Stata小白系列之一:调入数据
Stata小白系列之一:调入数据
Stata小白系列之一:调入数据
转自公众号:连享会
目录
- 概念区分
- 调入本地标准文件
- 调入全部数据
- 调入部分变量
- 调入部分样本
- 调入具有某些特征的样本
- 调入网络文件
- 调用 stata 自带数据库——
sysuse命令 - 调入stata 手册在线数据 ——
webuse set命令 - Wooldridge, Greene 等经典教科书范例数据获取——
bcuse命令 - 调用联邦储备经济数据库 (FRED)——
freduse&import fred - 大杀器
copy命令——从下载地址直接储存文件或复制网页文本信息
- 调用 stata 自带数据库——
第二篇
- 调入ASCII数据
- 读取ASCII数据 —— insheet命令
- 读取无固定格式命令 ——infile命令
- 读取固定格式数据——infix
- 调入excel数据——
import excel&xls2dta
0 从一个概念区分开始:打开&调入数据
使用 stata 的第一步是打开文件,但这一简单动作也是有所讲究的。严格来说,使用打开是不确切的。stata 在内存中分配了一块空间,用于存储调入的数据,而这份数据其实是存储于硬盘或网络上的数据文件的复制品而已,除非使用 save 命令将其保存到硬盘上,硬盘中数据文件是不受任何影响的。
小白上路,从细节做起!
1. 调入本地 Stata 格式数据文件
- 命令:
use [varlist] [if] [in] using filename [, clear nolabel ] - 解释:
use是打开数据的命令语句,varlist代表变量名称,if是条件语句,用于限定样本范围;in是范围语句,很少用using filename代表数据文件路径和名称。
1.1 调入文件中全部数据
如果想要调入 usaauto 数据文件中的全部数据,输入标准命令如:
use "D:\360Downloads\PanDownload\操作数据\教程数据\chap02\date.dta", clear 说明:use 是表示调入的命令语句,引号中 D:\360Downloads\PanDownload\操作数据\教程数据\chap02\date.dta 则指定了数据文件的路径。
1.2 调入文件中部分变量
有时,并不需要将数据文件中的所有变量全部调入,因为原始数据内容丰富,含有很多变量,而研究可能只涉及其中的几个变量。所以若只调入usaauto 文件中的 make 和price 这两个变量,应该使用如下命令:
use make price using "C:\data\usaauto.dta" 这个命令中 use make price 部分表示需要打开 make 和 price 两个变量, using “C:\data\usaauto.dta” 部分表示打开的数据文件路径及名称,如果用户使用此命令打开其他数据文件,所应用的命令相似,只需要把表示文件名称和变量的具体内容修改即可
1.3 调入文件中部分样本
有时,原始数据文件的样本数量过于庞大,例如人口普查的数据动辄千百万,可是一般的研究大部分不需要全部的样本,只需要部分样本即可,所以这时候只需要打开部分样本。例如,若只需要调入 usaauto 数据文件中第五到第十个样本的数据,可以使用如下命令:
use "C:\data\usaauto.dta" in 5\10 解释:
use "C:\data\usaauto.dta"表示调入的数据文件名称及路径,in 5\10表示选取的样本序号,即选取第 5-10 行观察值。
1.4 调入具有某些特征的样本
有时,原始数据将不同特征的样本混杂在一起,而现实的研究却要求将不同的样本分开研究,例如分别研究男性、女性的情况,城市、农村的经济问题,等等。这时就需要只调入具有这些特征的样本数据进行分析,在这个试验中,调入 usaauto 文件中进口车样本数据的命令为:
use "C:\data\usaauto.dta" if foreign==1 解释:这个命令语句中最重要的就是 if 语句,该命令执行的结果就是让 stata 仅仅读入符合条件的样本数据。在本例中, foreign==1 就表示是进口车,所以调入的数据就是进口车的数据。
连享会 最新专题 直播
2. 调入 Stata 自带范例数据文件
2.1 sysuse 命令:调用 stata 内置数据集
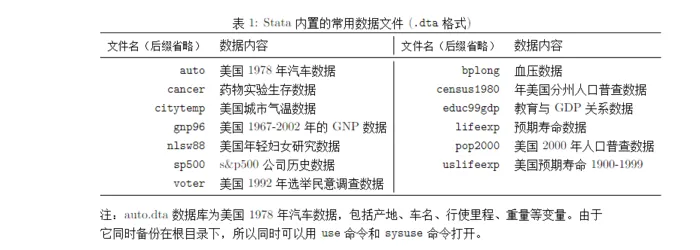
安装 Stata 时,会自带一些供练习所用的范例数据集。在命令窗口中输入如下命令可以查看完整的文件列表:
help dta_examples

