机器学习——模型融合:Boosting算法
Boosting算法通过组合多个弱学习器来构建一个强学习器,能够提高模型的泛化能力。常见的Boosting方法包括AdaBoost、Gradient Boosting、XGBoost、LightGBM和CatBoost等。Boosting方法在实际应用中取得了很好的效果,但也需要注意训练时间较长和对异常值敏感等缺点。
机器学习——模型融合:Boosting算法
1. Boosting核心思想
Boosting算法是一种集成学习方法,其核心思想是通过组合多个弱学习器(即准确率略高于随机猜测的学习器)来构建一个强学习器(即准确率较高的学习器)。在Boosting中,每个弱学习器都在之前学习器的基础上进行训练,以弥补前一个模型的不足,最终形成一个具有较强泛化能力的模型。
2. 基本流程
Boosting算法的基本流程如下:
- 初始化训练集的权重,使每个样本的权重相等。
- 训练一个弱学习器,根据样本权重学习,得到一个模型。
- 根据模型的性能调整样本的权重,使得被错误分类的样本权重增加,正确分类的样本权重减少。
- 基于调整后的样本权重再次训练一个弱学习器。
- 重复步骤3和4,直到达到预设的迭代次数或者模型性能满足要求。
- 将所有弱学习器加权组合,得到最终的模型。
3. 基本流程
Boosting算法的基本流程可以描述如下:
- 初始化样本权重 w i = 1 N w_i = \frac{1}{N} wi=N1, i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N,其中 N N N为训练集样本数量。
- 对于每一轮迭代
t
=
1
,
2
,
.
.
.
,
T
t=1,2,...,T
t=1,2,...,T:
- 使用当前样本权重训练一个弱学习器 h t h_t ht。
- 计算弱学习器的错误率 e t e_t et。
- 计算弱学习器的权重 α t = 1 2 log ( 1 − e t e t ) \alpha_t = \frac{1}{2} \log(\frac{1 - e_t}{e_t}) αt=21log(et1−et)。
- 更新样本权重: w i ← w i × exp ( − α t y i h t ( x i ) ) w_i \leftarrow w_i \times \exp(-\alpha_t y_i h_t(x_i)) wi←wi×exp(−αtyiht(xi))。
- 对样本权重进行归一化: w i ← w i ∑ i = 1 N w i w_i \leftarrow \frac{w_i}{\sum_{i=1}^{N} w_i} wi←∑i=1Nwiwi。
- 组合所有弱学习器: H ( x ) = sign ( ∑ t = 1 T α t h t ( x ) ) H(x) = \text{sign} \left( \sum_{t=1}^{T} \alpha_t h_t(x) \right) H(x)=sign(∑t=1Tαtht(x))。
4. 常见的Boosting方法
常见的Boosting方法包括:
- AdaBoost(Adaptive Boosting)
- Gradient Boosting
- XGBoost(eXtreme Gradient Boosting)
- LightGBM(Light Gradient Boosting Machine)
- CatBoost
5. Boosting方法的优缺点
优点:
- 提高模型的泛化能力:通过组合多个弱学习器,Boosting算法能够降低模型的偏差,提高模型的泛化能力。
- 对噪声数据具有鲁棒性:通过动态调整样本权重,Boosting算法对噪声数据具有一定的鲁棒性。
缺点:
- 训练时间较长:由于Boosting算法需要顺序训练多个弱学习器,因此训练时间较长。
- 对异常值敏感:Boosting算法对异常值敏感,异常值容易影响模型性能。
Python实现算法
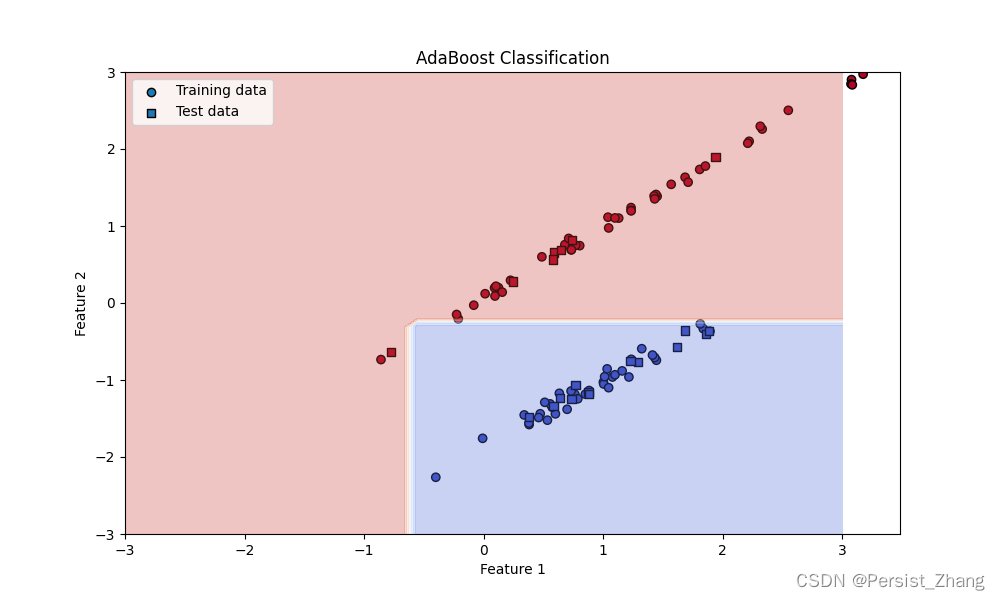
下面给出一个简单的Python实现,使用AdaBoost算法对一个示例数据集进行分类:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 创建示例数据集
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_clusters_per_class=1, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建AdaBoost分类器
clf = AdaBoostClassifier(n_estimators=50, random_state=42)
clf.fit(X_train, y_train)
# 测试集上的预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 可视化结果
plt.figure(figsize=(10, 6))
# 绘制训练数据
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='coolwarm', marker='o', edgecolors='k', label='Training data')
# 绘制测试数据
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap='coolwarm', marker='s', edgecolors='k', label='Test data')
# 绘制决策边界
xx, yy = np.meshgrid(np.linspace(-3, 3, 50), np.linspace(-3, 3, 50))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap='coolwarm')
plt.title('AdaBoost Classification')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()

使用AdaBoostClassifier创建一个AdaBoost分类器,并在训练集上拟合它。然后,使用测试集进行预测,并计算模型的准确率。最后,使用matplotlib库将训练数据、测试数据和决策边界可视化显示出来
总结
Boosting算法通过组合多个弱学习器来构建一个强学习器,能够提高模型的泛化能力。常见的Boosting方法包括AdaBoost、Gradient Boosting、XGBoost、LightGBM和CatBoost等。Boosting方法在实际应用中取得了很好的效果,但也需要注意训练时间较长和对异常值敏感等缺点。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 29
29 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)