大规模语言模型--LLaMA 家族
LLaMA 模型集合由 Meta AI 于 2023 年 2 月推出, 包括四种尺寸(7B 、13B 、30B 和 65B)。由于 LLaMA 的 开放性和有效性, 自从 LLaMA 一经发布, 就受到了研究界和工业界的广泛关注。LLaMA 模型在开放基准的各 种方面都取得了非常出色的表现, 已成为迄今为止最流行的开放语言模型。大批研究人员通过指令调整或持续 预训练扩展了 LLaMA 模型。特别需
LLaMA 模型集合由 Meta AI 于 2023 年 2 月推出, 包括四种尺寸(7B 、13B 、30B 和 65B)。由于 LLaMA 的 开放性和有效性, 自从 LLaMA 一经发布, 就受到了研究界和工业界的广泛关注。LLaMA 模型在开放基准的各 种方面都取得了非常出色的表现, 已成为迄今为止最流行的开放语言模型。大批研究人员通过指令调整或持续 预训练扩展了 LLaMA 模型。特别需要指出的是, 指令调优 LLaMA 已成为一种主要开发定制专门模型的方法, 由于相对较低的计算成本。
LLaMA是在训练一系列模型中, 通过训练比通常来说更多的 tokens,在不同的推理预算下达到尽可能好的性能而最终产生的模型。其参数范围为 70 亿(7B)到 650 亿(65B)。LLaMA 的预训练数据包含:CommonCrawl, C4 ,Github ,Wikipedia ,Books ,ArXiv,以及 StackExchange。
LLaMA 也使用了基本的 transformer 架构,并利用了以前的语言模型提出的各种改进:
-
预归一化为了提升训练的稳定性, LLaMA 使用了 RMSNorm将每个 transformer 子层的输入归一化而 不是归一化输出。
-
SwiGLU 激活函数将 ReLU 激活函数替换为 SwiGLU 激活函数,维度变为 2/3 * 4d 而不是 PaLM 中的 4d。
-
旋转嵌入将每层的绝对位置嵌入替换为旋转位置嵌入(RoPE)。
另外, 该模型使用了 AdamW 优化器进行训练。其超参数为 β 1 = 0.9 ,β2 = 0.95。使用余弦学习率调 度, 使最终学习率为最大学习率的 10%。权重衰减为 0.1,梯度裁剪为 1.0,使用了 2000 个预热步骤, 而且根据 模型大小调整学习率和批次处理大小。
