Redis第12讲——缓存的三种设计模式
缓存的使用在项目中是极其常见的,如果使用得当,缓存可谓时提升系统性能的最简单方法之一,反之则会出现一些莫名其妙的问题,在不同场景下,所使用的缓存策略也是有所变化的,下面我们就介绍一下三种常见的缓存设计模式——Cache Aside Pattern(重点)、Read/Write Through Pattern、Write Behind Caching Pattern。
缓存的使用在项目中是极其常见的,如果使用得当,缓存可谓时提升系统性能的最简单方法之一,反之则会出现一些莫名其妙的问题,在不同场景下,所使用的缓存策略也是有所变化的,下面我们就介绍一下三种常见的缓存设计模式——Cache Aside Pattern(重点)、Read/Write Through Pattern、Write Behind Caching Pattern。
一、Cache Aside Pattern
先看一下我们最经常使用的查询缓存流程:查询请求过来先去读缓存,缓存命中则直接返回,如果未命中就去查数据库,有数据则写入缓存并返回结果,没数据也直接返回,如下图:
这个缓存查询流程大家都不陌生,这应该是使用最为广泛的流程,但大部分人可能不知道,这个流程有一个名字:Cache Aside Pattern(旁路缓存模式),这是缓存设计模式的一种,也是Facebook比较推崇的一种模式,上面是该模式的查询流程,而更新流程如下:

ps:到此为止就是Cache Aside Pattern的全部内容了,由于此模式比较重要,下面我们将对其进行延申。
这个大家应该也并不陌生,更新完数据库后再把缓存给删了,下次再有查询请求过来时,就会先从数据库查询出更新后的数据再写入缓存,乍一看这个流程似乎很“完美”,但还有几个点需要我们思考一下:
- 为什么是先更新数据库再操作缓存,它俩能对调一下吗?
- 为什么是删除缓存而不是更新缓存?
- 读写、写写并发下会有什么问题?
1.1 删除缓存VS更新缓存
为了保证数据库和缓存的一致性,很多人会在做数据更新的时候,顺便会把缓存也一并更新了,虽然这是我们正常的思维,但是我要说的是删除缓存要优于更新缓存。
1.1.1 缓存的数据
我们先抛开并发问题,单从缓存的数据方面看。缓存中的数据大部分情况下可能不只是一个简单的字符串,可能是一个大JSON串。比如我们需要通过缓存进行扣减库存的时候,可能需要从缓存中查出整个订单模型数据,把它反序列化之后,再解析其中库存的字段,修改后再序列化放进缓存中。
可以看到相比于直接删除缓存,更新缓存更为复杂,也较容易出错。下面我们再来看看这两种操作在并发情况下的表现。
1.1.2 写写并发
在"写写并发"下,如果同时更新缓存和数据库,那么就会很容易出现并发问题导致数据不一致的情况。
先写数据库,再更新缓存:

先更新缓存,再写数据库:

可以看到,如果是更新缓存的话,无论是先操作数据库还是先操作缓存,都会出现数据不一致的情况(标红的地方)。但如果是直接删除缓存的话,就不会出现数据不一致的情况。
但它有个小缺点,就是会带来一次额外的cache miss,也就是说删除缓存后的下一次查询无法命中缓存,需要再查一下数据库。
ps:如果同一个key有大量的请求过来,在某种程度上可能会导致缓存击穿,不过可以通过加锁来解决。
所以,删除缓存相较于更新缓存,方案更简单,一致性问题也更少,建议大家优先选择删除缓存。
1.2 先写数据库VS先删缓存
在确定了优先选择删除缓存后,那么先写数据库还是先删缓存呢,下面一起来看看。
1.2.1 先写数据库
在读写并发下:

正常情况下,脏数据时间范围:更新数据库后,删除缓存前。这个时间范围很小,通常不会超过几毫秒。
异常情况下,如果缓存删除失败,会导致数据库中的数据已经更新,而缓存还是旧数据,从而导致数据不一致,但这种情况除非是网络问题或者缓存服务器宕机,否则大部分情况下还是会成功的。
1.2.2 先删除缓存
首先,如果是先删除缓存,那么第二步写数据库失败是可以接收的,因为这样不会有脏数据。
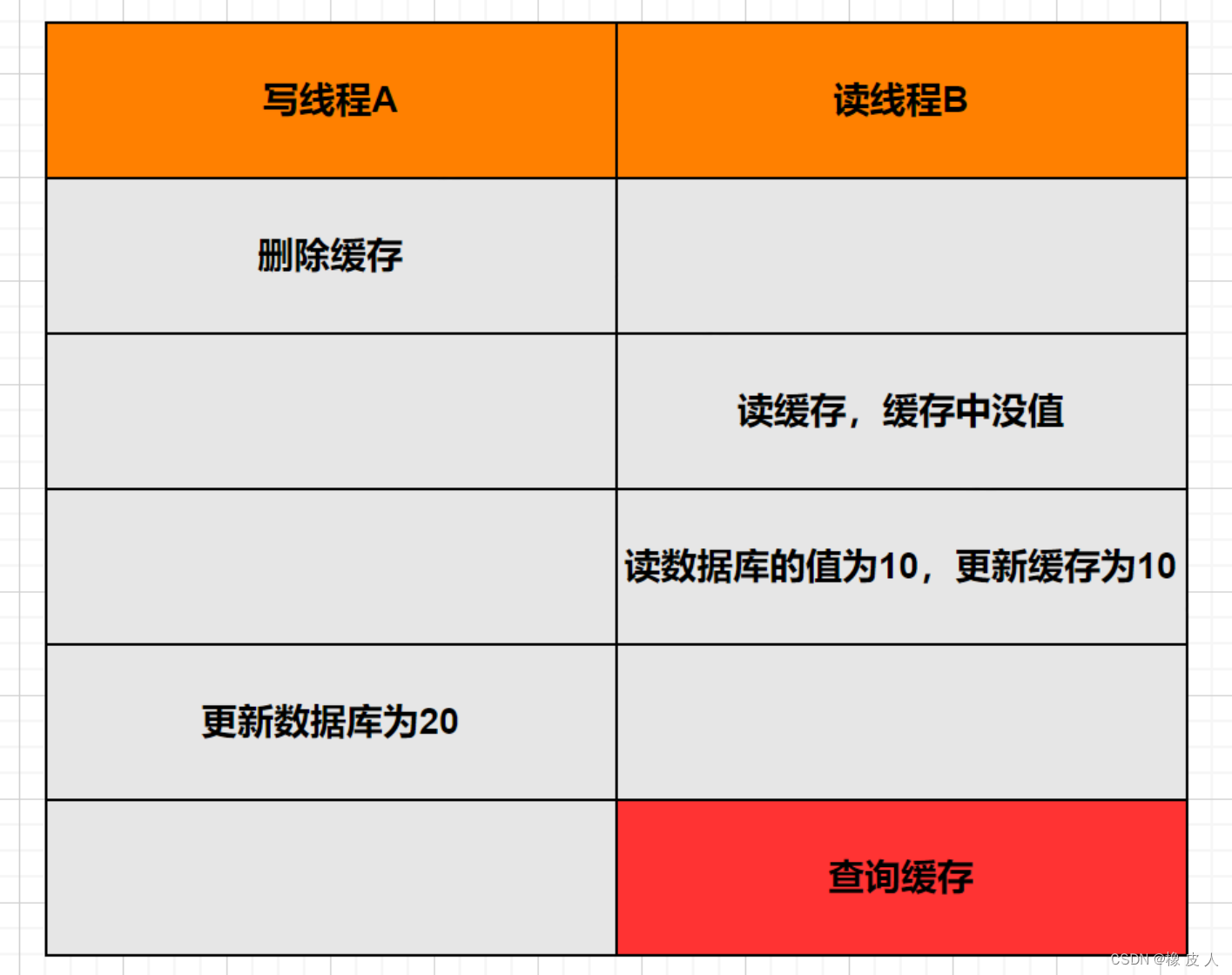
但是,先删除缓存再更新数据库,会放大"读写并发"导致的数据不一致问题。我们知道查询缓存的流程是这样的:
- 查询缓存,命中则直接返回。
- 查询数据库。
- 把数据库的值更新进缓存。
对于一个读线程来说,虽然不会写数据库,但是会写缓存。如下图:

脏数据时间范围:更新数据库后,下一次对该数据更新前。这个时间范围不确定性很大:
- 如果下一次数据更新马上来,那么会失效缓存,脏数据时间就很短。
- 如果下一次数据更新很久才到,那么这期间保存的都是脏数据。
通过上述两个方案的比较可以看出,先操作数据库和先操作缓存都会存在脏数据的情况。但相比之下,先操作数据库再操作缓存时更优的方式,即使再并发的情况下,也只会出现很小量的脏数据。
ps:由于篇幅原因,缓存和数据库一致性的解决方案下篇文章再介绍。
二、Read/Write Through Pattern
在Cache Aside中,应用层需要和缓存和数据库两个数据源打交道,这增加了应用层的复杂度,而Read/Write Through Pattern就是来解决这个问题的,在这两种模式下,应用层只需要将缓存作为主要数据源,不需要感知数据库,更新和读取的任务都交给缓存来代理。
2.1 Read Through Pattern
在Read Though模式下,是由缓存配置一个读模块,应用层查询数据时,当缓存未命中时,由缓存去查询数据库,并且将结果写入缓存中,最后返回结果给应用层:

在上述流程图中,红色框内的操作不再由应用层来处理,而是由缓存自己处理。
2.2 Write Though Pattern
在Write Though模式下,是由缓存配置一个写模块,应用层更新数据时,由缓存去更新数据库。同时,当缓存命中时,写缓存和写数据库这两个操作在一个事务中完成,保证同时成功:

当使用Write Though时,一般都配合使用Read Though来使用。Write Though适用的场景有:
- 需要频繁读取相同数据。
- 不能忍受丢失数据(相对于Write Behind而言)和数据不一致。
在使用Write-Through时要特别注意的是缓存的有效性管理,否则会导致大量的缓存占用内存资源。甚至有效的缓存数据被无效的缓存数据给清除掉。
三、Write Behind Caching Pattern
Write Behind又称为Write Back,从应用层视角来看和Write Through类似,在该模式下,应用层也只需和缓存一个数据源打交道,不同的是Write Through会立即把数据写入数据库,而Write Behind会在一段时间之后(或者被其它方式触发)把数据批量写入数据库,这个异步写操作是Write Behind的最大特点。
这样做的优点是:
- 应用层操作只写缓存,速度非常快。
- 缓存在异步地写数据库时,会将多个I/O操作合并为一个,减少I/O次数。
缺点是:
- 复杂度高。
- 更新后的数据还未写入数据库时,如果此时断电,数据将无法找回。
Write Behind缓存模式由于其复杂度比较高,所以在业务应用中适用的比较少,但是由于其性能比较好,还是有不少优秀的软件采用了该模式,比如:linux中的页缓存、Mysql中的InnoDB存储引擎。
End:希望对大家有所帮助,如果有纰漏或者更好的想法,请您一定不要吝啬你的赐教🙋。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 12
12 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)