一文读懂「Embedding」嵌入技术
Embedding 是一种将高维数据(如文本或图像)转换为较低维度的向量表示的技术。这种表示捕捉了数据的关键特征,使得在处理、分析和机器学习任务中更加高效。通常用于将离散的、非连续的数据转换为连续的向量表示,以便于计算机进行处理。“Embedding”直译是嵌入式、嵌入层。通俗讲,我们常见的地图就是对于现实地理的Embedding,现实的地理地形的信息其实远远超过三维,但是地图通过颜色和等高线等来
前言:计算机无法直接处理一个单词或者一个汉字,需要把一个token转化成计算机可以识别的向量,这也就是Embedding过程。
一、什么是Embedding?
🚩拓展了解整数编码和独热编码(one-hot)
Embedding 是一种将高维数据(如文本或图像)转换为较低维度的向量表示的技术。这种表示捕捉了数据的关键特征,使得在处理、分析和机器学习任务中更加高效。通常用于将离散的、非连续的数据转换为连续的向量表示,以便于计算机进行处理。
“Embedding”直译是嵌入式、嵌入层。通俗讲,我们常见的地图就是对于现实地理的Embedding,现实的地理地形的信息其实远远超过三维,但是地图通过颜色和等高线等来最大化表现现实的地理信息。
-
Embedding 技术将原始数据从高维度空间映射到低维度空间,有助于减少数据的复杂性和计算资源的需求,并提高模型的训练和推理效率;
-
Embedding 向量是连续的,因此可以在数学上进行操作,如向量加法、减法和点积等。这使得模型能够更好地理解数据之间的关系;
-
Embedding 技术通常会捕获数据的语义信息。在 NLP 中,这意味着相似的单词或短语在嵌入空间中会更接近,而不同的单词或短语会远离彼此。这有助于模型理解语言的含义和语义关系。
-
嵌入向量通常是可训练的,它们可以通过反向传播算法与模型一起训练。这意味着嵌入可以适应特定任务和数据集,从而提高模型的性能;
-
Embedding 技术通常是上下文感知的,它们可以捕获数据点与其周围数据点的关系。在 NLP 中,单词的嵌入会考虑其周围的单词,以更好地表示语法和语义;
-
Embedding 技术通常将高维数据降维到较低维度,但仍然保留了重要的信息。这有助于减少模型的复杂性,并提高模型的泛化能力。
二、原理说明

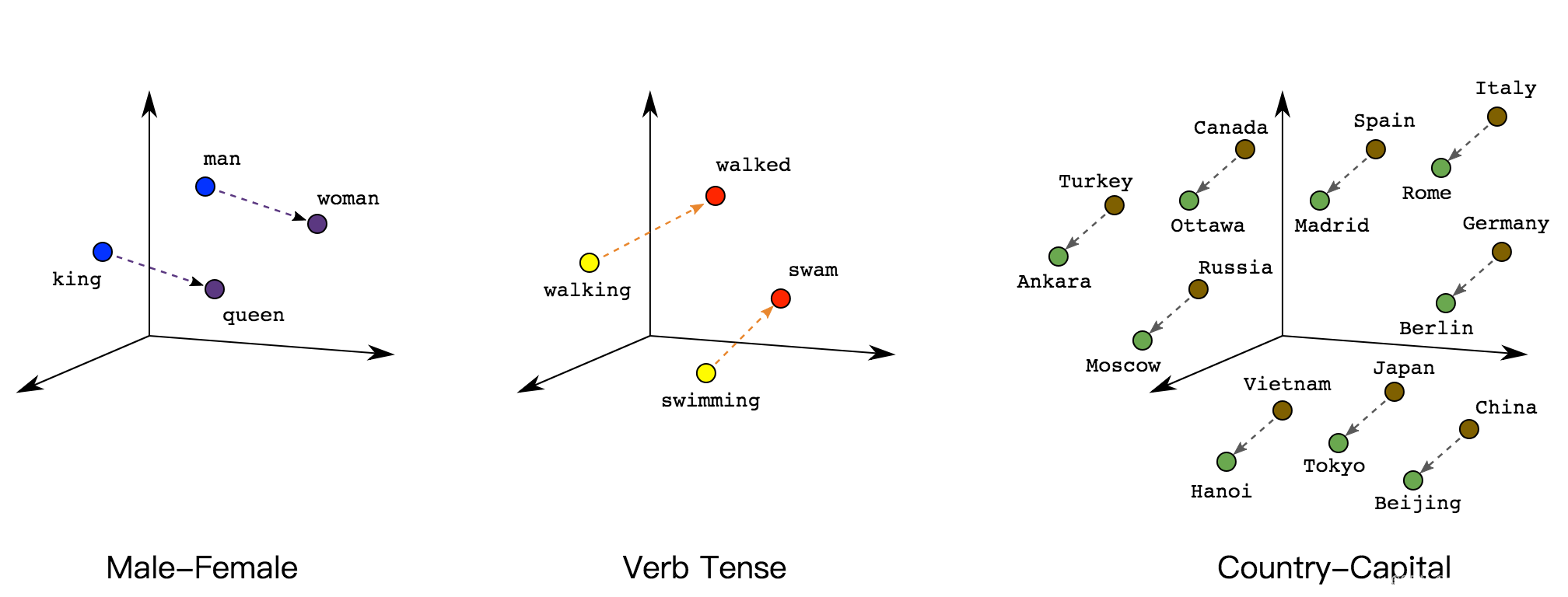
Embedding就是用一个低维稠密的向量表示一个对象(将大型稀疏向量转换为保留语义关系的低维空间)这里的对象可以是一个词(Word2vec),也可以是一个物品(Item2vec),亦或是网络关系中的节点(Graph Embedding)。Embedding向量能够表达对象的某些特征,两个向量之间的距离反映了对象之间的相似性。简单的说,Embedding就是把一个东西映射到一个向量X。如果这个东西很像,那么得到的向量x1和x2的欧式距离很小。
Embedding的本质是信息的聚合和解耦,也就是信息的再表达。如下图所示,前一个是1x4的高维embedding,分别表示猫、狗、花、草四种属性值,后一个是1x2的低维embedding,分别表示动物、植物两种属性值。从高维embedding降维成低维embedding是信息的聚合,猫狗聚合成动物,花草聚合成植物;从低维embedding升维成高维embedding是信息的结构,动物解耦成猫狗,植物解耦成花草。

