【数据库管理】①实例与数据库
【数据库管理】①实例与数据库
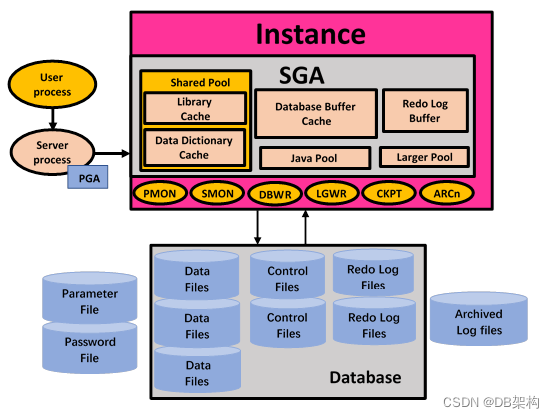
1.Oracle RDBMS 架构图

2. Oracle 体系结构
由此区分database和instance的区别
| No. | ||
|---|---|---|
| 1. | oracle server | database + instance |
| 2. | database | data file、control file、redo log file |
| 3. | instance | an instance accesses a database |
| 4. | oracle memory | SGA + PGA(oracle的内存结构) |
| 5. | instance | SGA + background process |
| 6. | SGA组成 | 一个instance只有一个SGA,SGA为所有session共享,随着instance 启动而分配,instance down ,SGA被释放. |
如RDBMS架构图所示,Oracle架构主要包括:
User Process、Server Process等的Client端+Instance实例+Databases+一些参数文件+密码文件+归档日志文件.
在Oracle数据库中,用户并不能直接访问到数据库文件,而是需要先创建一个数据库实例.数据库实例指的就是操作系统中一系列的进程以及为这些进程所分配的内存块,就是访问Oracle数据库文件的通道.
一个数据库实例包括Shared Pool(共享池),Data Buffer Cache(数据库缓冲区缓存),Redo Log Buffer(重做日志缓冲区)等部分,其中Shared Pool(共享池)又包括Library Cache(库缓存),Data Dictionary Cache(数据字典缓存).
当用户访问数据库文件时,需要先启动一个数据库实例,然后将数据库文件加载到Data Buffer Cache,将数据字典加载到Data Dictionary Cache,之后Server Process会首先访问Data Dictionary Cache,获取到有关数据库表的字段,关键字等元数据信息,然后再访问Data Buffer Cache,读取相关数据.从上述过程中,可以看到在Oracle数据库中,数据字典不仅是管理和查询元数据的工具,还是用户访问数据库文件的基础.
3. SGA (系统全局区)
3.1 SGA的6个基本组件
3.1.1 shared pool
共享池是对SQL、PL/SQL程序进行语法分析、编译、执行的内存区域.
共享池=库缓存(library cache)+数据字典缓存(data dictionary cache)+结果缓存(result cache)等组成.
共享池的大小直接影响数据库的性能.
关于shared pool中的几个概述
3.1.1.1 library cache
sql和plsql的解析场所,存放着所有编译后的sql语句代码,以备所有用户共享. (软解析\硬解析)
3.1.1.2 data dictionary cache
存放重要的数据字典信息,以备数据库使用
3.1.1.3 server result cache
存放服务器端的SQL结果集及PL/SQL函数返回值User Global Area (UGA) 与共享服务器模式有关

3.1.2 database buffer cache

3.1.2.1db buffer cache 概述
用于存储从磁盘数据文件中读入的数据,为所有用户共享.
服务器进程(server process)将读入的数据保存在数据缓冲区中,当后续的请求需要这些数据时可以在内存中找到,则不需要再从磁盘读取.
数据缓冲区中被修改的数据块(脏块)由后台进程(DBWR )将其写入磁盘.
数据缓冲区的大小对数据库的读取速度有直接的影响.
