13_旷视轻量化网络--ShuffleNet V2
https://www.bilibili.com/video/BV1d3411Y7Ms/?spm_id_from=333.999.0.0&vd_source=7dace3632125a1ef7fd32c285eb2fbac
回顾一下ShuffleNetV1:08_旷视轻量化网络--ShuffleNet V1-CSDN博客
1.1 简介
ShuffleNet V2是在2018年由旷视科技的研究团队提出的一种深度学习模型,主要用于图像分类和目标检测等计算机视觉任务。它是ShuffleNet V1的后续版本,重点在于提供更高效的模型设计,同时保持或提升模型的准确性。
核心设计理念:
-
高效性与准确性并重:ShuffleNet V2的设计初衷是解决深度学习模型在移动端和嵌入式设备上部署时面临的效率与准确性之间的权衡问题。它旨在以最少的计算资源和内存占用,达到尽可能高的分类或检测准确率。
-
通道重排(Channel Shuffle):这一特性从ShuffleNet V1继承而来,通过随机打乱不同组内的通道,促进特征的混合,增加模型的表达能力。这有助于模型学习到更加丰富的特征组合,从而提升性能。
主要创新点:
-
分层结构优化:不同于V1,V2版本通过引入更复杂的块(blocks)设计来优化网络结构。每个块可能包含多个路径,每个路径具有不同的功能,如特征提取、特征重组等,这样的设计能更高效地利用计算资源。
-
均衡通道宽度:研究发现,保持每层网络的通道数相对均衡可以减少内存访问的开销,并且对模型性能影响不大。因此,ShuffleNet V2采用了所有层通道数相等的设计原则,这有助于模型在移动设备上更快运行。
-
组卷积的改进应用:虽然组卷积能有效减少计算量,但过度分组会导致模型性能下降。V2通过精细调整组的数量和结构,找到了计算效率和模型性能之间的最佳平衡点。
-
直接面向实际运行速度的优化:在设计过程中,除了理论上的计算量(FLOPs)外,研究者还直接考虑了模型在实际硬件上的运行速度。这意味着在设计决策中融入了对实际部署环境的考量,包括CPU和GPU的特定性能特征。
-
计算和内存访问成本的细致优化:通过对模型内部的元素级操作(如ReLU、Addition)进行深入分析和优化,减少了不必要的计算负担和内存访问,进一步提升了模型的运行效率。
ShuffleNet V2由于其出色的效率和性能,在移动设备、智能安防、自动驾驶以及各种IoT设备上的视觉应用中得到了广泛应用。它的设计原则和优化思路也为后来的轻量化网络设计提供了宝贵的经验和指导,推动了深度学习模型在实际应用中的普及和发展。
shuffleNet出自论文《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》,下面我们来学习一下这篇论文。
1.2 四条轻量化网络设计原则

准则一和准则二:
对于V2,用了大量的分组1x1卷积。





准则三:(碎片化指分支多,网络较宽)

准则四:(尽量回避主元素操作)



