
重学SpringBoot3-集成Hazelcast
在这篇文章中,我们介绍了如何将 Hazelcast 集成到 Spring Boot 3 中,并展示了它作为分布式缓存的用法。Hazelcast 的优势包括分布式缓存、会话管理、数据共享和分布式锁等功能,非常适合在微服务环境中使用。Hazelcast 的作用总结:分布式缓存:缓存常用数据,减轻数据库压力,提高性能。会话管理:在多实例环境中管理用户会话,实现会话共享。数据共享:在分布式系统中共享数据,
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》
期待您的点赞👍收藏⭐评论✍

重学SpringBoot3-集成Hazelcast
Hazelcast 是一个流行的开源内存数据网格平台,可以用于分布式数据存储、缓存、会话管理和流处理。它具备水平扩展能力,并提供内存数据存储的高性能。通过将 Hazelcast 与 Spring Boot 3 结合,可以让开发者轻松实现分布式缓存、数据共享、会话管理等功能。
在这篇博客中,我们将详细介绍如何将 Hazelcast 整合到 Spring Boot 3 应用中,并探讨 Hazelcast 在分布式环境中的作用和优势。
1. Hazelcast 的作用
在分布式系统中,数据的一致性、可用性和性能至关重要。Hazelcast 通过其内存数据网格(IMDG)的特性,提供了一种集成式的解决方案:
- 分布式缓存:Hazelcast 可作为一个高性能的缓存系统,将经常访问的数据存储在内存中,减少数据库访问,提升应用性能。
- 会话管理:它支持分布式会话管理,在多实例的微服务环境中,可以将用户的会话信息存储到 Hazelcast 中,确保用户在不同实例之间的会话一致性。
- 分布式数据存储:Hazelcast 允许你将数据分布在多个节点中,这有助于实现数据的高可用性和容错性。
- 集群管理:Hazelcast 支持动态集群管理,节点可以随时加入或离开集群,而不会影响系统的稳定性。
- 分布式锁:在分布式环境中,可以通过 Hazelcast 实现分布式锁,用于防止数据竞争问题。
接下来,我们将介绍如何将 Hazelcast 与 Spring Boot 3 进行整合,打造高效的分布式缓存应用。
2. Spring Boot 3 整合 Hazelcast 的步骤
2.1 添加 Hazelcast 依赖
首先,你需要在项目的 pom.xml 中添加 Hazelcast 相关的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.3.0</version>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring</artifactId>
<version>5.3.0</version>
</dependency>
hazelcast-spring 提供了与 Spring 框架的集成支持。
2.2 配置 Hazelcast 实例
Hazelcast 可以通过 XML 或 Java 配置文件进行配置。为了简单起见,我们使用 Java 配置方式创建一个默认的 Hazelcast 配置实例:
import com.hazelcast.config.Config;
import com.hazelcast.config.MapConfig;
import com.hazelcast.config.EvictionPolicy;
import com.hazelcast.config.MaxSizePolicy;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.Hazelcast;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class HazelcastConfig {
@Bean
public HazelcastInstance hazelcastInstance() {
Config config = new Config();
// 配置分布式 Map
MapConfig mapConfig = new MapConfig();
mapConfig.setName("my-distributed-map");
mapConfig.setMaxSizeConfig(new MapConfig.MaxSizeConfig(200, MaxSizePolicy.FREE_HEAP_SIZE));
mapConfig.setEvictionPolicy(EvictionPolicy.LRU); // 最近最少使用策略
mapConfig.setTimeToLiveSeconds(60); // 设置 TTL 为 60 秒
config.addMapConfig(mapConfig);
return Hazelcast.newHazelcastInstance(config); // 启动 Hazelcast 实例
}
}
在这个配置中,我们创建了一个名为 my-distributed-map 的 Hazelcast 分布式 Map,并设置了以下配置:
- 最大大小:设置了缓存的最大堆内存使用量。
- 驱逐策略:使用 LRU(最近最少使用)策略来决定缓存对象的移除。
- 生存时间:设置每个缓存对象的 TTL 为 60 秒。
3. 集成 Hazelcast 与 Spring Boot 缓存
接下来,我们需要启用 Spring 的缓存功能,并使用 Hazelcast 作为缓存提供者。为此,我们可以使用 Spring Boot 的注解驱动缓存功能。
首先,启用缓存功能:
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableCaching
public class CacheConfig {
// Hazelcast 已在 HazelcastConfig 中配置,无需额外操作
}
然后,你可以使用 Spring 的缓存注解来在你的服务层启用缓存。以下是一个示例:
package com.coderjia.boot317hazelcast.service;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
/**
* @author CoderJia
* @create 2024/10/23 下午 10:45
* @Description
**/
@Service
public class ProductService {
@Cacheable(value = "my-distributed-map", key = "#id")
public String getProductById(Long id) {
// 模拟获取数据的耗时操作
try {
System.out.println("从数据库查数据id:" + id);
Thread.sleep(3000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return "Product-" + id;
}
}
这里,@Cacheable 注解指定了缓存的名称 my-distributed-map,并且指定 id 作为缓存的键。在第一次调用 getProductById() 时,方法的结果将被缓存。随后的相同 ID 调用将直接从 Hazelcast 缓存中获取结果,而不会再次执行耗时操作。
4. 验证 Hazelcast 缓存
启动 Spring Boot 应用后,你可以通过调用 ProductService 来验证缓存是否生效。
package com.coderjia.boot317hazelcast.controller;
import com.coderjia.boot317hazelcast.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author CoderJia
* @create 2024/10/23 下午 10:45
* @Description
**/
@RestController
public class Controller {
@Autowired
private ProductService productService;
@GetMapping("/test")
public void testCache() {
// 第一次调用,触发实际方法执行
System.out.println(productService.getProductById(1L));
// 第二次调用,应该从缓存中获取结果
System.out.println(productService.getProductById(1L));
}
}
你会发现第二次调用时,结果会立即返回,而不会再有耗时操作。

