大模型数据处理-数据分割的5种级别
我们将一份长文本输入到LLM的时候,有时候会出现内容过长等问题,最有效的策略是将长文本进行分割。这个过程英文被称为splitting 或者 chunking。chunking通常是比较前置的阶段,会对后续生成产生较大影响,让我们看看,都有哪些方案和对应的效果。
主体内容来源
简述
我们将一份长文本输入到LLM的时候,有时候会出现内容过长等问题,最有效的策略是将长文本进行分割。这个过程英文被称为splitting 或者 chunking。chunking通常是比较前置的阶段,会对后续生成产生较大影响,让我们看看,都有哪些方案和对应的效果。
概览
按划分效果从低到高排列。
- Level 1:字符分割-简单按照字符划分
- Level 2:递归字符分割-按照多个字符串递归划分,让划分结果趋近于chunk_size
- Level 3:特殊文档类型分割-如果文本本身就带有某种特殊格式,比如markdown,xml,python等文件,可以根据文档的类型配置特殊的分割符。
- Level 4:embedding语义分割-按照语义对段落进行分割。
- Level 5:智能体分割-使用LLM进行分割。
准备
pip install langchain
pip install langchain_openai
Level-1:按字符分割
按字符分割是最基本的分割策略,简单来说就是按N个字符长度将文本分割成多个块(chunk),但是不用费心处理块里的内容或者格式。
这种方式非常简单,但是太粗糙,实际上不推荐任何情况下使用,但是我们可以了解一些基本概念。
- 块大小:chunk size-每块的个数
- 块重合部分:chunk overlap-为了避免一份内容被分割到多个块内。
- 分隔符:separator

我们再通过一些例子这些概念。
from langchain.text_splitter import CharacterTextSplitter
text = "一二三四五 上山打老虎 偷油吃 叽里咕噜滚下来"
text_splitter = CharacterTextSplitter(chunk_size = 5, chunk_overlap=0, separator='', strip_whitespace=False)
text_splitter.create_documents([text])
注意:CharacterTextSplitter的默认分隔符是\n\n我们如果想只是简单的按任意字符分割,指定为空串即可。默认会为我们做strip,为了方便我们了解真实效果,这里我们关闭strip_whitespace。
[Document(page_content='一二三四五'),
Document(page_content=' 上山打老'),
Document(page_content='虎 偷油吃'),
Document(page_content=' 叽里咕噜'),
Document(page_content='滚下来')]
可以看到,效果还是比较粗糙的,我们加上chunk_overlap来看看效果。修改一下代码.
text_splitter = CharacterTextSplitter(chunk_size = 5, chunk_overlap=2, separator='', strip_whitespace=False)
[Document(page_content='一二三四五'),
Document(page_content='四五 上山'),
Document(page_content='上山打老虎'),
Document(page_content='老虎 偷油'),
Document(page_content='偷油吃 叽'),
Document(page_content=' 叽里咕噜'),
Document(page_content='咕噜滚下来')]
通过这个例子,我们就能看出overlap的作用。实际上就是每个块都往有几个字符与前一个块内容重叠,在chunk_size比较大的时候,通过冗余数据来避免边缘的不可分割内容被错误截断。目前看来效果仍然不好。我们来调整一下另一个非常重要的参数separator。
text_splitter = CharacterTextSplitter(chunk_size = 5, chunk_overlap=1, separator=' ')
需要注意的是chunk_overlap和separator是有一定冲突的,当你的separator不含“”时,chunk_overlap是不会生效的。
[Document(page_content='一二三四五'),
Document(page_content='上山打老虎'),
Document(page_content='偷油吃'),
Document(page_content='叽里咕噜滚下来')]
就目前的效果来看,当前例子使用separator,就可以按照简单的短句子划分了。
Level-2:递归字符分割
我们的需求常常是复杂的,有时候可能需要多个分割符,但是又希望chunk大小尽可能贴近我们设置的chunk size,这时候可以使用“递归字符分割”的方式。
递归分割大致分为两个部分:分割与合并。
分割阶段:取第一个分割符对字符串进行分割,如果len(chunk)大于chunk_size,则递归调用分割函数,使用其他分割符进行此chunk的分割,直到小于chunk_size或者执行完所有分割符。
合并阶段:将分割完的所有chunk,进行尝试合并,让一些连续的、比较小的chunk合并到一起,大小尽可能接近chunk_size,而不大于它。
我们以langchain中自带的RecursiveCharacterTextSplitter来进行演示。
首先需要补充的一点:RecursiveCharacterTextSplitter默认的分割符是如下几个。
"\n\n"
"\n"
" "
""
text = """
Ein Gespenst geht um in Europa – das Gespenst des Kommunismus. Alle Mächte des alten Europa haben sich zu einer heiligen Hetzjagd gegen dies Gespenst verbündet, der Papst und der Zar, Metternich und Guizot, französische Radikale und deutsche Polizisten.
