如何借助AI进行测试代码code review
本文引入了大模型进行测试代码Code Review的思路,然后介绍了如何较低成本搭建基于FastGPT+通用大模型的的CR系统,我们相信机器审查代码是一个非常有价值的赛道,随着AI的不断增强,CR的能力有望变得更完善,希望文本能给大家带来启发,感兴趣的读者也可以留言参与讨论,可以持续关注本公众号关于AI实践的文章。
成熟测试团队会产出大量自动化代码,因测试人员的经验和习惯原因,代码质量可能参差不齐,通常需要依靠专家code review(CR)来确保产出的测试代码质量,借助大模型进行CR已经成为一种趋势,可以提高CR效率和有效性。
大模型CR优势
-
自动化检查:利用大模型对代码进行自动化检查,可以快速识别出语法错误、代码风格问题、潜在安全漏洞等。这种自动化过程减少了人工审查的工作量,使开发者能够更加专注于代码的逻辑和功能问题。
-
减少重复工作:传统的人工CR往往会耗费大量时间在识别低级错误上,而大模型可以有效过滤这些错误,从而让审查者能够关注更有价值的逻辑和设计问题。
-
快速反馈:结合Gitlab CI等工具,大模型能够在代码提交后立即执行CR,并提供即时反馈,大大缩短了反馈周期。
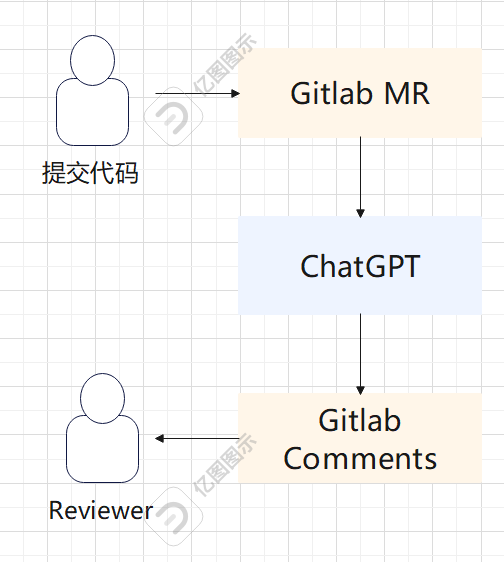
简单来讲,可发起Merge Request(MR)请求的时候使用Gitlab CI触发该任务,借助中间平台,调用大模型并给到反馈,信息回到Gitlab。
给到的提示词例如:
以下代码是GitLab代码补丁。请以测试专家的角度,从自动化测试用例设计;代码的实现;可改进的领域;这几个角度,给出详细的例子进行解释,尽量少离题和耍幽默。
这种模式,在CR具体场景内仍然会存在一些问题:
-
只针对表层问题,无法深度分析:拿UI自动化举例,通用大模型无法识别公共方法和业务相关的方法,这样给CR的深度会造成很大限制
-
一致性检查:代码风格命名,测试数据的管理方式,case写法有较多的个性化的内容因团队而异,没有业界的统一标准,这方面AI难免会有误判
-
修复建议噪音高:在review质量不够100%有效情况下,放入MR 的comments会非常困难,由谁去Resolve 提出的修改建议也是一个难题
借助RAG加强CR
改进思路
-
通过构造合适的prompt将约束条件,构建知识库系统来做规范管理,提供更加丰富和标准的信息,这里就要用到前序文章中对RAG的论述:
-
Review结果适合通过企信(钉钉)消息发出,而不是直接在gitlab评论上,CR建议只供参考,具体的Comments动作和Resolve过程由实际的Review人员来进行
现有业界的RAG支撑系统很多,这里我们选择的是FastGPT的平台,其他还有Dify,QAnything等,对CR场景没有太大区别,这里以fastGPT作为举例说明如何形成CR思路
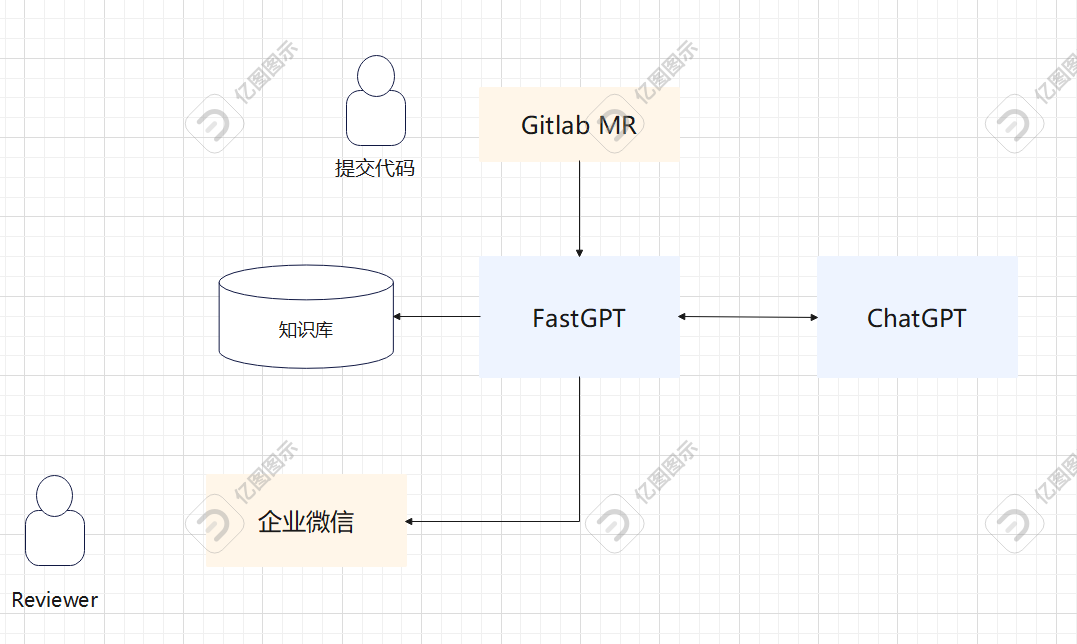
搭建步骤
初始化CR知识库

