
Dubbo服务调用过程详解
dubbo服务调用主要分为两个过程,分别是消费者发送请求和接收响应结果,提供者接收请求。发送请求:服务接口的代理对象执行目标方法,被InvokerInvocationHandler#invoke方法拦截,经过路由过滤、负载均衡后选择一个DubboInvoker对象,调用doInvoke方法。创建一个Request对象,并生成全局唯一的请求ID,接着实例化一个DefaultFuture对象,将请求I
主流程

客户端发起本地调用,实际上调用的是代理类,代理类通过远程客户端(默认是NettyClient)发起请求。先是构建协议头,指定通信协议、序列化器类型和body长度,接着将Java对象序列化成协议体,然后发送数据。
服务端(NettyServer)接收请求,分发给业务线程池处理,由业务线程找到对应的实现类,执行相应方法并返回结果。
调用具体的信息
那客户端告知服务端的具体信息应该包含哪些呢?
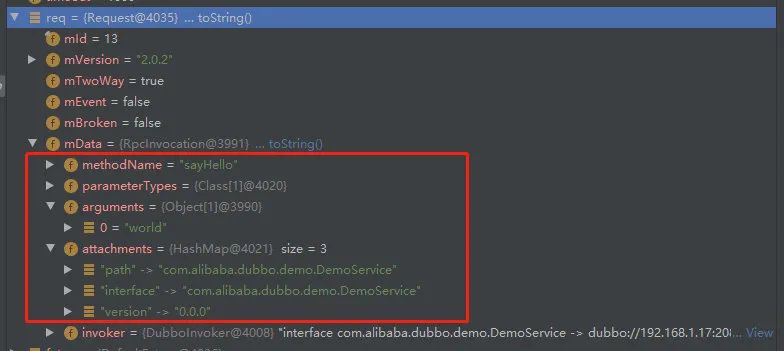
首先客户端肯定要告知要调用是服务端的哪个接口,当然还需要方法名、方法的参数类型、方法的参数值,还有可能存在多个版本的情况,所以还得带上版本号。
由这么几个参数,那么服务端就可以清晰的得知客户端要调用的是哪个方法,可以进行精确调用!
然后组装响应返回即可,我这里贴一个实际调用请求对象列子。
常见的三种协议形式
首先远程调用需要定义协议,也就是互相约定我们要讲什么样的语言,要保证双方都能听得懂。
应用层一般有三种类型的协议形式,分别是:固定长度形式、特殊字符隔断形式、header+body 形式。
固定长度形式:指的是协议的长度是固定的,比如100个字节为一个协议单元,那么读取100个字节之后就开始解析。
优点就是效率较高,无脑读一定长度就解析。
缺点就是死板,每次长度只能固定,不能超过限制的长度,并且短了还得填充,在 RPC 场景中不太合适,谁晓得参数啥的要多长,定长了浪费,定短了不够。
特殊字符隔断形式:其实就是定义一个特殊结束符,根据特殊的结束符来判断一个协议单元的结束,比如用换行符等等。
这个协议的优点是长度自由,反正根据特殊字符来截断,缺点就是需要一直读,直到读到一个完整的协议单元之后才能开始解析,然后假如传输的数据里面混入了这个特殊字符就出错了。
header+body 形式:也就是头部是固定长度的,然后头部里面会填写 body 的长度, body 是不固定长度的,这样伸缩性就比较好了,可以先解析头部,然后根据头部得到 body 的 len 然后解析 body。
dubbo 协议就是属于 header+body 形式,而且也有特殊的字符 0xdabb ,这是用来解决 TCP 网络粘包问题的。
Dubbo 协议
Dubbo 支持的协议很多,我们就简单的分析下 Dubbo 协议。

协议分为协议头和协议体,可以看到 16 字节的头部主要携带了魔法数,也就是之前说的 0xdabb,然后一些请求的设置,消息体的长度等等。
16 字节之后就是协议体了,包括协议版本、接口名字、接口版本、方法名字等等。

约定序列化器
网络是以字节流的形式传输的,相对于我们的对象来说,我们对象是多维的,而字节流是一维的,我们需要把我们的对象压缩成一维的字节流传输到对端。
然后对端再反序列化这些字节流变成对象。
