
Python量化交易(三):股票数据应用与获取
主要实现对股票等金融产品从数据采集、清洗加工到数据存储的全过程自动化运作,为金融分析人士提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究和实现上。我们可以通过API接口获取不同类型的指数K线数据,包括综合指数(如上证指数、深证综指)、规模指数(如上证50、沪深300)、行业指数(一级行业、二级行业等)、策略指数、成长指数、价值指数、主题

引言
大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列文章是我跟随DataWhale 2024年10月学习赛的Python量化交易学习总结文档。在现代金融市场中,投资已成为个人和机构追求财富增长的重要手段。本文将系统梳理股票投资的基本概念,重点解析技术面和基本面数据,并介绍如何使用Python进行量化分析。
一、股票数据的基本分类
股票数据根据信息来源不同可以分为技术面数据和基本面数据。这两类数据为投资者提供了不同的视角和方法来评估股票的投资价值。
1.技术面数据
技术面数据是通过股票的历史价格和交易量等市场数据进行计算和分析得出的指标。其核心观点是市场行为会在价格上留下痕迹,通过这些痕迹可以预测未来的价格走势。技术面数据主要关注股票价格的变动和市场趋势,常用的技术指标包括移动平均线、相对强弱指标、MACD指标等。
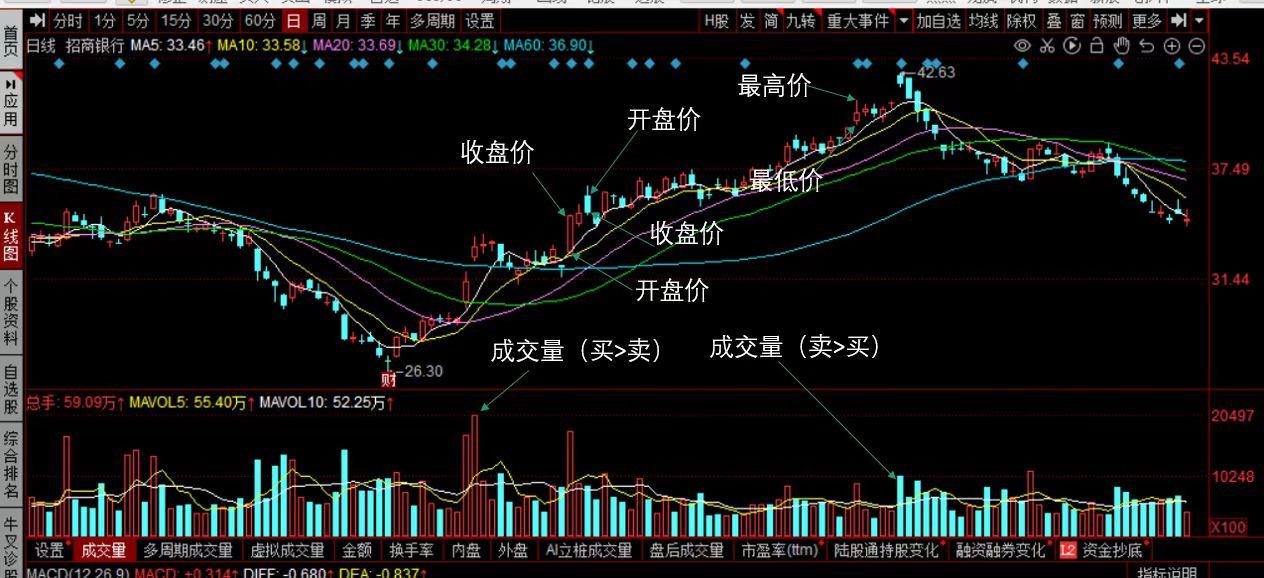
2.基本面数据
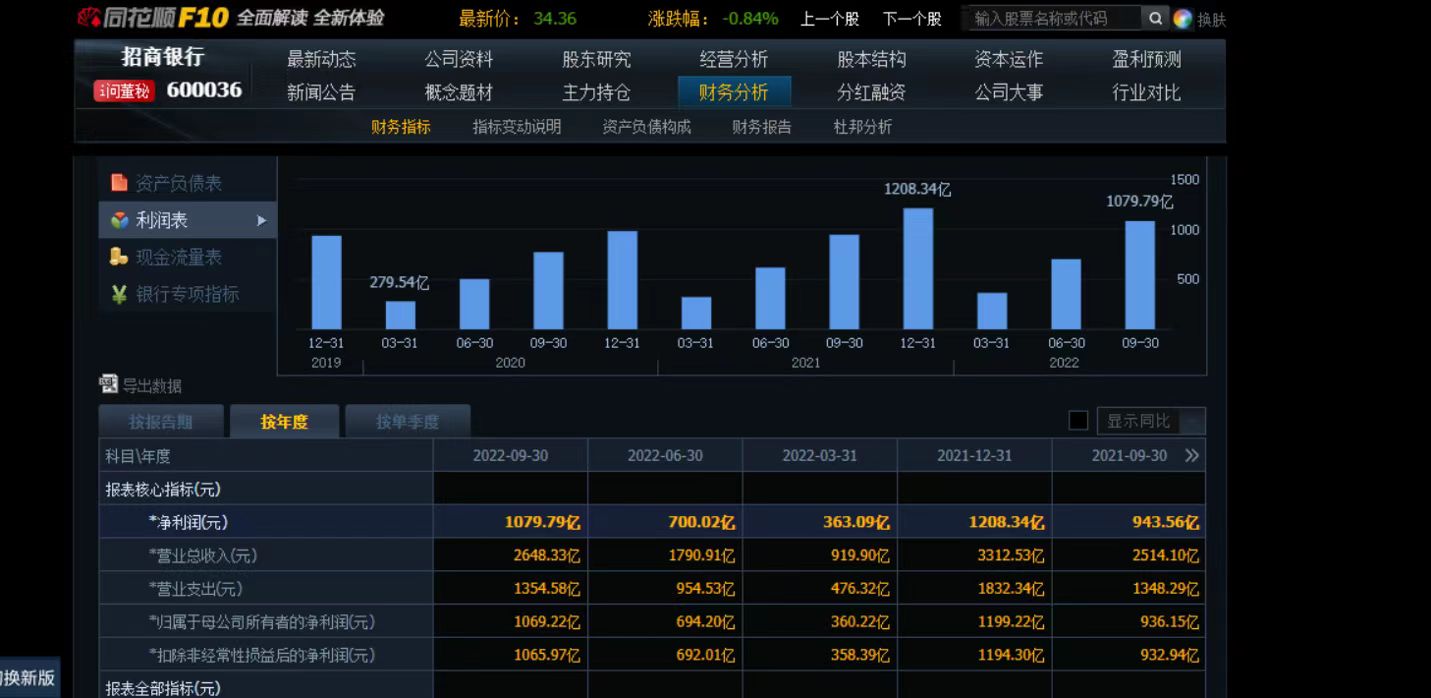
基本面数据是通过分析公司的财务状况、业绩表现、竞争力等基本信息得出的评估。基本面分析认为股票的价格是与公司的基本面因素相关的,包括公司的营业收入、盈利能力、资产负债情况、市场份额等。基本面分析的指标是评估公司的内在价值,并给予这些评估来判断股票的投资潜力。常用的基本面指标包括市盈率、市净率、股息率等。
技术面数据和基本面数据都是股票分析中的工具,它们提供了不同的视角和方法来评估股票的投资价值。投资者可以综合运用这两类数据,从技术面和基本面两个层面进行全面的分析和决策。
二、股票数据的常见指标
我们已知股票数据分为技术面数据和基本面数据,下面将分别阐述这两种数据的常见指标。
1. 技术面数据
① 移动平均线(MA:Moving Average)
移动平均线是通过计算一段时间内的股票平均价格来平滑价格波动。常见的移动平均线有简单移动平均线(SMA)和指数移动平均线(EMA)。