stata 内置有以上数据集供我们使用,在练习命令时我们不必舍近求远。例如,auto 数据集大名鼎鼎,笔者在不少教程中见过。由于 auto 数据库同时备份在根目录下 (D:\stata15\ado\base/a/),所以我们可同时用 use 或 sysuse 直接调用。显然,由于使用 use 需指定文件路径,较为繁琐,我们通常都是直接使用 sysuse 命令调入这些内置的数据文件。
以 cancer.dta 数据为例,如图所示,若想使用 use 命令调用,则需指定具体的存储路径:
use "D:\stata15\ado\base/c/cancer.dta", clear 相比之下,若用 sysuse 命令,则可以直接调入:
sysuse "cancer.dta", clear 
cancer数据库调用
2.2 调入在线数据 —— webuse set 命令
不要见识了内置数据集就心满意足了,因为接下来的资源更加强大。Stata 手册里使用的诗句都可以使用 webuse 命令直接下载、使用。数据集列表信息如下:
help dta_manuals

手册资源
如图所示,以上手册,简单直译了一下,读者可以自取所需,点击进入后会有命令介绍与配套数据库。上述手册配套的所有数据库都可以用 webuse 直接调入。
webuse 的特点是可以直接在线导入网上数据而不需指定具体网络路径,因为 web set 已经默认设定了网络地址为 stata 官网的手册地址。
举例:
use http://www.stata-press.com/data/r15/lifeexp, clear 可以简写为
webuse lifeexp, clear 输入 webuse query 命令,我们可以看到当前默认设定的网址:
. webuse query
(prefix now "http://www.stata-press.com/data/r15") 更改默认地址
使用 webuse set 可以更改默认地址,以便下载特定网址中的 Stata 数据文件。若需恢复默认网址设定,只需执行 webuse set ,后面不加网络路径。
2.3 bcuse 命令——Wooldridge, Greene 等经典教科书范例数据获取
bcuse 由波士顿大学 Baum 教授编写,提供了波士顿学院 Economics 实验室中使用的许多 Stata 格式数据集。包括 Wooldridge的导论, Greene 的计量分析等经典教科书范例数据。可以使用 ssc install bcuse, replace 命令下载并安装该命令。
以伍德里奇《导论》中的数据集为例带大家简单探索一番。
输入如下命令,打开 bcuse 的帮助文件,可以看到该命令能够下载的所有数据集的列表链接地址:
help bcuse 亦可在命令窗口中直接输入如下命令打开网页:
view browse "http://fmwww.bc.edu/ec-p/data/wooldridge/datasets.list.html" 截取部分网页信息如下:

Wooldridge data sets
如果有些命令是以zip保存的,只需再文件名后面加上.zip即可,如:
bcuse 401k.zip
2.4 调用联邦储备经济数据库 (FRED)—— freduse & import fred
fed 是由圣路易斯联邦储备银行 (Federal Reserve Bank of st . Louis) 维护的联邦储备经济数据库 (FRED)。该数据库提供了数十万个时间序列资料,用以衡量经济和社会活动的方方面面。在 stata14 使用的命令为 freduse ,需要先用 ssc install freduse, replace 命令下载。Stata 15 中提供了 import fred 命令用于快捷地导入 fred 上存储的数据。使用详情参见:链接1;链接2。
第二篇
- 大杀器
copy命令——从下载地址直接储存文件或复制网页文本信息 - 调入ASCII数据
- 读取ASCII数据 —— insheet命令
- 读取无固定格式命令 ——infile命令
- 读取固定格式数据——infix
- 调入excel数据——
import excel&xls2dta
3. 大杀器 copy 命令——从下载地址直接储存文件或复制网页文本信息
基本语句: copy filename1 filename2 [, options]
filename1 是要复制的来源文件地址,
filename2 是存放的新文件地址,可以是一个附带路径的本地文件名也可以是一个网络链接地址。当文件路劲比较复杂,比如含空格时要用双引号将两个路径包围。
- options 功能
public定义了 filename2 对所有用户可读;
replace 若 filename2 的文件已存在,则替换它
copy 命令的作用包括:
- 文件搬家:就是将硬盘上的一个文件搬到另一个地方,此时两个文件名都为本地路径文件,还可对文件改名
- 下载网上的文件,比如一些论文,上市公司年报,数据等,只要知道他们的 url 就能用
copy获取,以copy为基础有更高级的命令,如cntrade命令就是用copy直接读取网易财经的股价历史数据 - 爬虫的基础
下面,以功能 2 为例为大家示范
找到一篇关于 stata 教程文章, Creating a do-file ,地址比较复杂,使用引号包围,用 copy 将其保存在指定磁盘,并将其命名为 copy1 ,输入如下命令:
copy "https://www.kellogg.northwestern.edu/faculty/dranove/htm/dranove/coursepages/Mgmt%20469/Creating%20a%20do-file.pdf"
"C:/Users/Administrator/Desktop/文件中转/copy1.pdf" 文件就保存到本地了!copy命令极其精巧,许多妙用尚待发掘,作为一个小白能力有限,慢慢来吧!
连享会 最新专题 直播
4. 调入ASCII数据
当数据文件为其他格式时,也可以导入Stata软件中进行处理,常用的命令主要有 insheet 、 infile 、 infix 命令
4.1 insheet命令——读取 ASCII 格式的数据
ASCII数据: ASCII 数据是指原始的文本数据,是由由电子表格和数据库程序生成的数据文件中,每一行代表一个观测值,数值由逗号或制表符隔开,第一行可以包含变量名称。
基本命令语句:
insheet [varlsit] using filename [,options] 说明: insheet 代表导入数据的命令, [varlsit] using filename 代表数据文件中的某个变量,这里的 options 的具体内容显示在表 2.9 中,主要包括选项的内容和所代表的含义。

