目标检测算法-transformer系列-YOLOS(附论文和源码)
目标检测算法-transformer系列-YOLOS(附论文和源码)
目标检测算法-transformer系列-YOLOS(附论文和源码)
一,YOLOS:
YOLOS:You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
本文2021年收录于arxiv,作者是华科&地平线。
1.1 摘要
Transformer能在对2D空间结构了解最少的情况下,从序列到序列的角度执行2D对象级别识别吗?
为了回答这个问题,作者提出了You Only Look at One Sequence(YOLOS) ,这是一个基于原始视觉Transformer的目标检测模型,尽可能少的进行模型修改和加入归纳偏置。作者发现,仅在ImageNet-1k数据集上预训练的YOLOS已经能够在COCO上实现具有竞争力的目标检测性能,例如,YOLOS Base可以实现42.0 的box AP。
1.2 YOLOS
在模型设计上,YOLOS遵循了ViT的结构,并且用DETR的方式来进行学习优化。YOLOS可以很容易地采用NLP和CV中的各种Transformer变体。这种简单的设置并不是为了获得更好的检测性能,而是为了尽可能准确的显示Transformer系列在目标检测中的特性。
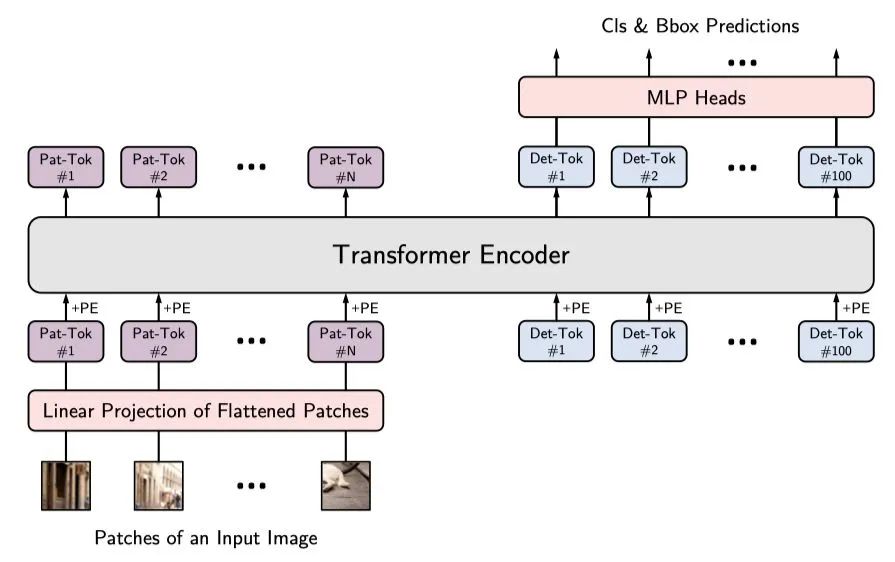
模型的结构如上图所示。从ViT到YOLOS检测器的改变很简单:
-
在ViT中丢弃了 [CLS] token,并向输入序列中添加100个可学习的 [DET] token用于目标检测。
-
将ViT中的图像分类损失替换为二分匹配损失,以便按照DETR的预测方式执行目标检测。
-
Detection Token 作者用随机初始化的 [DET] token作为对象表示的代理,以避免2D结构的归纳偏置和标签分配过程中注入任务的先验知识。在COCO数据集上进行微调时,对于每个向前传播,由[DET] token生成的预测和Ground Truth对象之间的最佳二分匹配被建立,从而执行目标检测任务。此过程起着与标签分配相同的作用,但并没有重建图像的2D结构,即,YOLOS不需要将ViT的输出序列重新解释为2D特征图以进行标签分配。
-
