Python自动化测试项目总结(超详细)
UnitTest 单元测试框架是受到 JUnit 的启发,与其他语言中的主流单元测试框架有着相似的风格。其支持测试自动化,配置共享和关机代码测试。支持将测试样例聚合到测试集中,并将测试与报告框架独立。unittest --- 单元测试框架 — Python 3.8.19 文档TestFixture:测试脚手架,测试所需要进行的准备工作,以及所有相关的清理操作。TestCase:测试用例,一个 Te
Python Web 自动化测试入门实战
自动化入门介绍
本次实验主要介绍什么是自动化测试和自动化测试工具 selenium。然后介绍怎么安装浏览器驱动工具 webdriver,并且开发一个简单的自动化测试脚本,体会自动化测试是怎么实现的。
自动化测试概念
自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。其实质是写脚本或使用工具测试程序。
自动化测试分类
自动化测试是使用各种工具或程序代替人工测试的一种行为。只要是解除人工操作的测试都可以称为自动化测试,细分又有好多种类,下面简单列举一些。
- Web UI 自动化测试。
- API 自动化测试。
- 性能自动化测试。
- 单元测试。
- Windows 窗体 UI 自动化测试。
本系列实验以 Python Web UI 自动化测试为主,为了方便起见以后直接简称自动化测试。
怎么学习自动化测试
写好自动化测试的前提是有夯实的手工测试基础,学习自动化测试的基本路线大致如下:
- 做好手工功能测试(包括测试理论知识,涉及的工具使用等)。
- 学习前端基本知识(HTML、CSS、JavaScript)。
- 掌握一门编程语言(例如 Python、Java)。
- 精通自动化测试工具(目前最流行的为 Selenium)。
- 精通自动化测试框架(UnitTest、Pytest)。
- 熟悉自动化测试模型(线性模型、模块化驱动、数据驱动、关键字驱动、行为驱动)。
- 熟悉集成工具(例如 Jenkins)。
学完以上七点,便可在项目中进行自动化测试。
本系列实验将会以 Python3 + Selenium 为基础进行展开。
什么样的项目适合自动化测试
对项目进行自动化测试之前要了解项目是否适合做自动化测试。业界普遍从三个方面进行考虑。
- 需求稳定,变更不会太频繁。
自动化测试只适用比较稳定的系统或系统中的部分功能模块。如果需求变更过于频繁则自动化测试的脚步维护也就比较大,进而成本也会加大,从而消耗更多的资源,是不划算的。
- 维护周期长,具有生命力。
开发自动化测试脚本是需要时间的。如果项目周期比较短,下一个版本已经开始了,对某些模块有了新的变动,而正在进行的自动化测试开发将会变得毫无意义。
- 被测系统开发规范,可测性强。
测试脚本的开发需要根据被测系统而考虑,如果被测系统架构不完善则测试工具和测试技术很难应对,一旦测试人员的能力不是很好,则设计出来的测试框架、写出来的测试脚本在应对性上也很差。由此便造成自动测试产生的价值没有手工测试来的直接。
selenium 是什么
Selenium 是一个用于 Web 系统自动化测试的工具集,现在所说的 Selenium 通常是指 Selenium Suite,其包含 Selenium IDE、Selenium WebDriver 和 Selenium Grid 三部分。
- Selenium IDE:是一个 Firefox 插件,可以根据用户的基本操作自动录制脚本,然后在浏览器中进行回放。
- Selenium WebDriver:WebDriver 的前身是 Selenium RC,其可以直接给浏览器发送命令模拟用户的操作。Selenium RC 为 WebDriver 的核心部分,它可以使用编程语言如 Java、C#、PHP、Python、Ruby 和 Perld 的强大功能来创建更复杂的测试。Selenium RC 分为 ClientLibraries(编写测试脚本)和 Selenium Server(控制浏览器行为)两部分。
- Selenium Grid:是一个用于运行在不同的机器、不同的浏览器并行测试的工具,用于加快测试用例的运行速度。
安装浏览器驱动
WebDriver 是 Selenium Tool 套件中最重要的组件,其就像一个媒介,用脚本驱动 WebDriver,WebDriver 再去控制浏览器,从而实现脚本对浏览器的操作。
只有安装了浏览器驱动才能使用 Selenium 发送指令模拟人类行为操作浏览器。不同的浏览器需要安装各自的驱动,接下来以 Chrome 浏览器为例安装 chromedriver.exe。
- 查看 Chrome 版本。
由于安装的 chromedriver.exe 版本需要和 Chrome 浏览器版本匹配,所以我们需要知道 Chrome 的版本。从 Chrome 浏览器右上角的菜单中依次选择【帮助(E)】、【关于 Google Chrome(G)】,查看浏览器的版本。

- 下载 chromedriver。
进入 chromedriver 下载地址下载 https://chromedriver.storage.googleapis.com/index.html 或使用淘宝镜像地址下载 https://npm.taobao.org/mirrors/chromedriver/ ,进入后选择对应的版本号。

然后根据自己的系统选择对应的 zip 文件进行下载。如实验的系统是 Linux 则下载 chromedriver_linux64.zip,并将其保存在 /home/shiyanlou/Code/ 下。

下载后通过 cd 命令进入到 /home/shiyanlou/Code/ 目录中,使用命令 unzip chromedriver_linux64.zip 进行解压。

- 将 chromedriver 移至 python 所在目录下。
将 chromedriver 移动至 Python 编辑器所在的目录 /usr/bin/ 下,使 chromedriver 与 python 处于同一目录下,这样做的目的是便于 Python 在执行时可以找到 chromedriver。 使用命令 sudo cp -r /home/shiyanlou/Code/chromedriver /usr/bin/。

不同的浏览器需要是使用不同的驱动,下面列出 FireFox 和 IE 浏览器驱动的下载地址。
- Firefox 浏览器驱动的下载网址:https://github.com/mozilla/geckodriver/releases/ 。
- IE 浏览器驱动下载:NuGet Gallery | Selenium.WebDriver.IEDriver 4.14.0 。
开发第一个自动化测试脚本
打开 Xfce 终端,依次输入下面命令,先安装 Python3 安装第三方库的程序 pip,安装完成后对 pip 进行升级,然后安装 selenium 库。
sudo apt install python3-pip sudo pip3 install --upgrade pip pip3 install selenium

继续输入下面命令,进入到 python 环境中,然后导入 webdriver。
python3 from selenium import webdriver
输入 driver = webdriver.Chrome() 启动 Chrome 浏览器。
输入 driver.get("***********************") 后在浏览器中打开蓝桥首页。
输入 driver.close() 关闭浏览器。
在命令行中体验了怎么运行,现在将上面的步骤写成 py 文件。
在 /home/shiyanlou/Code/ 目录下新建 myfirst_project.py 文件。
在 myfirst_project.py 中编辑代码,操作浏览器打开蓝桥首页,然后关闭浏览器。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("***********************")
driver.close()

然后打开 Xfce 终端,输入下面命令运行 myfirst_project.py 脚本。
python3 /home/shiyanlou/Code/myfirst_project.py
命令执行后脚本会驱动 webdriver 打开 Chrome 浏览器,然后访问蓝桥首页,最后关闭浏览器。
元素定位
元素定位是在进行自动化测试时的基本功,本次实验将介绍元素的八大定位、By 方法定位、定位一组元素和怎么确认定位到的元素就是自己需要的。
知识点
- id 定位
- class 定位
- name 定位
- tag 定位
- xPath 定位
- link 定位
- Partial link 定位
- CSS 定位
- By 定位
- 确认元素的唯一性
- 定位一组元素
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
元素定位
元素定位是通过在 HTML 代码中查找一些元素属性确定需要的元素。
在进行本次实验之前需要先进行下面的操作,在接下来的实验中将会在此基础上进行。
打开 Xfce 终端,依次输入下面语句,进入到 Python 环境,并且导入 webdriver,然后启动 Chrome 浏览器,并且访问元素定位练习的页面。
python3
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://labfile.oss.aliyuncs.com/courses/2335/20.html")

实验中用到的方法
- 获取元素属性值: .get_attribute('attribute') 。
- 断言两个值相等: assert 预期结果 == 实际结果 。
- 获取文本内容: .text 。
id 定位
语法: find_element_by_id('id') 。
定位元素:通过元素 id 属性定位输入框。

Xfce 终端中输入: driver.find_element_by_id('search')。
断言:通过元素其他属性断言定位的元素正确性。
通过检索框的 maxlength 属性值进行断言,如果获取到的 maxlength 值 与 HTML 脚本中的 maxlength='10' 相等,则表示定位的元素正确。
获取 maxlength 属性值: id_maxlength = driver.find_element_by_id('search').get_attribute('maxlength')。
通过 maxlength 属性值进行断言: assert id_maxlength == '10'。
如果输入断言后出现 Error 错误则获取到的元素错误,反之定位成功。
class 定位
语法:find_element_by_class_name('class')。
定位元素:通过元素 class 属性定位检索按钮。

Xfce 终端中输入: driver.find_element_by_class_name('btn-search')。
断言:通过元素其他属性断言定位的元素正确性。
通过检索按钮的 value 属性值进行断言,如果获取到的 value 值与 HTML 脚本中的 value="检索" 相等,则表示定位的元素正确。
获取 value 属性值: class_value = driver.find_element_by_class_name('btn-search').get_attribute('value')。
通过 value 属性值进行断言: assert class_value == "检索"。
如果输入断言后出现 Error 错误则获取到的元素错误,反之定位成功。
name 定位
语法: find_element_by_name('name')。
定位元素:通过元素 name 属性定位复选框。

Xfce 终端中输入: driver.find_element_by_name('language')。
断言:通过元素其他属性断言定位的元素正确性。
通过复选框的 type 属性值进行断言,如果获取到的 type 值与 HTML 脚本中的 type="checkbox" 相等,则表示定位的元素正确。
获取 type 属性值: name_type = driver.find_element_by_name('language').get_attribute('type')。
通过 type 属性值进行断言: assert name_type == "checkbox"。
如果输入断言后出现 Error 错误则获取到的元素错误,反之定位成功。
tag 定位
语法:find_element_by_tag_name('tag')。
定位元素:通过元素 tag 属性定位文本 “tag 定位”。

Xfce 终端中输入: driver.find_element_by_tag_name('h4')。
断言:通过元素其他属性断言定位的元素正确性。
通过文本的内容进行断言,如果获取到的文本内容与 HTML 脚本中的文本内容 “tag 定位” 相等,则表示定位的元素正确。
获取文本内容: tag_text = driver.find_element_by_tag_name('h4').text。
通过文本内容进行断言: assert tag_text == "tag定位"。
如果输入断言后出现 Error 错误则获取到的元素错误,反之定位成功。
xPath 定位
语法: find_element_by_xpath('xPath')。
定位元素:通过 xPath 定位文本 “xPath 定位”。

通过 HTML 脚本得到路径: /html/body/div/p。
Xfce 终端中输入:driver.find_element_by_xpath('/html/body/div/p')。
断言:通过元素其他属性断言定位的元素正确性。
通过文本的内容进行断言,如果获取到的文本内容与 HTML 脚本中的文本内容 “xPath 定位” 相等,则表示定位的元素正确。
获取文本内容: xPath_text = driver.find_element_by_xpath('/html/body/div/p').text。
通过文本内容进行断言: assert xPath_text == "xPath定位"。
如果输入断言后出现 Error 错误则获取到的元素错误,反正定位成功。
xPath 定位有两种选择路径的方式,绝对路径定位和相对路径定位:
- 绝对路径定位:从页面的最初位置开始定位,以一个单斜杠 “/” 开头,例如 /html/body/div/p。
- 相对路径定位:从页面中可以确定唯一性的一个节点开始定位,以双斜杠 “//” 开头,例如 //div[@id='search']/input,定位的元素是在含有 id='search' 属性的 div 节点下的 input 元素。
xPath 是一种比较实用的定位方式,通过 xPath 定位一个元素可以有多种方式实现。
| 定位方式 | 含义 | 示例 |
|---|---|---|
| * | 匹配任何元素节点 | //*[@name='firstName'] |
| @ | 属性匹配 | //input[@name='firstName'] |
| [index] | 索引定位 | //ul/li[4] |
| [contains(@属性, '属性值')] | 模糊匹配 | /a[contains(@href, 'news')] |
| 属性 1 and 属性 2 | 多个属性匹配 | //input[@type='button' and @name='ok'] |
| starts-with(@属性, '属性值') | 属性以某字段开头 | //input[starts-with(@name, 'first')] |
| ends-with (@属性, '属性值') | 属性以某字段结尾 | //input[ends-with(@name, 'name')] |
| .. | 选取元素的父节点 | //input[@name='firstName']/.. |
| preceding-sibling | 选取同级的哥哥元素 | //ul/li[2]/preceding-sibling:: * |
| following-sibling | 选取同级的弟弟元素 | //ul/li[2]/following-sibling:: * |
link 定位
语法: find_element_by_link_text('text')。
定位元素:通过元素 link 定位文本 “Tynam”。

Xfce 终端中输入: driver.find_element_by_link_text('Tynam')。
断言:通过元素其他属性断言定位的元素正确性。
通过 a 链接的 href 属性值进行断言,如果获取到的 href 值与 HTML 脚本中的 href="http://tynam.com/" 相等,则表示定位的元素正确。
获取 href 属性值:link_href = driver.find_element_by_link_text('Tynam').get_attribute('href')。
通过 href 属性值进行断言: assert link_href == "TYNAM.COM"。
如果输入断言后出现 Error 错误则获取到的元素错误,反之定位成功。
Partial link 定位
语法:find_element_by_partial_link_text('partialText')。
定位元素:通过元素 Partial link 定位文本 “Partial link 定位” 。

Xfce 终端中输入: driver.find_element_by_partial_link_text('link定位')。
断言:通过元素其他属性断言定位的元素正确性。
通过文本的内容进行断言,如果获取到的文本内容与 HTML 脚本中的文本内容 “Partial link 定位” 相等,则表示定位的元素正确。
获取文本内容: partial_link_text = driver.find_element_by_partial_link_text('link定位').text。
通过文本内容进行断言: assert partial_link_text == "Partial link定位"。
如果输入断言后出现 Error 错误则获取到的元素错误,反之定位成功。
CSS 定位
语法: find_element_by_css_selector('css') 。
定位元素:通过 CSS 定位 "CSS 定位" 按钮 。

通过 HTML 脚本可知,button 标签中有一个 class="css" 属性,则 CSS 可写成 button.css。
Xfce 终端中输入 driver.find_element_by_css_selector('button.css')。
断言:通过元素其他属性断言定位的元素正确性。
通过按钮文本内容进行断言,如果获取到的文本内容与 HTML 脚本中的文本内容 “CSS 定位” 相等,则表示定位的元素正确。
获取文本内容: css_text = driver.find_element_by_css_selector('button.css').text。
通过文本内容进行断言: assert css_text == "CSS定位"。
如果输入断言后出现 Error 错误则获取到的元素错误,反之定位成功。
CSS 是一种非常灵活的定位方式,和 xPath 一样,定位一个元素可以有多种方式实现。
| 定位方式 | 含义 | 示例 |
|---|---|---|
| * | 通配符 | * |
| #id | id 选择 | #login |
| .class | class 选择 | div.active |
| Element | 标签选择 | input |
| element1, element2 | 匹配 element1 和 element2 | input, p |
| element1>element2 | 匹配 element1 下子元素为 element2 的元素 | div>.active |
| element1+element2 | 匹配与 element1 同级并且在其相邻后面的 element2 元素 | .active+li |
| [attribute=value] | 匹配属性 attribute 的值为 value 的元素 | input[type="button"] |
| :first-child | 选择第一个子元素 | ul:first-child |
| element:not(s) | 匹配 element 元素但元素中没有 s 值 | div:not(.active) |
By 定位
By 定位和使用 webdriver.find_element_by_xxx 的定位方式类似,只是在写法上有些区别。使用 By 方式定位时需要导入 By 类: from selenium.webdriver.common.by import By。
| 定位方式 | 定位单个元素 | 示例 |
|---|---|---|
| id 定位 | find_element(By.ID, "id") | find_element(By.ID, "search") |
| class 定位 | find_element(By.CLASS_NAME, "class") | find_element(By.CLASS_NAME, "btn-search") |
| name 定位 | find_element(By.NAME, "name") | find_element(By.NAME," language") |
| tag 定位 | find_element(By.TAG_NAME, "tag") | find_element(By.TAG_NAME, "h4") |
| xPath 定位 | find_element(By.XPATH, "xPath") | find_element(By.XPATH, "/html/body/di*** |
| link 定位 | find_element(By.LINK_TEXT, "text") | find_element(By.LINK_TEXT, "Tynam") |
| Partial link 定位 | find_element(By.PARTIAL_LINK_TEXT,"partialText") | find_element(By.PARTIAL_LINK_TEXT, "link 定位") |
| CSS 选择器定位 | find_element(By.CSS_SELECTOR, "css") | find_element(By.CSS_SELECTOR, "button.css") |
确认元素的唯一性
在本次实验中,确定定位到的元素就是所需的,通过添加 assert 断言进行确认。如果在定位时就确认写的语法定位到的元素就是唯一的,那么将会省去甚多麻烦。下面介绍一些直接就可以确定定位到的元素是所需的两种方法。
1.源码中检索确认。
开启查看元素,在源码中检索。打开检索快捷键:Ctrl + F (Windows 下)/ Command + F (Mac OS X 系统下)。
输入要查找的元素属性,例如查找 button 标签中 class=“css” 的元素,则在检索框中输入 button.css。

在检索框的右侧可以看到匹配到的元素数量。如果剔除 CSS、JavaScript 中的记录后数量为 1,则基本可以确定定位的元素就是需要的元素。
2.控制台中确认。
主要是使用 JavaScript 中定位元素的方法,如果项目中使用了 JQuery 也可借助其语法进行确认。开启查看元素,进入控制台(Console),语法和 WebDriver API 中定位元素语法类似。例如确认 id=“search” 则输入 document.getElementById("search")。