序列化协议
序列化大致分为两大类,一种是字符型,一种是二进制流。
字符型的代表就是 XML、JSON,字符型的优点就是调试方便,它是对人友好的,我们一看就能知道那个字段对应的哪个参数。
缺点就是传输的效率低,有很多冗余的东西,比如 JSON 的括号,对于网络传输来说传输的时间变长,占用的带宽变大。
还有一大类就是二进制流型,这种类型是对机器友好的,它的数据更加的紧凑,所以占用的字节数更小,传输更快。
缺点就是调试很难,肉眼是无法识别的,必须借用特殊的工具转换。
更深层次的就不深入了,序列化还是有很多门道的,以后有机会再谈。
Dubbo 默认用的是 hessian2 序列化协议。
所以实际落地还需要先约定好协议,然后再选择好序列化方式构造完请求之后发送。
调用流程-客户端源码分析
客户端调用一下代码。
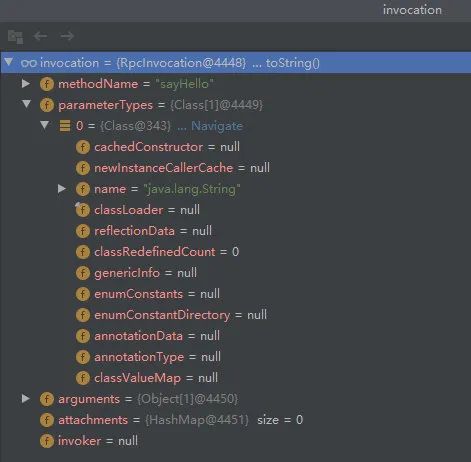
String hello = demoService.sayHello("world");调用具体的接口会调用生成的代理类,而代理类会生成一个 RpcInvocation 对象调用 MockClusterInvoker#invoke方法。
此时生成的 RpcInvocation 如下图所示,包含方法名、参数类和参数值。
我们顺着代码,看下执行过程。
com.alibaba.dubbo.rpc.cluster.support.wrapper.MockClusterInvoker#invoke
@Override
public Result invoke(Invocation invocation) throws RpcException {
Result result = null;
// 获取mock配置
String value = directory.getUrl()
.getMethodParameter(invocation.getMethodName(), Constants.MOCK_KEY, Boolean.FALSE.toString()).trim();
if (value.length() == 0 || value.equalsIgnoreCase("false")) {
//no mock
// 调用AbstractClusterInvoker
result = this.invoker.invoke(invocation);
}
// ..... 省略部分代码
return result;
}我们来看看 this.invoker.invoke 的实现,实际上会调用 AbstractClusterInvoker#invoker 。
路由和负载均衡得到 Invoker
com.alibaba.dubbo.rpc.cluster.support.AbstractClusterInvoker#invoke
@Override
public Result invoke(final Invocation invocation) throws RpcException {
// 检查是否被销毁
checkWhetherDestroyed();
LoadBalance loadbalance = null;
// binding attachments into invocation.
