总结9种提速又提效的Transformer优化方案
Transformer目前已经成为人工智能领域的主流模型,应用非常广泛。然而Transformer中注意力机制计算代价较高,随着序列长度的增加,这个计算量还会持续上升。为了解决这个问题,业内出现了许多Transformer的魔改工作,以优化Transformer的运行效率。我这次就给大家分享9篇对Transformer模型进行效率优化的改进文章,以方便大家更高效地使用模型,寻找论文创新点。
前言
Transformer目前已经成为人工智能领域的主流模型,应用非常广泛。然而Transformer中注意力机制计算代价较高,随着序列长度的增加,这个计算量还会持续上升。
为了解决这个问题,业内出现了许多Transformer的魔改工作,以优化Transformer的运行效率。我这次就给大家分享9篇对Transformer模型进行效率优化的改进文章,以方便大家更高效地使用模型,寻找论文创新点。
文章主要涉及4个方向:稀疏注意力机制、Transformer处理长文本、Transformer运行提效以及卷积Attention,原文及源码都已整理
一、稀疏注意力机制
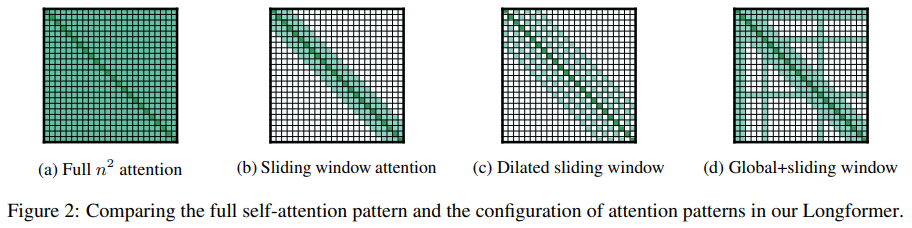
1.1 Longformer: The Long-Document Transformer
长文档Transformer
「方法简述:」Transformer-based models处理长序列时存在困难,因为它们的自注意力操作与序列长度呈二次方关系。Longformer通过引入一个与序列长度呈线性关系的注意力机制解决了这个问题,使其能够轻松处理数千个标记或更长的文档。Longformer在字符级语言建模方面表现优秀,并在各种下游任务上取得了最先进的结果。此外,Longformer还支持长文档生成序列到序列任务,并在arXiv摘要生成数据集上展示了其有效性。

1.2 Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
增强局部性并打破Transformer在时间序列预测中的内存瓶颈
「方法简述:」时间序列预测是许多领域中的重要问题,包括太阳能发电厂能源输出、电力消耗和交通拥堵情况的预测。本文提出了使用Transformer来解决这种预测问题的方法。虽然初步研究表明其性能令人印象深刻,但作者发现它有两个主要缺点:局部性不敏感和内存瓶颈。为了解决这两个问题,作者提出了卷积自注意力和LogSparse Transformer,它们能够更好地处理局部上下文并降低内存成本。实验表明,这些方法在时间序列预测方面具有优势。

1.3 Adaptive Attention Span in Transformers
Transformers中的自适应注意力跨度
「方法简述:」论文提出了一种新的自注意力机制,可以学习其最优的注意力跨度。这使得我们可以显著扩展Transformer中使用的最大上下文大小,同时保持对内存占用和计算时间的掌控。作者在字符级语言建模任务上展示了该方法的有效性,在该任务中,作者使用最大8k个字符的上下文实现了在text8和enwiki8上最先进的性能。

二、Transformer处理长文本
2.1 Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
超越固定长度上下文的注意语言模型
「方法简述:」Transformers在语言建模中受到固定长度上下文的限制,作者提出了一种新的神经网络架构Transformer-XL,可以学习超过固定长度的依赖关系。它由一个段级别循环机制和一个新的位置编码方案组成,能够捕捉更长的依赖关系并解决上下文碎片化问题。该方法不仅在短序列和长序列上都取得了更好的性能,而且在评估期间比普通的Transformers快1,800+倍。

三、Transformer运行提效
3.1 REFORMER: THE EFFICIENT TRANSFORMER
高效的Transformer
「方法简述:」大型Transformer模型训练成本高,尤其是在长序列上。论文提出了两种技术来提高效率:使用局部敏感哈希替换点积注意力,将复杂度从O(L^2)降低到O(L log L);使用可逆残差层代替标准残差,允许只存储一次激活。由此产生的Reformer模型在长序列上表现相当,但更内存高效和更快。

3.2 RETHINKING ATTENTION WITH PERFORMERS
重新思考注意力机制:Performer模型
「方法简述:」论文介绍了Performers,一种Transformer架构,可以以可证明的准确性估计常规(softmax)全秩注意力Transformers,但仅使用线性空间和时间复杂度。为了近似softmax注意力核,Performers使用了一种新颖的快速注意通过正交随机特征方法(FAVOR+),并可以用于高效地建模可核化的注意力机制。

3.3 Linformer: Self-Attention with Linear Complexity
具有线性复杂度的自注意力机制
「方法简述:」大型Transformer模型在自然语言处理应用中表现出色,但长序列的训练和部署成本很高。本文提出一种新自注意力机制,将复杂度从O(n^2)降低到O(n),同时保持性能不变。由此产生的Linformer比标准的Transformer更节省时间和内存。

四、卷积Attention
4.1 Conformer: Convolution-augmented Transformer for Speech Recognition
用于语音识别的卷积增强Transformer
「方法简述:」Conformer是一种结合了卷积神经网络和Transformer的模型,用于语音识别。它能够同时捕捉音频序列的局部和全局依赖关系,并实现了最先进的准确率。在LibriSpeech基准测试中,Conformer在不使用语言模型的情况下实现了2.1%/4.3%的WER,在使用外部语言模型的情况下实现了1.9%/3.9%的WER。此外,它还具有竞争力的小模型,只有10M参数。

4.2 LITE TRANSFORMER WITH LONG-SHORT RANGE ATTENTION
具有长短范围注意力的轻量级Transformer
「方法简述:」本文提出了一种高效的移动自然语言处理架构Lite Transformer,它使用长短范围注意力(LSRA)来提高性能。LSRA将一组头专门用于局部上下文建模(通过卷积),另一组头则专门用于长距离关系建模(通过注意力)。在三个语言任务上,Lite Transformer始终优于普通的Transformer。在受限资源下,Lite Transformer比Transformer在WMT’14英法翻译任务上高出1.2/1.7 BLEU分数。

最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)