- 简单移动平均线(Simple Moving Average, SMA):通过将一段时间内的股票收盘价相加,然后除以时间段的天数来计算。简单移动平均线可以平滑价格波动,显示出长期趋势。
- 指数移动平均线(Exponential Moving Average, EMA):对近期价格给予更高的权重,反映了市场更近期的变化。计算指数移动平均线时,当前价格会根据选定的时间段和权重系数,与之前的移动平均线值相结合。
应用:
- 确定趋势:投资者可以使用不同期限的移动平均线来确定趋势的强度和方向。
- 交叉信号:移动平均线的交叉可以提供买入或卖出的信号。
- 支撑与阻力线:移动平均线经常被用作支撑和阻力线的参考。
② 相对强弱指数(Relative Strength Index, RSI)
RSI是一种用于衡量股票价格变动强度和速度的技术指标。它可以帮助投资者判断股票市场的超买和超卖情况,以及价格的反转和确认信号。
计算步骤:
- 计算14个交易周期内的涨幅和跌幅的平均值。
- 计算涨幅平均值与跌幅平均值的相对强弱比例(RS)。
- 计算相对强弱指数(RSI)。
数值解读:
- RSI(0-30):表示股票市场被超卖,可能存在价格反弹的机会。
- RSI(70-100):表示股票市场被超买,可能存在价格下跌的机会。
- RSI(30-70):表示股票市场相对平稳,没有明显的超买或超卖信号。
③ 随机指标(Stochastic Oscillator)
随机指标用于判断股票价格的超买和超卖情况,以及价格反转的可能性。它可以帮助投资者确定适合买入或卖出股票的时机。
计算步骤:
- 计算一定时间段内的最高价和最低价。
- 计算当前收盘价与该时间段内最低价的差值,并除以最高价和最低价的差值。
- 计算%K的移动平均值作为%D线的值。
数值解读:
- 当%K线从下方穿越%D线时,被视为买入信号。
- 当%K线从上方穿越%D线时,被视为卖出信号。
- 当%K线位于高位(一般超过80)时,表示市场可能超买。
- 当%K线位于低位(一般低于20)时,表示市场可能超卖。
④ 成交量指标(Volume)
成交量指标衡量了股票交易的活跃程度。当股票价格上涨时,成交量增加可以被视为价格上涨的确认;当股票价格下跌时,成交量增加可能表示价格下跌的确认。
应用:
- 确认趋势:成交量指标可以用来确认价格趋势的有效性。
- 确认突破:成交量指标也可用于确认价格突破的有效性。
- 观察分析:投资者可以通过观察成交量指标的变化,研究市场情绪和买卖压力。
- 交易量模型:有些交易者会使用成交量指标构建交易量模型。
⑤ MACD指标(Moving Average Convergence Divergence)
