 f 12 f_{12} f12、 f 21 f_{21} f21将非实例映射到非实例,其中非实例是指在抽象问题的实例集中没有对应实例的二进制串)。也就是说, e 2 ( i ) e_2(i) e2(i)可以由一个多项式时间的算法根据编码 e 1 ( i ) e_1(i) e1(i)求出,反之亦然。例如,设 e 1 e_1 e1是二进制, e 2 e_2 e2是三进制,则二者互相转化是很简单的,只需要花费多项式时间。
下面的引理表明如果某一抽象问题的两种编码 e 1 e_1 e1和 e 2 e_2 e2是多项式相关的,则该问题本身是否是多项式时间可解的与选用 e 1 e_1 e1还是 e 2 e_2 e2编码无关。
引理 设 Q Q Q是定义在实例集 I I I上的抽象判定问题, e 1 e_1 e1和 e 2 e_2 e2是 I I I上多项式时间相关的编码,则 e 1 ( Q ) ∈ P e_1(Q)\in P e1(Q)∈P当且仅当 e 2 ( Q ) ∈ P e_2(Q)\in P e2(Q)∈P。
证明:只需证明一个方向(如 e 1 e_1 e1到 e 2 e_2 e2),因为两个方向是对称的。假定对于某一常数 k k k, e 1 ( Q ) e_1(Q) e1(Q)能在时间 O ( n ′ k ) O(n'^k) O(n′k)内求解;再假设对于任意问题实例 i i i和某个常数 c c c,可以在 O ( n c ) O(n^c) O(nc)的时间内将 e 2 ( i ) e_2(i) e2(i)转化为 e 1 ( i ) e_1(i) e1(i),其中 n = ∣ e 2 ( i ) ∣ n=|e_2(i)| n=∣e2(i)∣。因此对于问题 e 2 ( Q ) e_2(Q) e2(Q),可以先把输入 e 2 ( i ) e_2(i) e2(i)转化为 e 1 ( i ) e_1(i) e1(i),再在输入 e 1 ( i ) e_1(i) e1(i)上运行对问题 e 1 ( Q ) e_1(Q) e1(Q)的算法。对于 e 1 ( i ) e_1(i) e1(i),设 n ′ = ∣ e 1 ( i ) ∣ n'=|e_1(i)| n′=∣e1(i)∣,则问题可以在 O ( n ′ k ) O(n'^k) O(n′k)的时间内求解;又因为转换算法的输出为 e 1 ( i ) e_1(i) e1(i),输出的长度不可能超过运算的次数,所以 n ′ = ∣ e 1 ( i ) ∣ ≤ O ( n c ) n'=|e_1(i)|\le O(n^c) n′=∣e1(i)∣≤O(nc),于是求解关于 e 1 ( i ) e_1(i) e1(i)的问题所需是时间为 O ( n ′ k ) = O ( ∣ e 1 ( i ) ∣ k ) = O ( n c k ) O(n'^k)=O\left(|e_1(i)|^k\right)=O(n^{ck}) O(n′k)=O(∣e1(i)∣k)=O(nck),因为 c c c、 k k k均为常数,所以这个过程也是多项式时间的。
注意,这个引理的证明不能简单地用归约去理解,因为 e 1 ( Q ) e_1(Q) e1(Q)和 e 2 ( Q ) e_2(Q) e2(Q)中 n n n的含义发生了改变。
综上所述,对于一个问题的实例,无论用二进制还是三进制进行编码,对其“复杂性”,即能否在多项式时间内解决没有影响。但如果进行一元编码,其复杂性可能会变化。为了能够用一种与编码无关的方式进行描述,一般假定用合理的、简洁的方式对问题实例进行编码,除非我们有特殊说明。更确切地说,我们假定:
(1) 一个整数的编码与其二进制表示是多项式相关的;
(2) 一个有限集合的编码与其相应的括在括号中元素间用逗号隔开的列表的编码是多项式相关的(例如含有三个元素的集合
{
3
,
7
,
\{3,7,
{3,7,'a'
}
\}
}对应(3,7,97),即00101000000000110010110000000111001011000110000100101001);
我们将这种编码称为“标准编码”,从它就可以推导出其他数学对象(如元组、图和公式等) 的编码了。为方便起见,令
⟨
G
⟩
\langle G\rangle
⟨G⟩表示对象
G
G
G的标准编码。
在进行下面的讨论时,我们一般采用标准编码的二进制串来对问题的实例进行编码。同时,只要采用与标准编码多项式相关的编码,就可以忽略抽象问题与具体问题之间的差别,因为选取哪一种编码(只要这种编码代价不高)对这个问题能否在多项式时间内解决其实没有影响。
在讨论到这里之前,你可能对《Primes Is in P》这篇论文有疑惑,因为判断质数这个问题本身就可以在 O ( n ) O\left(\sqrt n\right) O(n)的时间内解决,它是 P \bold P P问题不是显而易见的吗?为什么要发一篇论文来证明呢?现在我们发现,这个问题的实例的编码的长度是 ⌊ log n ⌋ + 1 \left\lfloor\log n\right\rfloor+1 ⌊logn⌋+1,所以说它是 P \bold P P问题,其实是说它的时间复杂度是 log n \log n logn的函数。不过对于像求 n n n个数最小值的问题,虽然编码长度也不是 n n n,但因为每个数的编码长度都是有限的,比方说不超过 k k k,那么整体的编码长度就不超过 O ( k n ) O(kn) O(kn),所以讨论这个问题是不是 P \bold P P问题的时候考虑时间复杂度是 n n n的函数还是编码长度的函数并没有影响。
6. NP问题
6.1 基于验证关系(checking relation/verifier)的定义
验证关系:设有有穷字母表 Σ \Sigma Σ和 Σ 1 \Sigma_1 Σ1,则验证关系是一个从 Σ ∗ \Sigma^* Σ∗到 Σ 1 ∗ \Sigma_1^* Σ1∗的二元关系 R ⊆ Σ ∗ × Σ 1 ∗ R\subseteq \Sigma^*\times\Sigma_1^* R⊆Σ∗×Σ1∗。设字符 # ∉ Σ \#\notin\Sigma #∈/Σ。我们给每一个验证关系 R R R关联一个 Σ ∪ Σ 1 ∪ { # } \Sigma\cup\Sigma_1\cup\{\#\} Σ∪Σ1∪{#}上的语言 L R L_R LR,它的定义是 L R = { w # y ∣ R ( w , y ) } L_R=\{w\#y|R(w,y)\} LR={w#y∣R(w,y)}。如果 L R ∈ P L_R\in\bold P LR∈P,我们就称 R R R是多项式时间的。