Fine-tuning at Higher Resolution 当在COCO上进行微调时,除了用于分类和BBOX规范的MLP参数以及DET外,其他参数均由ImageNet预训练而来。在YOLOS中,分类与BBOX头采用两层MLP实现且参数不共享。在微调阶段,图像具有比预训练更大的分辨率,作者保持块尺寸(16*16)不变,因而导致了更大的序列长度。作者采用了类似ViT的方式对预训练位置嵌入进行2D插值。
-
Inductive Bias 作者设计的YOLOS最大限度地减少了额外的假设偏置注入。ViT固有的假设偏置来源于网络主干部分的patch提取和位置嵌入的分辨率调整。除此之外,YOLOS没有添加其他额外的卷积操作。从表征学习的角度来看,作者选择使用[DET] token作为最终预测对象的代理,以避免额外的2D归纳偏置。此外,目标检测中常用的FPN,local attention和region-wise pooling等为了提高性能的操作在本文中都没有被采用。这是为了在最少的输入空间结构和几何知识的情况下,以纯序列到序列的方式揭示Transformer从图像识别到目标检测的多功能性和可迁移性。
-
Comparisons with DETR YOLOS的设计灵感来自于DETR:YOLOS使用[DET] token作为对象表示的代理,以避免关于二维结构的归纳偏置和标签分配期间注入任务的先验知识,并且YOLOS用类似于DETR的方式进行优化。然而,两者之间也有一些关键的区别:
-
DETR使用具有编码器-解码器架构的随机初始化Transformer,而YOLOS研究了预训练的仅编码器的ViT的可迁移性;
-
DETR在图像特征和对象查询之间使用解码器-编码器注意(交叉注意),并在每个解码器层对辅助解码损失进行深度监督,而YOLOS始终只查看每个层的输入序列,在操作方面不区分patch token和[DET] token。
1.3 实验
1.3.1 Setup
Pre-training 作者在ImageNet上采用DeiT训练策略对YOLOS/ViT进行预训练。
Fine-tuning 作者采用类似DETR方式在COCO数据上对YOLOS进行微调。
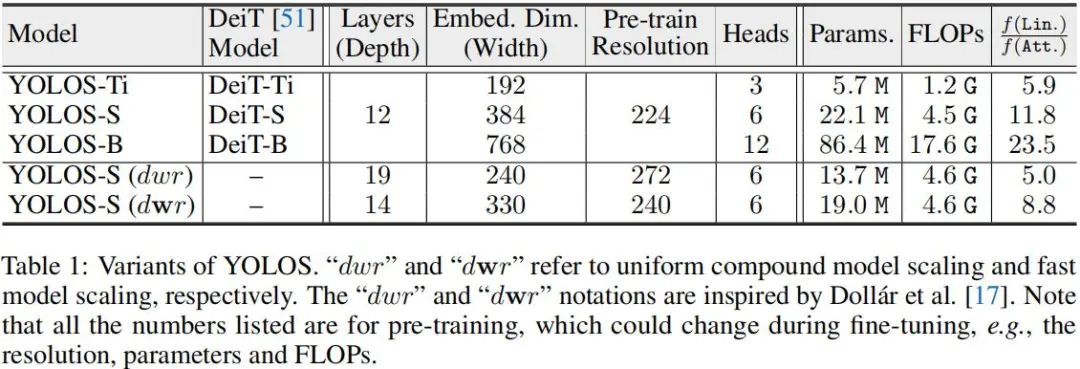
Model Variants 下表给出了作者关于YOLOS的不同模型配置信息。
1.3.2 预训练影响
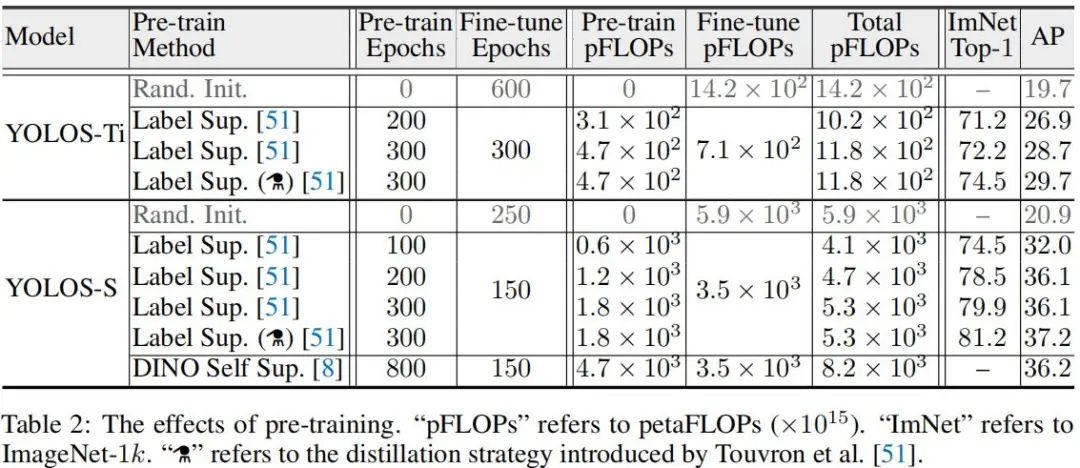