Wo ist die Oppositionspartei, die nicht von ihren regierenden Gegnern als kommunistisch verschrieen worden wäre? Wo ist die Oppositionspartei, die nicht den fortschrittlichsten Oppositionsleuten wie den eigenen Anhängern den brandmarkenden Vorwurf des Kommunismus zurückgeschleudert hätte?
Zwei Dinge gehen aus dieser Tatsache hervor.
1. Der Kommunismus wird bereits von allen europäischen Mächten als eine Macht anerkannt.
2. Es ist hohe Zeit, daß die Kommunisten ihre Anschauungsweise, ihre Zwecke, ihre Tendenzen vor der ganzen Welt offen darlegen und dem Märchen vom Gespenst des Kommunismus ein Manifest der Partei selbst entgegenstellen.
Zu diesem Zweck haben sich Kommunisten der verschiedensten Nationalität in London versammelt und das folgende Manifest entworfen, das in englischer, französischer, deutscher, italienischer, flämischer und dänischer Sprache veröffentlicht wird.
"""
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=0)
output
[Document(page_content='Ein Gespenst geht um in Europa – das Gespenst des'),
Document(page_content='Kommunismus. Alle Mächte des alten Europa haben'),
Document(page_content='sich zu einer heiligen Hetzjagd gegen dies'),
Document(page_content='Gespenst verbündet, der Papst und der Zar,'),
Document(page_content='Metternich und Guizot, französische Radikale und'),
Document(page_content='deutsche Polizisten.'),
Document(page_content='Wo ist die Oppositionspartei, die nicht von ihren'),
Document(page_content='regierenden Gegnern als kommunistisch verschrieen'),
Document(page_content='worden wäre? Wo ist die Oppositionspartei, die'),
Document(page_content='nicht den fortschrittlichsten Oppositionsleuten'),
Document(page_content='wie den eigenen Anhängern den brandmarkenden'),
Document(page_content='Vorwurf des Kommunismus zurückgeschleudert hätte?'),
Document(page_content='Zwei Dinge gehen aus dieser Tatsache hervor.'),
Document(page_content='1. Der Kommunismus wird bereits von allen'),
Document(page_content='europäischen Mächten als eine Macht anerkannt.'),
Document(page_content='2. Es ist hohe Zeit, daß die Kommunisten ihre'),
Document(page_content='Anschauungsweise, ihre Zwecke, ihre Tendenzen vor'),
Document(page_content='der ganzen Welt offen darlegen und dem Märchen'),
Document(page_content='vom Gespenst des Kommunismus ein Manifest der'),
Document(page_content='Partei selbst entgegenstellen.'),
Document(page_content='Zu diesem Zweck haben sich Kommunisten der'),
Document(page_content='verschiedensten Nationalität in London versammelt'),
Document(page_content='und das folgende Manifest entworfen, das in'),
Document(page_content='englischer, französischer, deutscher,'),
Document(page_content='italienischer, flämischer und dänischer Sprache'),
Document(page_content='veröffentlicht wird.')]