MACD指标是股票技术分析中常用的趋势追踪和买卖信号指标。它通过比较两条移动平均线的差异,来判断股票价格的趋势以及价格的买卖信号。
组成:
- DIF线(Difference Line):是短期指数移动平均线(如12日 EMA)减去长期指数移动平均线(如26日 EMA)得到的差值线。
- DEA线(Signal Line):是对 DIF 线进行平滑处理,一般使用DIF线的9日移动平均线得到。
- MACD柱(MACD Histogram):是 DIF 线与 DEA 线的差值。
应用:
- 趋势判断:当 DIF 线与 DEA 线发生金叉(DIF 线向上穿过 DEA 线)时,表示价格可能出现上涨趋势。
- 买卖信号:当 MACD 柱由负值转为正值时,被视为买入信号。
- 背离信号:观察价格和 MACD 指标的背离情况。
为了方便记忆,作者将其整理为如下表格:
| 指标名称 | 描述 | 计算方法 | 应用 |
|---|---|---|---|
| 移动平均线(MA) | 通过计算一段时间内的股票平均价格来平滑价格波动。 | - 简单移动平均线(SMA):将一段时间内的股票收盘价相加,然后除以时间段的天数。 - 指数移动平均线(EMA):对近期价格给予更高的权重,当前价格会根据选定的时间段和权重系数,与之前的移动平均线值相结合。 | - 确定趋势:使用不同期限的移动平均线来确定趋势的强度和方向。 - 交叉信号:移动平均线的交叉可以提供买入或卖出的信号。 - 支撑与阻力线:移动平均线经常被用作支撑和阻力线的参考。 |
| 相对强弱指数(RSI) | 用于衡量股票价格变动强度和速度的技术指标。 | 1. 计算14个交易周期内的涨幅和跌幅的平均值。 2. 计算涨幅平均值与跌幅平均值的相对强弱比例(RS)。 3. 计算相对强弱指数(RSI)。 | - RSI(0-30):表示股票市场被超卖,可能存在价格反弹的机会。 - RSI(70-100):表示股票市场被超买,可能存在价格下跌的机会。 - RSI(30-70):表示股票市场相对平稳,没有明显的超买或超卖信号。 |
| 随机指标(Stochastic Oscillator) | 用于判断股票价格的超买和超卖情况,以及价格反转的可能性。 | 1. 计算一定时间段内的最高价和最低价。 2. 计算当前收盘价与该时间段内最低价的差值,并除以最高价和最低价的差值。 3. 计算%K的移动平均值作为%D线的值。 | - 当%K线从下方穿越%D线时,被视为买入信号。 - 当%K线从上方穿越%D线时,被视为卖出信号。 - 当%K线位于高位(一般超过80)时,表示市场可能超买。 - 当%K线位于低位(一般低于20)时,表示市场可能超卖。 |
