RAG 系列之三:文本切分
本文对文本的切分进行了介绍,起到了抛砖引玉的作用。在实际的应用过程中,针对不同类型的文本应该选择不同的切分策略。而且,文本的切分和业务场景也是密切相关的,在制定策略的过程中,也要紧密结合业务场景,才能做到准确的切分。
在RAG 系列之二:PDF 解析中,我们探讨了 PDF 文件的解析。解析完文件,拿到纯文本的文件之后,接下来便是对文件内容进行分块,分块是为了更好地拆分语义单元,这样在后面可以更精确地进行语义检索。本文会介绍按字符切分、按字符递归切分。在按字符递归切分中,会分别介绍纯文本的切分、代码的切分、MarkDown 文本的切分。在进行示例演示时,使用 LangChain 的 API。
按字符切分
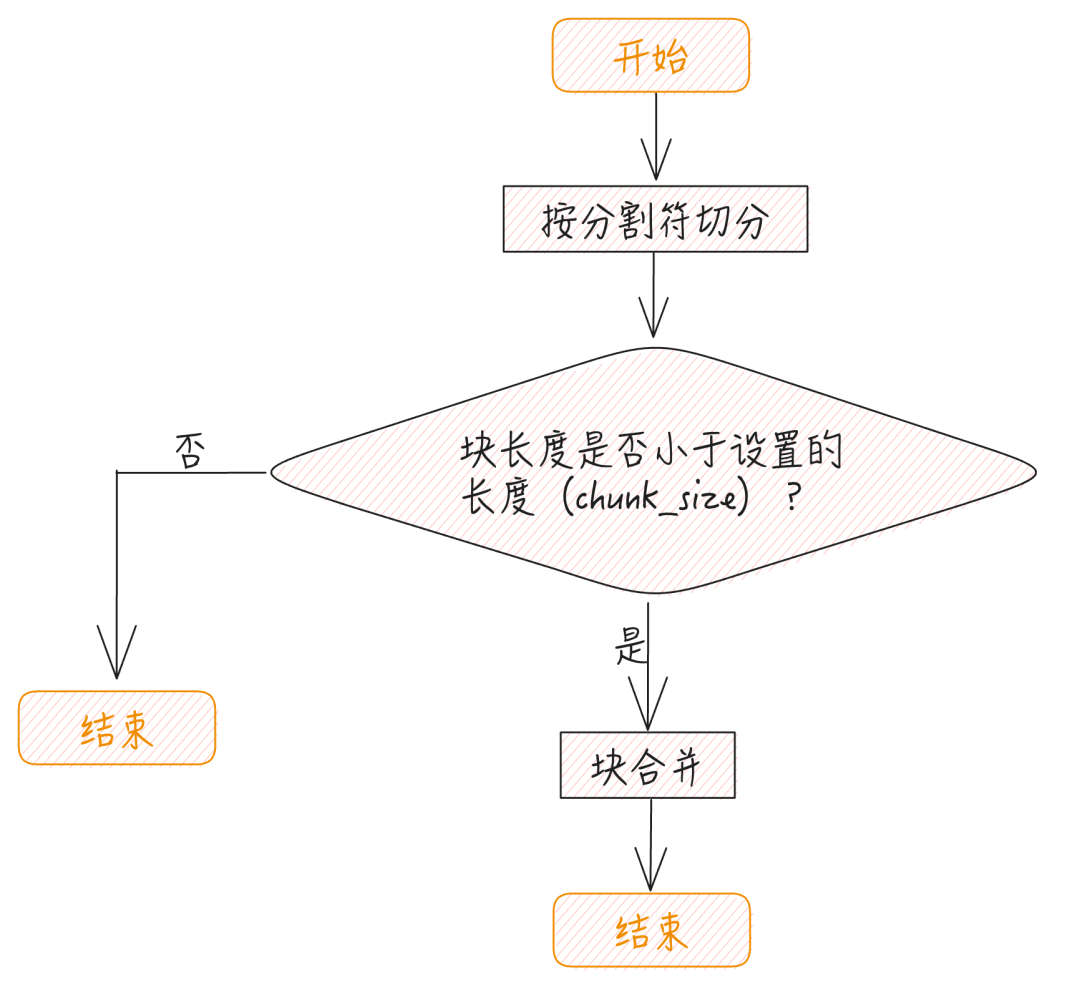
在使用按字符切分时,需要指定分割符,另外需要指定块的大小以及块之间重叠的大小(允许重叠是为了尽可能地避免按照字符进行分割造成的语义损失)。整个流程如下:

首先按照指定的分割符进行切分,切分过之后,如果块的长度小于 chunk_size 的大小,则进行块之间的合并。在进行合并时,遵循下面的规则:
-
1. 如果相邻块加在一起的长度小于或等于chunk_size,则进行合并;否则,不合并。
-
2. 在进行合并时,如果块的大小小于或等于chunk_overlap,并且和前后两个相邻块合并后,两个合并后的块均不超过chunk_size,则两个合并后的块允许有重叠。 示例:
from langchain_text_splitters import CharacterTextSplitter
test_text = """这几天心里颇不宁静。今晚在院子里坐着乘凉,忽然想起日日走过的荷塘,在这满月的光里,总该另有一番样子吧。月亮渐渐地升高了,墙外马路上孩子们的欢笑,已经听不见了;妻在屋里拍着闰儿,迷迷糊糊地哼着眠歌。我悄悄地披了大衫,带上门出去。
沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。今晚却很好,虽然月光也还是淡淡的。
路上只我一个人,背着手踱着。这一片天地好像是我的;我也像超出了平常的自己,到了另一个世界里。我爱热闹,也爱冷静;爱群居,也爱独处。像今晚上,一个人在这苍茫的月下,什么都可以想,什么都可以不想,便觉是个自由的人。白天里一定要做的事,一定要说的话,现在都可不理。这是独处的妙处,我且受用这无边的荷香月色好了。"""
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size = 300,
chunk_overlap = 200,
length_function = len,
is_separator_regex = False,
)
texts = text_splitter.create_documents([test_text])
for text in texts:
print(text)
在示例中,指定分割符为 \n,块的大小为 300,块之间重叠的大小为 200,输出结果如下:
page_content='这几天心里颇不宁静。今晚在院子里坐着乘凉,忽然想起日日走过的荷塘,在这满月的光里,总该另有一番样子吧。月亮渐渐地升高了,墙外马路上孩子们的欢笑,已经听不见了;妻在屋里拍着闰儿,迷迷糊糊地哼着眠歌。我悄悄地披了大衫,带上门出去。\n沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。今晚却很好,虽然月光也还是淡淡的。'
page_content='沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。今晚却很好,虽然月光也还是淡淡的。\n路上只我一个人,背着手踱着。这一片天地好像是我的;我也像超出了平常的自己,到了另一个世界里。我爱热闹,也爱冷静;爱群居,也爱独处。像今晚上,一个人在这苍茫的月下,什么都可以想,什么都可以不想,便觉是个自由的人。白天里一定要做的事,一定要说的话,现在都可不理。这是独处的妙处,我且受用这无边的荷香月色好了。'
按字符递归切分
纯文本的切分
