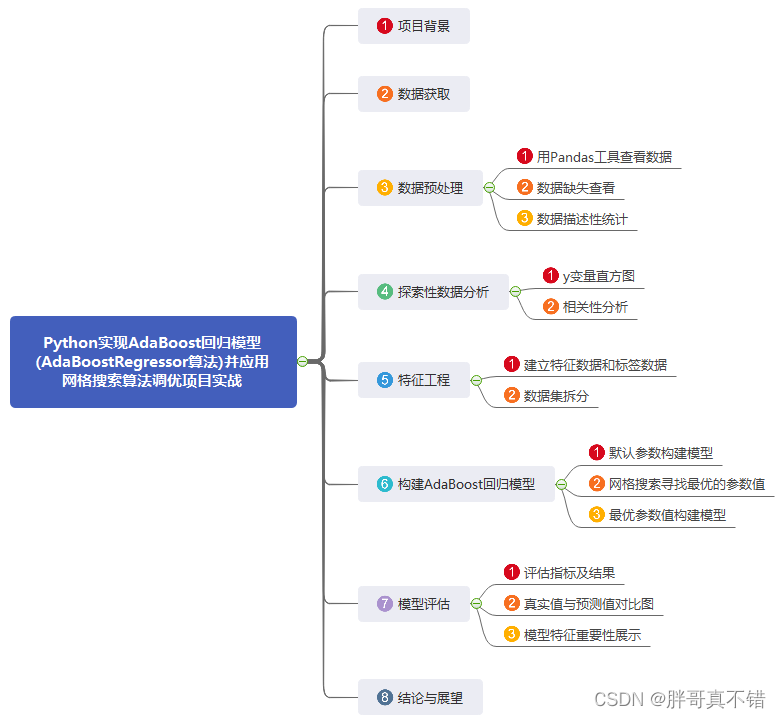
Python实现AdaBoost回归模型(AdaBoostRegressor算法)并应用网格搜索算法调优项目实战
Python实现AdaBoost回归模型(AdaBoostRegressor算法)并应用网格搜索算法调优项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+代码讲解),如需数据+代码+文档+代码讲解可以直接到文章最后获取。


1.项目背景
AdaBoost算法(Adaptive Boosting)是一种有效而实用的Boosting算法,它以一种高度自适应的方式按顺序训练弱学习器。针对分类问题,AdaBoost算法根据前一次的分类效果调整数据的权重,在上一个弱学习器中分类错误的样本的权重会在下一个弱学习器中增加,分类正确的样本的权重则相应减少,并且在每一轮迭代时会向模型加入一个新的弱学习器。不断重复调整权重和训练弱学习器,直到误分类数低于预设值或迭代次数达到指定最大值,最终得到一个强学习器。简单来说,AdaBoost算法的核心思想就是调整错误样本的权重,进而迭代升级。
本项目通过Adaboost回归算法来构建模型,并通过网格搜索算法寻找最优的参数值。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:

数据详情如下(部分展示):

3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:
![]()
3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:

从上图可以看到,总共有9个变量,数据中无缺失值,共1000条数据。
关键代码:
![]()
3.3 数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。

关键代码如下:
![]()
4.探索性数据分析
4.1 y变量直方图
用Matplotlib工具的hist()方法绘制直方图:

从上图可以看到,y变量主要集中在-300~300之间。
4.2 相关性分析

从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
![]()
6.构建AdaBoost回归模型
主要使用AdaBoost回归算法和网格搜索算法,用于目标回归。
6.1 默认参数构建模型

6.2 网格搜索寻找最优的参数值

6.3 最优参数值构建模型

7.模型评估
7.1 评估指标及结果
评估指标主要包括可解释方差值、平均绝对误差、均方误差、R方值等等。

从上表可以看出,R方为0.889;默认参数的R放为0.8552,经过网格搜索优化后模型效果有一定的提升。
关键代码如下:

7.2 真实值与预测值对比图

从上图可以看出真实值和预测值波动基本一致。
7.3 模型特征重要性展示

通过上图可以看到,每个特征的重要性。
8.结论与展望
综上所述,本文采用了AdaBoost算法来构建回归模型,并通过网格搜索算法寻找最优的参数值,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 链接:https://pan.baidu.com/s/1Osq_kdxdK0nL7LHdFFVznA
# 提取码:sp76更多项目实战,详见机器学习项目实战合集列表:
机器学习项目实战合集列表_机器学习实战项目_胖哥真不错的博客-CSDN博客

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)