属性在控制台中确认元素的语法:
- id 属性确认:document.getElementById()。
- class 属性确认:document.getElementsByClassName()。
- name 属性确认:document.getElementsByName()。
- tag 属性确认:document.getElementsByTagName()。
- xPath 确认:document.getSelection()。
- CSS 确认:document.querySelector()。
定位一组元素
find_elements 和 find_element 定位方式是一致的,只不过 find_elements 返回的是一组数据,且以列表数据结构形式返回,而 find_element 返回的只有一条数据。同样的,定义一组元素也有两种方式,即 find_elements_by_xxx 方法和 find_elements(By.xxx, " ") 方法。
- id 定位:find_elements_by_id()。
- class 定位:find_elements_by_class_name()。
- name 定位:find_elements_by_name()。
- tag 定位:find_elements_by_tag_name()。
- xPath 定位:find_elements_by_xpath()。
- link 定位:find_elements_by_link_text()。
- Partial link 定位:find_elements_by_partial_link_text()。
- CSS 定位:find_elements_by_css_selector()。
定位元素:定位页面中所有 tag=“input” 的元素。
Xfce 终端中输入:tags_input = driver.find_elements_by_tag_name('input')。
将其结果进行打印:print(tags_input)。

通过本次实验,对元素定位有一个基本的理解,在工作中比较通用的定位方式是 xPath 和 CSS 定位,因为这两种定位方式比较灵活,可以结合 id、name、tag、link、Partial link 的定位一起使用,在以后工作中,需要多加练习才能在运用时游刃有余。
浏览器操作
本次实验主要介绍通过 Selenium 对浏览器的一些行为操作,例如浏览器最大化、页面刷新等。
知识点
- 浏览器最大化
- 设置浏览器大小
- 访问网页
- 浏览器前进和后退
- 页面刷新
- 关闭窗口
- 退出浏览器
- 获取页面 title
- 获取页面 url
- 获取页面源码
- 切换窗口
- 操作滚动条
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
浏览器操作
自动化测试中通过 Selenium 的一些方法,达到模拟人的动作对浏览器的行为进行操控。
在进行本次实验之前需要先进行下面的操作,在接下来的实验中将会在此基础上进行。
打开 Xfce 终端,依次输入下面语句,进入到 Python 环境,并且导入 webdriver,然后启动 Chrome 浏览器。
python3 from selenium import webdriver driver = webdriver.Chrome()
浏览器最大化
浏览器最大化是将浏览器最大化占据整个屏幕。
语法:.maximize_window() 。
操作:Xfce 终端中输入 driver.maximize_window()。
结果:浏览器最大化并且占据整个屏幕。
设置浏览器大小
可以自定义浏览器的宽和高,浏览器默认打开大小为 400 像素(宽) X 580 像素(高)。
语法: .set_window_size(宽,高)。
操作:将浏览器的宽和高分别设置为 600 像素、 700 像素。
Xfce 终端中输入 driver.set_window_size(600, 700)。
结果:浏览器在屏幕中显示的大小为 600 像素(宽) X 700 像素(高)。
访问网页
访问网页就是输入 URL 后打开一个页面。
语法: .get()。
操作:访问蓝桥首页,URL 为 *********************** 。
Xfce 终端中输入 driver.get("***********************")。
结果:浏览器打开了蓝桥网站首页。
浏览器后退
浏览器后退是返回上一个网页。
语法: .back()。
操作:在上一个访问网页操作(访问蓝桥首页)后,返回打开浏览器时的默认页面。
Xfce 终端中输入 driver.back()。
结果:浏览器返回到打开浏览器时的默认页面。
浏览器前进
浏览器前进与浏览器返回表现相反,在浏览器返回后通过浏览器前进操作可以继续访问浏览器返回动作之前的网页。
语法: .forward()。
操作:在上一个浏览器后退操作(返回打开浏览器时的默认页面)后,使用浏览器前进功能再次访问蓝桥网站首页。
Xfce 终端中输入 driver.forward()。
结果:浏览器再次进入到蓝桥网站首页。
页面刷新
页面刷新是方法获取最新的数据。
语法: .refresh()。
操作:在上一个浏览器前进操作(再次进入到蓝桥网站首页)后,对网页进行刷新。
Xfce 终端中输入 driver.refresh()。
结果:网页进行了重新渲染。
关闭窗口
语法: .close()。
如果浏览器中打开了多个窗口,使用 close() 关闭的是当前窗口;如果只有一个窗口,使用 close() 则是关闭浏览器。
操作:在上一个页面刷新操作(刷新蓝桥网站首页页面)后,依次进行如下操作。
-
Xfce 终端中如下语句,打开国信蓝桥——1+X 证书制度试点页面 driver.find_element_by_css_selector("#nav-collapse .nav-link:first-child").click()。
-
使用 close() 方法关闭当前窗口 driver.close()。
结果:浏览器关闭了蓝桥网站首页窗口。
提示:在打开国信蓝桥——1+X 证书制度试点页面后,浏览器上显示的是国信蓝桥——1+X 证书制度试点页面,但关闭的却是蓝桥网站首页窗口。这是因为打开新的窗口后,没有进行窗口的切换,selenium 还停留在蓝桥网站首页窗口,只不过所看到的是国信蓝桥——1+X 证书制度试点窗口而已,接下来的操作还是针对蓝桥网站首页窗口进行操作。在做完本次实验 “切换窗口” 小实验后相信会对浏览器窗口操作有一个更深的认识。
退出浏览器
语法: .quit()。
如果浏览器有多个窗口,使用 quit() 方法则关闭所有的窗口并且退出浏览器。
操作:关闭打开的浏览器。
Xfce 终端中输入 driver.quit()。
结果:浏览器退出。
获取页面 title
Title 指的是 HTML 脚本 head 中的 title 值。
语法: .title。
操作:依次输入下面语句访问蓝桥网站首页。
driver = webdriver.Chrome()
driver.get("***********************")
获取页面 title 并且打印 print(driver.title)。
打印结果:连接高校和企业 - 蓝桥。
获取页面 url
获取当前页面的 URL。
语法: .current_url。
操作:获取当前页面 URL 并且打印 print(driver.current_url)。
获取页面源码
获取当前页面源代码。
语法: .page_source。
操作:获取当前页面源码并且打印 print(driver.page_source)。
为了接下来的实验进行时更清楚观察,暂时退出浏览器 driver.quit()。
打印结果:

切换窗口
当浏览器打开多个窗口,要对当前窗口以外的窗口进行操作时,就需要先切换到目标窗口才可以进行操作。确定具体窗口需要使用窗口句柄定位,然后进行切换。
语法:
- 获得当前窗口句柄 .current_window_handle。
- 获取所有的窗口句柄 .window_handles。
操作:根据下面语句访问蓝桥网站首页,然后进行窗口切换操作。
- driver = webdriver.Chrome()。
- driver.get("***********************")。
- 打开国信蓝桥——1+X 证书制度试点页面 driver.find_element_by_css_selector("#nav-collapse .nav-link:first-child").click()。
- 打印当前页面的 title print(driver.title)。
打印结果:连接高校和企业 - 蓝桥。
5. 打印当前窗口句柄 print(driver.current_window_handle)。
打印结果:CDwindow-21F04009ED58ABA8DBF0B4EA4F67C779。
6. 打印所有窗口句柄 print(driver.window_handles)。
打印结果:['CDwindow-21F04009ED58ABA8DBF0B4EA4F67C779', 'CDwindow-FBBB5A65E5B4AB0D7ECC8F00385274AC']。
7. 由结果可知,所有句柄返回的是一个列表,当前窗口句柄为第一个值,根据列表索引通过句柄进行窗口切换 driver.switch_to.window(driver.window_handles[1])。
再次打印当前页面的 title print(driver.title)。
打印结果:国信蓝桥——1+X 证书制度试点页面。
由打印的页面 title 可知,窗口切换成功。
8. 退出浏览器 driver.quit()。
操作滚动条
当页面上的某些元素不在浏览器的可见视野中,如果要操作就需要滑动滚动条使元素可见,而滚动条的操作需要借助 JavaScript 完成。
语法:
- 移动到页面顶部: .execute_script("window.scrollTo(document.body.scrollHeight,0)")。
- 移动到页面底部: .execute_script("window.scrollTo(0,document.body.scrollHeight)")。
- 移动到使元素顶部与窗口的顶部对齐位置: .execute_script("arguments[0].scrollIntoView();", element)。
- 移动到使元素底部与窗口的底部对齐位置: .execute_script("arguments[0].scrollIntoView(false);", element) 。
操作:根据下面语句访问蓝桥网站首页,然后操作进行滚动条操作。
- driver = webdriver.Chrome()。
- driver.get("***********************")。
- 移动到页面底部 driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")。
结果:滚动条滑动到页面底部。
4. 移动到页面顶部 driver.execute_script("window.scrollTo(document.body.scrollHeight,0)")。
结果:滚动条滑动到页面顶部。
5. 移动到使轮播图左侧的课程菜单顶部与窗口的顶部对齐位置。
通过 class 属性获取轮播图左侧的课程菜单 element = driver.find_element_by_class_name('course-nav')。
操作滚动条 driver.execute_script("arguments[0].scrollIntoView();", element)。
结果:轮播图左侧的课程菜单顶部与窗口的顶部对齐。
6. 移动到使页面 footer 中的微信标识底部与窗口的底部对齐位置。
通过 class 属性获取 footer 中的微信标识元素 element = driver.find_element_by_class_name('weixin')。
操作滚动条 driver.execute_script("arguments[0].scrollIntoView(false);", element)。
结果: footer 中的微信标识底部与窗口的底部对齐。
通过本次实验操作,对浏览器的行为操作有一个基本掌握。做完本次实验,不要只满足当前实验中的练习,在做完本次实验后对相关知识点要勤加练习才是。
对象操作
本次实验主要是对页面中元素对象操作的一些方法进行实战。例如鼠标左键单击、内容输入、获取元素的属性值、元素的状态判断。
知识点
- 单击元素
- 输入内容
- 清空内容
- 获取属性值
- 获取文本内容
- 对象显示状态判断
- 对象编辑状态判断
- 对象选择状态判断
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
对象操作
网页中的元素对象,由于属性不同而表现的行为就不同,操作也就不同。下面针对元素对象操作的一些方法进行实战练习。
在进行本次实验之前需要先进行下面的操作,在接下来的实验中将会在此基础上进行。
打开 Xfce 终端,依次输入下面语句,进入到 Python 环境,并且导入 webdriver,实例化 Chrome 浏览器后访问蓝桥首页(*********************** )。
python3
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("***********************")
单击元素
模拟鼠标左键操作,多用于按钮、a 链接等元素的单击事件。
语法: .click()。
操作:点击页面上的 【登录】。
Xfce 终端中输入 driver.find_element_by_xpath("//span[contains(text(),'登录')]").click()。 然后输入 driver.switch_to.frame('layui-layer-iframe1'),由于登录弹窗嵌套在 iframe 结构中,所以需要切换进入才能操作,在实验六中会详细介绍。
结果:页面弹出登录窗口。
提示:登录按钮所在的导航栏会根据浏览器的宽度、高度而做出变动,如果语句 driver.find_element_by_xpath("//span[contains(text(),'登录')]").click() 不生效的话,可使用 (driver.find_elements_by_xpath("//span[contains(text(),'登录')]"))[1].click() 。
输入内容
模拟按键输入,常用于输入框输入文本内容。
语法: .send_keys(text)。
操作:在上一个单击元素操作(打开登录弹窗)后,在第一个输入框中输入 “tynam”。
Xfce 终端中输入driver.find_element_by_css_selector("input[placeholder='手机号/邮箱']").send_keys('tynam')。

结果:登录窗口的第一个输入框中输入了文本 “tynam”。
清空内容
用于清除对象中的内容,常用于清除输入框的默认值。
语法: .clear()。
操作:在上一个输入内容操作(第一个输入框中输入文本 “tynam”)后,将第一个输入框中的内容清空。
Xfce 终端中输入 driver.find_element_by_css_selector("input[placeholder='手机号/邮箱']").clear()。
结果:登录窗口的第一个输入框中内容被清空。
获取属性值
元素对象的属性通常指 href、name、value、type 值等。
语法: .get_attribute(attribute)。
操作:在单击元素操作(打开登录弹窗)后,打印【登录】按钮的 class 值。
Xfce 终端中输入 print(driver.find_element_by_css_selector(".login-form-button").get_attribute('class'))。
打印结果:login-form-button ant-btn ant-btn-primary。
获取文本内容
元素对象的文本内容,一般是指元素在页面显示的文本内容。
语法: .text。
操作:在单击元素操作(打开登录弹窗)后,打印【登录】按钮的文本内容。
Xfce 终端中输入 print(driver.find_element_by_css_selector(".login-form-button").text)。
打印结果:登 录。
对象显示状态判断
语法: .is_displayed()。
元素对象在页面中显示,也可能被隐藏。is_displayed() 函数是一个布尔类型的函数,显示则返回 True,反之返回 False。
操作:在单击元素操作(打开登录弹窗)后,判断【登录】按钮的显示状态。
Xfce 终端中输入 driver.find_element_by_css_selector(".login-form-button").is_displayed()。
返回结果: True。
注意:对象显示与对象存在一定要做区分。对象显示指的是元素对象在 HTML 中存在,只是在页面上是否会显示。对象存在指 HTML 中是否存在,如果存在可能会显示在页面上,也可能不会显示在页面。
对象编辑状态判断
语法:.is_enabled()。
多用于判断 input、select 等标签元素的编辑状态。布尔类型的函数,可编辑则返回 True,反之返回 False。
操作:在单击元素操作(打开登录弹窗)后,判断第一个输入框的编辑状态。
Xfce 终端中输入 driver.find_element_by_css_selector("input[placeholder='手机号/邮箱']").is_enabled()。
返回结果: True。
对象选择状态判断
语法: .is_selected()。
用于判断元素的选中状态。布尔类型的函数,选中则返回 True,反之返回 False。
操作:在单击元素操作(打开登录弹窗)后,判断记住密码的复选框选中状态。
Xfce 终端中输入 driver.find_element_by_css_selector('.ant-checkbox-input').is_selected()。
返回结果: False。
如果手动将记住密码的复选框进行勾选,再次执行判断,则返回结果为 True。
通过本次实验对页面中元素对象进行鼠标左键单击、内容输入、获取元素属性值、元素状态判断进行实战,对元素对象的一些操作方法有一个基本掌握。
键盘和鼠标事件
本次实验主要介绍通过 Selenium 中提供的一些方法模拟鼠标和键盘的一些行为。键盘输入主要介绍 Keys 和 keyUp/keyDown,鼠标操作主要介绍鼠标右击、双击、悬停事件。
知识点
- Keys
- keyUp/keyDown
- 鼠标右击
- 鼠标双击
- 鼠标悬停
- 鼠标其他事件
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
键盘事件
键盘操作是指模拟用户使用键盘进行操作。有两种方法,一种是通过 send_keys 直接发送键值进行操作,另一种是使 keyUp/keyDow 方法发送键值进行操作。
在进行本次实验之前需要先进行下面的操作,在接下来的实验中将会在此基础上进行。
打开 Xfce 终端,依次输入下面语句,进入到 Python 环境,并且导入 webdriver,实例化 Chrome 浏览器后访问蓝桥首页(*********************** ),操作打开登录窗口,并切换到登录窗口所在的 iframe 中。
python3
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("***********************")
driver.find_element_by_xpath("//span[contains(text(),'登录')]").click()
driver.switch_to.frame('layui-layer-iframe1')
提示:登录按钮所在的导航栏会根据浏览器的宽度、高度而做出变动,如果语句 driver.find_element_by_xpath("//span[contains(text(),'登录')]").click() 不生效的话,可使用 (driver.find_elements_by_xpath("//span[contains(text(),'登录')]"))[1].click() 。
Keys
通过 send_keys 直接发送键值进行操作。实现键盘模拟操作时需要导入 Keys:from selenium.webdriver.common.keys import Keys。
常用的键盘操作及模拟方法如下表:
| 描述 | 模拟操作方法 |
|---|---|
| 全选(Ctrl+A) | send_keys(Keys.CONTROL, 'a') |
| 复制(Ctrl+C) | send_keys(Keys.CONTROL, 'c') |
| 剪切(Ctrl+X) | send_keys(Keys.CONTROL, 'x') |
| 粘贴(Ctrl+V) | send_keys(Keys.CONTROL, 'v') |
| 返回键(Esc) | send_keys(Keys.ESCAPE) |
| 制表键(Tab) | send_keys(Keys.TAB) |
| 空格键(Space) | send_keys(Keys.SPACE) |
| 退格键(BackSpace) | send_keys(Keys.BACK_SPACE) |
| 刷新键(F5) | Send_keys(Keys.F5) |
| 删除键(Delete) | Send_keys(Keys.DELETE) |
| 数字键 2(2) | send_keys(Keys.NUMPAD2) |
操作:点击【短信登录】进入到通过验证码登录画面,在【手机号】输入框中输入值 “321”,然后通过 Ctrl + C 和 Ctrl + V 组合键复制到【验证码】输入框中。
-
导入 Keys:from selenium.webdriver.common.keys import Keys。
-
点击【短信登录】进入到通过验证码登录画面 driver.find_element_by_xpath("//div[text()='短信登录']").click()。
-
在【手机号】输入框中输入值 “321” (driver.find_elements_by_css_selector("input[placeholder='手机号']"))[1].send_keys(321)。
-
通过 Ctrl + A 组合键全选【手机号】输入框中的值 (driver.find_elements_by_css_selector("input[placeholder='手机号']"))[1].send_keys(Keys.CONTROL, 'a')。
-
通过 Ctrl + C 组合键复制【手机号】输入框中的值 (driver.find_elements_by_css_selector("input[placeholder='手机号']"))[1].send_keys(Keys.CONTROL, 'c')。
-
通过 .clear() 方法清空【验证码】输入框 driver.find_element_by_css_selector("input[placeholder='验证码']").clear()。
-
通过 Ctrl + v 组合键将内容粘贴到【验证码】输入框 driver.find_element_by_css_selector("input[placeholder='验证码']").send_keys(Keys.CONTROL, 'v')。
结果:【验证码】输入框中输入了值 “321”。
keyUp/keyDown
在 ActionChains 中也提供了 keyUp(theKey)、keyDown(theKey) 和 sendKeys(keysToSend) 方法用来模拟键盘输入。
键盘操作是指模拟用户使用键盘进行操作。通常是操作 Shift、Ctrl 和 Alt 键。常用的有三种方法:
- keyUp(theKey):松开 theKey 键。
- keyDown(theKey):按下 theKey 键。
- sendKeys(keysToSend):发送某个键到当前焦点。
使用时需要导入 ActionChains from selenium.webdriver.common.action_chains import ActionChains。
操作:将鼠标光标放在【手机号】输入框中,使用 ActionChains 提供的方法将【手机号】输入框的值进行全选。
-
导入 ActionChains from selenium.webdriver.common.action_chains import ActionChains。
-
通过 ActionChains 提供的方法全选【手机号】输入框的值 ActionChains(driver).key_down(Keys.CONTROL).send_keys('a').perform()。
结果:【手机号】输入框的值被全部选中。
在上面操作中,在按下了 control 和 a 键后最后还使用了 perform() 方法。perform() 方法就是执行所有 ActionChains 中存储的行为,简单来说就是将整个操作事件进行提交执行。
鼠标事件
在其他实验中已经使用过鼠标单击操作 click(),除此之外 Selenium 还提供了右击、双击、悬停、拖动等方法,使用这些模拟方法时需要导入 ActionChains 类 from selenium.webdriver.common.action_chains import ActionChains。
鼠标右击
模拟鼠标右键单击事件。
方法: .context_click(element)。
操作:在当前页面进行鼠标右击。
-
定位需要右击的元素对象 element = (driver.find_elements_by_css_selector('.login-form-button'))[2]。
-
进行鼠标右击操作 ActionChains(driver).context_click(element).perform()
结果:鼠标右击后打开了,右键菜单。

