python-17-并行计算和分布式计算框架dask
并行计算dask
dask入门教程
并行计算库Dask官方教程(中文翻译)
dask和numpy的计算对比
参考dask,一个超强的 python 库
参考Python快快快
1 并行计算和分布式计算
1.1 并行计算parallel computing
并行计算:这是一台计算机的概念,即一台计算机中多个处理器被组织起来,大任务下达的时候,将大任务分成若干个小任务,然后分配给若干个处理器进行运算。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理器来并行计算。并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台的独立计算机构成的集群。通过并行计算集群完成数据的处理,再将处理的结果返回给用户。
并行计算可分为时间上的并行和空间上的并行。
时间上的并行:是指流水线技术,比如说工厂生产食品的时候步骤分为:
1. 清洗:将食品冲洗干净。
2. 消毒:将食品进行消毒处理。
3. 切割:将食品切成小块。
4. 包装:将食品装入包装袋。
如果不采用流水线,一个食品完成上述四个步骤后,下一个食品才进行处理,耗时且影响效率。但是采用流水线技术,就可以同时处理四个食品。这就是并行算法中的时间并行,在同一时间启动两个或两个以上的操作,大大提高计算性能。
空间上的并行:是指多个处理机并发的执行计算,即通过网络将两个以上的处理机连接起来,达到同时计算同一个任务的不同部分,或者单个处理机无法解决的大型问题。
比如小李准备在植树节种三棵树,如果小李1个人需要6个小时才能完成任务,植树节当天他叫来了好朋友小红、小王,三个人同时开始挖坑植树,2个小时后每个人都完成了一颗植树任务,这就是并行算法中的空间并行,将一个大任务分割成多个相同的子任务,来加快问题解决速度。
1.2 分布式计算distributed computing
分布式计算:这个一组计算机的概念,通过计算机网络连接起来,大任务下达的时候,将大任务分成若干个小任务,然后分配给若干个计算机进行运算。