可以看到实际上我们可以看到,RecursiveCharacterTextSplitter 实际上是按照顺序进行划分的,而最后一个分割符是“”,所以肯定会被每个chunk的长度不会超过chunk_size。
Level-3:特殊文档类型分割
上面的两种都属于比较通用的分割方式,有时候我们处理的是有明确类型的文档,比如markdown、json、python等扽,这时候根据文档类型来分割,会得到更好的效果。
在langchain里面,为我们提供了很多文档类型分割器。
我们以markdown举例:
from langchain.text_splitter import MarkdownTextSplitter
splitter = MarkdownTextSplitter(chunk_size = 40, chunk_overlap=0)
markdown_text = """
# Fun in California
## Driving
Try driving on the 1 down to San Diego
### Food
Make sure to eat a burrito while you're there
## Hiking
Go to Yosemite
"""
splitter.create_documents([markdown_text])
output
[Document(page_content='# Fun in California\n\n## Driving'),
Document(page_content='Try driving on the 1 down to San Diego'),
Document(page_content='### Food'),
Document(page_content="Make sure to eat a burrito while you're"),
Document(page_content='there'),
Document(page_content='## Hiking\n\nGo to Yosemite')]
如果我们进入MarkdownTextSplitter内部我们就会发现,实际上它是RecursiveCharacterTextSplitter的子类。
class MarkdownTextSplitter(RecursiveCharacterTextSplitter):
"""Attempts to split the text along Markdown-formatted headings."""
def __init__(self, **kwargs: Any) -> None:
"""Initialize a MarkdownTextSplitter."""
separators = self.get_separators_for_language(Language.MARKDOWN)
super().__init__(separators=separators, **kwargs)
通过get_separators_for_language获取了对应文档的特殊分割符。

Level-4:embedding语义分割
上面几个等级都是非常简单的按照字符分割,在特定的文档内可能效果不错,但是如果是复杂一些的文档,但是我们仍然以一个固定的chunk_size来分割,这非常的不合理。因此我们希望按照内容相关性进行区分,而这就需要一些更高级的方式。
我们可是使用词嵌入(embedding)技术来提取一个句子的含义,然后计算句子之间的相关性,把相关的内容合并成一个chunk,这样我们就实现语意划分了。
那么如何计算相关性呢?我们知道embedding是将文本转化为一个超高维度的向量,而向量是可以计算余弦相似度的。下图是一个二维的词向量图,横坐标性别区分行,纵坐标年龄,可以看到child和infant(婴儿)的方向非常近,这代表它们的意思很接近,只是程度上有所差别。同样我们如果把chunk的含义作为一个超高维度的坐标中的点,通过计算余弦相似度就可以得到chunk之间的相关性。

我们来动手试一下。先准备一些数据。
from sklearn.metrics.pairwise import cosine_similarity
raw_text="""
我家有一只猫,它叫tom。
它还有个老鼠朋友,叫jerry。
很多人希望通过AI来改变世界。
今天天气多云转晴。
很适合我们出去玩。
你想去哪里玩呢?
"""
single_sentences_list = raw_text.split()
将句子转为dict保存index
sentences = [{'sentence': x, 'index' : i} for i, x in enumerate(single_sentences_list)]