// 看下上下文有没有attachments,有的话绑定到Invocation
Map<String, String> contextAttachments = RpcContext.getContext().getAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addAttachments(contextAttachments);
}
// 调用directory#list,里面做的是路由过滤
List<Invoker<T>> invokers = list(invocation);
if (invokers != null && !invokers.isEmpty()) {
// 通过spi获取loadbalance实现类
loadbalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(
invokers.get(0).getUrl().getMethodParameter(
RpcUtils.getMethodName(invocation), Constants.LOADBALANCE_KEY, Constants.DEFAULT_LOADBALANCE));
}
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
// 最终调用DubboInvoker#doInvoke方法,通过负载均衡策略选择一个Invoker
return doInvoke(invocation, invokers, loadbalance);
}
protected List<Invoker<T>> list(Invocation invocation) throws RpcException {
List<Invoker<T>> invokers = directory.list(invocation);
return invokers;
}@Override
public List<Invoker<T>> list(Invocation invocation) throws RpcException {
if (destroyed) {
throw new RpcException("Directory already destroyed .url: " + getUrl());
}
List<Invoker<T>> invokers = doList(invocation);
List<Router> localRouters = this.routers; // local reference
if (localRouters != null && !localRouters.isEmpty()) {
for (Router router : localRouters) {
try {
if (router.getUrl() == null || router.getUrl().getParameter(Constants.RUNTIME_KEY, false)) {
invokers = router.route(invokers, getConsumerUrl(), invocation);
}
} catch (Throwable t) {
logger.error("Failed to execute router: " + getUrl() + ", cause: " + t.getMessage(), t);
}
}
}
return invokers;
}在代码中就是那个 doInvoke由子类来实现。
那个 list(invocation),其实就是通过方法名找 Invoker,然后服务的路由过滤一波
再进行一波 loadbalance 的挑选,得到一个 Invoker
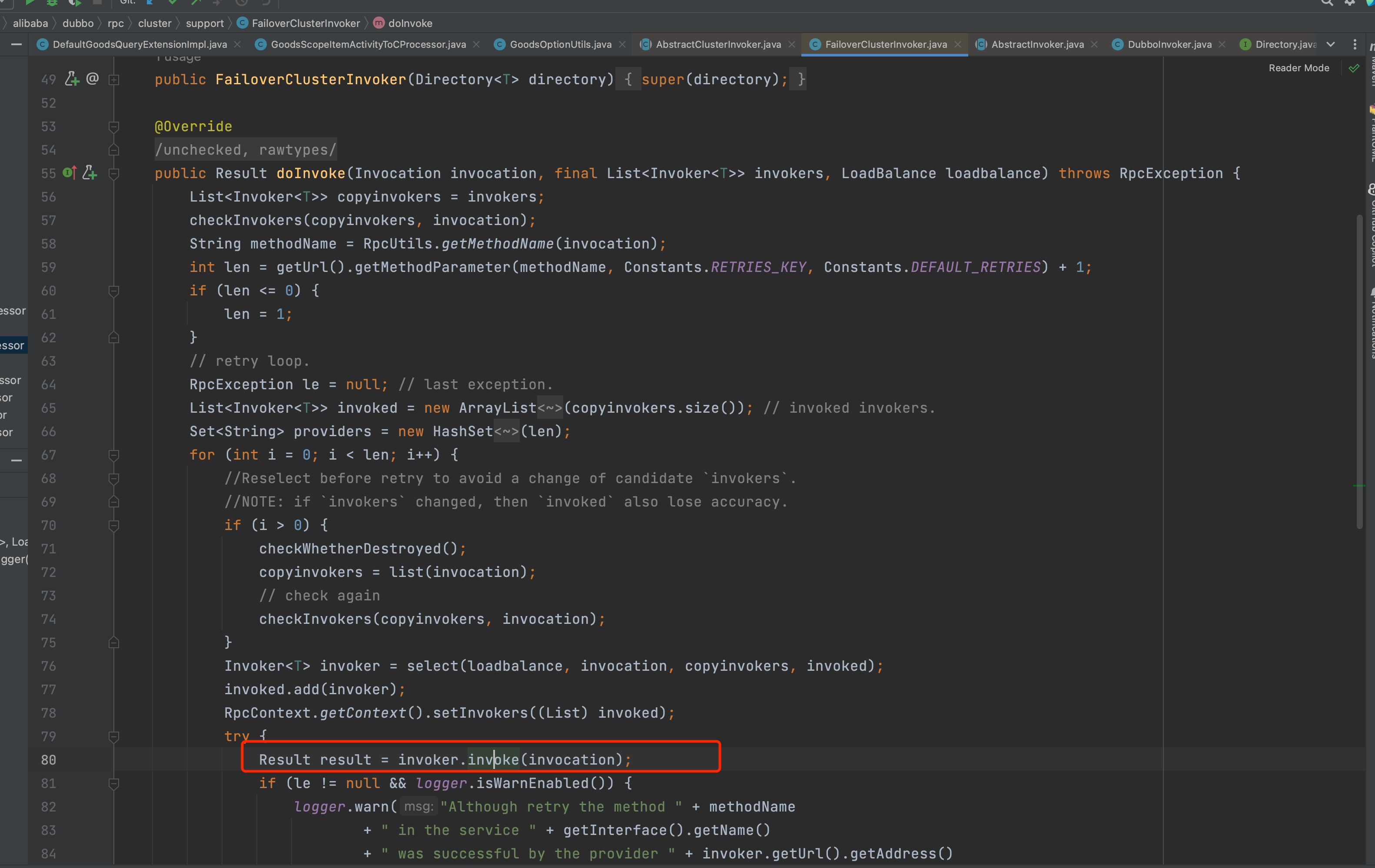
我们默认使用的是 FailoverClusterInvoker,也就是失败自动切换的容错方式
稍微总结一下就是 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表,并且经过路由之后,它会让 LoadBalance 从 Invoker 列表中选择一个 Invoker。
最后FailoverClusterInvoker会将参数传给选择出的那个 Invoker 实例的 invoke 方法,进行真正的远程调用,我们来简单的看下 FailoverClusterInvoker#doInvoke
发起调用的这个 invoke 又是调用抽象类com.alibaba.dubbo.rpc.protocol.AbstractInvoker中的 invoke 然后再调用子类的 doInvoker,直接看子类 DubboInvoker 的 doInvoke 方法
DubboInvoker#doInvoke
com.alibaba.dubbo.rpc.protocol.dubbo.DubboInvoker#doInvoke
@Override
