最强无套路脚本,公开免费文档下载
你好,我是坚持分享干货的 EarlGrey,翻译出版过《Python编程无师自通》、《Python并行计算手册》等技术书籍。如果我的分享对你有帮助,请关注我,一起向上进击。脚本地址:https://greasyfork.org/zh-CN/scripts/486211这是一个用于 Tampermonkey 或其他支持用户脚本的浏览器扩展的油猴脚本。看到论坛经常有小伙伴们需要下载一些免费文档,但是相
你好,我是坚持分享干货的 EarlGrey,翻译出版过《Python编程无师自通》、《Python并行计算手册》等技术书籍。
如果我的分享对你有帮助,请关注我,一起向上进击。
脚本地址:https://greasyfork.org/zh-CN/scripts/486211
这是一个用于 Tampermonkey 或其他支持用户脚本的浏览器扩展的油猴脚本。
看到论坛经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决您的烦恼而诞生,尽可能做到自动化。
安装
安装 Tampermonkey 浏览器扩展。
点击 脚本链接 或手动复制脚本代码。
在 Tampermonkey 中创建一个新脚本,将代码粘贴到编辑器中并保存。
原理说明
一般在线文档有以下几种方式展示在线文档预览功能:
将图片绘制成画布呈现
将二进制数据绘制画布
多种图片拼接页面渲染
直接图片渲染页面
所以该脚本只是将画布或图片在浏览器渲染时进行下载拼接成PDF文件,无法下载原始文件,并非破解,只要是你浏览器可以看到就可以下载。_宗旨就是你能看到多少,就能下载多少。_
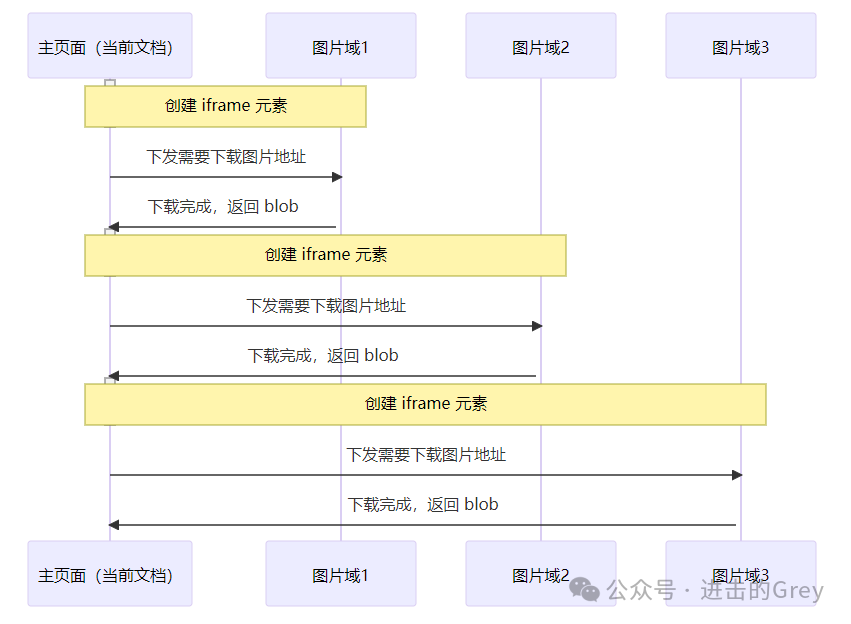
核心技术点解决一个文档由多个域名提供图片,解决跨域问题。
以上两个文档库中的文档,大部分文档都是来自好几个域名,并且有跨域问题,也就是说如果在当前页面通过JavaScript直接下载图片会产生跨域问题,这也是为什么网上其他脚本针对这两个网站只能提供图片下载地址,不能直接下载的根本原因。
解决跨域最简单的办法就是同源,在脚本中动态添加 iframe元素,通 iframe 内联元素框架打开当前图片所在域名,将需要下载的图片当 iframe 页面内下载,再通过 postMessage 方法将Blob 数据传回主页面进行保存。
当然也许有其他更好的办法解决,此脚本只是基于JavaScript进行处理,不借助额外第三方工具(下载,合并等exe文件)处理为前提。
平台/功能
| 📖 支持平台 | 状态 | 自动预览 | 停止预览 | 下载图片 | 下载PDF | 获取文本 | 打印PDF | 获取地址 |
|---|---|---|---|---|---|---|---|---|
| 百度文库 | ✅ | ✅ | ✅ | ✔️部分 | ✔️部分 | ✔️ 部分 | ✅ | ✔️ 部分 |
| 原创力文档 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 人人文库 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 360文库 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 豆丁网 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| 豆丁建筑 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| 道客巴巴 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| MBA智库 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ |
| ➡️得力文库 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 七彩学科 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 金锄头 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 爱问文库 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 蚂蚁文库 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 读根网 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ❌ |
| 搜弘文库 | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 微传网⬅️ | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 淘豆网 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
1->2->3 执行优先级
| 功能 | 解释说明 |
|---|---|
| 状态位 | 各个功能执行状态,当前进度。 |
| (1)自动预览 | 就是替你滚动页面,让所有页面进入可视范围内。百度文库必须使用自动预览功能,其他手动也行。 |
| (2)停止预览 | 顾名思义就是停下来,别动了 |
| (3)下载图片 | 把所有图片打包成压缩包下载,方便你们后续二次处理,例如:OCR识别 |
| (3)下载PDF | 把所有图片合并导出 PDF 文件 |
| (3)获取文本 | 文本内容 |
| (3)打印PDF | 浏览器本身打印功能,Ctrl+P 键也可以拉起来,“目标打印机处”点击另存为PDF即可 |
| (3)获取地址 | 把所有图片地址导出来自己处理,不一定有数据取决于文档类型 |
注意事项
F5刷新能解决大部分问题功能按钮要依次执行不要到处乱点,需等待上一个功能执行完成再执行下一个功能
蓝色箭头开始和结束内包含的平台同类型平台,可直接下载无需预览。
zip js库可能有时加载失败可打开脚本替换// 原始地址 @require https://cdn.jsdelivr.net/npm/@zip.js/zip.js@2.7.34/dist/zip.min.js // 新地址 @require https://cdn.dtking.cn/zip.min.js
| 平台 | 注意事项 |
|---|---|
| 百度文库 | PDF 格式分为:可编辑,不可编辑,图片格式,下载PDF只支持图片格式。当遇到下载空白页时使用打印PDF功能。可编辑PDF 文件可以点击编辑文档,再自动预览打印PDF,这样就得到了一个可以复制内容的PDF文件。支持复制文本内容和全局文档复制功能(_左上角展示当前复制内容文本框_)。 text类型点击自动预览后点击获取全文即可,可以使用过打印。 其他类型文件自行探索大部分都支持。 word/PDF 自动预览后就不能复制文本了,若要复制文本就不要执行自动预览。 可编辑文档优先使用可编辑下预览 |
| 原创力文档 | PPT 下载过程中如果点击停止预览后,想要继续预览全文需要刷新页面从头开始。全屏预览不要缩小浏览器。 |
| 人人文库 | 从侧边栏“相似文档”点击切换文档可能无法下载,需要 F5 刷新后就可以了 |
| 豆丁网/豆丁建筑 | 想要获取更多文章内容需要登录自己账号,默认只展示一部分内容。 |
| 道客巴巴 | 没啥注意的 |
- EOF -
文章已经看到这了,别忘了在右下角点个“赞”和“在看”鼓励哦~
推荐阅读 点击标题可跳转
回复下方「关键词」,获取优质资源
回复关键词「 pybook03」,领取进击的Grey与小伙伴一起翻译的《Think Python 2e》电子版
回复关键词「书单02」,领取进击的Grey整理的 10 本 Python 入门书的电子版
👇关注我的公众号👇
告诉你更多细节干货

欢迎围观我的朋友圈
👆每天更新所想所悟

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)