NOTE:server process对数据文件执行读操作,而DBWR对数据文件执行写操作
3.1.2.2 Buffer cache参数
Buffer pool= (default pool) + (nodefault pool)
其中:
| 参数 | |
|---|---|
| default pool(db_cache_size) | :是标准块存放的内存空间大小,SGA自动管理时此参数无需设置.使用LRU算法清理空间 nodefault pool |
| db_nk_cache_size | :指定非标准块大小内存空间,比如2k、4k、8k、16k、32k. |
| db_keep_cache_size | :keep存放经常访问的小表或索引等. 不会按照LRU清理. |
| db_recycle_cache_size | :与keep相反,存放偶尔做全表扫描的大表的数据. |
高速缓存中的缓冲区由一个复杂算法管理,该算法组合使用最近最少使用(LRU) 列表和停靠计数.LRU 有助于确保最近使用的块往往都留在内存中,从而最大限度地减少磁盘访问.
3.1.2.3 default 、keep、recycle相互独立
db_keep_cache_size和db_recycle_cache_size是可选的.
Buffer cache的大小就是以上cache参数size的总和,即没有分配到db_keep_cache_size和db_recycle_cache_size的任何数据对象都将分配给default cache.也就是 default 、keep、recycle相互独立的,对于某一个对象(表)来说,它只属于他们其中一种.
3.1.2.3.1 查看与更改default pool
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Thu Mar 30 10:06:22 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> alter session set container=PDB1;
Session altered.
SQL> show con_name;
CON_NAME
------------------------------
PDB1
SQL>
SQL> set pagesize 200 linesize 200
SQL>
SQL> drop table scott.emp1;
Table dropped.
SQL> create table scott.emp1 as select * from scott.emp;
Table created.
SQL>
SQL> col segment_name format a20
SQL> col buffer_pool format a20
SQL> select segment_name,buffer_pool from dba_segments where segment_name='EMP1';
SEGMENT_NAME BUFFER_POOL
-------------------- --------------------
EMP1 DEFAULT
SQL> -- 将表存放到keep缓存区.
SQL>
SQL> alter table scott.emp1 storage(buffer_pool keep);
Table altered.
SQL> select segment_name,buffer_pool from dba_segments where segment_name='EMP1';
SEGMENT_NAME BUFFER_POOL
-------------------- --------------------
EMP1 KEEP
SQL> 3.1.2.3.2 建立非标准块的 TBS
default pool对应的参数是db_cache_size与标准块default block是配套的
如果 default block是8k, db_cache_size将代替db_8k_cache_size.
如果要建立非标准块的 TBS ,先要设定db buffer中的与之对应的db_nk_cache_size参数.
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Thu Mar 30 10:19:13 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> set pagesize 200 linesize 200
SQL>
SQL> show user;
USER is "SYS"
SQL> -- 更改db buffer参数为16k
SQL> alter system set db_16k_cache_size=8m;
System altered.
SQL> -- 建立 TBS
SQL> create tablespace tbs_16k datafile '/u02/oradata/CDB1/pdb1/tbs16k01.dbf' size 10m blocksize 16k;
Tablespace created.
SQL> -- 查看 TBS
SQL> select TABLESPACE_NAME, block_size from dba_tablespaces;
TABLESPACE_NAME BLOCK_SIZE
------------------------------------------------------------------------------------------ ----------
SYSTEM 8192
SYSAUX 8192
UNDOTBS1 8192
TEMP 8192
USERS 8192
TEMP02 8192
TBS_16K 16384
7 rows selected.
SQL> 3.1.2.4 查看buffer cache命中率
SQL>
SQL> show user;
USER is "SYS"
SQL> select
2 (1-(sum(decode(name,'physical reads',value,0))/(sum(decode(name,'db block gets',value,0))+sum(decode(name,'consistent gets', value,0)))))*100 "Hit Ratio"
3 from v$sysstat;
Hit Ratio
----------
93.9413876
SQL>
-- 100条命令,93.9413876%的数据块能在内存buffer cache里找到Oracle DB 用户进程第一次请求特定数据片段时,将在数据库缓冲区高速缓存中搜索数据.如果该进程在高速缓存中找到数据(称为高速缓存命中),则直接从内存中读取数据.如果进程在高速缓存中找不到数据(称为高速缓存未命中),则在访问数据之前,必须将磁盘上的数据文件中的数据块复制到高速缓存中的缓冲区中.高速缓存命中时访问数据的速度要比高速缓存未命中时快.