protected Result doInvoke(final Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation) invocation;
final String methodName = RpcUtils.getMethodName(invocation);
// 设置path和version到attachment
inv.setAttachment(Constants.PATH_KEY, getUrl().getPath());
inv.setAttachment(Constants.VERSION_KEY, version);
// 选择一个客户端
ExchangeClient currentClient;
if (clients.length == 1) {
currentClient = clients[0];
} else {
currentClient = clients[index.getAndIncrement() % clients.length];
}
try {
// 异步调用标记
boolean isAsync = RpcUtils.isAsync(getUrl(), invocation);
// oneway发送方式标记
boolean isOneway = RpcUtils.isOneway(getUrl(), invocation);
// 超时时间
int timeout = getUrl().getMethodParameter(methodName, Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
if (isOneway) {
// oneway方式发送,不管发送结果
boolean isSent = getUrl().getMethodParameter(methodName, Constants.SENT_KEY, false);
currentClient.send(inv, isSent);
RpcContext.getContext().setFuture(null);
return new RpcResult();
} else if (isAsync) {
// 异步发送
ResponseFuture future = currentClient.request(inv, timeout);
RpcContext.getContext().setFuture(new FutureAdapter<Object>(future));
return new RpcResult();
} else {
RpcContext.getContext().setFuture(null);
// 同步发送,直接调用future.get()阻塞等待结果
// 异步和同步的区别是,future.get()是用户调用还是组件调用
return (Result) currentClient.request(inv, timeout).get();
}
}
// ... 省略部分代码
}调用的三种方式
oneway还是很常见的,就是当你不关心你的请求是否发送成功的情况下,就用 oneway 的方式发送,这种方式消耗最小,啥都不用记,啥都不用管。
异步调用,其实 Dubbo 天然就是异步的,可以看到 client 发送请求之后会得到一个 ResponseFuture,然后把 future 包装一下塞到上下文中,这样用户就可以从上下文中拿到这个 future,然后用户可以做了一波操作之后再调用 future.get 等待结果。
同步调用,这是我们最常用的,也就是 Dubbo 框架帮助我们异步转同步了,从代码可以看到在 Dubbo 源码中就调用了 future.get,所以给用户的感觉就是我调用了这个接口的方法之后就阻塞住了,必须要等待结果到了之后才能返回,所以就是同步的。
可以看到 Dubbo 本质上就是异步的,为什么有同步就是因为框架帮我们转了一下,而同步和异步的区别其实就是future.get 在用户代码被调用还是在框架代码被调用。
再回到源码中来,currentClient.request 源码如下就是组装 request 然后构造一个 future 然后调用 NettyClient 发送请求。
发送请求
发送请求currentClient.request(inv, timeout)的执行过程是,创建一个请求对象Request,设置版本号和请求内容,构造Future对象并缓存,调用NettyClient发送请求。
com.alibaba.dubbo.remoting.exchange.support.header.HeaderExchangeChannel#request(java.lang.Object, int)
@Override
public ResponseFuture request(Object request, int timeout) throws RemotingException {
// ... 省略部分代码
// create request.