鼠标双击
模拟鼠标鼠标左键双击事件。
方法:.double_click(element)。
操作:关闭登录弹框页面,点击蓝桥首页轮播图的右滑箭头。
-
在关闭登录框页面时需要退出 iframe 框体,回到之前的操作页面 driver.switch_to_default_content()。
-
关闭登录弹框页面 driver.find_element_by_class_name('layui-layer-close').click()。
定位轮播图的右滑箭头 element = driver.find_element_by_class_name('fa-angle-right')。
3. 进行鼠标左键双击操作 ActionChains(driver).double_click(element).perform()。
结果:可以看的轮播图的图片向左移动了两次。
鼠标悬停
将鼠标悬停在某个具体元素上。
方法: .move_to_element(element)。
操作:进入到【社区】页面,将鼠标移动到页面导航菜单的【实验楼】元素上。
- 进入到【社区】页面 driver.get('***********************questions/')。
- 定位【课程】元素 element = driver.find_element_by_xpath("//button[contains(text(),'课程')]")。
- 进行鼠标悬停操作 ActionChains(driver).move_to_element(element).perform()。
结果:可以看的鼠标悬停在【课程】元素上调出了二级菜单。
鼠标其他事件
除过以上介绍的几种鼠标事件,还有其他的一些鼠标操作方法。
| 事件 | 方法 | 使用 | 使用说明 |
|---|---|---|---|
| 鼠标拖动 | drag_and_drop(source, target) | ActionChains(driver).drag_and_drop(source, target).perform() | 将 source 对象拖放到 target 对象的位置 |
| 单击鼠标左键不放 | click_and_hold(element) | ActionChains(driver).click_and_hold(element).perform() | 在元素 element 进行鼠标左击并且不放松 |
| 移动到元素具***置 | move_to_element_with_offset(element, xoffset, yoffset) | ActionChains(driver). move_to_element_with_offset(element, 20, 10) .perform() | 将鼠标移动到 element 中 x=20,y=10 的位置,以元素 element 的左上处为原点 x=0,y=0。向右为 x 轴的正坐标,向下为 y 轴的正坐标。 |
| 释放鼠标 | release(element) | ActionChains(driver).release(element) |
本次实验主要对键盘输入 Keys 和 keyUp/keyDown,鼠标右击、双击、悬停事件进行实战。对键盘和鼠标操作的一些方法有一个基本掌握。
其他常用操作
本次实验主要介绍 selenium 提供的对下拉框、特殊 Dom 结构操作、frame 与 iframe 结构、JavaScript、截屏的操作方法。
知识点
- 下拉框操作
- 特殊 Dom 结构操作
- frame 与 iframe 结构
- JavaScript 调用
- 屏幕截图
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
下拉框操作
下拉框是比较常见的一种结构,WebDriver 在处理下拉框中提供了 Select 方法。使用时需要导入 Select,有两种导入的方法,选择其中的一个方法导入即可,因为它们的指向都是同一个文件。
from selenium.webdriver.support.ui import Select from selenium.webdriver.support.select import Select
Select 中对下拉框的选择项可以进行获取、选择、取消选择操作。
获取下拉框的选择项:
- options: 返回所有的选择项。
- all_selected_options: 返回所有已选中的选择项。
- first_selected_options: 返回选中的第一个选择项。
对选择项进行选择:
- select_by_index(index): 通过索引选择。
- select_by_value(value): 通过 value 值选择。
- select_by_visible_text(text): 通过文本值选择。
取消选择项的选择:
- deselect_all(): 取消全部的已选项。
- deselect_by_index(index): 根据索引取消选择项。
- deselect_by_value(value): 根据 value 值取消选择项。
- deselect_by_visible_text(text): 根据文本值取消选择项。
操作:对下拉框练习页面中下拉框进行操作。

- Xfce 终端中依次输入下面语句,启动浏览器并且访问下拉框练习页面。
python3
from selenium import webdriver
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome()
driver.get("https://labfile.oss.aliyuncs.com/courses/2335/60-0.html")
2.在操作下拉框时,需要先定位到下拉框。定位下拉框 select = driver.find_element_by_name('language')。
3.获取下拉框的第二个选项项文本值。索引是从 0 开始的,所以第二个选择项的索引为 1。print((Select(select).options)[1].text)。
结果:Html
4.通过索引选择第二个选择项 Select(select).select_by_index(1)。
结果:下拉框显示的值是第二个选择项 “Html”。
5.通过文本值选择 “PHP” 选择项 Select(select).select_by_visible_text("PHP")。
结果:下拉框显示的值是 “PHP”。
注:取消选择,适合下拉框是多选的情况。即存在属性 multiple=“multiple”。
特殊 Dom 结构操作
特殊 Dom 结构是指 Selenium 不能直接对元素进行操作,需要进行定位切换到它所在的 Dom 结构后才能对其元素进行操作。
操作:
Xfce 终端中依次输入下面语句,启动浏览器并且访问弹窗练习画面 特殊Dom结构操作 。
python3
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://labfile.oss.aliyuncs.com/courses/2335/60-1.html")
Windows 弹窗
常见的 Windows 弹窗有 alert、confirm 和 prompt 三种形式,由于这些弹窗结构不属于页面层结构,而是浏览器层结构,因此想要操作这些弹窗需要使用 driver.switch_to.alert 方法,切换到 Windows 弹窗后才可以进行操作。
alert 类提供了如下一些操作方法:
- accept():确定。
- dismiss():取消。
- text:获取弹出框里面的内容。
- send_keys(keysToSend):发送文本,对有提交需求的 prompt 提示消息框。
操作:点击弹窗练习画面中的【windows 弹窗】,打印弹出框里面的文本内容,然后点击【确定】。

- 点击【windows 弹窗】按钮 driver.find_element_by_css_selector("#windows input").click()。
结果:画面弹出了一个窗口。

2.切换进弹窗 alert = driver.switch_to.alert。
3.打印弹窗文本内容 print(alert.text)。
打印结果:你好,这里是 windows 弹窗。
4.点击【确定】关闭弹窗 alert.accept()。
结果:弹窗关闭。
非 Windows 弹窗
非 Windows 弹窗通常是通过单击事件改变 Dom 元素隐藏或显示的属性来控制窗口的显示。
操作:点击弹窗练习画面中的【非 windows 弹窗】,然后关闭弹窗。

- 点击【非 windows 弹窗】 driver.find_element_by_css_selector("#noWindows input").click()。
结果:打开弹窗。

2.点击非 windows 弹窗右上角的 “ x ” 关闭弹窗 driver.find_element_by_id('header-right').click()。
结果:弹窗关闭。
frame 与 iframe 结构
frame 标签有 frameset、frame 和 iframe 三种,frameset 和普通标签是一样的,不需要特殊处理,正常定位即可。但是如果是 iframe 和 frame 则需要特殊的处理。WebDriver 在 HTML 中查找元素时不会自动在 frame 结构中查找,需要引导 WebDriver 进入到 frame 结构中。使用 Selenium 提供的 switch_to.frame(reference) 方法可以进入到 frame 结构。
操作:访问 iframe 练习画面,并且在输入框中输入内容 “tynam”。
- Xfce 终端中依次输入下面语句,启动浏览器并且访问 iframe 练习画面 frame 结构操作 。
python3
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://labfile.oss.aliyuncs.com/courses/2335/60-2.html")
画面如图所示,由于输入框嵌套在 iframe 结构中,要想操作输入框则必须先切换到 iframe 中。

2.使用 id 定位 iframe, 切换进 iframe 结构 driver.switch_to.frame('iframeContainer')。
3.输入框中输入内容 “tynam” driver.find_element_by_id('search').send_keys("tynam")。
结果:输入框中输入了内容 “tynam”。
switch_to 除了切进 frame 结构,还有其他一些用法:
- switch_to_default_content():切出 frame,切换到 frame 结构后 WebDrvier 的操作都会在 frame 中进行,如果要对 frame 外的元素进行操作,则需要切出 frame 结构。
- switch_to.parent_frame():切换到上一层的 frame,多用于层层嵌套的 frame 结构。
JavaScript 调用
在自动化测试中,对某些元素的操作不能直接使用 Selenium 提供的方法,需要借助 javaScript 语句才能操作。在 WebDriver 中可通过 execute_script() 方法来执行 JavaScript 脚本。
例如在蓝桥首页点击【1+X 证书】后会重新打开一个窗口,而我们不需要重新打开,需要在当前窗口打开。控制是在当前窗口还是重新开启一个窗口是由元素属性 target="_blank" 来控制的。我们只需要使用 JavaScript 操作元素去掉 target 属性即可达到目的。
操作:
- Xfce 终端中依次输入下面语句,启动浏览器并且访问蓝桥首页。
python3
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("***********************")
2.JS 中获取【1+X 证书】元素,然后进行移除操作。最后执行 JS 语句。
js = "var el = document.getElementsByClassName('minor-nav-link')[3];" \
"el.removeAttribute('target','_blank');"
driver.execute_script(js)
3.点击【1+X 证书】 driver.find_element_by_css_selector(".home-right-menu .minor-nav-link:first-child").click()。
结果:在当前窗口打开 1+X 证书页面。
屏幕截图
当我们在自动化测试过程中,如果程序运行失败,那么就进行自动截取当前页面,保留记录,方便查看运行失败的原因。
WebDriver 提供了 4 种截屏方法:
- save_screenshot(): 获取当前窗口的屏幕截图,并且以 png 文件格式存储。
- get_screenshot_as_base64(): 以 base64 编码字符串的形式获取当前窗口的屏幕截图。
- get_screenshot_as_file(): 获取当前屏幕截图,使用完整的路径。如果有任何 IO error,返回 False,否则返回 True。
- get_screenshot_as_png(): 以二进制数据形式获取当前窗口的屏幕截图。
操作:截取当前窗口,并且将图片命名为 screenshot.png 并且保存在 /home/shiyanlou/Code/ 路径下。
driver.save_screenshot('/home/shiyanlou/Code/screenshot.png')
本次实验主要是在自动化测试过程中对一些特殊行为的操作进行实战练习,在实际项目中可能还会遇到许多其他特殊结构的操作,希望通过本次实验可以举一反三,可以从容应对各种操作。
时间等待和浏览器配置项
在脚本开发中,可能会因为页面未完全加载完成或由于浏览器对象的一些默认属性导致自动化测试出现停滞,本次实验将介绍脚本开发中三种时间时间等待和实例化浏览器对象时,通过一些设置对浏览器的某些默认属性进行更改。
知识点
- 时间等待
- 限制页面加载时间
- 配置 Chrome 浏览器
- SSL 证书错误处理
- 获取环境信息
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
时间等待
在网页操作中,可能会因为带宽、浏览器渲染速度、机器性能等原因造成页面加载缓慢,在自动化测试过程中造成某些元素还没有完全加载完成就进行下一步操作,导致程序抛出异常 “未找到定位元素”。此时可以通过添加等待时间来解决。
在 Python + Selenium 中,有三种时间等待的方式,强制等待、显示等待和隐式等待。
强制等待
强制等待是设置一个固定的线程休眠时间,通过 sleep(time) 方法来实验。它是 Python time 模块提供的一种非智能等待,如果设置等待时间为 3 秒则程序执行过程中就会等待 3 秒时间,多用于程序执行过程中观察执行效果。
time.sleep(time) 的时间单位默认是秒。
操作:验证 sleep(time) 是固定等待时间。
-
在 /home/shiyanlou/Code/ 目录下新建 time_practice.py 文件。
-
在 time_practice.py 中编辑代码,设置等待时间为 3 秒,且打印等待时间前后的时间。
# -*-coding: utf-8-*- import time from datetime import datetime print(datetime.now()) # 等待 3s time.sleep(3) print(datetime.now())
3.然后打开 Xfce 终端,输入下面命令运行 time_practice.py 脚本。
python3 /home/shiyanlou/Code/time_practice.py
结果:命令执行后打印等待时间前后的时间差为 3s。

显示等待
显示等待是指针对某个元素设置一个等待时间,通过 WebDriverWait() 方法实现。WebDriverWait() 一般会和 until() 和 until_not() 方法配合使用。例如,WebDriverWait().until() 程序执行时会对 until 中的返回结果进行判断,从而决定是否进行下一步。如果返回结果为 True 则进行下一步操作;如果返回结果为 False 则会不断地去判断 until 中的返回结果,直至超过设置的等待时间,然后抛出异常。
WebDriverWait().until_not() 与 WebDriverWait().until() 的判定结果相反。 WebDriverWait().until_not() 执行时如果 until_not 中返回结果为 False 则执行下一步,反之则不断地去判断 until_not 中的返回结果。
请看 WebDriverWait 的定义:
class WebDriverWait(object): def __init__(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None):
共有 4 个参数可供使用:
- driver:webdriver 实例,Chrome、IE、Firefox 等。
- timeout:超时时间,即等待的最长时间。
- poll_frequency:调用后面操作的频率,默认为 0.5s。
- ignored_exceptions:忽略的异常,默认为 NoSuchElementException。
在使用 WebDriverWait 是需要导入 from selenium.webdriver.support.ui import WebDriverWait。
until 中的判断通常通过 expected_conditions 类中的方法进行。使用时需要导入 from selenium.webdriver.support import expected_conditions。
操作:设置显示等待 10s,每隔 1s 尝试一次。
打开 Xfce 终端,输入下面语句。
python3
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
driver = webdriver.Chrome()
driver.get('https://labfile.oss.aliyuncs.com/courses/2335/20.html')
WebDriverWait(driver, 10, 1).until(expected_conditions.visibility_of_element_located((By.ID, 'search')))
结果:在查找 id="search" 元素时,每隔 1s 尝试查找一次元素显示在页面中,如果出现则进行下一步操作,直到时间超过 10s 程序抛出异常。
使用 expected_conditions 类常见的页面元素的判断方法:
- title_is: 判断当前页面的 title 是否等于预期结果。
- title_contains: 判断当前页面的 title 是否包含预期的字符串。
- presence_of_element_located: 判断元素是否被加到 dom 树下,该元素不一定可见。
- visibility_of_element_located: 判断元素是否可见,并且元素的宽和高都不为 0。
- presence_of_all_elements_located: 判断至少有一个元素存在于 dom 树下。
- text_to_be_present_in_element: 判断元素中的 text 文本是否包含预期的字符串。
- text_to_be_present_in_element_value: 判断元素中的 value 属性值是否包含预期的字符串。
- frame_to_be_availabe_and_switch_to_it: 判断 frame 是否可以 switch 进去,如果可以,则返回 True,并且 switch 进去,反之则返回 False。
- invisibility_of_element_located: 判断元素是否不存在于 dom 树或不可见。
- element_to_be_clickable: 判断元素可见并且可以操作。
- element_to_be_selected: 判断元素是否被选中。
- element_selection_state_to_be: 判断元素的选中状态是否符合预期。
- alert_is_present: 判断页面上是否存在 alert。
隐式等待
隐式等待是全局的针对所有元素设置的等待时间,通过 implicitly_wait(time) 方法来实现。这是 WebDriver 提供的一种智能等待,也称是对 driver 的一种隐式等待,使用时只需在代码块中设置一次。
操作:设置隐式等待时间为 10s。
打开 Xfce 终端,输入下面语句。
python3 from selenium import webdriver driver = webdriver.Chrome() driver.implicitly_wait(10)
结果:设置的 driver 隐式等待时间为 10 秒,则 driver 在以后操作中执行 find_element_by_xxx() 时如果找到元素就会立即执行下一个动作,不会完全等够 10 秒后才执行下一个动作。如果超过 10 秒还没有找到该元素,则抛出未能定位到该元素的错误。
限制页面加载时间
限制页面加载时间即设置页面加载的超时时间。通过 set_page_load_timeout(time) 方法实现。
操作:访问蓝桥首页,并且设置页面加载的超时时间为 10s。
打开 Xfce 终端,输入下面语句。
python3
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
driver = webdriver.Chrome()
driver.set_page_load_timeout(10)
try:
driver.get('***********************')
except TimeoutException:
print('页面加载超过10秒,强制停止加载....')
driver.execute_script('window.stop()')
结果:在访问蓝桥首页中,当页面加载时间超过 10s 后浏览器停止加载。
配置 Chrome 浏览器
屏蔽浏览器对 Selenium 的检测
在使用 Selenium 启动浏览器后,浏览器会检测到是被自动测试软件控制,而非人的行为,会提示 “Chrome 正受到自动测试软件的控制”。

解决方法:屏蔽浏览器的检测。在实例化浏览器对象进行设置:
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=options)
ChromeOptions 是一个配置 Chrome 启动时属性的类,使用该类可以对 Chrome 进行一些设置:
- 设置 Chrome 二进制文件的位置: binary_location。
- 添加启动参数: add_argument。
- 添加拓展应用: add_extension, add_encoded_extension。
- 添加实验性质的设置参数: add_experimental_option。
- 设置调试器地址: debugger_address。
禁止图片和视频加载
有时候为了提高网速,页面中不太关心图片和视频,此时可以禁止图片和视频加载:
options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images":2}
options.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(chrome_options = options)
设置编码
在项目测试中浏览器中默认的编码格式可能不是我们想要的,此时可以设置自己的默认编码格式,例如设置编码格式为 UTF-8:
options = webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
driver = webdriver.Chrome(chrome_options = options)
其他参数
除了以上几种参数外,还有以下参数也可以设置:
- 添加代理:options.add_argument("--proxy-server=http://192.10.1.1:8888")。
- 模拟移动设备:options.add_argument('user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1"')。
- 禁用 JS:option.add_argument("--disable-javascript")。
- 禁用插件:option.add_argument("--disable-plugins")。
- 禁用 java:option.add_argument("--disable-java")。
- 启动时最大化:option.add_argument("--start- maximized")。
- 添加扩展插件:options.add_extension('C:/extension/xxxx.crx')。
SSL 证书错误处理
SSL(Secure Sockets Layer,安全套接层)证书错误,它是浏览器一种安全机制引起的问题。一般情况下在以 HTTPS 模式访问目标 URL 时浏览器会提示安全问题或非信任站点。针对不同的浏览器有不同的处理方法,但是都是在实例化浏览器对象时添加设置参数,忽略不信任的证书或信任证书。下面是 Chrome 浏览器提示 SSL 证书错误。