LLaMA 使用了两种方法提高模型的训练速度。首先是使用 causal 多头注意力来减少内存使用量和运行时 间。这种方法可以通过 xformers 库实现。这种效果是由于它不存储注意力权重以及它不计算被掩盖的 key 和 query 的分数而产生的。接着是通过检查点减少向后传播期间重新计算的激活量。这是通过手动实现transformer 的向后传播函数来实现的。为了充分利用这个优化, 需要通过模型和序列并行来减少模型的内存使用。另外, 使 用 all_reduce 尽可能地重叠激活函数计算和GPU 之间通过网络的通信。
从结论上来说, LLaMA- 13B 的性能比 GPT-3 更强, 但模型大小是其十分之一。而 LLaMA-65B 的表现可以 与 Chinchilla-70B 和 PaLM-540B 竞争。与以前的模型不同, LLaMA 展示了仅使用公共数据集也能达到最先进的性能。
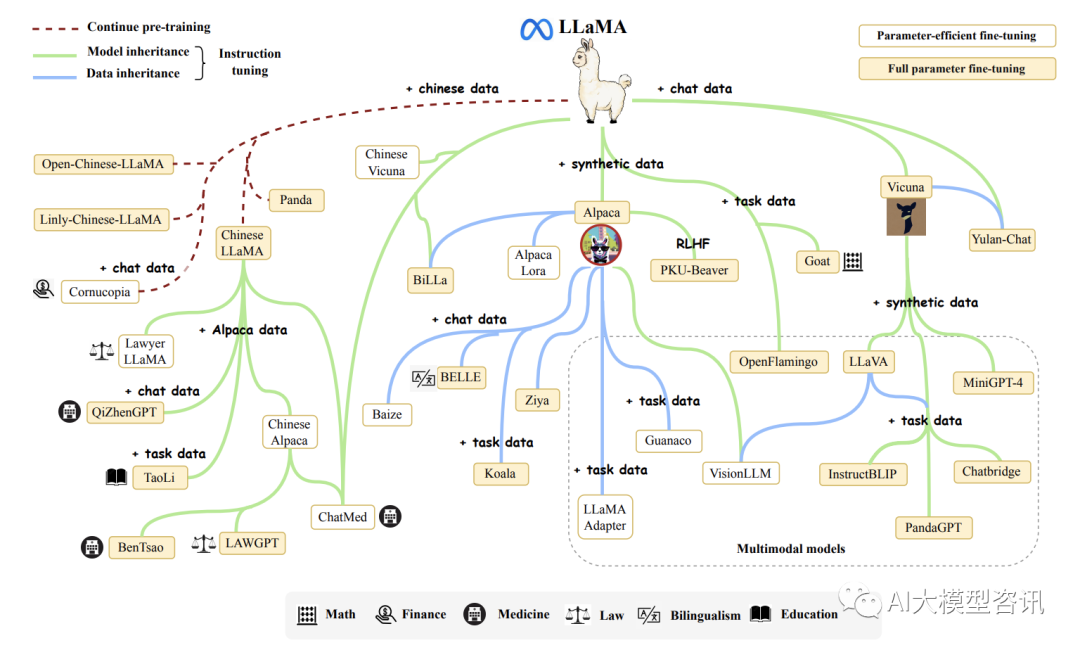
为有效适应非英语语言的 LLaMA 模型, 通常需要扩展原来的词汇(训练语料库主要是英语) 或使用指令 或数据对其进行微调目标语言。在这些扩展模型中, 斯坦福大学发布的 Alpaca 是第一个基于 LLaMA (7B) 进行 指令微调的开放模型。由 52K 训练使用 text-davinci-003 通过 selfinstruct 生成的指令遵循演示。指令名为Alpaca- 52K 的数据和训练代码在后续工作中被广泛采用, 例如 AlpacaLoRA 、LoRA 、Koala 和 BELLE。此外, Vicuna [120] 是另一种流行的 LLaMA 变体, 经过训练根据从 ShareGPT 16 收集的用户共享对话。由于其卓越的性能和 可用性 LLaMA 模型家族, 许多多模态模型将它们作为基础语言模型, 以实现强大的语言理解和生成能力。比 较的与其他变体相比, 骆马毛在多式联运中更受青睐语言模型, 这导致了各种流行模型的出现, 包括 LLaVA、MiniGPT4、InstructBLIP 和 PandaGPT。LLaMA 的发布极大地推进了大规模语言模型的研究进展。在下图中展 示了一个 LLaMA 简短的进化图。