研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。
最近的分布式计算项目已经被用于使用世界各地成千上万位志愿者的计算机的闲置计算能力,通过因特网,可以分析来自外太空的电讯号,寻找隐蔽的黑洞,并探索可能存在的外星智慧生命;可以寻找超过1000万位数字的梅森质数;也可以寻找并发现对抗艾滋病病毒的更为有效的药物。这些项目都很庞大,需要惊人的计算量,仅仅由单个的电脑或是个人在一个能让人接受的时间内计算完成是绝不可能的。
1.3 区别
显然,分布式计算非常强调计算机网络中的计算机合作,并行式计算强调一个计算机的多个处理器合作。
(1)并行计算投入更多机器,数据大小不变,计算速度更快,而分布式计算投入更多的机器,能处理更大的数据;
(2)并行计算必须要求时间同步,而分布式计算没有时间限制。
2 Dask
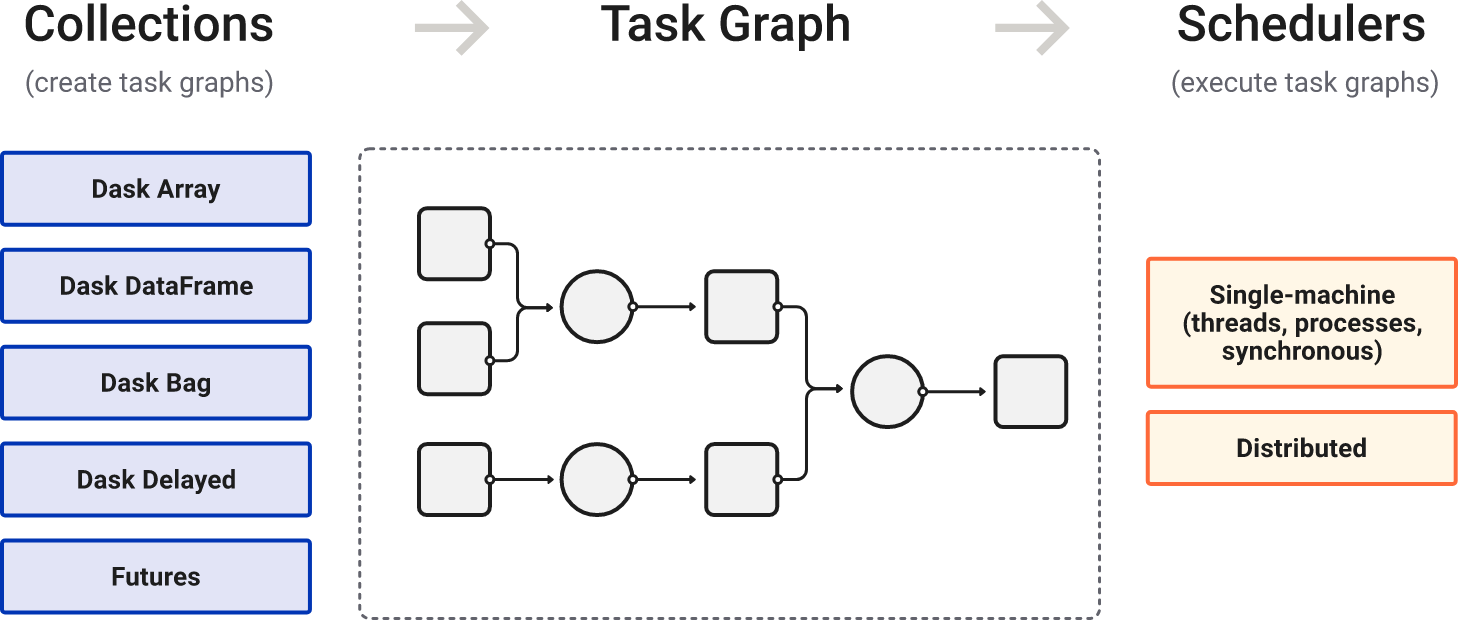
Dask是一个用于分析计算的灵活的并行计算库。
Dask是Python中的一个灵活的并行计算库,允许用户利用 CPU 内核的强大功能,对大于内存的数据集执行分布式计算。
Dask的特点
(1)动态任务调度:Dask能够智能地安排复杂的计算任务,优化资源利用率。
(2)兼容性:Dask提供了与这些库相似的API,允许用户轻松迁移到更大规模的数据处理上。
(3)延迟计算:Dask允许构建一个任务图,其中计算是延迟执行的,直到需要其结果时才真正触发计算。
(4)透明地扩展到分布式计算:Dask可以在单机上以多线程或多进程的方式运行,也可以扩展到多机的分布式集群。

pip install dask
python -m pip install "dask[array]"
python -m pip install "dask[distributed]"
python -m pip install "dask[dataframe]"
2.1 单机模式运行dask
#dask求解10个数的平均值
import dask.array as da
import numpy as np
x=np.arange(10000000)
#chunks表示划分时每块的大小(大数据超过内存容量时,需要对数据进行按块划分)
y=da.from_array(x,chunks=(100,))
print(y)
print(y.mean())
print(y.mean().compute())
2.2 分布式调度程序
首先在命令行窗口执行dask-scheduler命令,得到以下输出:

其中,tcp://192.168.1.4:8786可以做为当前电脑的url地址,在同一局域网下,可以在另一主机上通过client方法进行主机的连接。
(1)client内容为空或者为127.0.0.1.8786时,默认启动本地调度工作程序(此时客户端和本地客户端应建立连接),客户端将自身注册为默认的Dask调度程序。
from dask.distributed import Client
if __name__ == "__main__":
client = Client()
a = client.map(lambda x:x**2,range(10))
b = client.map(lambda x:x+1,a)
c = client.map(lambda x:-x,b)
re = client.submit(sum, c).result()
print(re)
(2)当client不为空,为另一主机的url时:
这时首先在当前客户机输入命令:
dask-worker 192.168.1.4:8786
此时将scheduler和workers绑定在一起。

结果表示客户机与主机连接成功,此时就能够分布式利用不同主机间运行程序。
from dask.distributed import Client
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
a = client.map(lambda x:x**2,range(10))
b = client.map(lambda x:x+1,a)
c = client.map(lambda x:-x,b)
re = client.submit(sum, c).result()
print(re)