Chrome 浏览器处理方式
Chrome 浏览器解决办法是在 ChromeOptions() 中添加 “--ignore-certificate-errors” 为 True 的选项:
from selenium import webdriver
options = webdriver.ChromeOptions()
# 添加忽视证书错误选项
options.add_argument('--ignore-certificate-errors')
driver = webdriver.Chrome(chrome_options=options)
driver.get('URL')
Firefox 浏览器处理方式
Firefox 浏览器解决办法是 FirefoxProfile() 中添加 “accept_untrusted_certs” 为 True 的选项:
from selenium import webdriver
profile = webdriver.FirefoxProfile()
# 添加接受不信任证书选项
profile.accept_untrusted_certs = True
driver = webdriver.Firefox(firefox_profile=profile)
driver.get('URL')
IE 浏览器处理方式
注:IE 浏览器不能在实验环境中安装,此项操作可在 Windows 系统中实战练习。
IE 浏览器可以通过使用 JavaScript 语句在页面中操作,忽略不信任证书的提示继续访问。

如上图所示【转到此网页(不推荐)】的 id="overridelink",可通过执行 JavaScript 语句 document.getElementById('overridelink').click() 执行页面的单击操作。
from selenium import webdriver
driver = webdriver.Ie()
driver.get('URL')
# 选择继续访问 URL
js = "javascript:document.getElementById('overridelink').click();"
driver.get(js)
driver.execute_script(js)
获取环境信息
在项目自动化测试中有时候需要对运行的环境有更详细的了解,比如程序在什么浏览器中执行、浏览器的版本号是多少等,此时可通过 capabilities[] 获取。
操作:获取系统名称后浏览器名称。
打开 Xfce 终端,依次输入下面语句。
python3 from selenium import webdriver driver = webdriver.Chrome() print(driver.capabilities['browserName'])
打印结果:chrome
当然,还可以获取运行环境的其他信息:
- browserName:获取浏览器名称。
- browserVersion:获取浏览器版本。
- platformName:获取操作系统名称。
- proxy:获取代理信息。
- timeouts:获取超时时间。返回的是一个字典。
本次实验主要是在自动化测试脚本开发中添加时间等待的三种方法以及在实例化浏览器对象时对其一些配置属性进行更改,在本次实验中浏览器的配置项只介绍了部分内容,在做完本实验后对浏览器的其他配置项均需要实战练习。
UnitTest 测试框架一
UnitTest 是 Python 自带的单元测试框架,在自动化测试框架中被用来组织测试用例的执行、断言和日志记录。除此之外,UnitTest 还提供了丰富的断言方法,用于判断测试用例执行后的结果与预期结果是否一致。
知识点
- UnitTest 简介
- VS Code 的使用
- TestFixture
- TestCase
- 断言 Assert
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
UnitTest 简介
UnitTest 单元测试框架是受到 JUnit 的启发,与其他语言中的主流单元测试框架有着相似的风格。其支持测试自动化,配置共享和关机代码测试。支持将测试样例聚合到测试集中,并将测试与报告框架独立。
UnitTest 官方文档参考网站:unittest --- 单元测试框架 — Python 3.8.19 文档
UnitTest 主要有四部分内容:
- TestFixture:测试脚手架,测试所需要进行的准备工作,以及所有相关的清理操作。
- TestCase:测试用例,一个 TestCase 的实例就是一个测试用例。它检查输入特定的数据时的响应。
- TestSuite:测试套件,用于归档需要一起执行的测试。将多个测试用例集合在一起就是一个 TestSuite。
- TestRunner:测试运行器,用于执行和输出测试结果的组件。

在获得测试用例后,将测试用例进行归档,集合在一起形成一个 TestSuite,然后 TextTestRunner 执行 run() 方法,将以 test 开头的方法当作测试用例就行执行,最后使用 TextTestResult 生成测试报告。完成一个完整的自动化测试流程。
VS Code 的使用
在此之前已经进行了七次实验,直到现在才使用 Python IDE,这是因为在前面的实验中希望多通过手动一个一个词进行练习,避免过多依赖。
在脚本开发中有多款 IDE 可供选择,比如 Pycharm、VS Code 等。在此选择 VS Code,有诸多优点:
- 轻量级。
- 界面美观,代码高亮效果好。
- 功能强大且易用。
- 跨平台 支持多种平台 Windows、Mac、Linux 等等。
VS Code 环境准备
在使用 VS Code 进行自动化脚本开发时,需要做一些准备工作。
-
在桌面启动 VS Code 程序。
-
安装 Python 插件。
如果不安装 Python 插件,则点击 【调试】 -> 【启动调试(快捷键 F5)】是不能运行代码的。会提示选择环境,而根本就没有可选环境。
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件,并安装。

使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,选择 Python3.5 解析器。

3.查看、安装外部库
直接在终端输入相应命令就可以进行查看、安装外部库。终端就相当于命令提示符(cmd)。
查看已安装包列表 pip3 list 。
安装外部库 pip3 install xxx 。例如安装 Selenium 库则可写成 pip3 install Selenium 。
TestFixture
TestFixture,测试脚手架。在自动化测试中许多用例都需要执行相同的测试准备和测试清理工作。这种情况下就可以使用 TestFixture 将准备工作、清理工作抽象出来实现代码复用。在 UnitTest 中,提供了两种方法用于准备工作 setUp() 和 setUpClass() ,了两种方法用于清理工作 tearDown() 和 tearDownClass()。
- setUp():测试用例执行前的准备工作,每个测试用例的前置条件。
- tearDown():测试用例执行完成后的善后工作,每个测试用例的后置条件。
- setUpClass():结合 @classmethod 装饰器一起使用,是所有测试用例执行的前置条件。
- tearDownClass():结合 @classmethod 装饰器一起使用,是所有测试用例执行的后置条件。
操作:分别使用 setUp()、tearDown()、setUpClass() 和 tearDownClass() 进行验证在测试执行过程中的运行状况。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建文件 test_fixture.py。
-
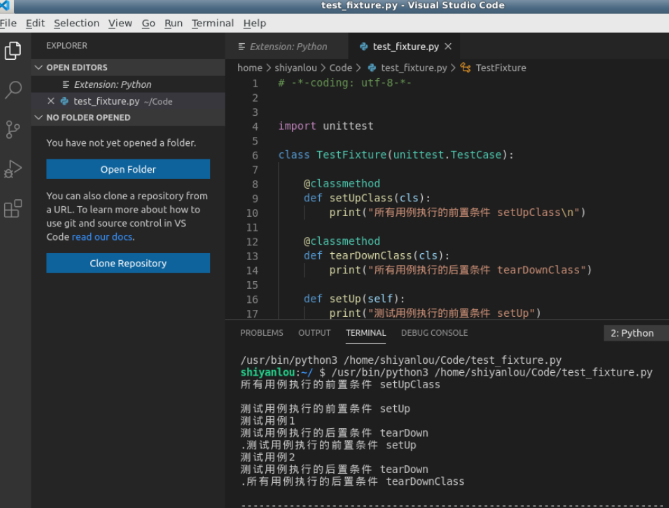
在 test_fixture.py 编写如下代码。两条测试用例方法,分别一条前置条件 setUp() 和 setUpClass(),分别一条后置条件 tearDown() 和 tearDownClass()。
# -*-coding: utf-8-*-
import unittest
class TestFixture(unittest.TestCase):
@classmethod
def setUpClass(cls):
print("所有用例执行的前置条件 setUpClass\n")
@classmethod
def tearDownClass(cls):
print("所有用例执行的后置条件 tearDownClass")
def setUp(self):
print("测试用例执行的前置条件 setUp")
def tearDown(self):
print("测试用例执行的后置条件 tearDown")
def test_01(self):
print("测试用例1")
def test_02(self):
print("测试用例2")
if __name__ == '__main__':
unittest.main()
3.VS Code 中进行运行。
运行结果:

setUpClass() 和 tearDownClass() 只执行一次并且在所有测试用例的前后,而 setUp() 和 tearDown() 在每一条测试用例的前后执行,有多少条测试用例就会执行多少次。
TestCase
每一个继承 TestCase 类的子类里面实现的具体的方法(以 test 开头的方法)都是一条用例。 一个完整的测试流程,包括测试前准备环境的搭建,执行测试代码,以及测试后环境的还原。元测试的本质也就在这里,一个测试用例是一个完整的测试单元,通过运行这个测试单元,可以对某一个问题进行验证。
操作:写一个类继承 unittest.TestCase,类中有两个方法,方法命名时一个以 test 开头,一个非 test 开头。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建文件 test_case.py。
-
在 test_case.py 编写如下代码。一个类继承 unittest.TestCase,类中有两个方法,方法命名时一个以 test 开头,一个非 test 开头。
# -*-coding: utf-8-*-
import unittest
class TestCase(unittest.TestCase):
def setUp(self):
print("测试用例开始执行")
def tearDown(self):
print("测试用例执行结束")
def add(self, a, b):
return a+b
def test_add(self):
print("test开头的方法")
result = self.add(2, 3)
assert result == 5
def add_test(self):
print("非test开头的方法")
result = self.add(2, 3)
assert result == 5
if __name__ == '__main__':
unittest.main()
3.VS Code 中进行运行。
测试用例开始执行 test开头的方法 测试用例执行结束 . ---------------------------------------------------------------------- Ran 1 test in 0.009s OK
只运行了以 test 开头命名的方法。在 UnitTest 框架中只将 test 开头的方法当作测试用例执行。
断言 Assert
断言用于判断实际结果和预期结果是否相等。如果断言失败则会标记该条测试用例执行失败。在 Python + UnitTest 结构中,有两种断言可供使用,一种是 Python 语言中提供的断言 Assert,另一种是 UnitTest 中提供的断言方法。
断言主要有 3 种类型:
- 布尔类型断言,即真或假,如果判断为真,则返回 True,反之返回 False。
- 比较类型断言,例如比较两个变量值的大小,如果判断为真,则返回 True,反之返回 False。
- 复杂类型断言,例如判断两个列表是否相等,如果相等,则返回 True,反之返回 False。
UnitTest 中提供的常用断言方法如下:
| 方法 | 说明 |
|---|---|
| assertEqual(a, b) | 判断 a 等于 b |
| assertNotEqual(a, b) | 判断 a 不等于 b |
| assertIs(a, b) | 判断 a 是 b |
| assertIsNone(a) | 判断 a 是 None |
| assertIn(a, b) | 判断 a 在 b 中,包含相等 |
| assertGreater(a, b) | 判断 a 大于 b |
| assertGreaterEqual(a, b) | 判断 a 大于等于 b |
| assertLess(a, b) | 判断 a 小于 b |
| assertLessEqual(a, b) | 判断 a 小于等于 b |
| assertListEqual(list1, list2) | 判断列表 list1 等于 list2 |
| assertTupleEqual(tuple1, tuple2) | 判断元组 tuple1 等于 tuple2 |
| assertDictEqual(dict1, dict2) | 判断字典 dict1 等于 dict2 |
操作:分别用 Python 和 UnitTest 提供的断言各写一条成功和失败的用例。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建文件 test_assert.py。
-
在 test_assert.py 编写如下代码。分别使用 Python 和 UnitTest 提供的断言各写一条成功和失败的用例。
# -*-coding: utf-8-*-
import unittest, time
class TestAssert(unittest.TestCase):
def setUp(self):
time.sleep(1)
def test_python_success(self):
print("python提供的断言,断言成功")
assert 1 == 1
def test_python_fail(self):
print("python提供的断言,断言失败")
assert 1 > 2
def test_unittest_success(self):
print("unittest提供的断言,断言成功")
self.assertIsNone(None)
def test_unittest_fail(self):
print("unittest提供的断言,断言失败")
self.assertIn('hello1', 'hello')
if __name__ == '__main__':
unittest.main()
3.VS Code 中进行运行。
python提供的断言,断言失败
Fpython提供的断言,断言成功
.unittest提供的断言,断言失败
Funittest提供的断言,断言成功
.
======================================================================
FAIL: test_python_fail (__main__.TestAssert)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/shiyanlou/Code/test_assert.py", line 17, in test_python_fail
assert 1 > 2
AssertionError
======================================================================
FAIL: test_unittest_fail (__main__.TestAssert)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/shiyanlou/Code/test_assert.py", line 25, in test_unittest_fail
self.assertIn('hello1', 'hello')
AssertionError: 'hello1' not found in 'hello'
----------------------------------------------------------------------
Ran 4 tests in 4.003s
FAILED (failures=2)
断言的成功与否不会影响代码的执行,即使断言失败代码也会继续执行。自动化测试中使用断言可判断测试用例是否通过。如结果所示使用 UnitTest 提供的断言比使用 Python 提供的断言在测试失败的结果中更详细的给出了失败原因,所以在自动化测试中要尽可能地使用 UnitTest 提供的断言,以方便查找断言失败的原因。
在上面的测试结果中可以看到,出现了 “ F ”、“ . ” 的标识,这些标识是对测试结果的一种表示。常见的测试标识有:
- .: 点,表示测试通过。
- F:failure,表示测试失败,未通过。
- s:skip,表示测试跳过,不执行该条测试用例。
- x:预期结果为失败的测试用例。
本次实验主要是对 Python 的单元测试框架 UnitTest 进行了解、VS Code 的使用以及测试准备与销毁的设置,认识测试用例,和测试过程中断言的实验练习,通过此次实验可对单元测试框架 UnitTest 框架基础知识点进行掌握。
UnitTest 测试框架二
在上一个实验中,对 UnitTest 的部分知识有所掌握,本次实验将对 UnitTest 进一步进行演练,主要介绍对测试用例的组织和运行,并且生成可视化测试报告。
知识点
- TestSuit
- TestLoader
- skip 装饰器
- TestRunner
- 可视化测试报告
VS Code 设置
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件,并安装。
使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,选择 Python3.5 解析器。
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
TestSuit
TestSuit,测试套件类,将多个独立的测试用例( test case )或者多个独立的测试套件( test suite )构建成一个测试套件。
可以通过 unittest.TestSuite() 类直接构建,也可以通过 TestSuite 实例的 addTest()、 addTests() 方法构建。
直接构建
操作:使用 TestSuit 直接构建测试套件。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建文件 test_suit_1.py。
-
在 test_suit_1.py 编写如下代码。三个测试用例 test1、test2、test3,然后使用 TestSuit 将 test1、test3 添加到测试套件中并且执行。
# -*-coding: utf-8-*-
import unittest
class TestSuit(unittest.TestCase):
def test1(self):
print('test1')
def test2(self):
print('test2')
def test3(self):
print('test3')
if __name__ == '__main__':
# 构建测试套件
suit = unittest.TestSuite(map(TestSuit, ['test3', 'test1']))
# 执行测试用例
unittest.TextTestRunner().run(suit)
3. VS Code 中进行运行。
test3 .test1 . ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK
unittest.TestSuite() 方法将需要执行的测试用例集合在一起,然后通过 unittest.TextTestRunner() 类中提供的 run() 方法执行。
在上述示例中用到了 map 函数,这是 Python 的一个内置函数,会根据提供的函数对指定的序列做映射。使用语法:map(function, iterable, ...)。第一个参数 function 表示以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
addTest() 构建
addTest() 也可以实现将测试用例添加到测试集中,但是一次只能添加一条测试用例。
操作:使用 addTest() 将 test1、test3 添加到测试套件中并且执行。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建文件 test_suit_2.py。
-
在 test_suit_2.py 编写如下代码。三个测试用例 test1、test2、test3,使用 addTest() 将 test1、test3 添加到测试套件中并且执行。
# -*-coding: utf-8-*-
import unittest
class TestSuit(unittest.TestCase):
def test1(self):
print('test1')
def test2(self):
print('test2')
def test3(self):
print('test3')
if __name__ == '__main__':
# 构建测试套件
suit = unittest.TestSuite()
suit.addTest(TestSuit('test3'))
suit.addTest(TestSuit('test1'))
# 执行测试用例
unittest.TextTestRunner().run(suit)
3. VS Code 中进行运行。
test3 .test1 . ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK
使用 addTest() 方法构建测试套件和直接使用 TestSuit 构建测试套件达到的效果是一样的。
addTests() 构建
addTests() 方法也可以实现构建测试套件,但是与 addTest() 方法有些许不同,addTests() 允许一次添加多条测试用例。
操作:使用 addTests() 将 test1、test3 添加到测试套件中并且执行。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建文件 test_suit_3.py。
-
在 test_suit_3.py 编写如下代码。三个测试用例 test1、test2、test3,使用 addTests() 将 test1、test3 添加到测试套件中并且执行。
# -*-coding: utf-8-*-
import unittest
class TestSuit(unittest.TestCase):
def test1(self):
print('test1')
def test2(self):
print('test2')
def test3(self):
print('test3')
if __name__ == '__main__':
# 构建测试套件
suit = unittest.TestSuite()
suit.addTests(map(TestSuit, ['test3', 'test1']))
# 执行测试用例
unittest.TextTestRunner().run(suit)
3. VS Code 中进行运行。
test3 .test1 . ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK
无论使用 TestSuite 直接构建,还是使用 addTest() 和 addTests() 进行构建,都可以达到相同的目的,即集合测试用例,最后使用 unittest.TextTestRunner() 类中提供的 run() 方法执行测试用例。
skip 装饰器
skip 装饰器用于跳过某个测试用例。在测试用例执行过程中如果某个测试用例不需要或者不希望执行,则只需要在其上面添加装饰器 “@unittest.skip()” 即可。 测试用例一旦被添加了 skip 装饰器则他所涉及到的测试准备 setUp() 和测试销毁 tearDown() 也会被跳过。
操作:使用 @unittest.skip() 跳过测试用例 test1。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建文件 test_skip.py。
-
在 test_skip.py 编写如下代码。三个测试用例 test1、test2、test3,在测试用例 test1 上添加 skip 装饰器 @unittest.skip(),将三个测试用例都进行执行。
# -*-coding: utf-8-*-
import unittest
class TestSuit(unittest.TestCase):
@unittest.skip('无条件跳过')
def test1(self):
print('test1')
def test2(self):
print('test2')
def test3(self):
print('test3')
if __name__ == '__main__':
# 构建测试套件
suit = unittest.TestSuite()
suit.addTests(map(TestSuit, ['test3', 'test2', 'test1']))
# 执行测试用例
unittest.TextTestRunner().run(suit)
3. VS Code 中进行运行。
test3 .test2 .s ---------------------------------------------------------------------- Ran 3 tests in 0.003s OK (skipped=1)
执行完成后,可以发现测试用例 test1 没有被执行。并且在结果中出现了 skipped=1 。
使用 skip 装饰器时可以有四种方式进行选择:
- @unittest.skip(reason):无条件跳过。reason 是描述跳过的原因。
- @unittest.skipIf(condition, reason):有条件跳过。当 condition 条件满足时才跳过。
- @unittest.skipUnless(condition, reason):有条件跳过。与 unittest.skipIf(condition, reason) 中的 condition 条件判断相反,当 condition 条件不满足时跳过。
- @unittest.expectedFailure:用于标记期望执行失败的测试方法。如果该测试方法执行失败,则被认为成功;如果执行成功,则被认为失败。
TestLoader
TestLoader 也是用来将测试用例添加到测试套件中,主要有以下几种方式:
- unittest.TestLoader().loadTestsFromTestCase(testCaseClass): 返回 testCaseClass 中包含的所有测试用例的套件。
- unittest.TestLoader().loadTestsFromModule(module):返回包含在给定模块中的所有测试用例的套件。
- unittest.TestLoader().loadTestsFromName(name, module=None):返回一组给定字符串说明符的所有测试用例。名称可以为模块、测试用例类、测试用例类中的测试方法,或其中的可调用对象,返回一个 TestCase 或 TestSuite 实例。
- unittest.TestLoader().loadTestsFromNames(names, module=None):返回使用给定序列找到的所有测试用例的套件说明符的字符串,用法和 loadTestsFromName 类似。
- unittest.TestLoader().getTestCaseNames(testCaseclass): 返回在 testCaseClass 中找到的方法名的排序序列。
- unittest.TestLoader().discover(start_dir, pattern=’test*.py’, top_level_dir=None):从 Python 文件中获取测试用例。
经常使用的便是 discover 方式获取测试用例。discover 中有三个参数:
- start_dir: 测试用例的路径。在什么路径下加载测试用例。
- pattern:一种匹配测试用例脚本名称规则,默认是 “test*.py”,即匹配所有以 test 开头的 py 文件,并将其作为测试用例脚本加载到测试套件中。
- top_level_dir:顶层目录的名称,默认为 None。
操作:使用 discover 方式加载测试用例。
-
使用 VS Code 在 /home/shiyanlou/Code/ 下新建目录 test_unittest, test_unittest 目录下新建文件 test_01.py。
-
test_01.py 中添加测试函数,test1、test2、test3。
# -*-coding: utf-8-*-
import unittest
class Test01(unittest.TestCase):
def test1(self):
print('test1')
def test2(self):
print('test2')
def test3(self):
print('test3')
3. 拷贝 test_01.py 两次,分别命名为 test_02.py 和 test_03.py 。
4. test_unittest 目录下新建文件 main.py。并且使用 discover 方式加载测试用例。
# -*-coding: utf-8-*- import unittest if __name__ == '__main__': testLoader = unittest.TestLoader() discover = testLoader.discover(start_dir='./', pattern="test*.py") print(discover) runner = unittest.TextTestRunner().run(discover)
此时的 test_unittest 目录下有四个文件 test_01.py、test_02.py、test_03.py 和 main.py。