LLaMA 简短的进化图
预训练数据
LLaMa 预训练数据大约包含 1.4T tokens,7B 和 13B 版本使用了 1T 的 tokens 进行训练, 33B 和 65B 的版本 使用了 1.4T 的 tokens 进行训练。对于绝大部分的训练数据, 在训练期间模型只见到过 1 次, Wikipedia 和 Books 这两个数据集见过 2 次。下表所示是 LLaMa 预训练数据的占比和分布, 其中包含了 CommonCrawl 和 Books 等 不同域的数据。

LLaMA 的预训练数据的占比和分布
-
English CommonCrawl [67%]:对五个 CommonCrawl 数据集进行预处理, 时间跨度从 2017 年到 2020 年, 使 用 CCNet 流水线。该过程在行级别进行数据去重, 使用fastText 线性分类器进行语言识别, 以删除非英语页面, 并使用 n-gram 语言模型过滤低质量内容。此外, 还训练了一个线性模型, 用于将页面分类为 Wikipedia 中的引 用页面与随机抽样页面,并丢弃未被分类为引用的页面。
-
C4 [15%] 。C4 的预处理还包括去重和语言识别步骤:与 CCNet 的主要区别在于质量过滤, 这主要依赖于标 点符号的存在或网页中的词语和句子数量等启发式方法。
-
Github [4.5%]。使用 Google BigQuery 上可用的公共 GitHub 数据集。只保留了在Apache、BSD 和 MIT 许可 下发布的项目。此外, 使用基于行长度或字母数字字符比例的启发式方法过滤低质量文件, 并使用正则表达式 删除了诸如头文件之类的样板文件。最后,对生成的数据集进行了文件级别的去重,使用完全匹配的方法。
-
Wikipedia [4.5%]。添加了截至 2022 年 6 月至 8 月的 Wikipedia 数据, 涵盖 20 种语言。处理数据以去除超链 接、评论和其他格式样板。
-
Gutenberg and Books3 [4.5%]。添加了两个书的数据集, 分别是 Gutenberg 以及 ThePile (训练 LLM 的常用公 开数据集) 中的 Book3 部分。处理数据时执行重复数据删除,删除内容重叠超过 90。
-
ArXiv [2.5%]。处理了 arXiv Latex 文件, 以添加科学数据到数据集中。移除了第一节之前的所有内容, 以及 参考文献。还移除了.tex 文件中的注释,并且内联展开了用户编写的定义和宏,以增加论文之间的一致性。
-
Stack Exchange [2%]。作者添加了 Stack Exchange,这是一个涵盖各种领域的高质量问题和答案网站, 范围 从计算机科学到化学。作者从 28 个最大的网站保留数据,从文本中删除 HTML 标签并按分数对答案进行排序。
模型架构
LLaMA 的模型架构与 GPT 相同, 采用了 causal decoder-only 的 transformer 模型结构, 如下图所示, 不过 也利用了随后提出的各种改进,这些改进也在不同模型(如 PaLM)中得到了应用,模型的主要特点为:
-
前置的 RMSNorm,为了提升训练的稳定性,没有使用传统的 post layer norm,而是使用了 pre layer Norm。
-
在 Q 、K 上使用RoPE 旋转式位置编码。
-
MLP 表达式 down(up(x)) × SwiGLU (gate(x)) ,其中 down, up, gate 都是线性层。
-
V2 的文本输入长度为 4096,使用了 Group Query Attention。
-
LLaMA 可以将更早的 K 、V 拼接到当前 K 、V 前面,可以用Q 查找更早的信息。