很多来说一句话和另一句话单独拿出来看意思并不相关,但是合到一起就会有不一样的感觉。比如:“今天我心情很好。”、“上证指数冲上5000点了!”。这两句放一起,可能就意味着我是个股民。所以我们需要把前后的句子合到一起来进行相关性的计算,负责可能后漏掉,上下文的赋予句子的含义。下面的函数就是做了这样一个工作,你可以根据实际情况调整buffer_size的大小,如果你切的比较碎,那么可以适当调大buffer_size。
def combine_sentences(sentences, buffer_size=1):
for i in range(len(sentences)):
combined_sentence = ''
#拼接前面的句子
for j in range(i - buffer_size, i):
if j >= 0:
combined_sentence += sentences[j]['sentence'] + ' '
combined_sentence += sentences[i]['sentence']
#拼接后面的句子
for j in range(i + 1, i + 1 + buffer_size):
if j < len(sentences):
combined_sentence += ' ' + sentences[j]['sentence']
# 为dict添加combined_sentence
sentences[i]['combined_sentence'] = combined_sentence
return sentences
sentences = combine_sentences(sentences)
sentences
output:
[{'sentence': '我家有一只猫,它叫tom。',
'index': 0,
'combined_sentence': '我家有一只猫,它叫tom。 它还有个老鼠朋友,叫jerry。'},
{'sentence': '它还有个老鼠朋友,叫jerry。',
'index': 1,
'combined_sentence': '我家有一只猫,它叫tom。 它还有个老鼠朋友,叫jerry。 很多人希望通过AI来改变世界。'},
{'sentence': '很多人希望通过AI来改变世界。',
'index': 2,
'combined_sentence': '它还有个老鼠朋友,叫jerry。 很多人希望通过AI来改变世界。 今天天气多云转晴。'},
{'sentence': '今天天气多云转晴。',
'index': 3,
'combined_sentence': '很多人希望通过AI来改变世界。 今天天气多云转晴。 很适合我们出去玩。'},
{'sentence': '很适合我们出去玩。',
'index': 4,
'combined_sentence': '今天天气多云转晴。 很适合我们出去玩。 你想去哪里玩呢?'},
{'sentence': '你想去哪里玩呢?',
'index': 5,
'combined_sentence': '很适合我们出去玩。 你想去哪里玩呢?'}]
embedding 部分我们使用OpenAIEmbeddings,比较方便使用,准确度也不错的。
import os
os.environ['OPENAI_API_KEY'] = 'your_key'
from langchain.embeddings import OpenAIEmbeddings
oaiembeds = OpenAIEmbeddings()
embeddings = oaiembeds.embed_documents([x['combined_sentence'] for x in sentences])
for i, sentence in enumerate(sentences):
sentence['combined_sentence_embedding'] = embeddings[i]
余弦相似度我们就使用现成的sklearn metrics库来计算,需要注意的是计算出余弦相似度越接近1则代表含义越接近,我们希望得到的是差异,那么使用1-similarity,来作为两句话含义的距离。
from sklearn.metrics.pairwise import cosine_similarity
def calculate_cosine_distances(sentences):
distances = []
for i in range(len(sentences) - 1):
embedding_current = sentences[i]['combined_sentence_embedding']
embedding_next = sentences[i + 1]['combined_sentence_embedding']
# Calculate cosine similarity
similarity = cosine_similarity([embedding_current], [embedding_next])[0][0]
# Convert to cosine distance
distance = 1 - similarity