2.3 常用函数及部分概念
2.3.1 submit()和result()
(1)submit(方法,数值), 对数值执行某种方法。
(2)若想显示出来直观的结果,则调用result()方法。
from dask.distributed import Client
def inc(x):
return x+1
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
x1 = client.submit(inc,10)
print(x1)
print(x1.result())
x2 = client.map(inc,range(2))
print(x2)
print(client.gather(x2))
x3 = client.submit(sum,x2)
print(x3)
print(x3.result())
输出如下:
<Future: pending, key: inc-d3f5af4d5bb89c246f58e2a8fa150373>
11
[<Future: pending, key: inc-9e50b1e0389d7a9c0a888ae20ae00cae>,
<Future: pending, key: inc-d78d089440e3814014b4f8e92775a40e>]
[1, 2]
<Future: pending, key: sum-36d98f2f40c36fc256240b1a9c0feadd>
3
(3)对于map()方法来说,map(方法,数值列表),通过遍历数值列表的数值进行数值计算,想直观的看到map()运行后的结果,需要调用client.garher(参数值)方法。
2.3.2 submit(pure=False)
(4)对于submit和map等函数运行结果中都出现了key关键词,可以试验并且发现,当调用的函数是纯函数时,所得的key应是完全一样的,这就是dask中避免重复计算所才用的策略,当出现重复的计算时,只需要比较key的值就能利用旧的结果,而不需要重新计算。
from dask.distributed import Client
from operator import add
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
x = client.submit(add,1,2)
y = client.submit(add,1,2)
print(x.key)
print(y.key)

(5)当函数不纯时,众所周知的就是random函数,每次执行的值都不同,但是函数是不变的,所以在dask中加入了一个参数:pure,当pure=False时,禁用以上功能。
from dask.distributed import Client
import numpy as np
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
x = client.submit(np.random.random,3,pure=False)
y = client.submit(np.random.random,3,pure=False)
print(x.key)
print(y.key)
print(x.result())
print(y.result())

2.3.3 将数据集发送到调度程序
from dask.distributed import Client
import dask.dataframe as dd
if __name__ == "__main__":
client = Client("192.168.1.4:8786")
df = dd.read_csv("data.csv")
df = client.persist(df)
client.publish_dataset(my_data=df)
my_data是把数据集命一个新的名称,在与调度机相连的任意客户机都能访问此数据集。
2.3.4 客户机访问数据集
from dask.distributed import Client
if __name__ == "__main__":
client = Client("tcp://192.168.1.4:8786")
print(client.list_datasets())
df = client.get_dataset("my_data")
2.4 应用样例
2.4.1 数据集生成
我们将创建一个包含六列的虚拟数据集。
第一列是时间戳—以秒的间隔采样的二年,其他五列是随机整数值。
import numpy as np
import pandas as pd
import dask.dataframe as dd
from datetime import datetime
dates = pd.date_range(
start=datetime(year=2022, month=1, day=1),
end=datetime(year=2023, month=12, day=31),
freq='s'
)
df = pd.DataFrame()
df['Date'] = dates
for i in range(5):
df[f'X{i}'] = np.random.randint(low=0, high=100, size=len(df))
df.to_csv(f'2022.csv', index=False) # 大小2.08G
df.shape # (62985601, 6)

2.4.2 性能对比
首先,让我们使用 pandas 来运行 groupby 计算并建立性能基线。
%%timeit
df.groupby("X0").agg({"X4": "sum"})
输出如下:
1.81 s ± 35.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
可以看到使用 pandas 进行 groupby 操作,需要耗费 1.81s
让我们使用 Dask 运行相同的 groupby 查询。
import dask.dataframe as dd
ddf = dd.read_csv('2022.csv')
%%timeit
ddf.groupby("X0").agg({"X4": "sum"})
输出如下:惰性计算
6.45 ms ± 387 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit
ddf.groupby("X0").agg({"X4": "sum"}).compute()
输出如下:执行计算
34.9 s ± 636 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
对于同样的操作,使用 dask惰性计算 只需要 6 ms ,性能有了显著的提升。
对于同样的操作,使用 dask计算 需要34s ,性能并未提升。并没有加快运行,反而更慢了。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)