LLaMA 的模型架构示意图
Pre-normalization
受到 GPT3 的启发, 为了提高训练稳定性, LLaMa 对每个 Transformer 子层的输入进行归一化, 而不是对输 出进行归一化, LLaMa 使用了 RMSNorm 归一化函数。
要讲 Layer Normalization,先讲讲为什么要做 Normalization,Normalization 通过将一部分不重要的信息损失 掉, 以此来降低拟合难度以及过拟合的风险, 从而加速模型收敛。其目的是让分布稳定下来(降低各个维度数 据的方差)。
-
不同的特征具有不同数量级的数据, 它们对线性组合后的结果的影响所占比重就很不相同, 数量级大的特 征显然影响更大。做 Normalization 可以协调在特征空间上的分布,更好地进行梯度下降;
-
在神经网络中, 特征经过线性组合后, 还要经过激活函数, 如果某个特征数量级过大, 在经过激活函数时, 就会提前进入它的饱和区间(比如 sigmoid 激活函数), 即不管如何增大这个数值, 它的激活函数值都在 1 附近, 不会有太大变化, 这样激活函数就对这个特征不敏感。在神经网络用 SGD 等算法进行优化时, 不同 量纲的数据会使网络失衡,很不稳定。
Normalization 的方式主要包括以下几种方法:BatchNorm (2015 年)、LayerNorm (2016 年)、InstanceNorm (2016 年)、 GroupNorm (2018 年)。
-
BatchNorm:batch 方向做归一化, 算 NHW 的均值, 对小 batchsize 效果不好;BN 主要缺点是对 batchsize 的 大小比较敏感,由于每次计算均值和方差是在一个 batch 上,所以如果 batchsize 太小,则计算的均值、方差不足以代表整个数据分布;
-
LayerNorm:channel 方向做归一化,算 CHW 的均值,主要对 RNN 作用明显;
-
InstanceNorm:一个 channel 内做归一化, 算 H*W 的均值, 用在风格化迁移;因为在图像风格化中, 生成 结果主要依赖于某个图像实例, 所以对整个 batch 归一化不适合图像风格化中, 因而对 HW 做归一化。可 以加速模型收敛,并且保持每个图像实例之间的独立。
-
GroupNorm:将 channel 方向分 group,然后每个 group 内做归一化, 算 (C//G)HW 的均值;这样与batchsize 无关,不受其约束。在 batchsize<16 的时候, 可以使用这种归一化。
-
SwitchableNorm:将 BN 、LN 、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
Batch Normalization 存在的一些问题:即不适用于什么场景。BN 在 mini-batch 较小的情况下不太适用。BN 是对整个 mini-batch 的样本统计均值和方差, 当训练样本数 很少时,样本的均值和方差不能反映全局的统计分布信息,从而导致效果下降。BN 无法应用于 RNN。RNN 实际是共享的 MLP,在时间维度上展开, 每个 step 的输出是 (bsz, hidden_dim)。由于不同句子的同一位置的分布大概率是不同的, 所以应用 BN 来约束是没意义的。而 BN 应用在 CNN 可 以的原因是同一个 channel 的特征图都是由同一个卷积核产生的。
BN 是对batch 的维度去做归一化, 也就是针对不同样本的同一特征做操作。LN 是对hidden 的维度去做归 一化, 也就是针对单个样本的不同特征做操作。因此 LN 可以不受样本数的限制。具体而言, BN 就是在每个维 度上统计所有样本的值, 计算均值和方差;LN 就是在每个样本上统计所有维度的值, 计算均值和方差(注意, 这里都是指的简单的 MLP 情况, 输入特征是(bsz,hidden_dim))。所以 BN 在每个维度上分布是稳定的, LN 是 每个样本的分布是稳定的。
常规的 Layer Normalization:

式中, gi 和 bi 是 Layer Normalization 的 scale (初始化为 1)和 shift 参数, µ 和 σ 的计算如下式所示:

而 RMSNorm,相当于是去掉了 µ 这一项。

RMSNorm 在 HuggingFace Transformer 库中代码实现如下所示:

SwiGLU 激活函数
受 PaLM 的启发, LLaMa 使用SwiGLU 激活函数替换 ReLU 以提高性能, 维度从 4d 变为 2/3 * 4d 。SwiGLU 是 2019 年提出的新的激活函数, 它结合了SWISH 和 GLU 两种者的特点。SwiGLU 主要是为了提升 Transformer 中 的 FFN(feed-forward network) 层的实现。FFN 通常有两个权重矩阵, 先将向量从维度 d 升维到中间维度 4d,再 从 4d 降维到d。而使用 SwiGLU 激活函数的 FFN 增加了一个权重矩阵, 共有三个权重矩阵, 为了保持参数量一 致,中间维度采用了2/3 * 4d ,而不是 4d。

其中, σ(x) 是 Sigmoid 函数。下图给出了 Swish 激活函数在参数 β 不同取值下的形状。可以看到当β 趋 近于 0 时, Swish 函数趋近于线性函数 y = x,当 β 趋近于无穷大时, Swish 函数趋近于 ReLU 函数, β 取值为 1 时, Swish 函数是光滑且非单调。

Swish 激活函数在参数 β 不同取值下的形状
Rotary Position Embedding
旋转位置编码是一种能够将相对位置信息依赖集成到 self-attention 中, 并提升 transformer 架构性能的位置 编码方式。受 GPTNeo 的启发, LLaMa 没有使用之前的绝对位置编码, 而是使用了旋转位置编码(RoPE),可以 提升模型的外推性, 这也目前大模型相对位置编码中应用最广的方式之一。模型的外推性是指大模型在训练时 和预测时的输入长度不一致, 导致模型的泛化能力下降的问题。例如, 如果一个模型在训练时只使用了 512 个 token 的文本, 那么在预测时如果输入超过 512 个 token,模型可能无法正确处理。这就限制了大模型在处理长文 本或多轮对话等任务时的效果。
在 Transformer 结构中做 self-attention 之前, 会用词嵌入向量计算q, k,v 向量同时加入位置信息, RoPE 借助 了复数的思想, 出发点是通过绝对位置编码的方式实现相对位置编码。其目标是通过下述运算来给 q,k 添加绝对位置信息, 函数公式表达如下:

其中 qm 表示第 m 个 token 对应的词向量 xm 集成位置信息 m 之后的 query 向量。而 kn 和 vn 则表示第 n 个 token 对应的词向量 xn 集成位置信息 n 之后的 key 和value 向量。而基于 transformer 的位置编码方法都是着重于 构造一个合适的 f (q, k, v) 函数形式。
而计算第 m 个词嵌入向量 xm 对应的 self-attention 输出结果, 就是 qm 和其他 kn 都计算一个 attention score, 然后再将 attention score 乘以对应的 vn 再求和得到输出向量 om :

对于位置编码, 常规的做法是在计算 query, key 和 value 向量之前, 会计算一个位置编码向量 pi 加到词嵌入 xi 上, 位置编码向量 pi 同样也是 d 维向量, 然后再乘以对应的变换矩阵 W,即 f (xi , i) = W(xi + pi ),而经典 的位置编码向量 pi 的计算方式是使用 Sinusoidal 函数:

其中 pi,2t 表示位置 d 维度向量 pi中的第 2t 位置分量也就是偶数索引位置的计算公式, 而 pi,2t+1 就对应第 2t +1 位置分量也就是奇数索引位置的计算公式。
对于 2 维旋转位置编码, 为了能利用上 token 之间的相对位置信息, 假定 query 向量 qm 和 key 向量 kn 之间 的内积操作可以被一个函数 g 表示,该函数g 的输入是词嵌入向量 xn 、xm 和它们之间的相对位置 m - n:

假定现在词嵌入向量的维度是两维 d = 2 ,这样就可以利用上 2 维度平面上的向量的几何性质, 然后论文中提出 了一个满足上述关系的 f 和 g 的形式如下:

这里面 Re 表示复数的实部。进一步地, fq 可以表示成下面的式子:

这里会发现, 这相当于 query 向量乘以了一个旋转矩阵, 这就是为什么叫做旋转位置编码的原因。同理, fk 可 以表示成下面的式子:

最终, g(xm , xn , m − n) 可以表示如下:

当然, 还可以将旋转位置编码从 2 维推广到任意维度。总结来说, RoPE 的 self-attention 操作的流程是:对 于 token 序列中的每个词嵌入向量, 首先计算其对应的 query 和 key 向量, 然后对每个 token 位置都计算对应的 旋转位置编码, 接着对每个 token 位置的 query 和 key 向量的元素按照两两一组应用旋转变换, 最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果。下图展示了旋转变换的过程:

RoPE 的旋转变换过程示例
RoPE 具有很好的外推性, 而且研究实验也证明了这一点, 这里解释下具体原因。RoPE 可以通过旋转矩阵 来实现位置编码的外推, 即可以通过旋转矩阵来生成超过预期训练长度的位置编码。这样可以提高模型的泛化 能力和鲁棒性。
回顾一下 RoPE 的工作原理:假设我们有一个 d 维的绝对位置编码 Pi ,其中 i 是位置索引。我们可以将 Pi 看成一个 d 维空间中的一个点。我们可以定义一个 d 维空间中的一个旋转矩阵 R,它可以将任意一个点沿着某 个轴旋转一定的角度。我们可以用 R 来变换 Pi ,得到一个新的点 Qi = R * Pi。我们可以发现, Qi 和 Pi 的距离 是相等的, 即 ||Pi − Qi || = 0。这意味着 Pi 和 Qi 的相对关系没有改变。但是, Pi 和 Qi 的距离可能发生改变, 即 ||Pi − Pj ||不等于||Qi − Pj ||。这意味着 Qi 和 Pj 的相对关系有所改变。因此, 我们可以用 R 来调整不同位置之间的 相对关系。
如果我们想要生成超过预训练长度的位置编码, 我们只需要用 R 来重复变换最后一个预训练位置编码 Pn , 得到新的位置编码 Qn+1 = R*Pn , Qn+2 = R*Qn+1 , Qn+3 = R*Qn+2 ,依此类推。这样就可以得到任意长度的位 置编码序列 Qn+1 , Qn+2 , ..., Qm ,其中 m 可以大于 n。由于 R 是一个正交矩阵,它保证了 Qi 和 Qj 的距离不会无限 增大或缩小,而是在一个有限范围内波动。这样就可以避免数值溢出或下溢的问题。同时,由于R 是一个可逆矩阵, 它保证了 Qi 和 Qj 的距离可以通过 R 的逆矩阵 R− 1 还原到 Pi 和 Pj 的距离,即 ||R− 1 *Qi −R− 1 *Qj || = ||Pi −Pj ||。这样就可以保证位置编码的可逆性和可解释性。所以,旋转位置编码总结而言:
-
旋转编码 RoPE 可以有效地保持位置信息的相对关系, 即相邻位置的编码之间有一定的相似性, 而远离位 置的编码之间有一定的差异性。这样可以增强模型对位置信息的感知和利用。这一点是其他绝对位置编码 方式(如正弦位置编码、学习的位置编码等) 所不具备的, 因为它们只能表示绝对位置, 而不能表示相对 位置。
-
旋转编码 RoPE 可以通过旋转矩阵来实现位置编码的外推, 即可以通过旋转矩阵来生成超过预训练长度的 位置编码。这样可以提高模型的泛化能力和鲁棒性。这一点是其他固定位置编码方式(如正弦位置编码、 固定相对位置编码等) 所不具备的, 因为它们只能表示预训练长度内的位置, 而不能表示超过预训练长度 的位置。
-
旋转编码 RoPE 可以与线性注意力机制兼容, 即不需要额外的计算或参数来实现相对位置编码。这样可以 降低模型的计算复杂度和内存消耗。这一点是其他混合位置编码方式(如 Transformer-XL 、XLNet 等) 所 不具备的,因为它们需要额外的计算或参数来实现相对位置编码。
RoPE 在 HuggingFace Transformer 库中代码实现如下所示:

模型超参数
不同规模 LLaMA 模型所使用的具体超参数如下表所示。

LLaMA 不同模型规模下的具体超参数细节
Group Query Attention(V2 only)
自回归模型生成回答时, 需要前面生成的 KV 缓存起来, 来加速计算。多头注意力机制 (MHA) 需要的缓存 量很大, Multi-Query Attention(MQA) 指出多个头之间也可以共享 KV 对, MQA 还可能会导致质量下降, 而且 可能不希望仅训练一个单独的模型以实现更快的推理。Group Query Attention(GQA) 没有像 MQA 一样极端, 将 query 分组, 组内共享 KV,效果接近 MQA,, 即分组查询注意力将查询头分成 G 组, 每组组共享单个键头和值 头, 速度上与 MQA 可比较, 分组查询注意力如下图所示。GQA-G 是指 G 组分组查询;GQA- 1 指单个组, 只有单个键和值头, 相当于 MQA;而 GQA-H 的组等于头数, 相当于 MHA。在将多头检查点转换为 GQA 检查点 时,通过平均池化该组内的所有原始头来构建每个组键和值头。

分组查询注意力示例
中间组数导致插值模型的质量高于 MQA,但比 MHA 更快。从 MHA 到 MQA 将 H 键和值头减少到单个键 和值头, 减少了键值缓存的大小, 因此需要加载的数据量 H 倍。然而, 较大的模型通常缩放头部的数量, 使得 多查询注意力在内存带宽和容量方面都代表了更积极的切割。GQA 允许随着模型大小的增加保持相同的带宽和 容量比例下降。此外, 较大的模型受到关注的内存带宽开销相对较小, 因为 KV-cache 随模型维度缩放, 而模型 FLOPs 和参数随模型维度的平方缩放。
HuggingFace Transformer 库中 LLaMA 解码器整体实现代码实现如下所示:

ps:欢迎扫码关注公众号^_^.


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)