上面的按字符切分只会按照指定的分割符切分一次,而按字符递归切分会指定一个分割符的列表,分割符列表为:"\n\n", "\n", " ", ""。在进行切分时,会遍历列表中的分割符进行按字符切分,直到满足块的大小要求。整个流程如下:

按字符递归切分可以认为是把按字符切分的流程循环多次,其中块合并的逻辑和按字符切分是一致的。 示例:
from langchain_text_splitters import RecursiveCharacterTextSplitter
test_text = """这几天心里颇不宁静。今晚在院子里坐着乘凉,忽然想起日日走过的荷塘,在这满月的光里,总该另有一番样子吧。月亮渐渐地升高了,墙外马路上孩子们的欢笑,已经听不见了;妻在屋里拍着闰儿,迷迷糊糊地哼着眠歌。我悄悄地披了大衫,带上门出去。
沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。今晚却很好,虽然月光也还是淡淡的。
路上只我一个人,背着手踱着。这一片天地好像是我的;我也像超出了平常的自己,到了另一个世界里。我爱热闹,也爱冷静;爱群居,也爱独处。像今晚上,一个人在这苍茫的月下,什么都可以想,什么都可以不想,便觉是个自由的人。白天里一定要做的事,一定要说的话,现在都可不理。这是独处的妙处,我且受用这无边的荷香月色好了。"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([test_text])
for text in texts:
print(text)
在示例中,块的大小为 150,块之间重叠的大小为 100,输出结果如下:
page_content='这几天心里颇不宁静。今晚在院子里坐着乘凉,忽然想起日日走过的荷塘,在这满月的光里,总该另有一番样子吧。月亮渐渐地升高了,墙外马路上孩子们的欢笑,已经听不见了;妻在屋里拍着闰儿,迷迷糊糊地哼着眠歌。我悄悄地披了大衫,带上门出去。'
page_content='沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。今晚却很好,虽然月光也还是淡淡的。'
page_content='路上只我一个人,背着手踱着。这一片天地好像是我的;我也像超出了平常的自己,到了另一个世界里。我爱热闹,也爱冷静;爱群居,也爱独处。像今晚上,一个人在这苍茫的月下,什么都可以想,什么都可以不想,便觉是个自由的人。白天里一定要做的事,一定要说的话,现在都可不理。这是独处的妙处,我且受用这无边的荷香月色'
page_content='闹,也爱冷静;爱群居,也爱独处。像今晚上,一个人在这苍茫的月下,什么都可以想,什么都可以不想,便觉是个自由的人。白天里一定要做的事,一定要说的话,现在都可不理。这是独处的妙处,我且受用这无边的荷香月色好了。'
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

代码的切分
代码切分的流程和按字符递归切分的流程是一样的,只不过每种语言的分割符列表是不一样的。下面以 Python 代码的切分来举例。Python 代码的分割符列表为 "\nclass ", "\ndef ", "\n\tdef ", "\n\n", "\n", " ", ""。
示例:
from langchain_text_splitters import (
Language,
RecursiveCharacterTextSplitter,
)
python_code = """
class Dog:
def __init__(self, name, age):
self.name = name
self.age = age
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = left + (right - left) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=400, chunk_overlap=0
)
python_docs = python_splitter.create_documents([python_code])
for python_doc in python_docs:
print(python_doc)