作者通过YOLOS研究了不同预训练策略对于ViT的影响,结果见上表。从上表可以看到:
-
至少在迁移学习框架下,从计算效率角度来看,预训练是很有必要的。从Tiny与Small模型对比来看,预训练可以节省大量的计算耗时;而且从头开始训练的模型性能要低于预训练模型的性能。这与恺明大神之前关于ConvNet的预训练研究不一致。
-
从真实标签监督预训练来看,不同大小模型倾向于不同的预训练机制:200epoch预训练+300epoch微调的YOLOS-Ti仍无法匹配300epoch预训练的性能;而对于small模型200epoch预训练具有与300epoch预训练相当的性能。引入额外的蒸馏,模型的性能可以进一步提升1AP指标。这是因为预训练CNN老师后模型有助于ViT更好的适配COCO。
-
从上述分析作者可以得出:ImageNet预训练结果无法精确的反应在COCO目标检测上迁移学习性能。相比图像识别中常用的迁移学习基准,YOLOS对于预训练机制更为敏感,且性能仍未达到饱和。因此,将YOLOS作为一个具有挑战性的迁移学习基础评价不同预训练策略对于ViT的影响是很合理的
1.3.3 不同尺度模型的预训练和迁移学习性能
作者研究了不同模型缩放策略的预训练与迁移学习性能,比如宽度缩放w、均匀复合缩放dwr以及快速速度dwr。模型从1.2G缩放到4.5G并用于预训练。相关模型配置见前面的Table1,结果见下表。
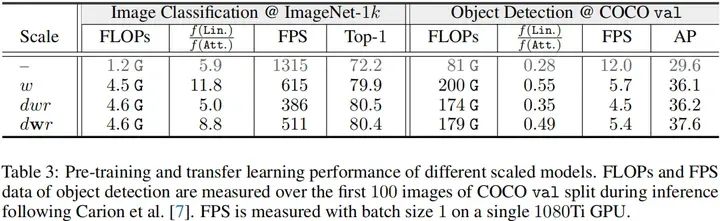
从上表指标对比可以看到:
-
dwr与dwr缩放均比简单的w缩放取得了更佳的精度;
-
关于缩放策略的属性与CNN相一致,比如w缩放速度最友好;dwr缩放取得了最佳精度;dwr缩放速度接近w缩放,精度与dwr相当。
-
由于COCO数据微调时分辨率与预训练分辨率不一致,此时预训练性能与迁移学习性能出现了不一致:dwr缩放具有与w缩放相当的性能,而dwr缩放则具有最佳性能。这种性能不一致说明:ViT需要一种新的模型缩放策略。
1.3.4 与基于CNN的目标检测器的比较
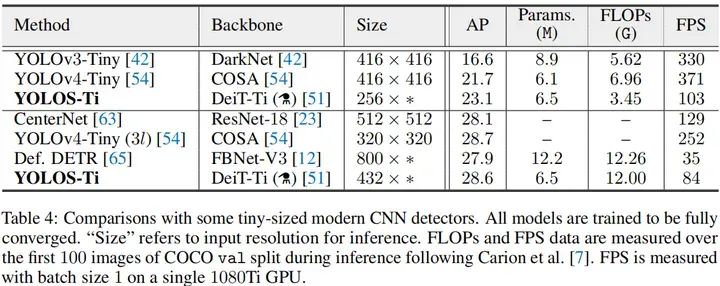
上表对比了YOLOS与ConvNet作为骨干时的性能,从中可以看到:在Tiny模型方面,YOLOS-Ti取得比高度优化CNN作为骨干时更佳的性能。
