VisionTransformer(四)ChangeFormer—— 纯Transformer的变化检测
纯Transformer的变化检测前言一、ChangeFormer提取特征的Transformer Block下采样Downsampling Block提取特征Transformer Block融合位置编码的MLP模块特征图差异计算Difference ModuleMLP Decoder差异特征融合残差块设计总结前言上次介绍过BIT,是一种基于Transformer孪生网络的变化检测结构,但它的设
纯Transformer的变化检测
前言
上次介绍过BIT,是一种基于Transformer孪生网络的变化检测结构,但它的设计思想是利用一个卷积网络提取特征图,将特征图像NLP那样处理成token,在token中集成了两张图片的异同特征,再进入Transformer模块进行后续提取。
所以可以认为BIT是ConvNet+Transformer的架构,而今天要介绍的ChangeFromer就是纯Transformer架构去做变化检测,并且我认为它可理解性可高。
如果对此没有了解,可以看看上篇相关文章:BIT—— 基于孪生网络的变化检测结构分析
一、ChangeFormer
ChangeFormer的论文很简短,设计思想也很简单,可以概括为大力出奇迹,硬train一个孪生网络来做变化检测了。

BIT中,是利用transformer中的编码器结构挖掘两张图片语义特征层面的相差,利用解码器去还原两张图片中异同点的感兴趣点。
但像VIT中,对于图像的处理是没有解码器部分的,所以CangeFormer也只是利用了transformer结果的编码器结果,去提取两张图片的特征。有意思的是,ChangeFormer设计了计算每层解码器输出特征图的偏差Difference Module,最后就是利用每层Difference Module计算出来的结果去经过一个MLP解码器生成差异图。所以我觉得ChangeFormer就是Transformer+FCN的架构。
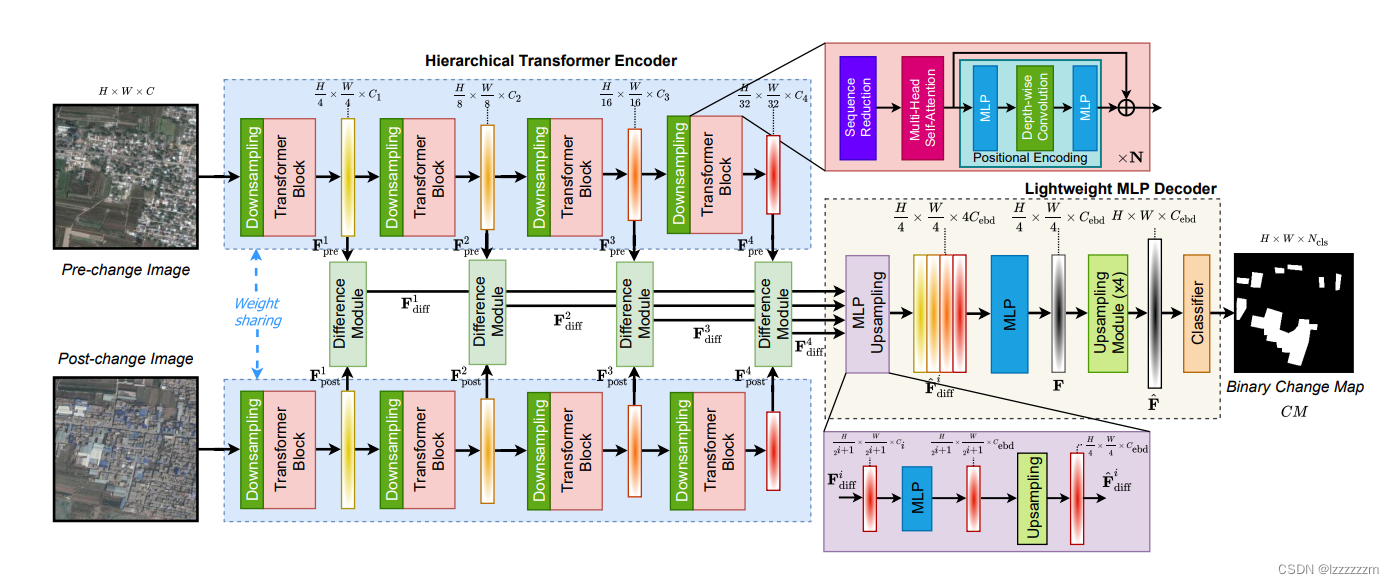
所以接下来,就以三个重要组成部分来分析一下ChangeFormer,分别是提取特征的Transformer Block,计算两张图片差异的Difference Module和根据差异特征生成变化图的MLP Decoder
提取特征的Transformer Block
每个提取特征的Transformer Block又分为三部分,一部分是对特征图下采样,一部分就是经典的自注意力模块还有就是融合了位置编码的MLP模块
下采样Downsampling Block
这里设计的下采样模块,其实应该是借鉴了Swin Transformer的设计思路,就是对于每一层的特征图都进行长宽4倍的下采样,在维度层面翻倍。
除了第一个特征层是用的7x7的,步幅4,Padding为3的卷积层以外,其余层用的都是3x3,步幅为2,padding为1的卷积层进行下采样操作。