5. VS Code 中运行 main.py。
<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<test_01.Test01 testMethod=test1>, <test_01.Test01 testMethod=test2>, <test_01.Test01 testMethod=test3>]>]>, <unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<test_02.Test01 testMethod=test1>, <test_02.Test01 testMethod=test2>, <test_02.Test01 testMethod=test3>]>]>, <unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<test_03.Test01 testMethod=test1>, <test_03.Test01 testMethod=test2>, <test_03.Test01 testMethod=test3>]>]>]> test1 .test2 .test3 .test1 .test2 .test3 .test1 .test2 .test3 . ---------------------------------------------------------------------- Ran 9 tests in 0.001s OK
使用 discover 方式可以通过固定模式进行匹配所有测试文件中的所有测试用例,然后通过 run() 方法执行。
TestRunner
TestRunner 是使用 TextTestRunner 提供的 run() 方法执行测试用例。在前面的实验中已经使用过 run()。在使用 unittest.TextTestRunner (verbosity).run(testCase) 执行测试用例时可以通过设置 verbosity 参数控制输出测试结果的详细程度。一共有三个等级。
- 0 (quiet): 只显示全局执行结果和执行结果中用例的总数。
- 1 (default): 默认值,显示全局执行结果和执行结果中用例的总数,并且对每一条用例的执行结果都有标注(成功 T 或失败 F)。
- 2 (verbose): 显示全局执行结果和执行结果中用例的总数,并输出每一条用例的详细结果。
操作:将 /home/shiyanlou/Code/test_unittest/ 目录下 main.py 文件中 TextTestRunner() 设置参数 verbosity 的值为 2,再次运行脚本。
# -*-coding: utf-8-*- import unittest if __name__ == '__main__': testLoader = unittest.TestLoader() discover = testLoader.discover(start_dir='./', pattern="test*.py") print(discover) runner = unittest.TextTestRunner(verbosity=2).run(discover)
VS Code 中运行 main.py。
<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<test_01.Test01 testMethod=test1>, <test_01.Test01 testMethod=test2>, <test_01.Test01 testMethod=test3>]>]>, <unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<test_02.Test01 testMethod=test1>, <test_02.Test01 testMethod=test2>, <test_02.Test01 testMethod=test3>]>]>, <unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<test_03.Test01 testMethod=test1>, <test_03.Test01 testMethod=test2>, <test_03.Test01 testMethod=test3>]>]>]> test1 (test_01.Test01) ... test1 ok test2 (test_01.Test01) ... test2 ok test3 (test_01.Test01) ... test3 ok test1 (test_02.Test01) ... test1 ok test2 (test_02.Test01) ... test2 ok test3 (test_02.Test01) ... test3 ok test1 (test_03.Test01) ... test1 ok test2 (test_03.Test01) ... test2 ok test3 (test_03.Test01) ... test3 ok ---------------------------------------------------------------------- Ran 9 tests in 0.001s OK
使用 verbosity=2 等级输出的结果明显比默认等级 verbosity=1 结果更详细。每条测试用例都可以看到来自那个测试文件,执行通过后也使用 ok 表示,结果更清晰明了。
可视化测试报告
为了使测试报告可以美观,直观的进行查看,就需要通过一些方式将测试结果进行可视化输出。HTMLTestRunner 模块可用于生成可视化测试报告。
- 进入 HTMLTestRunner 官网 HTMLTestRunner - tungwaiyip's software 下载 HTMLTestRunner.py 文件并保存在 /home/shiyanlou/Code/ 下。

为了提高下载速度,大家可以通过如下命令进行下载:
cd /home/shiyanlou/Code/ wget https://labfile.oss-internal.aliyuncs.com/courses/2335/HTMLTestRunner.py
2. 将 HTMLTestRunner.py 移动至 Python 编辑器所在的目录 /usr/bin/ 下,便于 Python 在执行时可以找到 HTMLTestRunner.py 。 使用命令 sudo cp -r /home/shiyanlou/Code/HTMLTestRunner.py /usr/bin/。
3. 下载的 HTMLTestRunner.py 适合在 Python2 中使用,如果要在 Python3 中使用需要修改一些内容:
- 第 94 行,import StringIO 修改为 import io。
- 第 539 行,self.outputBuffer = StringIO.StringIO() 修改为 self.outputBuffer= io.StringIO()。
- 第 631 行,print >> sys.stderr, '\nTime Elapsed: %s' %(self.stopTime-self.startTime) 修改为 print(sys.stderr, '\nTimeElapsed: %s' % (self.stopTime-self.startTime))。
- 第 642 行,将 if not rmap.has_key(cls): 修改成 if not cls in rmap:。
- 第 766 行,将 uo = o.decode('latin-1') 修改成 uo = e。
- 第 772 行,将 ue = e.decode('latin-1') 修改成 ue = e。
4. 修改 /home/shiyanlou/Code/test_unittest/ 目录下 main.py 文件,使用 HTMLTestRunner 生成测试报告。
# -*-coding: utf-8-*-
import unittest
from HTMLTestRunner import HTMLTestRunner
if __name__ == '__main__':
testLoader = unittest.TestLoader()
discover = testLoader.discover(start_dir='./', pattern="test*.py")
# 生成 HTML 格式测试报告
with open('TestReport.html', 'wb') as f:
runner = HTMLTestRunner(
stream=f,
title="自动化测报告",
description="XXX项目自动化测试"
)
runner.run(discover)
HTMLTestRunner 中使用的参数说明:
- stream:测试报告写入存储区域。
- title:测试报告的标题。
- description:测试报告描述的内容。
5. VS Code 中运行 main.py。
代码执行完成后,在 /home/shiyanlou/Code/test_unittest/ 目录下生成了一个 TestReport.html 文件。

本次实验完成后,对 Python 的单元测试框架 UnitTest 可全流程掌握使用,并进行测试用例的收集、整合、运行及测试报告的输出。
docker 搭建 selenium-grid 环境
本次实验是通过 Docker 搭建 selenium-grid 分布式环境。通过分布式环境可以使测试脚本同时在不同的系统环境和不同的浏览器中运行。可以显著地提高了测试效率,缩短了测试完成需要的时间。
知识点
- Docker 简介
- Selenium Grid 简介
- 获取 docker-selenium 镜像
- 运行 Docker 镜像
- 使用 VNC Viewer
- 脚本运行
VS Code 设置
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件,并安装。
使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,选择 Python3.5 解析器。
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
Docker 简介
Docker 是一个开源的应用容器引擎,基于 Go 语言并遵从 Apache2.0 协议开源。Docker 是一个用于开发,交付和运行应用程序的开放平台。借助 Docker 可以与管理应用程序相同的方式来管理基础架构。通过利用 Docker 的方法来快速交付,测试和部署代码,可以大大减少编写代码和在生产环境中运行代码之间的延迟。
使用 Docker 可以自动执行自动化测试用例和持续集成、发布。除此之外还有诸多优点:
- 主机资源利用率高,直接运行在宿主机内核,不需要硬件虚拟化。
- 启动时间快, Docker 秒级比虚拟机快太多,虚拟机自身加载操作系统。
- 运行环境一致性,将应用同依赖环境打包成一个镜像,避免多处部署不一致。
- 部署简单,而官方提供了很多镜像可以直接使用,非常方便。
Selenium Grid 简介
Selenium Grid 是 Selenium 三大组件之一,至今发布了两个版本 Grid1 和 Grid2。在 Grid2 中 Selenium Grid 与 Selenium RC 服务器合并,使用时只需在 https://selenium-release.storage.googleapis.com/index.html 中下载一个 .jar 文件即可,该 jar 包已将远程 Selenium RC Server 和 Selenium Grid 集成在一起。例如有两台不同的操作系统机器,分别是 Windows 和 Mac OS X。每台机器均可运行一个 Firefox 浏览器和一个 Chrome 浏览器。当执行测试用例时,通过 Selenium Grid 将测试用例均匀指派给两台机器的不同的浏览器。由此可以拥有 4 个测试任务并行运行以完成测试,既测试了项目在不同系统下运行,也测试了项目在不同浏览器中运行。
Selenium Gird 主要有以下优点:
- 可以在不同系统和浏览器中运行测试。
- 可以同时测试多个浏览器类型和版本。
- 允许多线程并发运行。
Selenium Grid 是基于 Selenium RC 的分布式结构,由一个 Hub 节点和若干 个 Node 代理节点组成。其工作原理是 Selenium Scripts 发送请求调用 Hub 节点,然后通过 Hub 节点分发具体的测试用例到 Node 节点执行。

- Hub 是管理中心,用来管理各个代理节点的注册信息和状态信息,接受远程客户端代码的请求调用,然后将请求的命令转发给 Node 节点来执行。
- Node 可以理解为不同系统的测试机,如 Linux 系统、Mac OS X 系统,负责执行 Hub 分发的具体测试用例。
获取 docker-selenium 镜像
在实验环境中已经存在 Docker 环境,所以可以直接使用。
获取 docker-selenium 镜像,在 github 上有现成的镜像 https://github.com/SeleniumHQ/docker-selenium 。
本次实验需要获取 selenium/hub 、selenium/node-chrome、selenium/node-chrome-debug 三个镜像。其中 selenium/node-chrome-debug 启动后会启动一个 VNC Server,在脚本执行过程中,本地可以连上 VNC Server,通过界面查看服务器的脚本执行情况。
- 获取 selenium/hub 镜像 docker pull selenium/hub。

2. 获取 selenium/node-chrome 镜像 docker pull selenium/node-chrome。

3. 获取 selenium/node-chrome-debug 镜像 docker pull selenium/node-chrome-debug。

运行 Docker 镜像
- 启动 Hub docker run -d -p 4444:4444 -e GRID_MAX_SESSION=100 --name hub selenium/hub。
参数说明:
- run:运行一个镜像,创建出一个容器。
- -p 4444:4444 :映射容器里端口。
- -d:后台运行。
- --name:容器名称,这里直接把这个容器称为 hub。
2. 启动 Node docker run -d -p 5555:5555 -e NODE_MAX_INSTANCES=5 -e NODE_MAX_SESSION=5 --shm-size=2g --link hub:hub --name node1 selenium/node-chrome。
参数说明:
- --link 是链接别名为 hub 的容器。
3. 启动 chrome-debug,开启 debug 模式 docker run -d -p 5900:5900 --link hub:hub selenium/node-chrome-debug。
4. 查看运行的容器 docker ps -a。

可以看到一共有三个容器在运行, selenium/hub 、selenium/node-chrome、selenium/node-chrome-debug。
5. 访问 Hub 节点查看配置。
使用 Docker IP 进行访问。也就是 hub 节点所在的服务器 IP :http://IP:4444/grid/console 。如果使用实验机器访问也可使用 http://localhost:4444/grid/console 进行访问。

使用 VNC Viewer
VNC (Virtual Network Console) 是虚拟网络控制台的缩写。是一款优秀的远程控制工具软件,在基于 UNIX 和 Linux 操作系统的免费的开源软件,远程控制能力强大,高效实用。
这里我们已经将 VNC 上传到服务器中,大家可以通过如下命令进行下载:
cd /home/shiyanlou/Code/ wget https://labfile.oss-internal.aliyuncs.com/courses/2335/VNC-Viewer-6.20.113-Linux-x86.deb
- 使用 dpkg 命令进行安装 sudo dpkg -i deb /home/shiyanlou/Code/VNC-Viewer-6.20.113-Linux-x86.deb。
如果在安装过程中出错则使用 sudo apt-get install -f 解决依赖关系的错误,然后再次安装。
2. 从【Applications】--> 【Internet】中打开 VNC Viewer。

3. 打开后输入访问的机器 IP,由于脚本是在 Node 机器中运行,所以输入 Node 机器的 IP。机器 IP 可以从 http://localhost:4444/grid/console 中进行查看。
进行访问时会要求输入密码,默认密码为 secret。

脚本运行
在脚本开发中需要调用 WebDriver 的 remote 方法。在使用 rmote 时有两种方式,指定 Node 节点和指定 Hub 地址。
指定 Node 节点
首先需要列出所有的 Node 节点以及对应需要启动的浏览器,然后在 for 循环中调用 remote 方法,在每一个节点中使用不同的浏览器执行测试代码。
-
在 /home/shiyanlou/Code/ 下新建脚本 grid_example.py。
-
编辑 grid_example.py 内容。
# -*-coding: utf-8-*-
import time
from selenium import webdriver
# node与其所需要启动的浏览器
nodes = {'http://172.17.0.4:5555/wd/hub': 'chrome'
}
for host, browser in nodes.items():
print(host, browser)
# 调用remote方法
driver = webdriver.Remote(command_executor=host,
desired_capabilities={'browserName': browser,
"platform": "Linux"
})
try:
# 操作步骤
driver.maximize_window()
driver.implicitly_wait(30)
driver.get('https://www.lanqiao.cn')
time.sleep(3)
except Exception as e:
print("发生异常错误")
print(e)
finally:
driver.quit()
3. 在 Xfce 终端中执行命令,运行脚本 python3 /home/shiyanlou/Code/grid_example.py。
通过 VNC Viewer 可观察到运行结果。启动 Chrome 浏览器并且最大化,然后访问实验楼首页,最后关闭浏览器。