// 创建请求对象,同时生成唯一的请求ID
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setData(request);
// 新建并缓存Future
DefaultFuture future = new DefaultFuture(channel, req, timeout);
try {
// 最终调用NettyChannel#send
channel.send(req);
} catch (RemotingException e) {
future.cancel();
throw e;
}
return future;
}我们再来看一下 DefaultFuture 的内部,你有没有想过一个问题,因为是异步,那么这个 future 保存了之后,等响应回来了如何找到对应的 future 呢?
这就是利用一个唯一 ID。
构建Future
com.alibaba.dubbo.remoting.exchange.support.DefaultFuture#DefaultFuture
public DefaultFuture(Channel channel, Request request, int timeout) {
this.channel = channel;
this.request = request;
// 生成请求id,作为key,用于接收响应结果时从Map中获取到对应的Future和Channel
this.id = request.getId();
this.timeout = timeout > 0 ?
timeout : channel.getUrl().getPositiveParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
// put into waiting map.
FUTURES.put(id, this);
CHANNELS.put(id, channel);
}
// FUTURES和CHANNELS都是一个ConcurrentHashMap
private static final Map<Long, Channel> CHANNELS = new ConcurrentHashMap<Long, Channel>();
private static final Map<Long, DefaultFuture> FUTURES = new ConcurrentHashMap<Long, DefaultFuture>();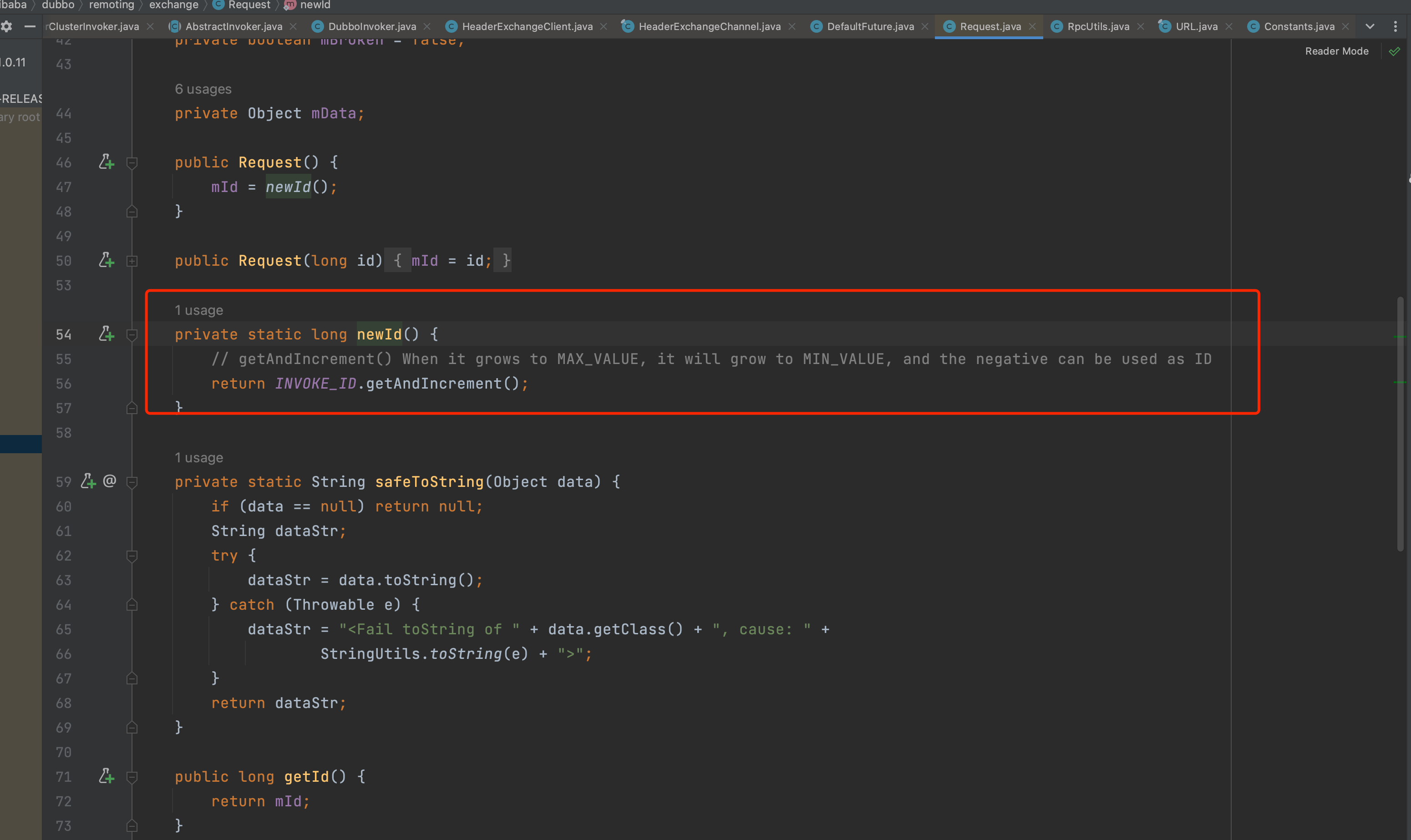
可以看到,当我们创建请求对象时,Request内部会调用AtomicLong#getAndIncrement生成一个全局唯一的ID。当创建DefaultFuture对象时,将请求ID作为key,把Future保存到Map。当接收响应结果时,最终调用的是DefaultFuture#received来接收结果
先看下一个响应的 message 的样子:
Response [id=14, version=null, status=20, event=false, error=null, result=RpcResult [result=Hello world, response from provider: 192.168.1.17:20881, exception=null]]看到这个 ID 了吧,最终会调用 DefaultFuture#received的方法。
接收响应结果
com.alibaba.dubbo.remoting.exchange.support.DefaultFuture#received
public static void received(Channel channel, Response response) {
try {
// 响应返回的id,就是服务端请求时发送的id
// 根据请求id到缓存找到对应的Future
DefaultFuture future = FUTURES.remove(response.getId());
if (future != null) {
future.doReceived(response);
} else {
logger.warn("The timeout response finally returned at "
+ (new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date()))
+ ", response " + response
+ (channel == null ? "" : ", channel: " + channel.getLocalAddress()
+ " -> " + channel.getRemoteAddress()));
}
} finally {
CHANNELS.remove(response.getId());
}
}
private void doReceived(Response res) {
lock.lock();
try {
// 接收响应结果
response = res;
if (done != null) {
// 唤醒请求线程