1.3 V2的模型结构
ShuffleNet V2相比V1有几项关键改进和特点,这些改进主要是为了进一步提升模型的效率和准确性,特别是在移动端和嵌入式设备上的表现。以下是ShuffleNet V2相较于V1的一些主要特点:
- 更高效的结构设计:
- V2放弃了V1中的基于瓶颈模块的设计,转而采用一种新的结构,称为“ShuffleNet块”。这种设计通过重新安排层的顺序和结构,减少了计算成本,同时保持了模型的表达能力。
- 均衡的通道宽度:
- V2提出了一种“均衡通道宽度”的设计理念,即网络中所有层的通道数保持一致或接近。这与V1中通道数随深度增加而增加的做法不同。实验表明,这种设计能降低内存访问成本(MAC),提升运行效率,且对准确性影响较小。
- 优化的组卷积策略:
- 在V2中,对组卷积(group convolution)的使用进行了优化,避免了过量分组可能带来的性能下降。通过合理设置组数,V2在减少计算量的同时,确保了模型的表达能力不受太大影响。
- 直接优化实际运行速度:
- 设计时不仅考虑理论上的计算复杂度(FLOPs),更侧重于模型在实际设备上的运行速度。这意味着V2在设计时充分考虑了硬件特性,如内存带宽和计算单元的利用率。
- 减少元素级操作:
- 为了避免element-wise操作(如加法)造成的额外计算负担,V2中使用concatenation(连接操作)代替了部分element-wise操作,减少了计算成本,提升了运行效率。
- 通道重排的改进位置:
- 相对于V1中channel shuffle的位置,V2将其放置在block的不同位置,以更好地适应新的结构设计,进一步促进了特征的混合和信息的流通。
- 新增操作:
- 在全局平均池化(Global Average Pooling, GAP)之前添加了一个额外的卷积层(conv5),这是V2相比于V1的一个显著区别,旨在进一步提炼特征,提升模型的分类性能。
右侧是V2的结构。我们先看基本模块。V2在基本模块采用了一个“channel Split”操作,就是把一半的通道数走左边的路,另一半通道数走右边的路,且注意:V2的1x1卷积并不是像V1那样是分组1x1卷积。然后采用concat(摞在一起连接)操作而不是逐元素相加(ADD)的操作

可以看到V2是满足轻量化网络的四条设计原则的。
V2的模型结构如下图:

和DenseNet的特征复用相比较,类似的地方:
 ShuffleNetV2通过模型的结构实现了不同层之前模型的共享和复用。这种效果和DenseNet相比是很类似的。
ShuffleNetV2通过模型的结构实现了不同层之前模型的共享和复用。这种效果和DenseNet相比是很类似的。
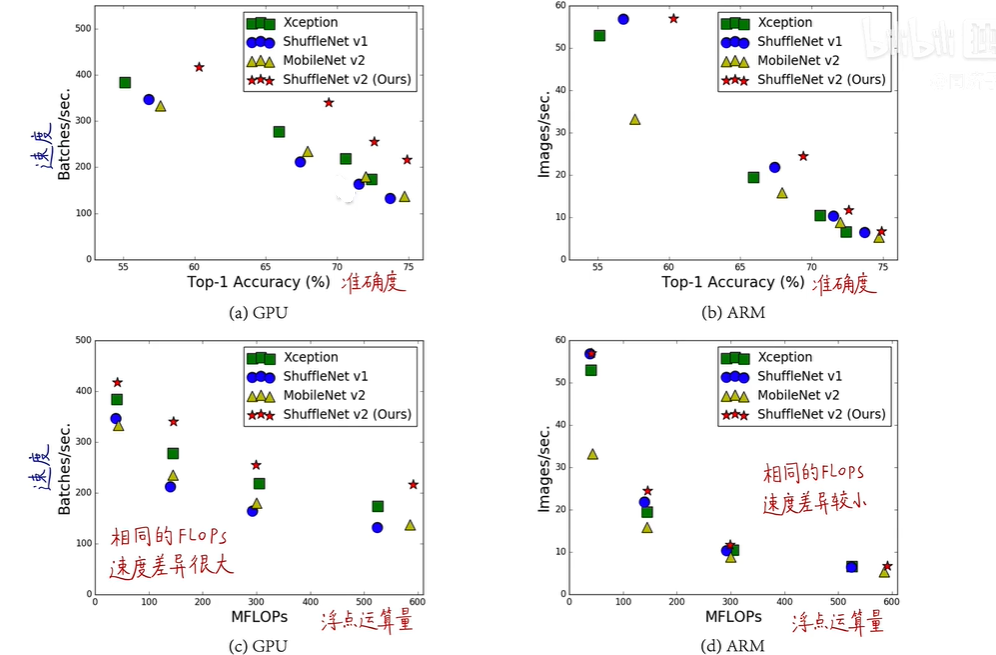
1.4 V2的性能

图为ShuffleNetV2与部分其他轻量化的网络比较:

2.pytorch模型复现
# Author:SiZhen
# Create: 2024/6/30
# Description: pytorch实现ShuffleNetV2模型
import torch
import torch.nn as nn
import torchvision
#3x3DW卷积(含激活函数)
def Conv3x3BNRelu(in_channels,out_channels,stride,groups):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=3,stride=stride,padding=1,groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True) #在原有张量修改,节省内存
)
#3x3DW卷积(不含激活函数)
def Conv3x3BN(in_channels,out_channels,stride,groups):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=3,stride=stride,padding=1,groups=groups),
nn.BatchNorm2d(out_channels)
)
#1x1PW卷积(含激活函数)
def Conv1x1BNRelu(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=1,stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
#1x1PW卷积(不含激活函数)
def Conv1x1BN(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=1,stride=1),
nn.BatchNorm2d(out_channels)
)
#进行channel split。dim默认为0,但是由于channels位置在1,故传参为1
class HalfSplit(nn.Module):
def __init__(self,dim=0,first_half=True):
super(HalfSplit, self).__init__()
self.first_half = first_half
self.dim = dim
def forward(self,input):
#对input的channels进行分半操作
splits = torch.chunk(input,2,dim=self.dim) #shape=[b,c,h,w],对于dim=1,针对channels
return splits[0] if self.first_half else splits[1] #返回其中一半
#channel shuffle模块,增加组间交流
class ChannelShuffle(nn.Module):
def __init__(self,groups):
super(ChannelShuffle, self).__init__()
self.groups = groups
def forward(self,x):
N,C,H,W = x.size()
g = self.groups
return x.view(N,g,int(C/g),H,W).permute(0,2,1,3,4).contiguous().view(N,C,H,W)
#ShuffleNet的基本单元
class ShuffleNetUnits(nn.Module):
def __init__(self,in_channels,out_channels,stride,groups):
super(ShuffleNetUnits, self).__init__()
self.stride = stride
#如果stride = 2,由于主分支需要加上从分支的channels,为了两者加起来等于planes,所以需要先减一下
if self.stride>1:
mid_channels = out_channels - in_channels
#如果stride = 1,mid_channels是一半,直接除以2即可
else:
mid_channels = out_channels//2
in_channels = mid_channels
#进行两次切分,一次接受一半,一次接受另外一半
self.first_half = HalfSplit(dim=1,first_half=True) #对channels进行切半操作,第一次分:first_half = True
self.second_split = HalfSplit(dim=1,first_half=False) #返回输入的另外一般channels,两次合起来才是完整的一份channels
#两个结构的主分支都是一样的,知识3x3DW卷积中的stride不一样,所以可以调用同样的self.bottleneck,stride会自动改变
self.bottleneck = nn.Sequential(
Conv1x1BNRelu(in_channels,in_channels), #1x1卷积不改变channels
Conv3x3BN(in_channels,mid_channels,stride,groups), #升维
Conv1x1BNRelu(mid_channels,mid_channels) #不改变channels
)
#图d的从分支:3x3的DW卷积->1x1卷积
if self.stride>1:
self.shortcut = nn.Sequential(
Conv3x3BN(in_channels=in_channels,out_channels=in_channels,stride=stride,groups=groups),
Conv1x1BNRelu(in_channels,in_channels)
)
self.channel_shuffle = ChannelShuffle(groups)
def forward(self,x):
# stride = 2,对于结构(d)
if self.stride>1:
x1 = self.bottleneck(x) #torch.size([1,220,28,28])
x2 = self.shortcut(x) #torch.size([1,24,28,28])
#两个分支作concat操作之后,输出的channels便为224,与planes[0]值相等
#out输出为:torch.size([1,244,28,28])
#stride = 1:对于结构(c)
else:
x1 = self.first_half(x) #一开始直接将channels等分两半,x1称为主分支的一半,此时的x1:channels=112
x2 = self.second_split(x) #x2称为输入的另外一半channels:此时x2::channels = 112
x1 = self.bottleneck(x1) #结构(c)的主分支处理
#两个分支作concat操作之后,输出的channels便为224,与planes[0]值相等