N P \bold{NP} NP:字符集 Σ \Sigma Σ上的语言 L L L属于 N P \bold{NP} NP,当且仅当存在 k ∈ N k\in\mathbb N k∈N以及一个多项式时间的验证关系 R R R使得 ∀ w ∈ Σ ∗ \forall w\in\Sigma^* ∀w∈Σ∗,都有 w ∈ L ⟺ ∃ y ( ∣ y ∣ ≤ ∣ w ∣ k ∧ R ( w , y ) ) w\in L\Longleftrightarrow\exists y\left(|y|\le|w|^k\land R(w,y)\right) w∈L⟺∃y(∣y∣≤∣w∣k∧R(w,y)),其中 ∣ w ∣ |w| ∣w∣和 ∣ y ∣ |y| ∣y∣分别是 w w w和 y y y的长度。
这句天书一样的话到底是什么意思呢?考虑子集和问题,即对于一个集合判断其有没有一个非空子集,使得该子集的所有元素之和和为 0 0 0的问题。例如对于集合 { − 7 , − 3 , − 2 , 1 , 5 , 9 } \{-7,-3,-2,1,5,9\} {−7,−3,−2,1,5,9},答案是肯定的,因为它的一个子集 { − 3 , − 2 , 5 } \{-3,-2,5\} {−3,−2,5}的和 ( − 3 ) + ( − 2 ) + 5 = 0 (-3)+(-2)+5=0 (−3)+(−2)+5=0。直接解决这个问题固然很困难,因为可能需要枚举其所有非空子集,再检查每个子集的和,复杂度高达 O ( n 2 n ) O\left(n2^n\right) O(n2n)。不过对于一个子集,我们可以很容易地检查它的和是不是 0 0 0,这显然是可以再多项式时间内完成的。
在这个问题中,验证关系 R R R就是用来判断一个子集的和是不是 0 0 0的。如果采用二进制编码,则 Σ = Σ 1 = { 0 , 1 } \Sigma=\Sigma_1=\{0,1\} Σ=Σ1={0,1}, w w w是一个集合 W W W的编码(比如 { − 7 , − 3 , − 2 , 1 , 5 , 9 } \{-7,-3,-2,1,5,9\} {−7,−3,−2,1,5,9}), y y y是一个子集 Y Y Y的编码(比如 { − 3 , − 2 , 5 } \{-3,-2,5\} {−3,−2,5}), R ( w , y ) R(w,y) R(w,y)代表 Y Y Y是 W W W的子集且 Y Y Y的和为 0 0 0。字符 # \# #的作用仅仅是隔开 w w w和 y y y,使不至于混淆。因为判断 Y Y Y是 W W W的子集以及判断 Y Y Y的和为 0 0 0都可以在多项式时间内完成,所以语言 L R ∈ P L_R\in\bold P LR∈P。事实上,二元关系 R R R所做的事情是一个图灵机 M R M_R MR完成的,它的输入是 w # y w\#y w#y,且运行有限步就可以给出结果。这个图灵机所扮演的角色就是验证问题的一个解是正确的。
我们再看 N P \bold{NP} NP的定义。语言 L L L包含了所有满足条件的集合的编码,对 L L L的所有元素问题的答案都是“是”。 w ∈ L ⟺ ∃ y ( ∣ y ∣ ≤ ∣ w ∣ k ∧ R ( w , y ) ) w\in L\Longleftrightarrow\exists y\left(|y|\le|w|^k\land R(w,y)\right) w∈L⟺∃y(∣y∣≤∣w∣k∧R(w,y))的意思就是说对于一个 L L L中的元素 w w w,一定存在 y y y,使得 R ( w , y ) R(w,y) R(w,y)(即 y y y所代表的集合 Y Y Y是 w w w所代表的集合 W W W的子集且 Y Y Y的和为 0 0 0)且 ∣ y ∣ ≤ ∣ w ∣ k |y|\le|w|^k ∣y∣≤∣w∣k,其中 k k k是一个常数。 