done.signal();
}
} finally {
lock.unlock();
}
if (callback != null) {
invokeCallback(callback);
}
}客户端接收到响应结果的处理过程:根据响应结果ID,也就是请求ID,到缓存中找到对应的Future对象,调用doReceived方法,保存响应结果,并唤醒对应的请求线程。
调用流程-服务端端源码分析
服务端接收到请求后,会解析得到消息。消息有五种派发策略。
默认是all,也就是所有消息都派发到业务线程池中,我们来看下AllChannelHandler的实现
com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler#received
@Override
public void received(Channel channel, Object message) throws RemotingException {
// 获取线程池
// Executors.newCachedThreadPool(new NamedThreadFactory("DubboSharedHandler", true));
ExecutorService cexecutor = getExecutorService();
try {
// ChannelEventRunnable#run方法,包含多种类型处理
cexecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
}
// ...省略部分代码
}ChannelEventRunnable
ChannelEventRunnable实现Runnable接口,我们看下它的run方法。
com.alibaba.dubbo.remoting.transport.dispatcher.ChannelEventRunnable#run
@Override
public void run() {
if (state == ChannelState.RECEIVED) {
try {
handler.received(channel, message);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel
+ ", message is " + message, e);
}
} else {
switch (state) {
case CONNECTED:
try {
handler.connected(channel);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel, e);
}
break;
case DISCONNECTED:
try {
handler.disconnected(channel);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel, e);
}
break;
case SENT:
try {
handler.sent(channel, message);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel
+ ", message is " + message, e);
}
case CAUGHT:
try {
handler.caught(channel, exception);
} catch (Exception e) {
logger.warn("ChannelEventRunnable handle " + state + " operation error, channel is " + channel
+ ", message is: " + message + ", exception is " + exception, e);
}
break;
default:
logger.warn("unknown state: " + state + ", message is " + message);
}
}
}结合上面的代码,服务端接收到请求后解析成消息,接着获取线程池,把消息封装成ChannelEventHandler,类型是 ChannelState.RECEIVED。当空闲线程处理请求时,执行ChannelEventRunnable#received方法,最终调用HeaderExchangeHandler#handleRequest
HeaderExchangeHandler
com.alibaba.dubbo.remoting.exchange.support.header.HeaderExchangeHandler#handleRequest
Response handleRequest(ExchangeChannel channel, Request req) throws RemotingException {
// 封装一个响应对象,保存请求ID
Response res = new Response(req.getId(), req.getVersion());
// ...省略部分代码
// find handler by message class.
