图机器学习——5.5 广义 GNN 框架:消息传递与聚合
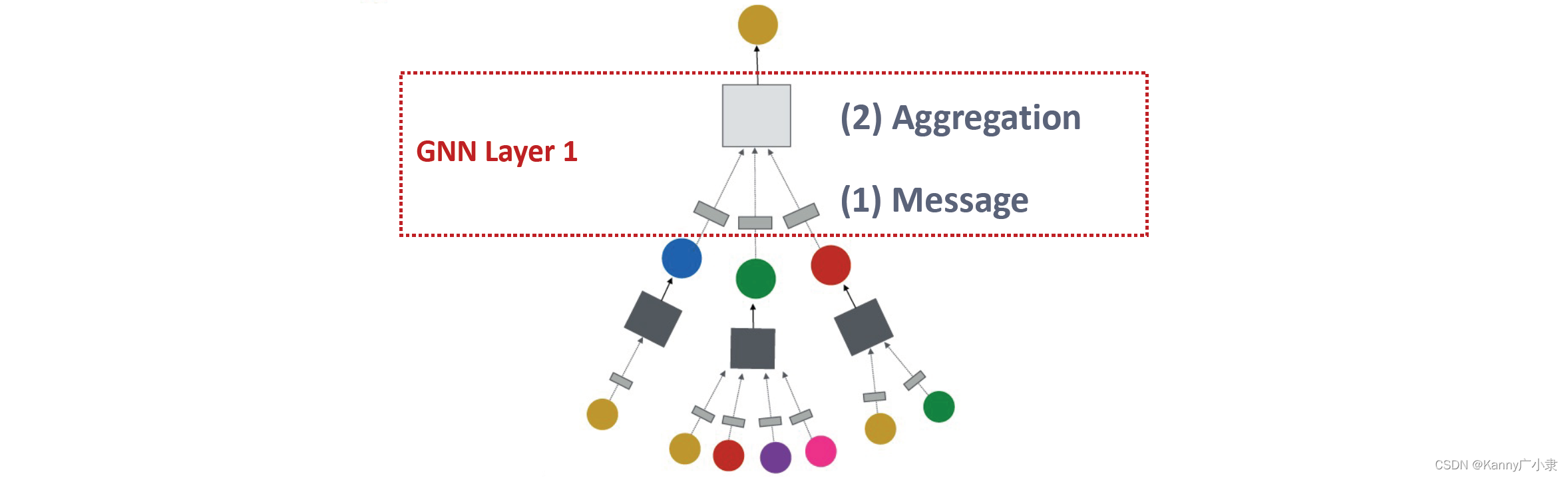
5. 广义视角下的 GNN 框架GNN 层的本质为:消息(Message) + 聚合(Aggregation)。在这一视角下的有许多不同的实例:GCN,GraphSAGE,GAT等,下面我们将着重讲解这三个不同的实例。GNN 的总体框架分别包括:1)消息 与 2)聚合,也就是一个网络层中的操作。3)层与层之间的连接4)图增广(Graph augmentation) 与 5)学习目标(Learnin
5. 广义视角下的 GNN 框架
- GNN 层的本质为:消息(Message) + 聚合(Aggregation)。在这一视角下的有许多不同的实例:GCN,GraphSAGE,GAT等,下面我们将着重讲解这三个不同的实例。
GNN 的总体框架分别包括:1)消息 与 2)聚合,也就是一个网络层中的操作。

3)层与层之间的连接

4)图增广(Graph augmentation) 与 5)学习目标(Learning Object)

下面我们一部分一部分进行分析。
1)消息(Message)

图网络中的message函数可以通过下式进行表示:
m u ( l ) = MSG ( l ) ( h u ( l − 1 ) ) \mathbf{m}_{u}^{(l)}=\operatorname{MSG}^{(l)}\left(\mathbf{h}_{u}^{(l-1)}\right) mu(l)=MSG(l)(hu(l−1))
主要想法是:每个节点将创建一条消息,稍后再发送给其他节点。
最简单的message函数是线性变换:
m u ( l ) = W ( l ) h u ( l − 1 ) \mathbf{m}_{u}^{(l)}=\mathbf{W}^{(l)} \mathbf{h}_{u}^{(l-1)} mu(l)=W(l)hu(l−1)
其通过将节点特征 h u ( l − 1 ) \mathbf{h}_{u}^{(l-1)} hu(l−1) 乘以权重矩阵 W ( l ) \mathbf{W}^{(l)} W(l),得到变换之后的message。
2)聚合(Aggregation)

每个节点,假设当前节点为 v v v都将从其邻居节点 N ( v ) N(v) N(v)中聚合信息
h v ( l ) = A G G ( l ) ( { m u ( l ) , u ∈ N ( v ) } ) \mathbf{h}_{v}^{(l)}=\mathrm{AGG}^{(l)}\left(\left\{\mathbf{m}_{u}^{(l)}, u \in N(v)\right\}\right) hv(l)=AGG(l)({mu(l),u∈N(v)})
聚合函数可以选取:求和 Sum ( ⋅ ) \operatorname{Sum}(\cdot) Sum(⋅), Mean ( ⋅ ) \operatorname{Mean}(\cdot) Mean(⋅) 或 Max ( ⋅ ) \operatorname{Max}(\cdot) Max(⋅) 函数。
但这样直接聚合邻居节点会有一个问题:自身节点本身的信息会被遗失。
因此,在聚合操作时,我们考虑自身信息与邻居信息,首先分别进行一次变换,转为对应的message。

而后再通过拼接(Concatenation)的方式来将自身节点与邻居节点汇总的信息进行聚合。
h v ( l ) = CONCAT ( AGG ( { m u ( l ) , u ∈ N ( v ) } ) , m v ( i ) ) \mathbf{h}_{v}^{(l)}=\operatorname{CONCAT}\left(\operatorname{AGG}\left(\left\{\mathbf{m}_{u}^{(l)}, u \in N(v)\right\}\right), \mathbf{m}_{v}^{(i)}\right) hv(l)=CONCAT(AGG({mu(l),u∈N(v)}),mv(i))
在经过了聚合之后通常需要再进行一次非线性激活层 σ ( ⋅ ) \sigma(\cdot) σ(⋅),通常为: ReLU ( ⋅ ) , Sigmoid ( ⋅ ) , ⋯ \operatorname{ReLU}(\cdot), \operatorname{Sigmoid}(\cdot), \cdots ReLU(⋅),Sigmoid(⋅),⋯
后面以这种广义视角,分别单独介绍三种网络中的信息与聚合结构。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)