3.1.3 redo log buffer
3.1.3.1 概述与作用
日志条目(redo entries )记录了数据库的所有修改信息(包括DML和DDL),为的是数据库恢复,日志条目首先产生于日志缓冲区. 日志缓冲区较小,它是以字节为单位的,它极其重要
3.1.3.2 大小和单位
SQL>
SQL> show parameter log_buffer;
NAME TYPE VALUE
------------------------------------ --------------------------------- ------------------------------
log_buffer big integer 15000K
SQL>
NOTE:日志缓冲区的大小启动后就是固定不变的,如要调整只能通过修改参数文件后重新启动生效.不能动态修改!不能由SGA自动管理!
-- 如果想让它是一个最小值,这样可以做:
SQL> alter system set log_buffer =1 scope=spfile; -- 修改动态参数文件,下次启动有效.
SQL> startup force; -- 非正常重启,生产环境不能这么启动
SQL> show parameter log_buffer;
NAME TYPE VALUE
---------- -------- ------------
log_buffer integer 2927616 -- 这就是最小值了
3.1.4 large pool(可选)
为了进行大的后台进程操作而分配的内存空间,与shared pool不同,主要用于共享服务器的session memory, RMAN备份恢复以及并行查询等.
对于表查询很慢,Oracle有4招::索引、分区、物化视图(读写分离)、并行查询 并行查询
比如一个select语句分成四个部分查询,需要4个CPU(一个CPU并行查询没有意义),每个CPU有各自的进程,查询后拼接起来,该技术叫并行查询.
3.1.5 java pool(可选)
为了java虚拟机及应用而分配的内存空间,包含所有session指定的JAVA代码和数据.
3.1.6 stream pool流池(可选)
为了stream process而分配的内存空间.
stream技术是为了在不同数据库之间共享数据,因此它只对使用stream数据库特性的系统是重要的.
3.2 SGA的granules(颗粒)
3.2.1 SGA的管理
9i是PGA先自动管理,10G是PGA和SGA分别管理,11G是两个整合管理
a) SGA_MAX_SIZE : SGA最大物理空间b) SGA_TARGET : SGA实际可达最大空间,SGA_target<SGA_max_size ,设定SGA_target >0时就能SGA自动管理
以上是a)和b)是10G的管理,11G默认SGA_target设定成0,将参数 AMM的memory的target设置非0后自动管理PGA和SGA
3.2.2 Granules(颗粒)
组成oracle内存的最小单位
| SGA_MAX_SIZE | Granule Size |
|---|---|
| <=1 GB | 4 MB |
| 1GB -- 8GB | 16 MB |
| 8GB --16GB | 32 MB |
| 16GB--32GB | 64 MB |
| 32GB--64GB | 128 MB |
| 64GB--128GB | 256 MB |
| >128GB | 512 MB |
3.2.3 查看SGA分配情况
SQL>
SQL> show user;
USER is "SYS"
SQL> -- 在 oracle里查看SGA分配情况
SQL> select name ,bytes/1024/1024 "Size(M)" from v$SGAinfo;
NAME Size(M)
------------------------------------------------------------------------------------------------ ----------
Fixed SGA Size 8.71464539
Redo Buffers 15.2851563
Buffer Cache Size 180
In-Memory Area Size 0
Shared Pool Size 376
Large Pool Size 20
Java Pool Size 0
Streams Pool Size 0
Shared IO Pool Size 24
Data Transfer Cache Size 0
Granule Size 4
Maximum SGA Size 599.999802
Startup overhead in Shared Pool 190.286659
Free SGA Memory Available 0
14 rows selected.
SQL>
4. Oracle的三种进程
4.1 user process
4.1.1 分类
属于客户端的process,一般分为三种形式,1)sql*plus, 2)应用程序,3) web方式(OEM).
4.1.2 查看win进程
客户端请求,sqlplus是客户端命令.