y y y其实就是用来验证 w ∈ L w\in L w∈L的,我们称其为证明(certificate/witness)。而 ∣ y ∣ ≤ ∣ w ∣ k |y|\le|w|^k ∣y∣≤∣w∣k限制了 y y y的长度只能是 w w w的多项式函数,这样做的意义是使得 L R L_R LR中的元素 w # y w\#y w#y的长度也是 w w w的多项式函数,从而使得我们说 M R M_R MR是在多项式时间内运行指的是运行时间是 ∣ w ∣ |w| ∣w∣的多项式函数,而不仅仅是 ∣ w # y ∣ |w\#y| ∣w#y∣的多项式函数。
显然 P ⊆ N P \bold P\subseteq\bold{NP} P⊆NP。这是因为对于每个字符集 Σ \Sigma Σ上的语言 L L L,若 L ∈ P L\in\bold P L∈P,那么我们可以定义多项式时间的验证关系 R ⊆ Σ ∗ × Σ ∗ R\subseteq\Sigma^*\times\Sigma^* R⊆Σ∗×Σ∗为: ∀ w , y ∈ Σ ∗ \forall w,y\in\Sigma^* ∀w,y∈Σ∗, R ( w , y ) ⟺ w ∈ L R(w,y)\Longleftrightarrow w\in L R(w,y)⟺w∈L。因为判定 w ∈ L w\in L w∈L是多项式时间的,所以 R R R也是多项式时间的。可以这样理解:对于 P \bold P P类问题,只需要把原问题解决了,证明了 w ∈ L w\in L w∈L,那肯定存在证据 y y y能够验证 w ∈ L w\in L w∈L。至于这个 y y y到底是什么,我们不关心,我们只知道它肯定存在。
6.2 基于非确定型图灵机(Nondeterministic Turing Machine, NTM)的定义
6.2.1 非确定型图灵机
前面我们介绍的图灵机是确定型图灵机(Deterministic Turing Machine, DTM),它处于每一格局后下一格局的状态是确定的。但非确定型图灵机则不然,每一格局的下一个格局可能有多个,如图所示:

下面给出NTM的形式化定义。
非确定型图灵机(NTM):是一个有序六元组
M
=
(
Q
,
Σ
,
q
0
,
B
,
A
,
δ
)
M=(Q,\Sigma,q_0,B,A,\delta)
M=(Q,Σ,q0,B,A,δ),其中:
(1)
Q
Q
Q是非空有穷的状态集合;
(2)
Σ
\Sigma
Σ是非空有穷的带字母表;
(3)
q
0
∈
Q
q_0\in Q
q0∈Q是初始状态;
(4)
B
∈
Σ
B\in\Sigma
B∈Σ是空白符;
(5)
A
⊆
Q
A\subseteq Q
A⊆Q是接受状态集合;
(6)
δ
⊆
(
(
Q
−
A
)
×
Σ
)
×
(
Q
×
Σ
×
{
L
,
S
,
R
}
)
\delta\subseteq((Q-A)\times\Sigma)\times(Q\times\Sigma\times\{L,S,R\})
δ⊆((Q−A)×Σ)×(Q×Σ×{L,S,R})是一个二元关系,称为转移关系,指示着图灵机将做什么样的动作;
L
L
L代表带头向左移,
S
S
S代表原地不动,
R
R
R代表向右移。
与一般的图灵机(DTM)不同,NTM的 δ \delta δ是一个二元关系而非函数,因为它的每一个输入可能有多个输出。