其他二维embedding聚合的例子,比如CNN对图像进行降采样得到的feature map,是embedding;解耦的例子,GAN生成的图像是embedding。N维同理。
三、分类
- 词嵌入(Word Embeddings):如 Word2Vec、GloVe,将单词转换为向量。
把单词w映射到向量x。如果两个单词的意思相近,比如bike和bicycle,那么它们映射后得到的两个词向量x1和x2的欧式距离很小。
-
句子/文档嵌入(Sentence/Document Embeddings):如 Doc2Vec、BERT,将整个句子或文档转换为单个向量。
-
图嵌入(Graph Embeddings):将图形数据(如社交网络、知识图谱)中的节点、边或整个图转换为向量。
把图中的每个节点映射成一个向量x。如果图中两个节点接近,比如它们的最短路很小,那么它们embed得到的向量x1和x2的欧式距离很小。
- 图像嵌入(Image Embeddings):通过深度学习模型,如卷积神经网络(CNN),将图像转换为向量形式。
四、优缺点
4.1 优点
- 语义信息捕捉:Embedding 技术能够捕捉数据的语义信息,使得相似的数据在嵌入空间中更接近,有助于模型更好地理解数据之间的关系。
- 维度约减:Embedding 技术将高维数据映射到低维空间,减少了计算和内存需求,提高了模型的效率。
- 上下文感知:嵌入向量通常是上下文感知的,可以考虑数据点与其周围数据点的关系,这对于自然语言处理等任务非常有用。
- 可训练:嵌入向量通常是可训练的,可以与模型一起训练,从而适应特定任务和数据集。
- 泛化能力:适当训练的嵌入可以提高模型的泛化能力,从而使其能够处理新数据和未知情况。
4.2 缺点
- 数据依赖性:Embedding 技术的性能高度依赖于训练数据的质量和多样性。如果训练数据不足或不具代表性,嵌入可能不准确。
- 维度选择:选择适当的嵌入维度可以是挑战性的,太低的维度可能丧失信息,太高的维度可能增加计算成本。
- 过拟合:嵌入可以过度拟合训练数据,特别是在小数据集上。这可能导致模型在未见过的数据上表现不佳。
- 计算复杂性:在训练嵌入时,可能需要大量的计算资源和时间,尤其是对于大规模数据集和高维度嵌入。
- 可解释性差:嵌入向量通常是抽象的,难以解释。这使得难以理解模型为什么做出特定的预测或推荐。
总的来说,Embedding 技术为许多深度学习任务提供了有力的工具,但在使用时需要权衡其优点和缺点,并根据具体情况进行调整和改进。
五、应用
Embedding 技术不仅在NLP领域有广泛应用,还在计算机视觉、推荐系统、社交网络分析等多个领域中有用途。
-
自然语言处理:文本分类、情感分析、机器翻译等。
-
推荐系统:通过用户和物品的嵌入来提高推荐的相关性。

-
计算机视觉:图像识别、分类和检索。

-
社交网络分析:社区检测、链接预测等。
-
生物信息学:通过嵌入技术分析基因表达数据和蛋白质结构。
在NLP中,Word Embedding是一种常见的技术,用于将单词映射到连续向量空间。在计算机视觉中,卷积神经网络(CNN)和循环神经网络(RNN)等模型也使用嵌入来处理图像和文本数据。
Embedding 在大语言模型中的主要应用有:
- 作为 Embedding 层嵌入到大语言模型中,实现将高维稀疏特征到低维稠密特征的转换(如 Wide&Deep、DeepFM 等模型);
- 作为预训练的 Embedding 特征向量,与其他特征向量拼接后,一同作为大语言模型输入进行训练(如 FNN)。
- 作为 Embedding 层嵌入到大语言模型中。大语言模型无法直接理解书面文本,需要对模型的输入进行转换。为此,实施了句子嵌入,将文本转换为数字向量。
六、原理补充
强烈建议看一下,解释的非常妙!https://zhuanlan.zhihu.com/p/164502624
七、拓展阅读
https://www.featureform.com/post/the-definitive-guide-to-embeddings

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)