如果windows作为客户端,可以通过查看任务管理器查看sqlplus用户进程
4.1.3 查看linux进程
linux作为客户端时可以使用ps看到sqlplus关键字:
[root@oracle-db-19c ~]#
[root@oracle-db-19c ~]# ps -ef | grep sqlplus
oracle 46213 45436 0 10:19 pts/0 00:00:00 rlwrap sqlplus / as sysdba
oracle 46214 46213 0 10:19 pts/1 00:00:00 sqlplus as sysdba
root 47281 47239 0 10:39 pts/2 00:00:00 grep --color=auto sqlplus
[root@oracle-db-19c ~]# 4.1.4 User process终止与事务
*NOTE: 由user process造成的会话终止,系统将自动回滚该会话上的处于活动状态的事务.
4.2 server process:
服务器端的进程*,user process不能直接访问Oracle,必须通过相应的server process访问实例,进而访问数据库.*
[root@oracle-db-19c ~]#
[root@oracle-db-19c ~]# ps -ef |grep LOCAL
oracle 46215 46214 0 10:19 ? 00:00:00 oraclecdb1 (DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))
root 47407 47239 0 10:41 pts/2 00:00:00 grep --color=auto LOCAL
[root@oracle-db-19c ~]#
# 注意: 在linux下看到的server process, (LOCAL=YES)是本地连接,(LOCAL=NO)是远程连接.-- 可以在oracle查看v$process视图,它包括了当前所有的oracle进程,即后台进程和服务器进程.
SQL>
SQL> show user;
USER is "SYS"
SQL>
SQL> select pid, program, background from v$process where background is null;
PID PROGRAM BAC
---------- ------------------------------------------------------------------------------------------------------------------------------------------------ ---
1 PSEUDO
34 oracle@oracle-db-19c (D000)
35 oracle@oracle-db-19c (S000)
50 oracle@oracle-db-19c (P000)
51 oracle@oracle-db-19c (P001)
52 oracle@oracle-db-19c (P002)
53 oracle@oracle-db-19c (P003)
54 oracle@oracle-db-19c (P004)
55 oracle@oracle-db-19c (P005)
56 oracle@oracle-db-19c (P006)
57 oracle@oracle-db-19c (P007)
58 oracle@oracle-db-19c (P008)
59 oracle@oracle-db-19c (P009)
60 oracle@oracle-db-19c (P00A)
61 oracle@oracle-db-19c (P00B)
67 oracle@oracle-db-19c (TNS V1-V3)
16 rows selected.
SQL>
-- 其中background等于1指的是后台进程,null代表server进程
4.3 Background process
SQL>
SQL> -- 如果客户端登陆,也会产生会server进程,可以通过v$process 查看
SQL> select pid, program, background from v$process;
PID PROGRAM BAC
---------- ------------------------------------------------------------------------------------------------------------------------------------------------ ---
1 PSEUDO
2 oracle@oracle-db-19c (PMON) 1
3 oracle@oracle-db-19c (CLMN) 1
4 oracle@oracle-db-19c (PSP0) 1
5 oracle@oracle-db-19c (VKTM) 1
6 oracle@oracle-db-19c (GEN0) 1
7 oracle@oracle-db-19c (MMAN) 1
8 oracle@oracle-db-19c (TT00) 1
9 oracle@oracle-db-19c (GEN1) 1
10 oracle@oracle-db-19c (SCMN) 1
11 oracle@oracle-db-19c (DIAG) 1
12 oracle@oracle-db-19c (OFSD) 1
13 oracle@oracle-db-19c (SCMN) 1
14 oracle@oracle-db-19c (DBRM) 1
15 oracle@oracle-db-19c (VKRM) 1