接受字符串:对于一个输入字符串 ω \omega ω,只要有一种计算的路径可以到达接受状态,就称 M M M接受 ω \omega ω。如上图中,虽然最后接受状态和拒绝状态都有可能到达,但因为有一条路径接受可以到达状态,所以该NTM接受这个输入字符串。
DTM是NTM的特殊情况。
6.2.2 利用NTM对NP的定义
定理 N P = { L ∣ 存在非确定型图灵机 M ,使得 M 能在多项式时间内判定任意字符串 w ∈ { 0 , 1 } ∗ 属于 L } \bold{NP}=\{L|\text{存在非确定型图灵机}M\text{,使得}M\text{能在多项式时间内判定任意字符串}w\in\{0,1\}^*\text{属于}L\} NP={L∣存在非确定型图灵机M,使得M能在多项式时间内判定任意字符串w∈{0,1}∗属于L}。
证明:需要证明这个定义和基于验证关系的定义是等价的。
(1) 设非确定型图灵机 M M M可以在多项时间内判定语言 L L L,且判定所需时间为 p ( n ) p(n) p(n),其中 p p p是多项式。那么对于任意 w ∈ L w\in L w∈L,我们需要给出一个证明,这样才能说明 L ∈ N P L\in\bold{NP} L∈NP。因为 w w w属于 L L L,所以 M M M存在一个计算序列使得它以 w w w作为输入可以进入接受状态。那么该计算序列就可以作为 w w w的一个证明,且其长度为 p ( ∣ w ∣ ) p(|w|) p(∣w∣)。这个证明实际上包含了 M M M在每一步的决策过程(即往哪边走)。有了决策过程,我们就可以用确定型图灵机 M ′ M' M′以 ω \omega ω作为输入在多项式时间内走一遍这个过程,以此来验证 w w w能否使 M M M进入接受状态。换言之,我们的验证关系 R ( w , y ) R(w,y) R(w,y)就是定义如下: R ( w , y ) ⟺ M ′ 以 w 作为输入、 y 作为证明(即 M 的计算序列)能否进入接受状态 R(w,y)\Longleftrightarrow M'\text{以}w\text{作为输入、}y\text{作为证明(即}M\text{的计算序列)能否进入接受状态} R(w,y)⟺M′以w作为输入、y作为证明(即M的计算序列)能否进入接受状态。这样就可以说明 L L L符合 N P \bold{NP} NP问题的定义。
(2) 现在我们假设 L ∈ N P L\in\bold{NP} L∈NP,需要构造多项式时间内运行的非确定型图灵机 M M M来判定 L L L。因为 L ∈ N P L\in\bold{NP} L∈NP,所以存在验证关系 R R R及其对应的确定型图灵机 M R M_R MR来判断对于输入 w ∈ L w\in L w∈L和证明 y y y,是否有 R ( w , y ) R(w,y) R(w,y)成立。我们要针对这个验证关系构造非确定型图灵机 M M M。
《计算复杂性:现代方法》中给出的构造是: M M M利用它能进行非确定型选择的能力写出一个长为 p ( ∣ w ∣ ) p(|w|) p(∣w∣)的位串 y y y,这个位串 y y y包含了它的决策过程,即它每一步向哪边走。然后, M M M运行 M R M_R MR来判断 y y y是否为 w w w的有效证明。如果是,则 M M M进入接受状态;否则进入拒绝状态。显然, M M M在 w w w上进入接受状态当且仅当存在 ω \omega ω的有效证明。因为 y y y的长度就是 M M M做决定的次数,或者说运行的步数,所以 M M M是在多项式时间内运行的。