# Append cosine distance to the list
distances.append(distance)
# Store distance in the dictionary
sentences[i]['distance_to_next'] = distance
# Optionally handle the last sentence
# sentences[-1]['distance_to_next'] = None # or a default value
return distances, sentences
distances, sentences = calculate_cosine_distances(sentences)
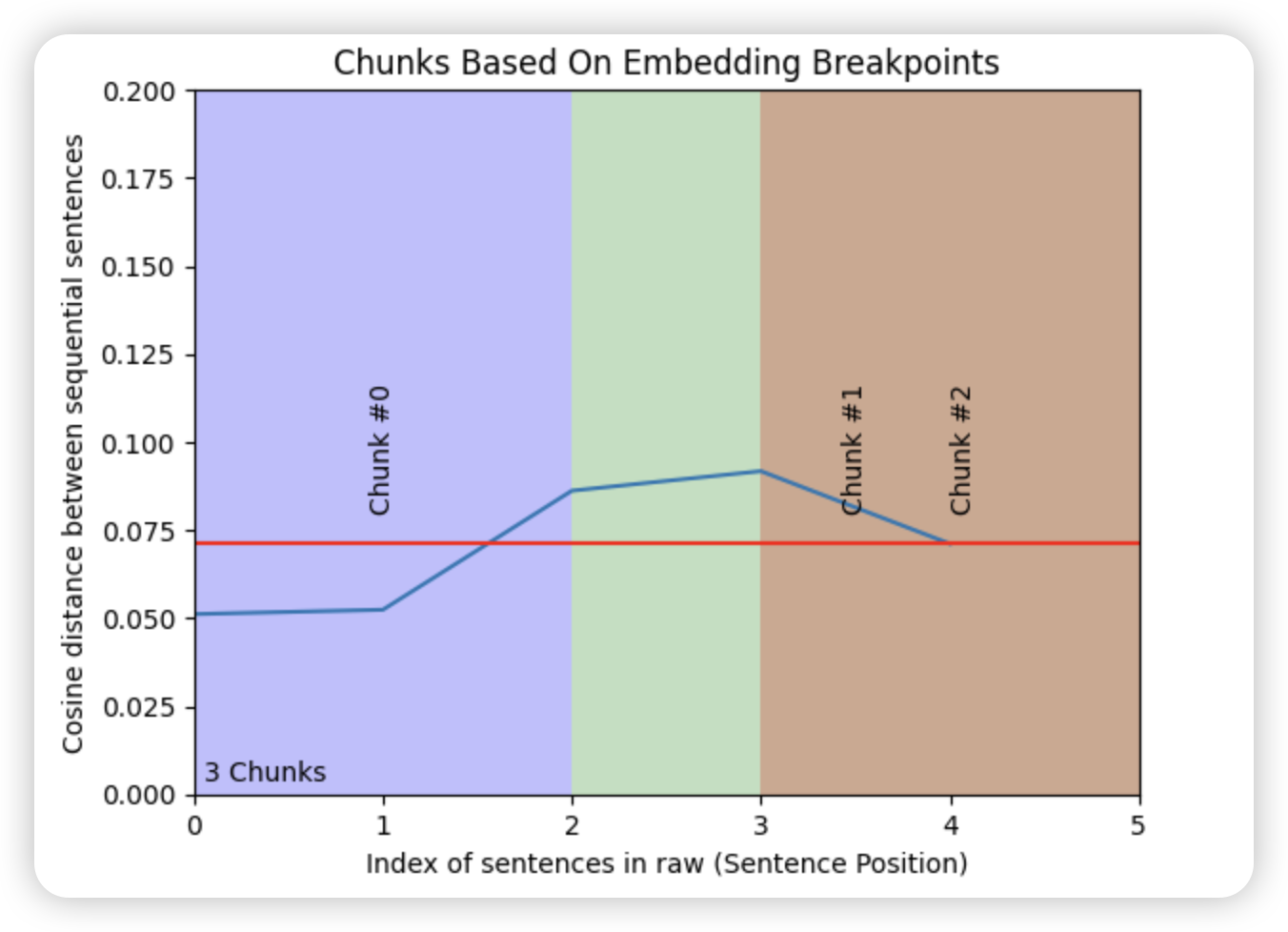
让我们使用matplotlib画一下。
这里使用breakpoint_percentile_threshold设置chunk截断点的含义差距阈值,如果想多截chunk就把阈值调低,那么细小的差异就会被截断。
import matplotlib.pyplot as plt
import numpy as np
plt.plot(distances);
y_upper_bound = .2
plt.ylim(0, y_upper_bound)
plt.xlim(0, len(distances))
breakpoint_percentile_threshold = 50
breakpoint_distance_threshold = np.percentile(distances, breakpoint_percentile_threshold)
plt.axhline(y=breakpoint_distance_threshold, color='r', linestyle='-');
# Then we'll see how many distances are actually above this one
num_distances_above_theshold = len([x for x in distances if x > breakpoint_distance_threshold]) # The amount of distances above your threshold
plt.text(x=(len(distances)*.01), y=y_upper_bound/50, s=f"{num_distances_above_theshold + 1} Chunks");
# Then we'll get the index of the distances that are above the threshold. This will tell us where we should split our text
indices_above_thresh = [i-1 for i, x in enumerate(distances) if x > breakpoint_distance_threshold] # The indices of those breakpoints on your list
# Start of the shading and text
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
for i, breakpoint_index in enumerate(indices_above_thresh):
start_index = 0 if i == 0 else indices_above_thresh[i - 1]
end_index = breakpoint_index if i < len(indices_above_thresh) - 1 else len(distances)
plt.axvspan(start_index, end_index, facecolor=colors[i % len(colors)], alpha=0.25)
plt.text(x=np.average([start_index, end_index]),
y=breakpoint_distance_threshold + (y_upper_bound)/ 20,
s=f"Chunk #{i}", horizontalalignment='center',
rotation='vertical')
# # Additional step to shade from the last breakpoint to the end of the dataset
if indices_above_thresh:
last_breakpoint = indices_above_thresh[-1]
if last_breakpoint < len(distances):