16 oracle@oracle-db-19c (SVCB) 1
17 oracle@oracle-db-19c (PMAN) 1
18 oracle@oracle-db-19c (DIA0) 1
19 oracle@oracle-db-19c (DBW0) 1
20 oracle@oracle-db-19c (LGWR) 1
21 oracle@oracle-db-19c (CKPT) 1
22 oracle@oracle-db-19c (LG00) 1
23 oracle@oracle-db-19c (SMON) 1
24 oracle@oracle-db-19c (LG01) 1
25 oracle@oracle-db-19c (SMCO) 1
26 oracle@oracle-db-19c (RECO) 1
27 oracle@oracle-db-19c (W006) 1
28 oracle@oracle-db-19c (LREG) 1
29 oracle@oracle-db-19c (W005) 1
30 oracle@oracle-db-19c (PXMN) 1
31 oracle@oracle-db-19c (W000) 1
32 oracle@oracle-db-19c (MMON) 1
33 oracle@oracle-db-19c (MMNL) 1
34 oracle@oracle-db-19c (D000)
35 oracle@oracle-db-19c (S000)
36 oracle@oracle-db-19c (TMON) 1
37 oracle@oracle-db-19c (RVWR) 1
38 oracle@oracle-db-19c (W00B) 1
39 oracle@oracle-db-19c (ARC0) 1
40 oracle@oracle-db-19c (TT01) 1
41 oracle@oracle-db-19c (ARC1) 1
42 oracle@oracle-db-19c (ARC2) 1
43 oracle@oracle-db-19c (ARC3) 1
44 oracle@oracle-db-19c (TT02) 1
45 oracle@oracle-db-19c (W002) 1
46 oracle@oracle-db-19c (W003) 1
47 oracle@oracle-db-19c (W00A) 1
48 oracle@oracle-db-19c (AQPC) 1
49 oracle@oracle-db-19c (CJQ0) 1
50 oracle@oracle-db-19c (P000)
51 oracle@oracle-db-19c (P001)
52 oracle@oracle-db-19c (P002)
53 oracle@oracle-db-19c (P003)
54 oracle@oracle-db-19c (P004)
55 oracle@oracle-db-19c (P005)
56 oracle@oracle-db-19c (P006)
57 oracle@oracle-db-19c (P007)
58 oracle@oracle-db-19c (P008)
59 oracle@oracle-db-19c (P009)
60 oracle@oracle-db-19c (P00A)
61 oracle@oracle-db-19c (P00B)
62 oracle@oracle-db-19c (QM02) 1
63 oracle@oracle-db-19c (M003) 1
64 oracle@oracle-db-19c (Q005) 1
65 oracle@oracle-db-19c (M004) 1
66 oracle@oracle-db-19c (W001) 1
67 oracle@oracle-db-19c (TNS V1-V3)
70 oracle@oracle-db-19c (W009) 1
71 oracle@oracle-db-19c (Q009) 1
76 oracle@oracle-db-19c (W004) 1
77 oracle@oracle-db-19c (W008) 1
80 oracle@oracle-db-19c (M000) 1
82 oracle@oracle-db-19c (M001) 1
86 oracle@oracle-db-19c (M002) 1
87 oracle@oracle-db-19c (W007) 1
75 rows selected.
SQL> -- background字段为1是background process,其余都是server process
SQL> -- 六个基本的后台进程(background process)
SQL> 4.3.1 SMON :系统监控(system monitor)
在实例崩溃之后,Oracle会自动恢复实例
前滚 :把redo log里面所做的记录某个点开始重做一变
回滚 :打开数据库*,*没有完成的事务回滚
另一个作用是释放不再使用的临时段.
4.3.2 PMON :进程监控
当user process失败时,清理出现故障的进程. (所有事务都要回滚)
释放所有当前挂起的锁定、释放服务器端使用的资源监控(server进程和PGA进程都要释放)、空闲会话是否到达阀值动态注册监听
4.3.3 DBWR :数据写入进程
DBWn和DBWR是一个概述,DBWR(database writer)就是写数据文件的进程, 后来允许多进程写data file,所以改成DBWn了
4.3.3.1 作用
将修改后的缓冲区(脏buffer)数据写入数据文件中,即写脏块. (把DB buffer cache脏块写到数据文件data files)
释放data buffer空间.