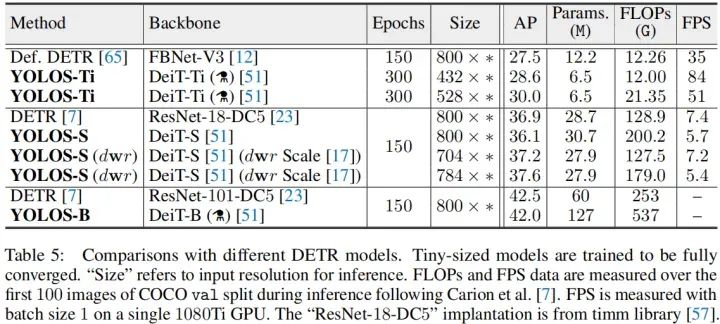
上表给出了YOLOS与DETR的性能对比,从中可以看到:
-
YOLOS-Ti具有比DETR更佳的性能;
-
YOLOS-S-dwr缩放取得了比DETR更佳的性能;
-
而YOLOS-B尽管具有更多的参数量,但仍比同等大小DETR稍弱。
尽管上述结果看起来让人很是沮丧,但是YOLOS的出发点并不是为了更佳的性能,而是为了精确的揭示ViT在目标检测方面的迁移能力。仅需要对ViT进行非常小的修改,这种架构即可成功的迁移到极具挑战性的COCO目标检测基准上并取得42boxAP指标。YOLOS的这种最小调改精确地揭示了Transformer的灵活性与泛化性能。
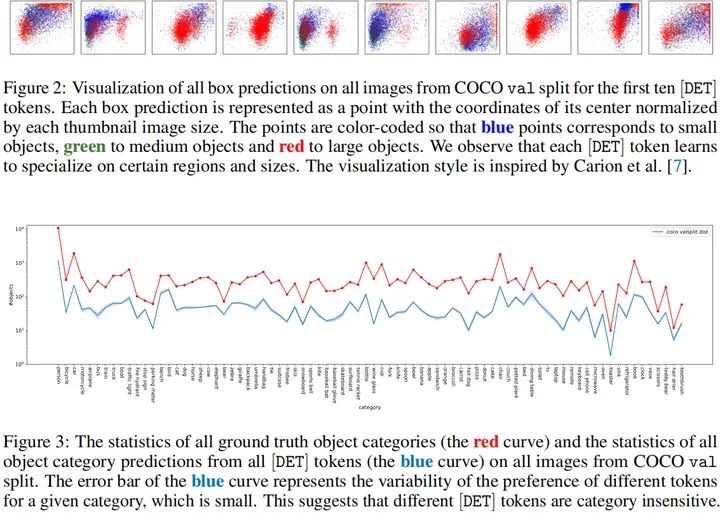
作为一种目标检测器,YOLOS采用DET表示所检测到地目标。作者发现:不同DET对目标位置与尺寸比较敏感,而对目标类别不敏感。见上面Fig2与Fig3.
1.3 总结
在本文中,作者探索了在ImageNet-1k数据集上预训练的标准ViT到COCO目标检测任务上的可迁移性。作者证明了2D目标检测可以以纯序列到序列的方式完成,具有最少的额外归纳偏置。并且YOLOS在COCO上的目标检测性能也是不错的,这表明纯Transformer结构对各种下游任务的泛化性和通用性。
虽然这篇文章展示了ViT的可拓展性,但是YOLOS仍然存在许多局限性。比如,相比如分类任务,需要用更长的序列来进行目标检测以及其他密集预测任务。但是自注意操作复杂度与序列长度成二次关系,因此,这篇文章的方法不能用于更大的模型 。
二,相关地址:
论文地址:https://www.arxiv-vanity.com/papers/2106.00666/
代码地址:https://github.com/hustvl/YOLOS
三,参考文章:
https://www.arxiv-vanity.com/papers/2106.00666/
https://zhuanlan.zhihu.com/p/377265869
https://zhuanlan.zhihu.com/p/377641656
https://zhuanlan.zhihu.com/p/426267828

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)