plt.axvspan(last_breakpoint, len(distances), facecolor=colors[len(indices_above_thresh) % len(colors)], alpha=0.25)
plt.text(x=np.average([last_breakpoint, len(distances)]),
y=breakpoint_distance_threshold + (y_upper_bound)/ 20,
s=f"Chunk #{i+1}",
rotation='vertical')
plt.title("Chunks Based On Embedding Breakpoints")
plt.xlabel("Index of sentences in essay (Sentence Position)")
plt.ylabel("Cosine distance between sequential sentences")
plt.show()
可以看到大致分成了三段,chunk 0-2,0-5分别对应之前分的句子,每一个threshold以上的点,都可以被作为分段的breakpoint。

最后我们把sentence合并成chunk
start_index = 0
chunks = []
for index in indices_above_thresh:
end_index = index
group = sentences[start_index:end_index]
combined_text = ' '.join([d['sentence'] for d in group])
chunks.append(combined_text)
start_index = index
if start_index < len(sentences):
combined_text = ' '.join([d['sentence'] for d in sentences[start_index:]])
chunks.append(combined_text)
print(chunks)
可以看到效果还是非常好的。
['我家有一只猫,它叫tom。 它还有个老鼠朋友,叫jerry。', '很多人希望通过AI来改变世界。', '今天天气多云转晴。 很适合我们出去玩。 你想去哪里玩呢?']
Level-5:使用智能体进行文本分割
在Level4中,我们已经实现了一定的语义分割,但是稍显粗糙,由于使用的是embedding和余弦相似度,所以实际上相似的句子只是意思上接近,而并非逻辑上就应该在一个chunk内。比如,我们一份原始资料描述山东、山西、河南、河北的高考情况,很可能这些地区内容都很类似,差异度就会很小,使用Level4很可能被划分到一个chunk。如果我们使用LLM来进行处理,则可以很好的将它们划分成不同的chunk。
方式1
现在假设让一个人来做文本划分的工作,那么可能是如下的步骤。
- 准备一张纸,用作记录内容摘要。
- 读一块内容,用简洁的语言总结每一段的内容。
- 根据写的总结,来区分哪些段之间应该分割,哪些段之间应该合并。
当然,这种方式适合文本不是特别长的情况,因为要通读所有总结。
但是大多数情况下,我们不需要考虑通篇理解的情况下再分段,所以第三步可以改为:直接根据总结来判断是否要再两段之间划分。
方式2
参考这份资料
使用被称为命题化的方案(Propositionizer),关于命题化可以看这篇论文。这是一个很酷的概念。
很多时候,原始的内容对于大模型来说,过于粗糙。我们可以在保证原始文字意思不变的情况下,尽量切碎语句。
例如: Greg went to the park. He likes walking -> ['Greg went to the park.', 'Greg likes walking']
最小的碎片🧩,被称为proposition。我们根据它,来进行分段的行为。
下面我们要做的是:
1.将原始文本命题化。参考相关prompt
2. 创建空白chunk,为其添加一个proposition。
3. 根据chunk内的propositions,生成泛化的总结。
4. 将总结,放入一个大纲outline,并存下对应的chunk_id和。
5. 再取一个proposition,判断它属于大纲里的哪个chunk。
6.1. 如果属于已有的chunk,那么加入其中,并根据propositions更新chunk的summary。
6.2. 如果内容不属于大纲的任何chunk,那么新建一个chunk,重复2以后的步骤。
方式2有着比方式1更好的效果,但是也将使用更多tokens.
总结
从效果来来看,1->5 依次增强,但是5通常需要使用gpt-4级别的LLM,这意味着有着非常高的成本。对与我来说,最常用的可能是 Level3和Level4。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)