4.3.3.2 触发 DBWR写的情况
1).ckpt发生
2).脏块太多
3).db_buffer 自由空间不够时
4).3秒
5).TBSread only/offline/backup等
4.3.3.3 NOTE
1).服务器进程对数据文件执行读操作,而DBWR负责对数据文件执行写操作.
2).commit时DBWR有何举动?答案是: 它什么也不做!
4.3.4 LGRW :日志的写进程
4.3.4.1 作用
从redo log buffer到redo log file写日志条目 (必须在DBWR写脏块之前写入日志)
负责将日志缓冲区中的日志条目写入日志文件. 有多个日志文件,该进程以循环的方式将数据写入文件.
4.3.4.2 触发 LGWR写的情况
(1). commit
(2). 三分之一满
(3). 1m满
(4). 先于DBWR写而写(先记后写,即DBWR正好要执行写入前)
(5). 3秒(由先记后写引发)
检查点发生的时候会发生LGWR写吗?
不会.
检查点发生的时候不会直接导致LGWR写*,间接导致LGWR写* *;在检查点发生的时候会导致DBWR写**,在DBWR发生之前LGWR要写一下.*
4.3.5 CKPT :生成检查点, 通知或督促DBWR写脏块
完全检查点: 保证数据一致性.
增量检查点: 不断更新控制文件中的检查点位置,当发生实例崩溃时,可以尽量缩短实例恢复的时间.
“检查点”是一种数据结构,它定义了数据库的重做线程中的系统更改号(SCN).
检查点记录在控制文件和每个数据文件头中*,*它们是恢复操作的关键元素
遇到检查点时Oracle DB 必须更新所有数据文件的头*,以记录该检查点的详细信息.*这是由KPT 进程完成的
CKPT 进程不会将块写入磁盘*,*该工作始终由DBWR 执行
文件头中记录的CN 可保证在该CN 之前对数据库块进行的所有更改都已写入到磁盘中.
4.3.6 ARCn :归档日志进程
归档模式下,发生日志切换时,把当前日志组中的内容写入归档日志,作为备份历史日志.
NOTE: LGWR负责对联机日志文件写操作,ARCN负责读取联机日志文件.其他进程与日志文件不接触.
11g里又强调了其他几个后台进程,它们都和数据库性能有关
MMON #:Oracle自我监视和自我调整的支持进程(与AWR有关) MMNL: MMON的辅助进程(与ASH有关)
MMAN #:内存自动管理,10g时推出,11g得到加强,在11g里这个进程负责Oracle内存结构(SGA+PGA)的自动调整.
CJQN #:与job队列有关
5. PGA (程序全局区)
属于oracle内存结构,存放用户游标、变量、控制、数据排序、存放hash值.与SGA不同, PGA是独立的,非共享.
9i的时候,PGA的自动管理:
Workarea_siza_policy = auto :根据需要将PGA分配给会话
Pdg_aggregate_target>0 :力求将达到的PGA分配总量
11g的时候将Pdg_aggregate_target=0,将AMM的memory的target设置非0后,PGA和SGA统一自动管理
由于是PGA的自动管理,hash_area_size, sort_srea_size 这两个参数现在已经不用了
6. 用户与Oracle服务器的连接方式
在DBCA 建库的时,提示选择连接类型,这里有两种类型:专用服务器模式和共享服务器模式.默认使用专用模式.
OracleDatabase creates server processes to handle the requests of user processesconnected to an instance. A server process can be either of the following:
Oracle 创建Server process 来处理user processes连接实例的的请求. server process 分两种:dedicated server process和 sharedserver process.
(1)A dedicated server process, which services only one userprocess
(2)A shared server process, which can service multiple userprocesses
Your database is always enabled to allow dedicated server processes, but you mustspecifically configure and enable shared server by setting one ormore initialization parameters.
6.1 专用连接模式
dedicated server process
对于客户端的每个user process,服务器端都会出现一个server process,会话与专用服务器之间存在一对一的映射.