// 获取请求消息,比如方法名称、参数类型、参数值。也就是封装了目标方法信息的RpcInvocation
Object msg = req.getData();
try {
// handle data.
// 最终调用DubboProtocol#reply
Object result = handler.reply(channel, msg);
res.setStatus(Response.OK);
res.setResult(result);
} catch (Throwable e) {
res.setStatus(Response.SERVICE_ERROR);
res.setErrorMessage(StringUtils.toString(e));
}
return res;
}DubboProtocol#reply
这是个关键方法,源码如下
com.alibaba.dubbo.remoting.exchange.support.ExchangeHandlerAdapter#reply
@Override
public Object reply(ExchangeChannel channel, Object message) throws RemotingException {
if (message instanceof Invocation) {
Invocation inv = (Invocation) message;
// 找到Invoker
Invoker<?> invoker = getInvoker(channel, inv);
// ... 省略部分代码
RpcContext.getContext().setRemoteAddress(channel.getRemoteAddress());
// 最终找到真正实现类,调用目标方法
return invoker.invoke(inv);
}
}
Invoker<?> getInvoker(Channel channel, Invocation inv) throws RemotingException {
// ... 省略部分代码
// 构建key,生成规则:group/serviceName:version:port
String serviceKey = serviceKey(port, path, inv.getAttachments().get(Constants.VERSION_KEY),
inv.getAttachments().get(Constants.GROUP_KEY));
// 根据key,从之前暴露服务的Map中找到对应的Exporter
DubboExporter<?> exporter = (DubboExporter<?>) exporterMap.get(serviceKey);
// 返回Exporter封装的Invoker
return exporter.getInvoker();
}关键是serviceKey,在服务暴露时,生成的exporter会保存到exporterMap,它的key也是serviceKey。

总结
dubbo服务调用主要分为两个过程,分别是消费者发送请求和接收响应结果,提供者接收请求。
消费者端:
- 发送请求:服务接口的代理对象执行目标方法,被InvokerInvocationHandler#invoke方法拦截,经过路由过滤、负载均衡后选择一个DubboInvoker对象,调用doInvoke方法。创建一个Request对象,并生成全局唯一的请求ID,接着实例化一个DefaultFuture对象,将请求ID作为key,把DefaultFuture保存到一个ConcurrentHashMap。最后,通过NettyClient把封装了目标方法信息的RpcInvocation序列化后发送出去
- 接收响应:先通过响应ID,即请求ID,在缓存中找到对应的Future,执行doReceived方法。保存结果,接着唤醒对应的请求线程来处理响应结果
提供者端:
NettyServer接收到请求后,根据协议得到信息并反序列化成对象,派发到线程池等待处理。信息会被封转成ChannelEventRunnable对象,类型为RECEIVED。工作线程最终会调用DubboProtocol#reply方法,根据port、path、version、group构建serviceKey,从缓存中找到对应Exporter,经过层层调用,最后会找到真正实现类,执行目标方法返回结果。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)