指定 Hub 地址
指定 Hub 地址与指定 Node 节点的编程方法类似,只需要将 remote 方法中的 command_executor 参数值更改为 Hub 地址,选择启动的浏览器需要在 desired_capabilities 参数中指定。
修改 grid_example.py 内容。
# -*-coding: utf-8-*-
import time
from selenium import webdriver
# Hub 地址
hub = 'http://172.17.0.1:4444/wd/hub'
driver = webdriver.Remote(command_executor=hub,
desired_capabilities={'browserName': 'chrome',
"platform": "Linux"
})
try:
# 操作步骤
driver.maximize_window()
driver.implicitly_wait(30)
driver.get('https://www.lanqiao.cn')
time.sleep(3)
except Exception as e:
print("发生异常错误")
print(e)
finally:
driver.quit()
在 Xfce 终端中执行命令,运行脚本 python3 /home/shiyanlou/Code/grid_example.py。 通过 VNC Viewer 可观察到运行结果。与指定 Node 节点达到的效果是相同的,启动 Chrome 浏览器并且最大化,然后访问实验楼首页,最后关闭浏览器。
通过本次实验的实战,能够使用 Docker 搭建 selenium-grid 分布式环境,使测试脚本在不同的机器、不同的浏览器的并行运行,加快测试用例的运行速度。
测试模型
自动化测试模型是自动化测试框架和工具设计的一种思想。选择合适的测试模型有利于项目的开发和维护,应对项目版本的更迭。本次实验将介绍线性模型、模块化驱动模型、数据驱动模型、关键字驱动模型和一种国外比较流行的行为驱动模型。
知识点
- 线性模型
- 模块化驱动模型
- 数据驱动模型
- 关键字驱动模型
- 混合驱动模型
- 行为驱动模型
VS Code 设置
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件,并安装。
使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,选择 Python3.5 解析器。
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
线性模型
线性模型是指将录制或编写的脚本与应用程序的操作步骤对应起来,就像流水线工作一样,每一个步骤对应一行或多行代码。每一条流水线(每个测试脚本)都是相对独立的,且不产生其他依赖与调用,这样产生的脚本叫线性脚本。这是在自动化测试早期采用的一种测试模型,由于工作脚本是线性的,所以也叫线性模型。
线性模型的每一个脚本都是独立的,且几乎没有其他依赖和调用。每一个脚本就是一条测试用例,都可单独执行,但是也正是由于它太独立了,使得开发成本比较高,而且代码的复用性特别差。因为相同的步骤在不同的脚本中都要进行重新录制或编写,其应变能力较差,维护成本也特别高,如果项目某一个功能有变动,所有涉及的脚本都需要重新调整。
优点:
- 单个脚本相对完整,且独立,可拿出来单独执行。
缺点:
- 开发成本很高,重复操作多。
- 维护成本很高。
操作:在 /home/shiyanlou/Code/ 下新建脚本 linearity_example.py。编辑内容:
# -*-coding: utf-8-*-
import time
from selenium import webdriver
driver = webdriver.Chrome()
# 访问 URL
driver.get("https://www.lanqiao.cn")
time.sleep(1)
# 点击登录
driver.find_element_by_xpath("//span[contains(text(),'登录')]").click()
time.sleep(1)
# 切换 iframe
driver.switch_to.frame('layui-layer-iframe1')
# 输入用户名和密码
driver.find_element_by_css_selector("input[placeholder='手机号/邮箱']").send_keys('123456')
driver.find_element_by_css_selector("input[placeholder='密码']").send_keys('pwd')
# 点击登录
(driver.find_elements_by_css_selector('.login-form-button'))[0].click()
driver.quit()
linearity_example.py 中每一步骤一行代码,这样的代码几乎没有复用的可能。如果在项目中使用线性模型进行自动化测试开发,将是一件既苦又累的体力劳动。
模块化驱动模型
模块化驱动测试借鉴了开发编程的模块化思想,是将重复的代码提取到一个公共的模块,然后在需要的时候调用封装好的公共模块,如果项目某一个功能有变动,只需要变动相应的脚本,很大程度上提高了编写脚本的效率。比如,登录模块就可以封装在公共模块中,一旦模块中的元素定位有所变动或其他因素影响了模块,只需要在封装的模块中进行调整对应,而不会影响到任何测试用例,机动性、灵活性非常强。
模块化驱动模型可以很大程度地提高开发效率和增强代码的复用性,对于共同的或多次使用的模块独立封装,维护简单方便,模块变动时只需要对相应的模块封装即可。
优点:
- 提高开发效率,共同功能进行封装,复用性强。
- 维护方便。
在接下来的实验 PO 模型中会重点进行实战练习。
数据驱动模型
数据驱动测试是将测试数据和测试脚本分离,通过测试数据的改变驱动自动化的执行,从而产生不同的测试结果。简单地说,就是数据的参数化,输入不同的参数驱动程序执行,从而输出不同的测试结果。数据的保存形式可以是列表、字典,也可以保存在 Excel、数据库、xml 等外部文件中。
数据驱动测试中相同的操作步骤,只需要改变测试数据就能完成测试,能够快速地应对测试系统中的大量数据,迅速创建出数百个测试迭代和排列。
优点:
- 脚本复用性强。
关键字驱动模型
关键字驱动和数据驱动很相似,通过关键字的改变引起测试结果的改变,也称为表格驱动测试或基于动作字的测试。
关键字驱动模型将测试用例分为 4 个不同的部分:测试步骤、测试对象、测试对象操作和测试对象数据。
- 测试步骤:对测试步骤的一个动作描述,或者说是在测试对象上执行的动作描述。
- 测试对象:页面中元素对象的名称,例如邮箱、密码和登录等。
- 测试对象操作:测试对象上执行的动作名称,例如单击、打开浏览器、输入等。
- 测试对象数据:数据是指对测试对象执行操作所需的值,例如“邮箱”字段的值为 “tynam@test.com”。
Robot Framework 工具就是遵循关键字驱动模型开发的一个功能强大的测试工具,其封装了底层的代码,提供给用户独立的图像界面,以 “填表格” 形式编写测试用例,降低了脚本的编写难度。
优点:
- 编写脚本简单。
- 编写测试用例效率高。
- 维护简易。
混合驱动模型
混合驱动模型并不是一种真正意义上的测试模型,它是将模块化驱动、数据驱动和关键字驱动揉合在一起,取长补短,是在软件自动化测试实际应用中提练出来的一个产物。针对不同的应用场景,从 UI 层面、业务逻辑层面、数据层面或其他层面进行抽象,针对特定场景,混合驱动模型可以实现快速编写场景测试脚本和准备测试数据,以达到效率的最大化。
例如,针对登录模块,我们将页面封装成单独的模块,测试登录模块时利用数据驱动方式将测试数据保存在外部测试文件中,只需要改变测试数据就能达到预期的测试结果。其他功能模块调用登录模块时,使用模块化驱动模型传入一个特定的值就可以达到登录的目的。
优点:
- 即拥有脚本与测试数据相互分离的优点,又结合了模块驱动的架构。
- 试脚本更加简洁。
- 测试用例的维护复杂性降低,提升了脚本开发效率。
- 测试脚本的可复用性、移植性较强。
总之,混合驱动模型可以根据整个项目的特点选择适合的测试模式,在可读性、可维护性等方面有着显而易见的优点。
行为驱动模型
行为驱动开发英文名为 Behave Driven Development,简称 BDD,是一种敏捷开发方法,主要是从用户的需求出发强调系统行为。将此模型借鉴到自动化测试中称其为行为驱动测试模型,它是一种通过使用自然描述语言确定自动化测试脚本的模型。用例的写法基本和功能测试用例的写法类似,具有良好协作的益处。这种测试模型使每个人都可以参与到行为开发中,而不仅仅是程序员。每个测试场景都是一个独立的行为,以避免重复,并且已有的行为可以重复使用。
目前在 Python 中最流行的 BDD 框架是 Behave。使用时需要先安装 Behave。
打开 Xfce 终端,输入命令 pip3 install behave 进行安装 Behave。

待安装完成后配置临时环境变量,使 behave 在全局下都可使用, Xfce 终端中输入 export PATH=$PATH:/home/shiyanlou/.local/bin 。当然也可修改 profile 文件将环境变量设置为永久。
环境变量设置完成后可以使用命令 behave --lang-list 查看支持的语言。

使用命令 behave --lang-help “language” 查看对应语言的关键字。例如查看简体中文语言下的关键字,命令可写成 behave --lang-help zh-CN 。

在编写测试用例时需要依靠这些关键字,下面会做具体说明。
Behave 使用
以蓝桥登录操作为例进行 Behave 的使用。
- 搭建工程结构
在 /home/shiyanlou/Code/ 下新建如下结构文件和目录。

各目录和文件说明:
- features:存放场景文件。
- steps:features 目录下场景 .feature 文件对应的执行文件。
- environment.py:环境配置文件。
- report:存放测试报告文件。
- result:存放测试数据 JSON 文件。
2. 编写 feature 文件
在 features 目录下新建 login.feature 文件,作为登录场景测试用例,在文件中编写测试用例。
Feature: Login function test Scenario: Open the lanqiao home page When open the web page 【url】 Then assert lanqiao home page Scenario: Open the login window When open the sign window Scenario: Login test When enter phone number 【phone number】 and password 【password】 and sign Then login failed
关键字说明:
- Feature:功能测试名称。
- Scenario:场景名称。
- When:可以理解为测试步骤。
- Then:预期结果。
由于【url】、【phone number】和【password】是动态变化的,所以需要以参数的形式传入。暂时以这种括号的形式表示。
3. 配置 enviroment.py 文件
environment.py 文件主要用来定义一些测试执行前后的操作,比如启动和退出浏览器,类似于单元测试框架里的测试前置条件 setUp 和测试销毁 tearDown。
使用方法 before_feature(context, feature) 添加测试用例执行前的操作,使用方法 after_feature(context, feature) 添加测试用例执行后的操作。编辑 enviroment.py 内容如下:
# -*- coding: utf-8 -*- from selenium import webdriver def before_feature(context, feature): context.driver = webdriver.Chrome() context.driver.maximize_window() def after_feature(context, feature): context.driver.quit()
将浏览器启动并且最大化放在测试用例执行前的方法 before_featrue 中,将退出浏览器放在测试用例执行后的方法 after_featrue 中。函数中参数 context 用于存储信息以及在不同的 step 中分享信息,可以理解为超级全局变量。
4. 编写 steps
在 steps 目录下新建 login_steps.py 文件,存放登录页面的操作。steps 是通过修饰符来进行匹配的,修饰符是一串字符串,如果 feature 文件中 scenario 下使用的关键字和字符串与 steps 中某一个 step 关键字和字符串一致,则执行对应的 step 下的函数。
定义 open the web page "{url}"、assert lanqiao home page、open the sign window、enter phone number "{phone}" and password "{password}" and sign 及 login failed 几个步骤,与 feature 文件中操作步骤的语言字符串相匹配。
# -*- coding: utf-8 -*-
import time
from behave import *
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
@When('open the web page "{url}"')
def step_open(context, url):
context.driver.get(url)
time.sleep(5)
@Then('assert lanqiao home page')
def step_assert_open(context):
title = context.driver.title
assert title == "连接高校和企业 - 蓝桥云课"
@When('open the sign window')
def open_sign(context):
time.sleep(1)
context.driver.find_element_by_xpath("//span[contains(text(),'登录')]").click()
@When('enter phone number "{phone}" and password "{password}" and sign')
def step_login(context, phone, password):
context.driver.switch_to.frame('layui-layer-iframe1')
time.sleep(1)
phone_element = context.driver.find_element_by_css_selector("input[placeholder='手机号/邮箱']")
phone_element.send_keys(phone)
time.sleep(1)
password_element = context.driver.find_element_by_css_selector("input[placeholder='密码']")
password_element.send_keys(password)
time.sleep(1)
login_button_element = (context.driver.find_elements_by_css_selector('.login-form-button'))[0]
login_button_element.click()
@Then('login failed')
def step_assert_login(context):
WebDriverWait(context.driver, 3, 0.5).until(expected_conditions.visibility_of_element_located((By.CSS_SELECTOR, '.flash-message')))
login_text = context.driver.find_element_by_css_selector(".ant-message").text
assert login_text in ["用户不存在", "用户密码不正确"]
修饰符 @given、@when、@then 下的方法名以 step_xxx 命名方式实现,传递参数以大括号 {参数名} 来表示,当然还可以使用正则表达式来匹配。
5. 根据 steps 的操作修改 feature 文件,给对应的参数赋值。
Feature: Login function test Scenario: Open the lanqiao home page When open the web page "https://www.lanqiao.cn" Then assert lanqiao home page Scenario: Open the login window When open the sign window Scenario: Login test When enter phone number "123456789" and password "pwd123" and sign Then login failed
运行脚本
进入 /home/shiyanlou/Code/BddTest 下,直接输入命令 behave 运行脚本。

从运行结果中可以看出:
- 测试功能 Feature 以及测试场景 Scenario 和测试步骤 When、Then。
- 测试每一步骤的耗时时间,总的耗时时间。
- 每一个行代码在哪个文件中的哪一行。
- 测试结果统计,即 feature、scenarios、steps 通过、失败及跳过。
生成测试报告
Behave 库可以很好地与 Allure 结合生成可视化测试报告。Allure 是一款非常轻量级且灵活的开源测试报告生成框架,它支持绝大多数测试框架, 例如 TestNG、Pytest、JUint 等,使用起来很简单,也可配合持续集成工具 Jenkins 使用。
- 安装 Allure 程序。进入到 Allur e 网站 https://github.com/allure-framework/allure2/releases 进行下载,然后解压使用。
注意:因为 Allure 是基于 Java 的一个程序,所以使用时需要 Java 环境。最好是 Java1.8+ 环境。
在 Linux 下可以通过 npm 命令进行安装 npm install -g allure-commandline@2.13 --save-dev 。
安装完成后可以直接使用 命令 allure 进行验证是否安装成功。

2. 安装 allure-behave,使用命令 pip3 install allure-behave 进行安装。
3. 在 /home/shiyanlou/Code/BddTest 下再次使用 behave 命令,结合 allure 生成成 JSON 格式的测试数据并保存在 result 目录下 behave -f allure_behave.formatter:AllureFormatter -o result ./features 。
在 result 目录下生成 JSON 数据文件。

4. 通过 allure generate ./result/ -o ./report/ --clean 命令将 result 目录下的 JSON 格式的测试数据转换成测试报告并且保存在 report 目录下。
参数说明:
- generate:生成测试报告,后面跟测试数据路径。
- --clear:也可以写成 -c,清除 Allure 报告路径后再生成一个新的报告。
- -o:也可以写成 --report-dir 或 --output,生成报告的路径。

打开 index.html 可查看生成的测试报告内容。

注意:由于跨域等问题的影响,在打开 index.html 后可能会显示数据一直加载,404 等现象。可在 VS Code 中安装插件 Live Server ,然后右键点击,选择 Open with Live Server 进行打开。
通过本次实验将对各种自动化测试模型的优缺点有所了解。在了解优缺点后,针对不同的项目需要选择合适的自动化测试模型,这样才有利于应对项目的持续发展、快速版本的迭代、提高代码的健壮性。
PO 模型一
PO 模型是页面对象模型,共有两次实验,本次实验主要对 PO 模型有个了解,对被测项目进行分析,然后搭建一个基础的项目结构,最后对一些常用的功能进行封装。
知识点
- PO 模型简介
- 项目解析
- 框架搭建
- 结构封装
VS Code 设置
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件,并安装。
使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,选择 Python3.5 解析器。
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
PO 模型简介
PO 模型英文为 Page Object Model,中文名称为页面对象模型。是自动化测试的一种设计模式,主要作用是将每一个页面当作一个 page class 类,并且将页面中所有的测试元素或测试功能封装成方法,在生成测试用例时通过页面类得到元素方法从而对元素进行操作。如此将页面定位和业务操作分离,即测试对象和测试脚本分离,标准化了测试与页面的交互方式。
PO 模型的一些参考文章:
- Martin Fowler 在 2013 年发表的一篇博客 《 PageObject 》 : Page Object
- Selenium 官方对 PO 模型解说: PageObjects · SeleniumHQ/selenium Wiki · GitHub
在项目实际应用中通过对脚本进行分层处理,一般情况下会分为三层:
- 对象库层,页面元素和一些特殊控件操作。
- 逻辑层,封装好的功能用例模块。
- 业务层,测试用例的操作。
如果需要大量的数据,还会多添加一层,数据层。存放测试数据。
这样做有诸多益处:
- 集中管理元素对象,便于应对元素的变化。
- 提高代码重用性,结构更加清晰,维护代码更容易。
- 后期维护方便,不需要重复的复制和修改代码。
项目解析
由于实验内容有限,本次实验对蓝桥网站的部分功能或页面进行实战。
- 登录功能
进入蓝桥首页后,点击【登录】会弹窗登录窗口,输入正确的用户名和密码便可登录成功。

2. 训练营页面
训练营页面只进行页面选择导航、检索功能、分页功能进行演示。

框架搭建
PO 模型可以很灵活地对项目结构进行配置,做到结构清晰,各司其职。根据 PO 模型的特点来搭建一个简单的项目结构。
使用 VS Code 在 /home/shiyanlou/Code/ 下新建项目文件 shiyanlouAutoTest 。

目录文件说明:
- config: 配置文件。
- data: 测试数据。存放上传数据,还可以细分,例如存放照片 image 目录、存放视频 video 目录、存放文本 txt 目录等。
- download: 存放下载的数据。存放下载的数据还可以细分,例如存放下载的照片 image 目录、存放下载的视频 video 目录、存放下载的文本 txt 目录等。
- drivers: 驱动文件,存放浏览器驱动,例如谷歌浏览器驱动 chromedriver、Edge 浏览器驱动 edgedriver 等。
- log: 日志文件,存放项目执行过程中的产生的 .log 文件。还可以添加 errorImage 目录存放用例执行失败时的页面截图。
- report: 测试报告,存放生成的 HTML 测试报告文件。
- test: 测试文件,存放测试脚本、测试用例等。
- common: 公用方法,项目相关的方法。
- pages: 以页面为单位,每个页面是一个 page class。
- case: 测试用例。
- runner: 对测试用例进行组织。
- utils: 存放一些其他的方法。主要存放和测试相关,但是与项目无关的一些文件。比如,日志生成文件、发送邮件文件等。
- HTMLTestRunner.py: 生成测试报告时使用的文件。
- readConfig.py: 读取配置文件的文件。
- run.py: 项目入口文件,主要是对 /test/runner 下组织的用例进行执行并且生成测试报告。
在框架搭建上要注意结构和层次的划分,良好的目录结构和层次划分可以使项目具有直观的可读性和扩展性。
分页结构封装
结构封装是对项目中常用的功能进行单独封装,便于后续项目中使用,提高代码的复用性。
数据量太大时需要对数据进行分页处理。分页也是常见的一种功能,接下来以蓝桥 - 训练营下的分页结构为例进行封装操作。