#out输出为:torch.Size([1,244,28,28])
out = torch.cat([x1,x2],dim=1)
out = self.channel_shuffle(out) #shufflenet的精髓
return out
class ShuffleNetV2(nn.Module):
#shuffle_v2_x2_0:planes = [244,488,976] layers = [4,8,4]
#shuffle_v2_x1_5:planes = [176,352,704] layers = [4,8,4]
def __init__(self,planes,layers,groups,is_shuffle2_0,num_classes=5):
super(ShuffleNetV2, self).__init__()
self.groups = groups
self.stage1 = nn.Sequential(
Conv3x3BNRelu(in_channels=3,out_channels=24,stride=2,groups=1), #torch.size([1,24,112,112])
nn.MaxPool2d(kernel_size=3,stride=2,padding=1) #torch.size([1,24,56,56])
)
self.stage2 = self._make_layer(24,planes[0],layers[0],True) # ([1,244,28,28])
self.stage3 = self._make_layer(planes[0],planes[1],layers[1],False) #([1,488,14,14])
self.stage4 = self._make_layer(planes[1],planes[2],layers[2],False) #([1,976,7,7])
#0.5x / 1x / 1.5x 输出为1024 ,2x输出为2048
self.conv5 = nn.Conv2d(in_channels=planes[2],out_channels=1024*is_shuffle2_0,kernel_size=1,stride=1)
self.global_pool =nn.AdaptiveAvgPool2d(1) #([1,976,1,1])
self.dropout = nn.Dropout(p=0.2) # 丢失概率为0.2
#0.5x / 1x /1.5x 输入为1024 ,2x输入为2048
self.linear = nn.Linear(in_features=1024*is_shuffle2_0,out_features=num_classes)
#此处的is_stage2作用不大,因为均采用3x3DW卷积,也就是group=1的组卷积
def _make_layer(self,in_channels,out_channels,block_num,is_stage2):
layers = []
#V2中,每个stage的第一个结构stride均为2;此stage的其余结构stride均为1
#对于stride = 2的情况,对应结构(d):一开始无切分操作,主分支经过1x1->3x3->1x1,从分支经过3x3->1x1,两个分支作concat操作
layers.append(ShuffleNetUnits(in_channels=in_channels,out_channels=out_channels,stride=2,groups=1 if is_stage2 else self.groups))
#对于stride = 1的情况,对应结构(c):一开始就切分channel,主分支经过1x1->3x3->1x1再与shortcut进行concat操作
for idx in range(1,2):
layers.append(ShuffleNetUnits(in_channels=out_channels,out_channels=out_channels,stride=1,groups=self.groups))
return nn.Sequential(*layers)
#何凯明的方法初始化权重
def init_params(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m,nn.BatchNorm2d)or isinstance(m,nn.Linear):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,0)
#input: torch.size([1,3,224,224])
def forward(self,x):
x = self.stage1(x) #[1,24,56,56]
x = self.stage2(x) #[1,244,28,28]
x = self.stage3(x) #[1,488,14,14]
x = self.stage4(x) #[1,976,7,7]
x = self.conv5(x) #[1,2048,7,7]
x = self.global_pool(x) #[1,2048,1,1]
x = x.view(x.size(0),-1) #[1,2048] ,相当于flatten操作
out = self.linear(x) #torch.size([1,5])
return out
def shufflenet_v2_x2_0(**kwargs):
planes = [244,488,976]
layers = [4,8,4]
model = ShuffleNetV2(planes,layers,1,2)
return model
def shufflenet_v2_x1_5(**kwargs):
planes = [176,352,704]
layers = [4,8,4]
model = ShuffleNetV2(planes,layers,1,1)
return model
def shufflenet_v2_x1_5(**kwargs):
planes = [116,232,464]
layers = [4,8,4]
model = ShuffleNetV2(planes,layers,1,1)
return model
def shufflenet_v2_x0_5(**kwargs):
planes = [48,96,192]
layers = [4,8,4]
model = ShuffleNetV2(planes,layers,1,1)
return model
if __name__ == '__main__':
model = shufflenet_v2_x2_0()
input = torch.rand(1,3,224,224)
out = model(input)
print(out.shape)
torch.save(model.state_dict(),"shufflenet_v2_x2_0.mdl")

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)