第一次调接口:
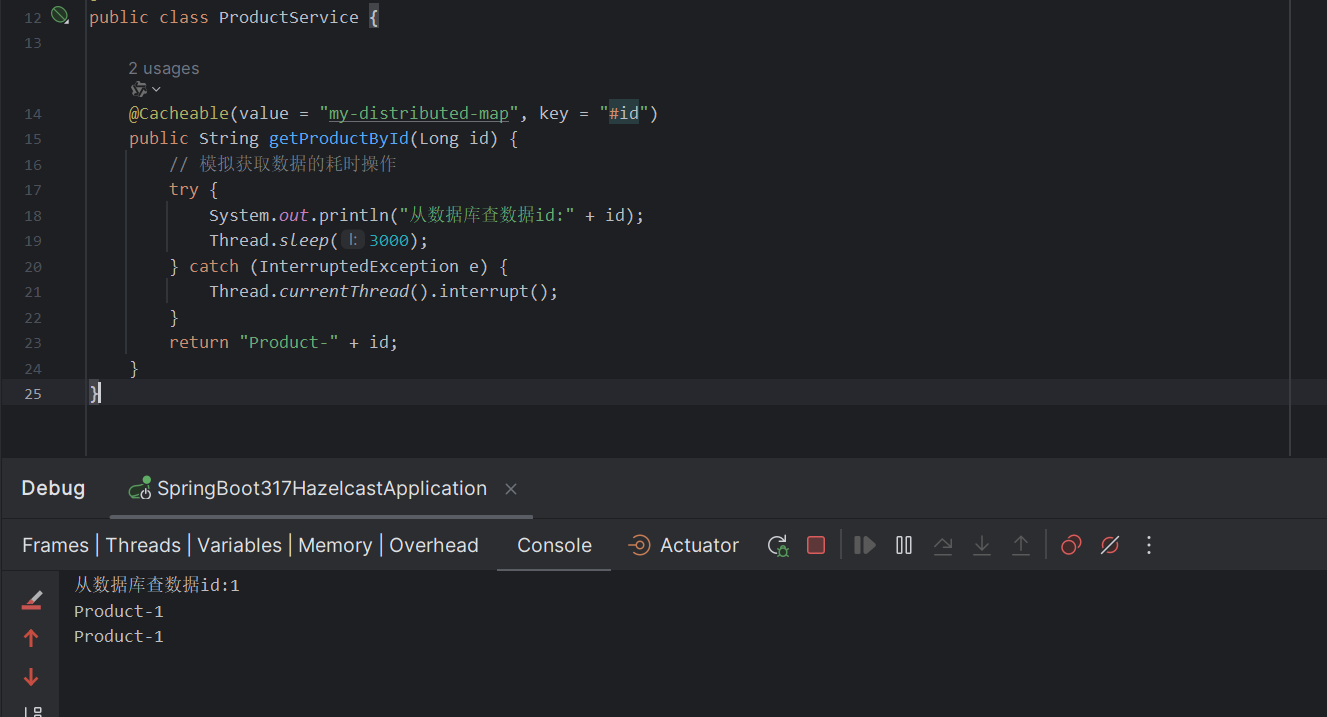
第二次调接口,此时缓存还在有效期中。

5. Hazelcast 集群配置
Hazelcast 的强大之处在于其原生支持集群。在多实例的微服务环境中,Hazelcast 实例可以自动发现并组成集群,实现数据的共享和同步。可以通过以下方式启用集群配置:
@Bean
public HazelcastInstance hazelcastInstance() {
Config config = new Config();
config.getNetworkConfig().getJoin().getMulticastConfig().setEnabled(true); // 启用多播发现
return Hazelcast.newHazelcastInstance(config);
}
当多个 Hazelcast 实例在同一网络中运行时,它们会自动发现并组成集群,提供高可用性和负载均衡。
6. 总结
在这篇文章中,我们介绍了如何将 Hazelcast 集成到 Spring Boot 3 中,并展示了它作为分布式缓存的用法。Hazelcast 的优势包括分布式缓存、会话管理、数据共享和分布式锁等功能,非常适合在微服务环境中使用。
Hazelcast 的作用总结:
- 分布式缓存:缓存常用数据,减轻数据库压力,提高性能。
- 会话管理:在多实例环境中管理用户会话,实现会话共享。
- 数据共享:在分布式系统中共享数据,实现高可用性和容错性。
- 分布式锁:实现分布式系统中的并发控制。
通过 Hazelcast,我们可以轻松构建高性能、高可用的分布式应用。未来可以进一步探索 Hazelcast 的更多特性,比如分布式事件处理、分布式集合和流处理等。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 68
68 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)