封装分页结构的思路:先定位到分页结构,再定位上一页、下一页或直接点击相应的页数。使其传入对应的值确定用户需要的操作,然后返回。
在 shiyanlouAutoTest/test/common/ 下新建项目文件 PagingOperation.py 。
编写代码如下:
# -*-coding:utf-8-*-
from time import sleep
from selenium.webdriver.common.by import By
class PagingOperation(object):
"""分页操作"""
def __init__(self, driver):
sleep(1)
self.driver = driver
# 分页整体定位
self.__paging = self.driver.find_element(By.CLASS_NAME, 'number-pagination')
# 页数
self.__pageing_number = self.__paging.find_elements(By.CSS_SELECTOR, '.page-link')
def __get_page(self, text):
"""获取分页"""
# 使翻页区域可见
self.driver.execute_script("arguments[0].scrollIntoView(false);", self.__paging)
sleep(3)
try:
if text == "上一页":
return self.__pageing_number[0]
elif text == "下一页":
return self.__pageing_number[-1]
else:
for paging_number in self.__pageing_number:
if paging_number.text == str(text):
return paging_number
except:
error = "只接收上一页、下一页和页面可见的整型数字"
print(error)
return
def paging_operation(self, text):
"""分页操作"""
if self.__get_page(text):
self.__get_page(text).click()
定义一个类 PagingOperation ,两个方法 paging_operation 和 __get_page,其中 __get_page 用来根据用户输入的字符串判断用户的操作,然后将需要操作的元素进行返回。在 paging_operation 中根据 __get_page 返回的元素进行相应的操作,进行分页跳转。
部分内容解释:
- self.driver.execute_script("arguments[0].scrollIntoView(false);", self.__paging) 是因为分页不在视野中无法操作,需要让分页结构出现。
- 在执行 self.driver.execute_script("arguments[0].scrollIntoView(false);", self.__paging) 后添加了一个时间等待 sleep(3) ,为了避免程序执行过快,相应的分页结构中的元素没有加载出来。
- self.__pageing_number = self.__paging.find_elements(By.CSS_SELECTOR, '.page-link') 因为分页操作中所有的可操作元素都有共同的属性 class='page-link' ,所以使用 find_elements 获取一组元素,然后通过列表的操作方式进行相应元素的操作。
接下来验证上面的定义的方法正确性。接着上面的代码继续输入如下内容:
if __name__ == '__main__':
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://www.lanqiao.cn/bootcamp/')
paging = PagingOperation(driver)
paging.paging_operation(3)
paging.paging_operation("上一页")
paging.paging_operation("下一页")
paging.paging_operation(123)
# driver.quit()
在 VS Code 中直接运行,结果是:启动 Chrome 浏览器,然后访问 蓝桥 - 训练营页面,滑动滚动条使分页出现在视野中,然后点击第三页,接着操作上一页,下一页。当执行 paging.paging_operation(123) 时,由于 123 找不到,此时控制台会打印 "只接收上一页、下一页和页面可见的整型数字" 。
页面选择导航封装
在蓝桥网站中,页面选择导航是经常会进行操作的一个功能,所以选择将其单独封装。

功能分析:导航功能中全部为一级菜单,可以直接点击操作。所以在封装时只需要将操作的文本值传入,如果传入的文本与导航中的文本值相等则进行点击操作。
封装思路:先定位到导航菜单,根据用户传入的值进行判断,如果传入的文本与导航中的文本值相等则进行点击操作。
在 shiyanlouAutoTest/test/common/ 下新建项目文件 PageMenuOperation.py 。
编写代码如下:
# -*-coding:utf-8-*- from time import sleep from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC class PageMenuOperation(object): """页面菜单操作""" def __init__(self, driver): sleep(1) self.driver = driver def select_menu(self, menu_text): __nav = self.driver.find_elements(By.CSS_SELECTOR, '.nav-item a') WebDriverWait(self.driver, 20, 0.5).until(EC.visibility_of_element_located((By.CSS_SELECTOR, '.nav-item a'))) try: for nav in __nav: if menu_text == nav.text: nav.click() return except: err = "所输入的菜单名称未找到" print(err) return
定义一个类 PageMenuOperation ,一个变量 __nav 和一个方法 select_menu。使用 __nav 获取所有的菜单元素,在 select_menu 进行循环获取导航的文本值,根据用户输入的文本内容与导航菜单中的文本值进行相等判断,如果相等则对对应的元素进行点击操作。
接下来验证上面的定义的方法正确性。接着上面的代码继续输入如下内容:
if __name__ == '__main__':
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get('https://www.lanqiao.cn/louplus/')
PageMenu = PageMenuOperation(driver)
PageMenu.select_menu("竞赛")
PageMenu.select_menu("社区")
#driver.quit()
VS Code 中直接执行脚本,结果是:启动 Chrome 浏览器,访问 蓝桥云课楼+ 页面,然后点击页面菜单导航栏中的竞赛进入了竞赛页面,接着点击社区进入社区页面。
本次实验是 PO 模型实验的第一次实验,做完本次实验需要重点理解框架结构和常用功能的封装。合适的项目结构可以使项目逻辑层次明了、管理方便,好的结构封装可以减少代码量、增加代码的复用。
PO 模型二
实验介绍
PO 模型的第二次实验,根据项目的功能模块或页面进行对应的模块封装,对基础页面、登录功能和训练营页面进行封装。
知识点
- 配置文件
- 页面封装 - 基础页面
- 页面封装 - 登录功能
- 页面封装 - 训练营页面
项目准备
本次实验是接着【PO 模型一】实验继续进行。大家可以通过如下命令下载上一个实验的代码:
cd /home/shiyanlou/Code/ wget https://labfile.oss-internal.aliyuncs.com/courses/2335/130-code.zip
下载后进行解压:
unzip 130-code.zip
VS Code 设置
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件,并安装。
使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,选择 Python3.5 解析器。
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
配置文件
配置文件用来存放项目中的基础数据,例如 URL、登录用户名和密码等。也可用来进行项目的一些配置,例如使用 Chrome 浏览器进行运行,本次实验以 Chrome 浏览器进行,所以就不在此进行配置说明。接下来以 JSON 格式文件操作演示。
配置文件
使用配置文件进行存放蓝桥首页 URL、登录用户名和密码。
在 shiyanlouAutoTest/config/ 下新建配置文件 base_data.json 。内容填写蓝桥首页 URL、登录用户名和密码,如下:
{
"base_url": "https://www.lanqiao.cn/",
"phone": "13888888888",
"password": "tynam123"
}
读取配置文件
配置文件创建完成后,就需要对配置文件的内容进行读取。在 shiyanlouAutoTest/utils/ 下新建读取配置文件 ReadConfig.py,对文件内容读取进行封装。
# -*-coding:utf-8-*-
import os
import json
class ReadConfig(object):
"""
读取配置文件,Excel、josn 等文件的读取方法都可写在此类下
"""
def __init__(self):
pass
def read_json(self, json_file=None):
"""读取json文件"""
# 设置默认文件
if json_file is None:
current_path = os.path.abspath(os.path.dirname(__file__))
json_file = os.path.join(current_path, os.path.pardir, 'config/base_data.json')
try:
with open(json_file) as f:
data = json.load(f)
return data
except:
print("文件不存在或不是json文件")
定义一个类 ReadConfig ,一个方法 read_json ,read_json 方法中需要传入一个配置文件参数,如果不传入则默认读取 config 目录下的 base_data.json 文件。文件读取后以字典的形式返回。
接下来验证上面的定义的方法正确性。接着上面的代码继续输入如下内容:
if __name__ == '__main__': data = ReadConfig().read_json() print(data) print(data['base_url'], data['phone'], data['password'])
VS Code 中直接执行脚本,执行后控制台输出结果如下:
{'base_url': 'https://www.lanqiao.cn/', 'phone': '13888888888', 'password': 'tynam123'}
https://www.lanqiao.cn/ 13888888888 tynam123
页面封装 - 基础页面
页面封装是将每一个页面封装成一个类,所有页面的类都继承一个基础类,在基础类中封装 Selenium 的基础方法,从而在使用所有继承基础类的类时都可以使用封装的 Selenium 的方法。
作为基础页面类,所有的页面都会继承该类,需要封装 Selenium 的常用方法,例如,元素定位、时间等待等。还可以将常用的一些方法封装在内,例如打开浏览器默认进入的页面、菜单操作等。
在 shiyanlouAutoTest/test/pages 目录下新建基础页面 basePage.py ,编辑文件内容如下:
# -*-coding:utf-8-*-
import os, sys
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
current_path = os.path.abspath(os.path.dirname(__file__))
shiyanlou_path = os.path.join(current_path, os.path.pardir, os.path.pardir)
sys.path.append(shiyanlou_path)
from utils.ReadConfig import ReadConfig
class BasePage(object):
"""基础页面"""
def __init__(self, browser='Chrome', driver_path=None, url=None):
"""
基础的参数,browser、webdriver、默认访问的 url
:param browser: 浏览器
:param driver_path: 浏览器驱动
:param url: 默认打开的 url,一般都是蓝桥首页
"""
if driver_path is None:
driver_path = os.path.join(shiyanlou_path, 'drivers/chromedriver')
if url is None:
data = ReadConfig().read_json()
url = data['base_url']
self.base_url = url
else:
self.base_url = url
if browser == "Chrome":
self.driver = webdriver.Chrome(driver_path)
else:
print("请输入支持的浏览器")
# 默认打开蓝桥首页
self.open_page()
def open_page(self):
"""打开默认页面"""
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.driver.get(self.base_url)
try:
self.driver.find_element(By.CSS_SELECTOR, '.modal-content .btn-close').click()
return
except:
pass
sleep(1)
def close_page(self):
"""关闭页面"""
return self.driver.close()
def quit_driver(self):
"""关闭页面且退出程序"""
return self.driver.quit()
def find_element(self, element, by=By.CSS_SELECTOR):
"""返回单个定位元素"""
sleep(1)
return self.driver.find_element(by, element)
def find_elements(self, element, by=By.CSS_SELECTOR):
"""返回一组定位元素"""
sleep(1)
return self.driver.find_elements(by, element)
def switch_iframe(self, id):
"""iframe 切换"""
sleep(1)
return self.driver.switch_to.frame(id)
def switch_default_iframe(self):
"""iframe 切出"""
sleep(1)
return self.driver.switch_to_default_content()
定义了一个基础页面类 BasePage ,并且在实例化对象时设置了三个默认参数 browser、driver 和 url ,当使用时如果不传入特定的浏览器值则默认启动 Chrome 浏览器,url 默认使用配置文件中的 base_url,并且访问 base_url。
在 BasePage 基础类下封装了一些常用的方法:
- open_page():打开一个网页。
- close_page():关闭一个网页。
- quit_driver():关闭所有网页并且关闭浏览器。
- find_element():定位一个元素, CSS 定位方式作为默认定位方式。
- find_elements():定位一组元素, CSS 定位方式作为默认定位方式。
- switch_iframe():切换 iframe 。
- switch_default_iframe():切出 iframe 。
在 open_page() 函数下添加了一个 try 语句,这是因为网站会经常做一些活动,有一个弹窗提示。所以当出现弹窗后会尝试着去关闭,如果没有弹窗则 try 语句不执行。
接下来验证上面的定义的方法正确性。接着上面的代码继续输入如下内容:
if __name__ == '__main__': page = BasePage() # page.close_page()
VS Code 中直接执行脚本,结果是:启动 Chrome 浏览器,访问蓝桥首页。
页面封装 - 登录功能
由于登录功能是一个比较常用的功能,所以拿出来作为一个单独的页面。
在 shiyanlouAutoTest/test/pages 目录下新建登录功能页面 loginPage.py ,本次实验只进行正常的功能和业务逻辑实战,对异常的操作不做处理。编辑文件内容如下:
# -*-coding:utf-8-*-
import os, sys
from time import sleep
from selenium.webdriver.common.by import By
current_path = os.path.abspath(os.path.dirname(__file__))
shiyanlou_path = os.path.join(current_path, os.path.pardir, os.path.pardir)
sys.path.append(shiyanlou_path)
sys.path.append(current_path)
from utils.ReadConfig import ReadConfig
from basePage import BasePage
class LoginPage(BasePage):
"""登录功能页面"""
def __open_login_page_element(self):
# 打开登录窗口按钮
if (self.find_elements("//span[contains(text(),'登录')]", By.XPATH))[0].is_displayed():
return (self.find_elements("//span[contains(text(),'登录')]", By.XPATH))[0]
else:
return (self.find_elements("//span[contains(text(),'登录')]", By.XPATH))[1]
def __phone_element(self):
# 账号
return self.find_element("input[placeholder='手机号/邮箱']")
def __password_element(self):
# 密码
return self.find_element("input[placeholder='密码']")
def __login_button_element(self):
# 登录按钮
return (self.find_elements('.login-form-button'))[0]
def __get_account(self):
"""获取默认的登录账号和密码"""
data = ReadConfig().read_json()
phone = data['phone']
password = data['password']
return phone, password
def open_login_page(self):
"""打开登录弹窗且切换进登录 iframe"""
self.__open_login_page_element().click()
self.switch_iframe('layui-layer-iframe1')
def login(self, phone=None, password=None):
"""登录"""
# 获取配置文件账号和密码
default_phone, default_password = self.__get_account()
if phone is None:
phone = default_phone
if password is None:
password = default_password
self.__phone_element().clear()
self.__phone_element().send_keys(phone)
self.__password_element().clear()
self.__password_element().send_keys(password)
self.__login_button_element().click()
定义了一个 LoginPage 类,并且继承基础页面 BasePage 类。在 LoginPage 类下首先对所有需要定位的元素进行单个封装,打开登录窗口的按钮、用户名输入框、密码输入框及登录按钮。其次使用定位到的元素方法将打开登录窗口封装成 open_login_page() 方法,登录操作步骤封装成 login() 方法,并且设置默认的手机号和密码,默认值来于 __get_account(),而 __get_account() 是读取配置文件 base_data.json 中的内容并且将读取到的手机号和密码返回。
函数 __open_login_page_element() 下做了一次判断,大家可以在开发者工具下查找文字“登录”,而后查看登录按钮所在的导航栏,会发现导航栏存在两个,页面会根据浏览器的宽、高来判断使用那个导航栏,所以我们添加判断,那个登录按钮在页面显示就操作那个登录元素。
在对页面进行封装中,对每一个元素定位需要写上注释表明是那个字段,以增加代码的可读性,也方便后期维护。
接下来验证上面的定义的方法正确性。接着上面的代码继续输入如下内容:
if __name__ == '__main__': login = LoginPage() login.open_login_page() login.login() # login.close_page()
VS Code 中直接执行脚本,结果是:启动 Chrome 浏览器,访问蓝桥首页,然后打开登录窗口,输入了用户名和密码然后点击登录。
页面封装 - 训练营页面
训练营页面是一个单独的页面,所以作为一个单独的页面进行封装。
在 shiyanlouAutoTest/test/pages 目录下新建训练营页面 bootcampPage.py ,训练营页面只进行页面选择导航、检索功能、分页功能进行演示。由于页面选择导航和分页功能已经作为共公方法在 shiyanlouAutoTest/test/common/ 下进行了封装,所以将公共方法引用在 basePage 中,以便后续所有继承 basePage 的文件都可使用。修改 basePage.py 内容如下:
# -*-coding:utf-8-*-
import os, sys
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
current_path = os.path.abspath(os.path.dirname(__file__))
shiyanlou_path = os.path.join(current_path, os.path.pardir, os.path.pardir)
test_path = os.path.join(current_path, os.path.pardir)
sys.path.append(shiyanlou_path)
sys.path.append(test_path)
from utils.ReadConfig import ReadConfig
from common.PageMenuOperation import PageMenuOperation
from common.PagingOperation import PagingOperation
class BasePage(object):
"""基础页面"""
def __init__(self, browser='Chrome', driver_path=None, url=None):
"""
基础的参数,browser、webdriver、默认访问的 url
:param browser: 浏览器
:param driver_path: 浏览器驱动
:param url: 默认打开的 url,一般都是蓝桥首页
"""
if driver_path is None:
driver_path = os.path.join(shiyanlou_path, 'drivers/chromedriver')
if url is None:
data = ReadConfig().read_json()
url = data['base_url']
self.base_url = url
else:
self.base_url = url
if browser == "Chrome":
self.driver = webdriver.Chrome(driver_path)
else:
print("请输入支持的浏览器")
# 默认打开蓝桥首页
self.open_page()
def open_page(self):
"""打开默认页面"""
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.driver.get(self.base_url)
sleep(1)
def close_page(self):
"""关闭页面"""
return self.driver.close()
def quit_driver(self):
"""关闭页面且退出程序"""
return self.driver.quit()
def find_element(self, element, by=By.CSS_SELECTOR):
"""返回单个定位元素"""
sleep(1)
return self.driver.find_element(by, element)
def find_elements(self, element, by=By.CSS_SELECTOR):
"""返回一组定位元素"""
sleep(1)
return self.driver.find_elements(by, element)
def switch_iframe(self, id):
"""iframe 切换"""
sleep(1)
return self.driver.switch_to.frame(id)
def switch_default_iframe(self):
"""iframe 切出"""
sleep(1)
return self.driver.switch_to_default_content()
def page_menu_operation(self, menu=[]):
"""页面菜单选择"""
return PageMenuOperation(self.driver).select_menu(menu)
def paging_operation(self, page):
"""分页操作"""
return PagingOperation(self.driver).paging_operation(page)
if __name__ == '__main__':
page = BasePage()
page.page_menu_operation(["竞赛"])
# page.close_page()
将公共页面菜单导航操作 PageMenuOperation 和翻页操作 PagingOperation 重新进行封装,以便更好的使用。在 BasePage 类中添加页面菜单选择方法 page_menu_operation() 和翻页操作方法 paging_operation()。
接下来对训练营页面的检索功能进行处理。编辑文件内容如下:
# -*-coding:utf-8-*-
import os, sys
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
current_path = os.path.abspath(os.path.dirname(__file__))
sys.path.append(current_path)
from basePage import BasePage
class BootcampPage(BasePage):
"""训练营页面"""
def __search_element(self):
# 搜索框
return self.find_element("form input[placeholder='搜索 课程/问答")
def search(self, text):
"""检索功能"""
sleep(3)
self.__search_element().clear()
self.__search_element().send_keys(text)
# 发送 “回车键”
self.__search_element().send_keys(Keys.ENTER)
定义了一个 BootcampPage 类,并且继承基础页面 BasePage 类。在 BootcampPage 类下对检索输入框元素进行封装 __search_element()。然后使用封装好的检索元素方法将其封装成 search(text) 方法,对输入框输入内容发送回车键进行确认检索。
接下来验证上面的定义的方法正确性。接着上面的代码继续输入如下内容:
if __name__ == '__main__': bootcamp = BootcampPage(url='https://www.lanqiao.cn/bootcamp/') bootcamp.search(123) # bootcamp.close_page()
VS Code 中直接执行脚本,结果是:启动 Chrome 浏览器,访问蓝桥 - 训练营,然后在右上角的检索处输入了 123 进行检索。
备注:当屏幕太小时,浏览器没有没有足够空间展开,可能会导致检索功能被隐藏。
做完本次实验对 PO 模型的页面封装又一个基本的掌握,在工作实践中,对页面的封装都是需要将页面元素和操作步骤分开进行,便于后续的维护。
PO 模型三
实验介绍
PO 模型的第三次实验,在 PO 模型的第二次实验中根据项目的功能模块或页面进行对应的模块封装,本次实验通过封装的模块进行编写测试用例,最后组织测试用例,运行自动化测试脚本。
知识点
- 测试用例生成 - 登录功能
- 测试用例生成 - 训练营页面
- 用例组织
- 设置项目入口
项目准备
本次实验是接着【PO 模型二】实验继续进行。大家可以通过如下命令下载上一个实验的代码:
cd /home/shiyanlou/Code/ wget https://labfile.oss-internal.aliyuncs.com/courses/2335/140-code.zip
下载后进行解压:
unzip 140-code.zip
VS Code 设置
在 VS Code 的应用商店(快捷键:Ctrl + Shift + X)里搜索 Python 插件,并安装。
使用快捷键 Ctrl + Shift + P(或 F1),在打开的输入框中输入 Python: Select Interpreter 搜索,选择 Python3.5 解析器。
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
测试用例生成 - 登录功能
在 shiyanlouAutoTest/test/case 目录下新建测试用例文件 testLogin.py,使用单元测试框架 UnitTest 进行组织测试用例。编辑代码如下:
# -*-coding:utf-8-*- import os, sys import unittest from time import sleep current_path = os.path.abspath(os.path.dirname(__file__)) test_path = os.path.join(current_path, os.path.pardir) sys.path.append(test_path) from pages.loginPage import LoginPage class TestLogin(unittest.TestCase): """登录测试用例""" @classmethod def setUpClass(cls): cls.login = LoginPage() @classmethod def tearDownClass(cls): cls.login.quit_driver() def test_login_001(self): self.login.open_login_page() self.login.login() def test_login_002(self): self.login.login(phone='123445', password='3333333')
将启动浏览器和关闭浏览器的操作分别放在测试的预置条件 setUpClass 和测试销毁 tearDownClass 中,进行测试登录的操作方法设置为 test_login_001()、test_login_002()。
在测试用例的命名中使用测试页面名称加阿拉伯数字命名的方式,可以控制自动化用例在执行中的顺序。
接下来验证上面的测试用例。接着上面的代码继续输入如下内容:
if __name__ == '__main__': unittest.main()
VS Code 中直接执行脚本,结果是:启动 Chrome 浏览器,访问蓝桥首页,然后打开登录窗口,输入了默认用户名和密码然后点击登录,接着清空了之前输入的用户名,并且输入了 '123445',然后清空了之前输入的密码,并且输入了 '3333333',然后点击登录。
测试用例生成 - 训练营页面
在 shiyanlouAutoTest/test/case 目录下新建测试用例文件 testBootcamp.py,使用单元测试框架 unittest 进行组织测试用例。编辑代码如下:
# -*-coding:utf-8-*-
import os, sys
import unittest
current_path = os.path.abspath(os.path.dirname(__file__))
test_path = os.path.join(current_path, os.path.pardir)
sys.path.append(test_path)
from pages.bootcampPage import BootcampPage
class TestBootcamp(unittest.TestCase):
"""训练营测试用例"""
@classmethod
def setUpClass(cls):
cls.bootcamp = BootcampPage(url='https://www.lanqiao.cn/bootcamp/')
@classmethod
def tearDownClass(cls):
cls.bootcamp.quit_driver()
def test_bootcamp_001(self):
self.bootcamp.paging_operation(3)
self.bootcamp.paging_operation("上一页")
self.bootcamp.paging_operation("下一页")
def test_bootcamp_002(self):
self.bootcamp.search('测试')
def test_bootcamp_003(self):
self.bootcamp.page_menu_operation("社区")
将启动浏览器和关闭浏览器的操作分别放在测试的预置条件 setUpClass 和测试销毁 tearDownClass 中,进行测试登录的操作方法设置为 test_bootcamp_001()、test_bootcamp_002() 和 test_bootcamp_003()。
接下来验证上面的测试用例。接着上面的代码继续输入如下内容:
if __name__ == '__main__': unittest.main()
VS Code 中直接执行脚本,结果是:启动 Chrome 浏览器,访问蓝桥 - 训练营页面,对训练营的分页进行操作,分页操作完成后进行检索,然后通过社区下拉菜单点击直播进入直播页面。
用例组织
测试用例完成后需要将 test/case 下测试用例组织在一起,将 shiyanlouAutoTest/test/runner 目录下 main.py 作为测试用例组织文件。编辑内容如下:
# -*-coding:utf-8-*-
import os, time, sys
import unittest
current_path = os.path.abspath(os.path.dirname(__file__))
shiyanlou_path = os.path.join(current_path, os.path.pardir, os.path.pardir)
sys.path.append(shiyanlou_path)
from utils.HTMLTestRunner import HTMLTestRunner
class Main:
def get_all_case(self):
"""导入所有的用例"""
current_path = os.path.abspath(os.path.dirname(__file__))
case_path = current_path + '/../case/'
discover = unittest.defaultTestLoader.discover(case_path, pattern="test*.py")
print(discover)
return discover
def set_report(self, all_case, report_path=None):
"""设置生成报告"""
if report_path is None:
current_path = os.path.abspath(os.path.dirname(__file__))
report_path = current_path + '/../../report/'
else:
report_path = report_path
# 获取当前时间
now = time.strftime('%Y{y}%m{m}%d{d}%H{h}%M{M}%S{s}').format(y="年", m="月", d="日", h="时", M="分", s="秒")
# 标题
title = u"实验楼自动化测试"
# 设置报告存放路径和命名
report_abspath = os.path.join(report_path, title + now + ".html")
# 测试报告写入
fp = open(report_abspath, "wb")
runner = HTMLTestRunner(stream=fp, title=title)
runner.run(all_case)
fp.close()
return
def run_case(self, report_path=None):
all_case = self.get_all_case()
self.set_report(all_case, report_path)
if __name__ == '__main__':
Main().run_case()
在 Main 类中,定义 get_all_case() 方法获取所有的测试用例,然后定义生成测试报告的方法 set_report(),最后使用 run_case() 方法运行获取到的所有测试用例并且生成测试报告。最后将整个自动化测试项目整理输出。
VS Code 中直接执行脚本,可以看到测试用例在执行,执行完成后在 shiyanlouAutoTest/report 下生成一个 html 测试报告。
打开报告,报告内容详情如下:

设置项目入口
每个项目都有一个入口文件,以对整个项目进行全盘整理、提取和运行。通过将项目的运行整合到一个运行文件中,可以实现只需要执行该文件即可运行整个项目的目的。
将项目中的 run.py 文件设置成入口文件,该文件可执行测试用例并输出测试结果。编写代码如下:
# -*-coding:utf-8-*- """ Created on 2020-06-06 Project: 实验楼自动化测试 @Author: Tynam """ import sys, os current_path = os.path.abspath(os.path.dirname(__file__)) sys.path.append(current_path) from test.runner.main import Main if __name__ == '__main__': Main().run_case()
VS Code 中直接执行脚本,可以看到测试用例在执行,执行完成后在 shiyanlouAutoTest/report 下生成一个 html 测试报告。
做完本次实验对 PO 模型的实验也全部完成。通过 PO 模型实验,在自动化测试工作开展中便可以从项目解析、框架搭建、常用结构封装、页面封装、用例组织、设置项目入口等几个方面进行。很多公司在项目中都会以 PO 模型为基础,混合数据驱动模型和其他的一些方式进行项目操作,对此还需要深入学习。
持续集成
实验介绍
持续集成可认为是在软件开发过程中只要项目有更改或者代码有变动就会自动运行构建和测试,反馈运行结果。本次实验将以持续集成工具 Jenkins 结合 PO 模型实验中做成的项目脚本进行持续集成在自动化测试中的应用。
知识点
- 持续集成简介
- Jenkins 安装
- 创建项目
- 任务定时
- 邮件发送
项目准备
本次实验需要使用【PO 模型三】实验产生的项目文件。大家可以通过如下命令下载上一个实验的代码:
cd /home/shiyanlou/Code/ wget https://labfile.oss-internal.aliyuncs.com/courses/2335/150-code.zip
下载后进行解压:
unzip 150-code.zip
其他环境准备
Chrome 浏览器对应版本 chromedriver 已经存放在 /usr/bin/ 目录下,无需再次进行操作。
持续集成简介
持续集成(Continuous Integration)简称 CI,是在软件开发过程中只要项目有更改或者代码有变动,就会自动运行构建和测试,反馈运行结果。自动化测试中使用持续集成有很多优点:
- 可以及时反馈结果,尽早将问题暴露出来。
- 快速构建。
- 提高迭代的效率。
- 定位问题更加容易。
常用的持续集成工具有 Jenkins、Travis、Codeship 和 Strider。Jenkins 是最常用的开源工具,它可以自动化各种任务,包括构建、测试和部署软件,并且支持各种运行方式,如可以通过系统包、Docker 或者一个独立的 Java 程序来运行。
本次实验以 Jenkins 工具进行实战。
Jenkins 安装
enkins 安装方法有多种,可以通过进入官方下载地址 jenkins.war 下载相应的安装包进行安装,也可以结合 docker 进行安装,本次使用 下载的 war 包进行安装。
- 打开 Xfce 终端,使用如下命令下载 war 包:
cd /home/shiyanlou/Code/ wget https://labfile.oss-internal.aliyuncs.com/courses/2335/jenkins.war
2. 输入命令 java -jar jenkins.war 启动 Jenkins。
首次启动会产生一个随机口令,产生的口令将会在解锁 Jenkins 中使用到,如下图便是本次启动后产生的随机口令。

3. 访问 Jenkins。由于 war 包中存在自带的 Jetty 服务器,在浏览器中输入 http://IP:8080 可进行访问,如果在本机访问也可写成 http://localhost:8080 。

4. 首次访问需要解锁。将第一步中产生的随机口令输入在 Administrator password 下输入框中,进行继续操作。
5. 进入选择插件页面,如果选择【Install suggested plugins】,Jenkins 将会安装认为可能会用到的插件。如下图便是选择安装默认插件,此过程会比较慢,需要耐心等待。为了方便起见,我们选择【Select plugins to install】进行安装,安装完成后将所需要的插件再导入。选择【Select plugins to install】后取消所有选择的插件,然后点击【Install】进行下一步。

6. 插件安装完成后需要设置管理员用户。填写用户名、密码、确认密码、全名和电子邮件地址。

7. 管理员用户设置完成后进行下一步,配置 Jenkins 的 URL,选择默认值进行下一步即可,至此 Jenkins 的配置完成。进入 Jenkins 主页。

8. 为了接下来的实验顺利进行,我们将所需的插件进行下载,并且解压。
wget https://labfile.oss-internal.aliyuncs.com/courses/2335/plugins.zip unzip plugins.zip
将解压的后的 plugins 文件移动到 /home/shiyanlou/.jenkins/ 下,替换原有的 plugins 。
创建项目
安装完成后,开始创建项目。
- 单击左边菜单栏中的【New Item】选项,开始创建任务,进入创建项目页面。

输入项目名,并且选择自由风格【Freestyle project】。然后点击【OK】进入到下一个画面。
2. 在【Description】填写项目描述。

3. 在【Build Trigger】下的【Build】中添加【Execute shell】执行 shell 脚本。

输入下面语句:
cd /home/shiyanlou/Code/150-code/shiyanlouAutoTest/ /usr/bin/python3 run.py
然后进行应用保存。保存后页面会返回项目画面。
4. 单击左侧菜单栏中的【Build Now】选项进行立即构建,会看到测试项目在运行,浏览器启动并且执行相应的操作。

5. 构建完成后,可以在对应的构建历史记录下,进行下拉菜单的选项,进入控制台页面【Console Output】,可以看到运行日志。

任务定时
在项目配置中单击【Build Trigger】并且勾选定期性构建【Build periodically】选项,对项目可以进行定时构建设置。构建设置的详细内容可通过右边的问号符号来查看。例如每 15 分钟构建一次则可写成 H/15 * * * * 。

定时构建字段遵循 cron 语法(但是与 cron 又略有不同),该字段每行包含 5 个字段,5 个字段之间使用 TAB 或空格进行分隔。例如,* * * * *,第一个字段为 MINUTE;第二个字段为 HOUR;第三个字段为 DOM;第四个字段为 MONTH;第五个字段为 DOW 。
- MINUTE:分钟数。取值范围 0 ~ 59 。
- HOUR:小时数,取值范围 0 ~ 23 。
- DOM:一个月中的第几天,取值范围 1 ~ 31 。
- MONTH:第几个月,取值范围 1~12 。
- DOW:一周之中的第几天,取值范围 0 ~ 7 其中 0 和 7 都表示星期日。
下面列出一些示例可供参考:
- 每 15 分钟构建一次(可能构建的时间为:07,:22,:37,:52):H/15 * * * * 。
- 在每小时的前 30 分钟内(即 0~30 分钟)每 10 分钟构建一次(可能构建的时间为:04,:14,:24):H(0-29)/10 * * * * 。
- 每周一至周五上午 9:45 到下午 3:45,每隔 2 小时并且在 45 分钟的时候构建一次:45 9-16/2 * * 1-5 。
- 每个工作日上午 9 点到下午 5 点每两小时构建一次(可能构建的时间为:上午 10:38,下午 12:38,下午 2:38,下午 4:38):H H(9-16)/2 * * 1-5 。
- 除 12 月外,每月 1 号和 15 号每天构建一次:H H 1,15 1-11 * 。
邮件发送
邮件发送是一个比较常用的功能,因为在任务运行完成后我们不可能每次都登录服务器查看结果,所以需要以固定的形式进行邮件发送,通知我们任务的执行结果。
注:由于实验环境中只开放了部分端口,所以在实验环境中邮件发送是不成功的。
插件安装
发送邮件需要安装邮件发送的插件【email ext recipients column】和 HTML 报告显示插件【HTML Publisher】。
在 Jenkins 主页面中选择【 Manage Jenkins 】,然后选择【 Manage Plugins 】进入插件管理。

选择可选插件【Available】选项卡,在查找中搜索 HTML 报告插件 HTML Publisher 进行安装。勾选 HTML Publisher 插件单击【Install without restart】即可完成安装。

重复上面 HTML Publisher 插件的步骤安装邮件发送插件【email ext recipients column】。
如果在安装过程中发现安装比较慢或安装失败的情况,可以在 Jenkins 插件管理站点 Index of /download/plugins 中下载对应的插件。
为了方便,所需的两个插件可以通过如下命令下载:
cd /home/shiyanlou/Code/ wget https://labfile.oss-internal.aliyuncs.com/courses/2335/email-ext-recipients-column.hpi wget https://labfile.oss-internal.aliyuncs.com/courses/2335/htmlpublisher.hpi
下载完成后在 Jenkins 插件管理的【Advanced】高级设置中上传插件,在上传插件【Upload Plugin】区域的文本框中添加插件文件,单击【Upload】按钮,完成插件安装。

如果插件安装成功则可以在【Installed】下查看系统已经成功安装的所有插件。
安装完成后,在 Xfce 终端使用快捷键 Ctrl + C 终止 Jenkins 程序,并且输入 java -jar jenkins.war 重新启动 Jenkins,使安装的插件生效。
HTML 报告配置
从项目页面单击【Configure】进入项目管理的配置中,对项目进行 HTML 报告配置。
选择【Post-build Actions】选项卡,在构建后操作区域单击【Add post-build action】选项,从下拉框中选择【 Publish HTML reports】选项发布 HTML 报告。
单击 Reports 后面的【Add】对 Reports 进行设置。在【HTML directory to archive】输入框中填写项目生成的测试报告存放路径,如 /home/shiyanlou/Code/150-code/shiyanlouAutoTest/report。
【Index page[s] 】输入框用于匹配 HTML 测试报告文件,默认为 index.html ,修改为 *.html。 *.html 意味着匹配所有的 HTML 文件。配置完成后进行应用并且保存。

返回到项目页面,再次执行【Build Now】对项目进行构建,执行完成后在项目左边菜单处会多出一个【HTML Report 】菜单项,其中将会存放所有的测试报告。

进入【HTML Report 】查看生成的测试报告,单击任意一个报告文件可查看详细内容。

获取发送邮箱的授权码
在邮箱设置中需要获取发送邮箱的授权码。以 163 邮箱设置为例。
- 进入 163 邮箱,点击设置中的 【pop3/smtp/imap】。

2. 开启 smtp 服务,如果没有开启,点击设置,手机号验证后勾选开启即可。

3. 设置客户端授权密码。

邮箱设置
注:由于实验环境中只开放了部分端口,所以在实验环境中邮件发送是不成功的。
在 Jenkins 中进行邮件配置,需要进行系统配置和项目配置两个部分。
-
在 Jenkins 主页中选择【 Manage Jenkins 】,然后选择【 Configure System 】进入系统配置。
-
在【Jenkins Location】输入框中添加管理员邮箱地址,管理员地址必须和下面发送邮件的邮箱配置的地址相同,否则容易发生许多不必要的错误。

3. 接下来在【Extended E-mail Notification】中配置邮箱服务。

- SMTP server:邮箱 SMTP 服务,例如 163 邮箱为 smpt.163.com。
- Default user E-mail suffix:默认用户电子邮件后缀。
- User Name: 用户邮箱地址,要与上面的系统管理员邮件地址一致。
- Password:授权码,填写的是授权密码并非登录密码。
- SMTP port:端口号,分 SSL 协议和非 SS L 协议,需根据不同的邮箱进行设置。
4. 编辑发送的邮件内容。

- Default Content Type:邮件发送内容样式,选择默认 HTML(text/html)。
- Default Subject:邮件主题。例如,QA-Build:$PROJECT_NAME - Build # $BUILD_NUMBER - $BUILD_STATUS!。
- Default Content:邮件内容模板,填写 ${SCRIPT,template="groovy-html.template"}。因为默认提供的邮件内容过于简单,所以使用 Email Extension Plugin 提供的 Groovy 标准 HTML 模板: groovy-html.template,也可以自定义模版。
配置完成后执行应用并且保存。
5. 对项目进行邮件发送的配置。进入到项目配置中,在【Post-build Actions】下添加【Editable Email Notification】电子邮件通知。
在【Project Recipient List】中添加收件人,收件人如果有多个则需要用分号分割标识,例如 tynam.yang@gmail.com;yangdingjia@qq.com。

6. 设置触发器。在邮箱设置下方点击【advanced setting】,展开后设置触发,删除默认的设置。

删除后在【Add Trigger】下拉列表中添加新的触发,选择 【Always】选项,即每次构建完成后都会触发邮件发送。
其他设置保持默认即可,然后应用并且保存设置。
7. 返回项目单击【Build Now】立即构建。等到自动化脚本执行完成后进入到接收的邮箱中查看邮件。

本次实验是 Python 自动化测试入门实战中最后一个实验,做完本次实验对持续集成有一个新的认识,对持续集成工具 Jenkins 从项目创建、任务定时、邮件发送等几个方面有一个深入的掌握。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 37
37 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)