提取特征Transformer Block
这里的Transformer模块,其实也和之前介绍过的大差不差,唯一的区别应该是有关多头自注意的实现。使用了类似分组卷积思想的注意力实现,来加速运算。原来的attention可以用下式表示。
而在ChangeFormer中采用的是形式是将Q,K,V 从reshape到
,R为设置的缩放因子来加速计算。再经过一个线性层把维度从CR降维为C,那么原来
的QKV最后变为
的维度。
原来Attention的计算量是,如果经过上述操作后的计算量就变为
。具体为什么能忽略线性层的计算量。是因为其代码实现层面,上述Reshape和线性层的操作,是通过一个卷积完成的。
我们假设R选为8,那么只需要利用一个kernel size为8,步幅为8的卷积,那么QKV就可以达到上面所说的效果啦。
具体结构这里就不画了,因为只是在多头注意力模块中计算QKV前,把输入的Patch经过上面描述的卷积即可。
融合位置编码的MLP模块
在ChangeFormer中的位置编码和VIT中的有所不同,在VIT中,位置编码是相对于一个独立的向量加到Embedding后的向量组中的。而ChangeFormer 则是通过全连接层+深度卷积+全连接层的结构去表示位置编码的。这个好处在于这个位置编码不是固定的,所以可以处理不同分辨率的位置信息。这个地方其实是借鉴了SegFormer里的操作(有空会讲)

所以整个编码器的组成就是由这个Block组成。
特征图差异计算Difference Module
ChangeFormer很直观,如果要分析两张图片的区别是什么,那么我就把两张图片的每层特征图拉出来,做处理,通过集成每层之间的区别,最后根据此去生成变化图。那么我就看看如果设计这个计算差异的模块。
作者设计的计算这个差异的模块,其实就是把每层的两个特征图拼接起来,然后一起经过一系列卷积去进一步提取两个特征图之间的差异。

具体来说,即上图所示。
有一点注意的是,每一层差异模块计算出来的差异,都会再传递到下一层继续计算。
MLP Decoder
在经过上述一系列差异模块计算出来的特征图后,我们就可以依据此差异特征图的信息,去构造变化图了。整个Decoder的设计思想就是依据FCN的思路,主要就两部分,上采样和最后的分类输出(这里分类就是指此像素属不属于变化类)
具体步骤就是将结合不同层次的差异特征图进行特征融合,然后利用转置卷积进行上采样操作,通过一系列残差块保持特征,最后经过一个分类卷积,来生成变化图。
差异特征融合
不同层次的特征进行融合时,作者将不同层次的特价在维度上进行拼接,然后经过一个1x1的卷积进行特征融合(也是很经典的操作)
对于上采样就不多说了,就是一个转置卷积。
残差块设计
作者这里的残差块设计,我个人认为就是一个在上采样的基础上,尽可能想保留信息的操作,因为当特征图经过两层卷积后,我们将其中的值乘以0.1后再和原始特征相加。

然后再相加的操作之后,作者并没有接上RELU的激活层(不太理解)
最后分类头也比较简单,就是一个3x3的卷积,维度降维2.
 至此,整个ChangeFormer的结构就捋清了。
至此,整个ChangeFormer的结构就捋清了。
总结
对于ChangeFormer,个人认为他的优点就是设计思路比较直观,并且利用Transformer不需要卷积网络做为bacbkone提取特征的优点。其中直接去计算每层特征图的差异,然后利用此去做FCN还原变化图,这个思路是比较直观的。
但其中有些地方的设计,我个人是有点不能理解的,有可能这就是大力出奇迹吧。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)