hive 中 order by, sort by, distribute by, cluster by 的区别【详细】
hive 中 order by, sort by, distribute by, cluster by 的区别【详细】
文章目录
Order By(全局排序)
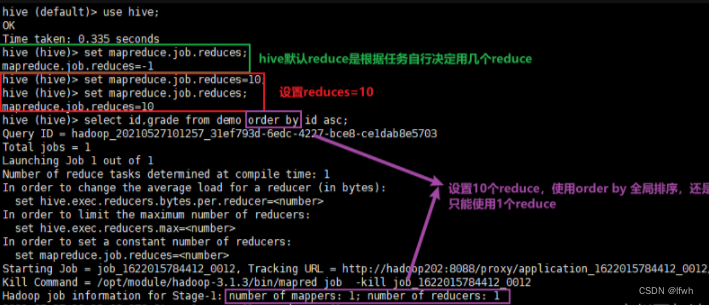
Order By 用于结果集的排序。也可以称之为全局排序。对于 MR 任务来说,如果我们使用了 Order By 排序,意味着MR 任务只会有一个 Reducer 参与排序。
在 Hive 中执行脚本时,我们可以通过set mapreduce.job.reduces = 10 来设置 reduce 的个数为 10。但只要使用了 Order By 排序,即使设置了 10 个reduce ,也是不会生效的。Order By 就是一个全局排序,只能用一个 Reduce 进行全局排序。

Sort By(每个reduce内部排序)
Sort By:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 sort by。Sort by 在每个 Reducer 内部进行排序,即使每个 reduce 内部是有序的,但是对于全局结果集 来说也还是乱序的。
Distribute By(指定分区规则)
Distribute by 是用来指定Distribute By 是用来指定分区规则的,它结合 Sort By 一起使用。上文介绍的单独使用 Sort By 对部门编号排序,因为没有指定分区规则,Sort By 则随机分区排序。Distribute By 类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。通常是先用 Distribute By 指定分区规则,然后再使用 Sort By 对分区内数据排序。
Cluster By(分区字段和排序字段相同时使用)
当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 ASC 或者 DESC。Cluster by 不常用的。
Sort By和Distribute By使用案例
1.假设我们有一个名为sales的表,包含以下字段:product_id、sale_date、quantity和revenue。我们想要按照product_id进行排序,并将数据按照product_id进行分区。
2.创建一个名为sales的表,并导入数据:
CREATE TABLE sales (
product_id INT,
sale_date DATE,
quantity INT,
revenue DECIMAL(10, 2)
);
INSERT INTO sales VALUES
(1, '2023-01-01', 10, 100.00),
(2, '2023-01-02', 5, 50.00),
(1, '2023-01-03', 8, 80.00),
(3, '2023-01-04', 12, 120.00);
3.使用Sort By和Distribute By来查询并排序数据:
SELECT *
FROM sales
SORT BY product_id
DISTRIBUTE BY product_id;
-
在上述示例中,SORT BY product_id用于按照product_id字段进行排序,DISTRIBUTE BY product_id用于按照product_id字段进行分区。
-
执行上述查询后,将按照product_id进行排序,并且数据将按照product_id进行分区。这样可以提高查询性能,使得相同product_id的数据在同一个分区中,方便后续的查询操作。
-
请注意,Sort By和Distribute By的使用可能会受到Hive版本和配置的影响。请根据您使用的Hive版本和具体需求,参考Hive的官方文档和相关资料,了解更多关于Sort By和Distribute By的用法和注意事项。
总结
如果此篇文章有帮助到您, 希望打大佬们能
关注、点赞、收藏、评论支持一波,非常感谢大家!
如果有不对的地方请指正!!!

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 20
20 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)