在示例中,块的大小为 400,块之间重叠的大小为 0,输出结果如下:
page_content='class Dog:\n def __init__(self, name, age):\n self.name = name\n self.age = age'
page_content='def binary_search(arr, target):\n left, right = 0, len(arr) - 1\n \n while left <= right:\n mid = left + (right - left) // 2\n if arr[mid] == target:\n return mid\n elif arr[mid] < target:\n left = mid + 1\n else:\n right = mid - 1\n \n return -1'
Markdown 的切分
Markdown 切分的流程和按字符递归切分的流程是一样的,只不过 Markdown 的分割列表为 "\n#{1,6} ", "```\n", "\n\\*\\*\\*+\n", "\n---+\n", "\n___+\n", "\n\n", "\n", " ", ""。
示例:
from langchain_text_splitters import RecursiveCharacterTextSplitter
markdown_text = """
## 灵活的 Markdown 语言
+ 在一篇笔记中处理文本、图片、表格和待办事项列表
+ 通过灵活的标签轻松整理笔记和项目
+ 根据不同场景需求,使用简单的 Markdown 符号便捷添加格式
## 轻松整理
+ 帮助您记笔记、制定周计划、写书,甚至建立个人维基的强大工具
+ 快如原生应用,无论在线或离线状态下都能与您天马行空的想象力同步
+ 想与全世界分享您的绝妙想法?可自由分享笔记或将其导出为多种格式
## 赏心悦目
+ 曾荣获苹果设计大奖
+ 界面简约而无冗杂,助您全身心沉浸其中
+ 多款精美主题提供了完美舒适的工作空间
## 安全私密
+ 您的笔记仅存储于本地或 iCloud,我们无法读取任何信息
+ 选择加密笔记,为拒绝窥视提供加强防线
"""
md_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN, chunk_size=200, chunk_overlap=0
)
md_docs = md_splitter.create_documents([markdown_text])
for md_doc in md_docs:
print(md_doc)
在示例中,块的大小为 200,块之间重叠的大小为 0,输出结果如下:
page_content='## 灵活的 Markdown 语言\n+ 在一篇笔记中处理文本、图片、表格和待办事项列表\n+ 通过灵活的标签轻松整理笔记和项目\n+ 根据不同场景需求,使用简单的 Markdown 符号便捷添加格式'
page_content='## 轻松整理\n+ 帮助您记笔记、制定周计划、写书,甚至建立个人维基的强大工具\n+ 快如原生应用,无论在线或离线状态下都能与您天马行空的想象力同步\n+ 想与全世界分享您的绝妙想法?可自由分享笔记或将其导出为多种格式\n\n\n## 赏心悦目\n+ 曾荣获苹果设计大奖\n+ 界面简约而无冗杂,助您全身心沉浸其中\n+ 多款精美主题提供了完美舒适的工作空间'
page_content='## 安全私密\n+ 您的笔记仅存储于本地或 iCloud,我们无法读取任何信息\n+ 选择加密笔记,为拒绝窥视提供加强防线'
总结
总结
本文对文本的切分进行了介绍,起到了抛砖引玉的作用。在实际的应用过程中,针对不同类型的文本应该选择不同的切分策略。而且,文本的切分和业务场景也是密切相关的,在制定策略的过程中,也要紧密结合业务场景,才能做到准确的切分。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
自己也整理很多AI大模型资料:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

{kind=link}
所有评论(0)