例子:将数据 citywater.csv 导入Stata中,就不能直接使用 use 命令了,因为此数据文件的后缀名不是 .dta ,而是 .csv ,这种数据类型表示使用逗号分隔的一种数据类型:
insheet using C:\data\citywater.csv insheet 是导入此类数据的命令, using C:\data\citywater.csv 指明了数据的路径,此时数据文件 citywater.csv 就被正确导入Stata中,可以进行各种操作了
4.2 infile命令——读取无固定格式的数据文件
infile 在某种程度上可以完成与 insheet 命令相同的功能,最大区别是 infile 必须指明变量名称,尤其是字符型变量。而用 infile 命令读取数据的基本命令语句如下:infile varlist [_skip[(#)] [varlist [_skip[(#)] ...]]] using filename [if] [in] [, options]
例如,同样将数据 citywater.csv 导入Stata中, infile 操作命令为:
infile year production capital labor using C:\data\citywater.csv
4.3 infix命令——读取固定格式数据
固定格式的数据是指有固定的位数,当位数不够时,前面用 0 补齐,对于这种数据是用 infix 命令读入的,具体形式如下:
infix using dfilename [if] [in] [, using(filename2) clear]
infix specifications using filename [if] [in] [, clear]
例如,将下列一组数据(数据文件 chengji.csv )转化成如表 2.10 所示的数据形式。 chengji 这组数据为用逗号隔开的数据类型,如图 2.11 所示,其中 gender (性别)只有 0 和 1 两个数字组成, number (学号)这一栏必须由三位数组成,math和english的成绩必须由两位数组成,所以这是一个固定格式的数据,应该使用infix命令。

具体的命令语句为:
infix gender 1 number 3-5 math 7-8 english 10-11 ///
using C:\data\chengji.csv, clear
在这个命令语句中, infix gender 1 说明第一位数据为性别, number 3-5 表示第 3 至 5 位表示学号, math 7-8 表示第 7 至 8 位表示数学成绩, english 10-11 表示第 10 至 11 为表示英语成绩, using C:\data\chengji.csv 表示原始数据文件的路径。
5. 调入excel 数据—— import excel & xls2dta
5.1 简介
读取 excel 数据有两种选择,一种是利用鼠标点击菜单,这种方式简单,无法对文件做精细设置。具体操作步骤如下:
File > Import > Excel spreadsheet ( .xls;.xlsx)
另一种是利用 stata 官方命令 import excel 。基本语句:
import excel [using] filename [, import_excel_options] 使用命令导入可以利用参数设置对细节进行设置,以下介绍常用三个参数
options功能sheet("sheetname")含多张表的文件选择要导入的表头cellrange([start][:end])选择数据的起始,结束位置firstrow输入的话将Excel表的第一行数据作为变量名
举例介绍,以 stata 附带的 auto.dta 数据为例(为演示方便已将其导出为 Excel)
首先我们导入数据,将第一行设置为变量名,选取数据范围为(A1,D10),使用命令
import excel auto.xls, cellrange(A1:D10) firstrow 
需要说明是,此处,若不附加 cellrange(A1:D10) 选项,则默认将整份 Excel 表格一次性导入 Stata 中。
5.2 数据导出—— export excel
基本语句:
export excel [varlist] using filename [if] [in] [, export_excel_options] options功能
sheet("sheetname")保存到名为 sheetname 的工作表中cell(start)指定 Excel 工作表中的左上角单元格开始保存firstrow(variables、varlabels)将变量名或变量标签名保存为首行nolabel保存数据值而非数据值标签值
5.3 多文档同时导入—— xls2dta
上文介绍的 import excel 命令一般用于导入单个 excel 文件。当需读取多个 excel 文件时需用到宏循环处理,对小白并不友好。为大家介绍一个便捷的命令 xls2dta——此命令在处理多个 excel 文件上具有显著优势,不仅可以读取保存,还可以进行合并等其他操作。由于篇幅限制,不再为大家介绍,为大家寻找了相关博客,有兴趣同学可以自行学习。
值得一提的是,此命令需从 ssc 下载 ,可以使用 ssc install xls2dta 命令下载之。
本文中所用数据文件下载地址:
数据文件:链接: https://pan.baidu.com/s/1qXRh9EG 密码: 5ltw

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)