对专用连接来说,用户在客户端启动了一个应用程序,例如sql*plus,就是在客户端启动一个用户进程;与oracle服务器端连接成功后,会在服务器端生成一个服务器进程,该服务器进程作为用户进程的代理进程,代替客户端执行各种命令并把结果返回给客户端.用户进程一旦中止,与之对应的服务器进程立刻中止.
专用连接的PGA的管理方式是私有的.Oracle缺省采用专用连接模式.
A dedicated server process services only one user process.
In the following situations, however, users and administrators should explicitly connect to an instance using a dedicated server process:
在以下两种情况,需要显示的使用dedicated server process 去连接实例
To submit a batch job (for example, when a job can allow little or no idle time for the server process)
To use Recovery Manager (RMAN) to back up, restore, or recover a database
To request a dedicated server connection when Oracle Database is configured for shared server, users must connect using a net service name that is configured to use a dedicated server. Specifically, the net service name value should include the SERVER=DEDICATEDclause in the connect descriptor.
如果数据库配置的是shared server,想要用dedicated server 去连接实例,就必须配置在net service name(tnsnames.ora)里指定SERVER=DEDICATED
6.2 共享连接模式
shared server process
多个user process共享一个server process.它通过调度进程(dispatcher)与共享服务器连接,共享服务器实际上就是一种连接池机制(connection pooling),连接池可以重用已有的超时连接,服务于其它活动会话.但容易产生锁等待.

在Shared Server环境中,一个调度器(dispatcher process)服务多个连接的请求,并将请求放到公共请求队列(common request connect pool)中,所有调度器共用一个请求队列,接着由共享服务进程(Shared Server processes)来处理这些请求,并将处理后的结果返回到响应队列(response queue).与请求队列不同,每个调度器都有自己的响应队列(response queue),然后由调度器把响应队列中的结果返回给客户端.其中请求队列和响应队列都是SGA中的一部分.
在一个共享服务环境中,一个客户端请求的步骤是这样的:
-- 客户端发送一个请求到调度器
-- 调度器(dispatcher)将请求放入到请求队列中(common request connect pool)
-- 共享服务进程(Shared Server processes)从请求队列中取出请求进行处理
-- 共享服务进程将处理后的结果放到调度器的响应队列中(response queue)
-- 调度器从响应队列中取出结果返回给客户端
上图实线表示发送信息,虚线表示返回信息.
6.3 驻留连接池模式
database resident connection pooling,简称DRCP
适用于必须维持数据库的永久连接.结合了专用服务器模式和共享服务器模式的特点,它提供了服务器连接池,但是放入连接池的是专用服务器.它使用连接代理(而不是专用服务器)连接客户机到数据库,优点是可以用很少的内存处理大量并发连接
(11g 新特性,特别适用于Apache的PHP应用环境).
6.4 NOTE
1).所有调度进程(dispatcher process)共享一个公共请求队列(common request connect),但每个调度进程都有自己响应的队列(response queue).
2).在共享服务器中会话是在SGA中的User Global Area(UGA)存储信息,而专用连接在PGA中存储信息,这时的PGA的存储结构为堆栈空间.
3).PGA itself is subdivided. The UGA (User Global Area) contains session state information, including stuff like package-level variables, cursor state, etc.
Note that, with shared server, the UGA is in the SGA. It has to be, because shared server means that the session state needs to be accessible to all server processes, as any one of them could be assigned a particular session. However, with dedicated server (which likely what you're using), the UGA is allocated in the PGA.
在Dedicated Server环境中,每一个连接都将启动一个专用服务进程,这个专用服务进程始终服务于这个连接直到连接断开.每一个专用服务进程都有一个属于自己的内存区域,叫做PGA(Program GlobalArea),里面存放了会话的信息,包括绑定变量、游标、排序等等. 而在Shared Server环境中,这些信息被存放到SGA中的UGA(User Global Area)区域中,这个区域一般都位于大型池中(Large pool)
4).The Location of a private SQL area depends on the type of connection established for a session. If a session is connected through a dedicated server, private SQL areas are located in the server process’ PGA. However, if a session is connected through a shared server, part of the private SQL area is kept in the SGA

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)