我认为这种解释过于晦涩,在此给出自己的解释:可以把非确定性图灵机想象成一个可以“并发”的机器。我们这样构造 M M M:对于输入 w w w, M M M可以检查所有可能的证明 y y y是否满足 R ( w , y ) R(w,y) R(w,y)(可以枚举所有长度满足 R R R要求的 0 , 1 0,1 0,1串,对于每个串调用关系 R R R进行验证);这个过程只会花费检查一个 y y y的时间,因为 M M M是“并发性”的,是“不确定”的,一次可以转移多个状态,就像递归的时候每次向下递归同时进行,最终只花费一趟递归的时间。这样,因为 ∃ k \exists k ∃k使得 ∣ y ∣ ≤ ∣ w ∣ k |y|\le|w|^k ∣y∣≤∣w∣k(见基于验证关系的定义),所以枚举 y y y的过程也可以在多项式时间内完成,而调用 R R R也只需要花费多项式时间,所以花费的总时间是多项式时间。
7. NP完全性
归约的形式化定义:设 L ∈ { 0 , 1 } ∗ L\in\{0,1\}^* L∈{0,1}∗, L ′ ∈ { 0 , 1 } ∗ L'\in\{0,1\}^* L′∈{0,1}∗。若存在多项式时间内可计算的函数 f : { 0 , 1 } ∗ → { 0 , 1 } ∗ f:\{0,1\}^*\to\{0,1\}^* f:{0,1}∗→{0,1}∗使得 ∀ x ∈ { 0 , 1 } ∗ \forall x\in\{0,1\}^* ∀x∈{0,1}∗, x ∈ L ⟺ f ( x ) ∈ L ′ x\in L\Longleftrightarrow f(x)\in L' x∈L⟺f(x)∈L′,则称 L L L可在多项式时间内归约到 L ′ L' L′,记作 L ≤ p L ′ L\le_p L' L≤pL′。一般意味着 L L L不难于 L ′ L' L′。
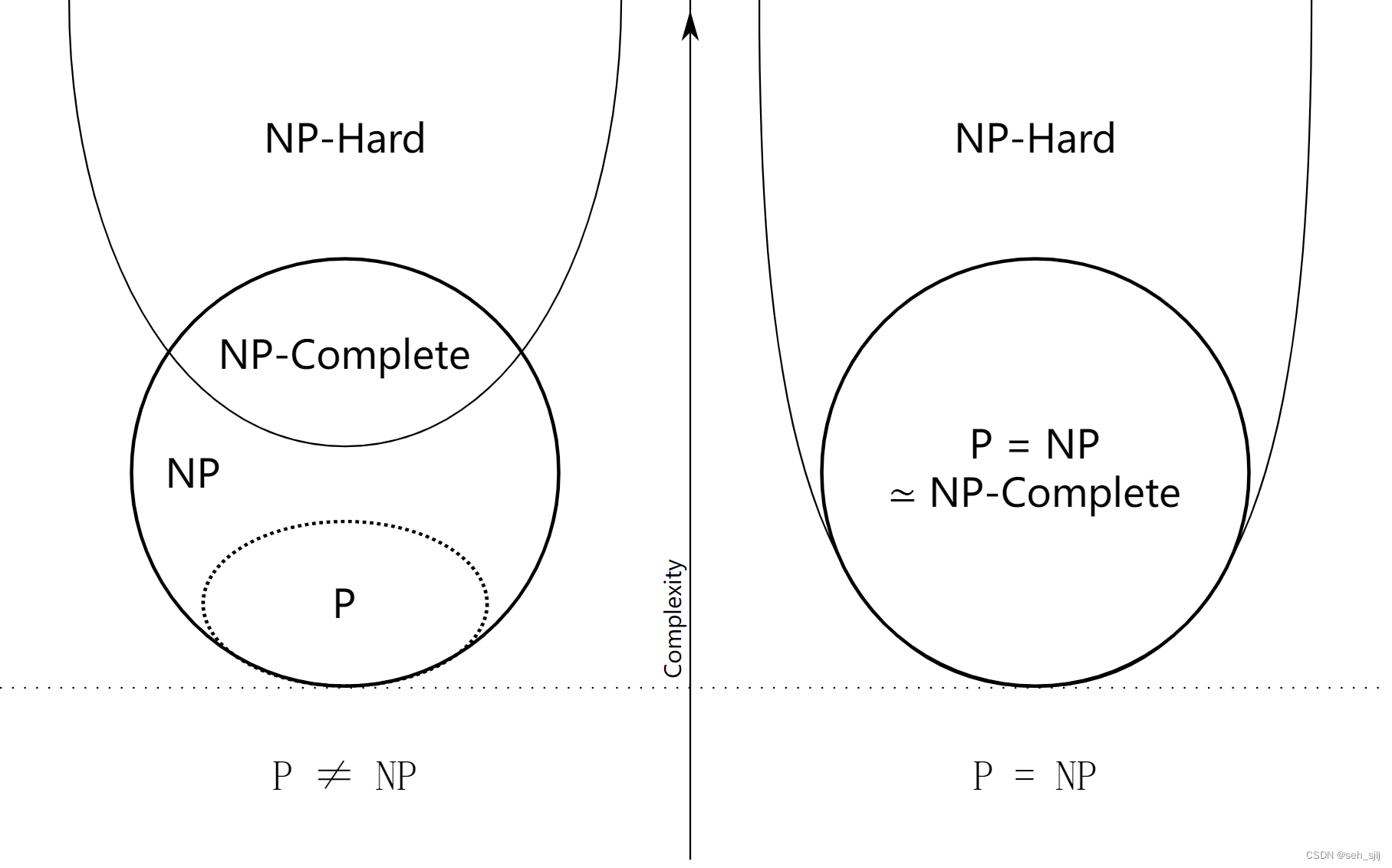
NP难和NP完全: ∀ L ∈ N P \forall L\in\bold{NP} ∀L∈NP, L ≤ p L ′ L\le_p L' L≤pL′,则称 L ′ L' L′是 N P \bold{NP} NP难的(NP-Hard)。若 L ′ L' L′是 N P \bold{NP} NP难的且 L ′ ∈ N P L'\in\bold{NP} L′∈NP,则称 L ′ L' L′是 N P \bold{NP} NP完全(NP-Complete)的。
P \bold P P、 N P \bold{NP} NP、 N P \bold{NP} NP难、 N P \bold{NP} NP完全的关系取决于 P = N P \bold{P}=\bold{NP} P=NP是否成立,见下图:
 下面要介绍的库克-列文定理发现了前两个
N
P
\bold{NP}
NP完全问题:SAT和3-SAT。请点击布尔表达式可满足性问题(SAT)与库克-列文定理(下)继续阅读。
下面要介绍的库克-列文定理发现了前两个
N
P
\bold{NP}
NP完全问题:SAT和3-SAT。请点击布尔表达式可满足性问题(SAT)与库克-列文定理(下)继续阅读。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)