这里非常重要,个性化的信息主要通过有效的知识库来实现:
-
测试基础方法的信息,明确哪些是最佳方法以及语义
-
对测试代码规范自定义信息
-
不同业务线的要求,例如给到最佳实践的代码模板
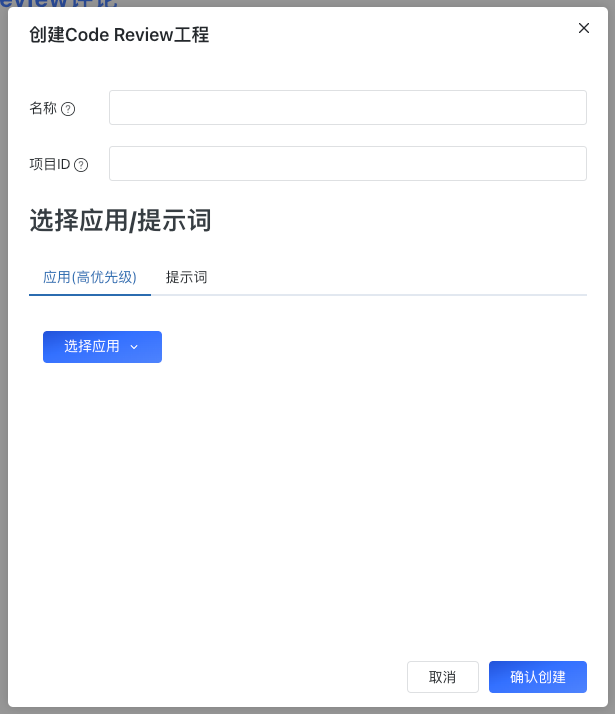
新建FastGPT项目
-
在界面和交互方面公司内针对FastGPT进行对应小范围改造,但基本遵从FastGPT对应用的定义
-
新建的项目要勾选之前的知识库
-
配置好一个FastGPT应用后,根据应用可提供API
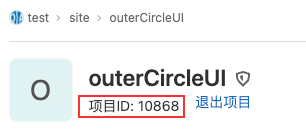
选取待CR的Repo
从gitlab内筛选想要review的项目ID
优化提示词
测试代码的提示词可参考:
-
假设你是测试开发工程师,现在你的任务是阅读GitLab代码变更,使用中文给出修改建议。 -
建议要求: -
a.必须使用知识库给出建议;生成的建议语句通顺; -
b.指明具体位置,使用例子进行解释,只需要给出少量关键代码不要全部输出; -
d.不要脱离给定的代码; -
e.不要复述原代码; -
f.不要给出重复建议; -
g.评审建议不超过700字符; -
下面是GitLab代码变更:(后面附上MR的变更代码)
触发Review
调用GET:https://fastqa.xxxx.com/api/review/work?projectId=xxxxx&mrId=xx 接口即可发起Review,此处我们改造fastGPT代码去抓取Gitlab的MR信息和代码变更
-
projectId:项目ID
-
mrId:MR请求ID
在Gitlab CI中添加以下内容
curl --location "https://fastqa.xxxxx.com/api/review/work?projectId=$CI_MERGE_REQUEST_PROJECT_ID&mrId=$CI_MERGE_REQUEST_IID"这样MR请求的时候就会触发Review任务,结果触发企信机器人。
结果查看
Review结束的时候企业微信(钉钉)会收到消息


打开企业微信(钉钉)通知中的链接就可以查看结果,高价值的CR信息具体review同学或者mgr可以补充到gitlab上进行修改,使用平台人员标记Review结果是否有效便于后续优化

实际内部CR实践
摘取对公司内某一个真实自动化代码的一些建议

从初步实践的情况看:
-
确实可产出大量值得采纳的建议
-
存在一些误报情况,和AI目前返回数据的不确定性相关,但可通过调优知识库进行优化
本文引入了大模型进行测试代码Code Review的思路,然后介绍了如何较低成本搭建基于FastGPT+通用大模型的的CR系统,我们相信机器审查代码是一个非常有价值的赛道,随着AI的不断增强,CR的能力有望变得更完善,希望文本能给大家带来启发,感兴趣的读者也可以留言参与讨论,可以持续关注本公众号关于AI实践的文章。
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)