| 成交量指标(Volume) | 衡量股票交易的活跃程度。 | 即用某一时间周期内的总成交量。 | - 确认趋势:成交量指标可以用来确认价格趋势的有效性。 - 确认突破:成交量指标也可用于确认价格突破的有效性。 - 观察分析:投资者可以通过观察成交量指标的变化,研究市场情绪和买卖压力。 - 交易量模型:有些交易者会使用成交量指标构建交易量模型。 |
| MACD指标(Moving Average Convergence Divergence) | 用于判断股票价格的趋势以及价格的买卖信号。 | 1. DIF线(Difference Line):短期指数移动平均线(如12日 EMA)减去长期指数移动平均线(如26日 EMA)得到的差值线。 2. DEA线(Signal Line):对 DIF 线进行平滑处理,一般使用DIF线的9日移动平均线得到。 3. MACD柱(MACD Histogram):是 DIF 线与 DEA 线的差值。 | - 趋势判断:当 DIF 线与 DEA 线发生金叉(DIF 线向上穿过 DEA 线)时,表示价格可能出现上涨趋势。 - 买卖信号:当 MACD 柱由负值转为正值时,被视为买入信号。 - 背离信号:观察价格和 MACD 指标的背离情况。 |
2. 基本面数据常见指标
① 每股收益(Earnings Per Share, EPS)
每股收益用于衡量公司每股可供股东分配的净利润,即每股盈利能力。每股收益是投资者评估公司盈利能力和估值的重要参考指标之一。
计算公式:EPS = 净利润 / 流通股本
应用:
- 估值比较:每股收益可以作为比较不同公司的盈利能力和估值水平的重要依据。
- 成长趋势:观察每股收益的变化趋势可以了解公司盈利能力的增长速度和稳定性。
- 盈利稳定性:通过比较每股收益的波动程度,可以判断公司的盈利稳定性。
② 市净率(Price-to-Book Ratio, P/B Ratio)
市净率用于衡量股票当前市场价格与公司每股净资产之间关系的指标。它是用来评估公司的市场估值是否低估或高估的重要指标。
计算公式:市净率 = 公司总市值 / 公司净资产
数值解读:
- 市净率低于1:通常表示公司的市场价值低于其净资产,股票可能被低估。
- 市净率约等于1:表示公司的市场价值大致等于其净资产,股票被市场公平估价。
- 市净率高于1:通常表示公司的市场价值高于其净资产,股票可能被高估。
③ 股息收益率(Dividend Yield)
股息收益率用于衡量股票派发的股息相对于股票的价格的比率。股息是公司利润的一部分,以现金或股票形式派发给股东。股息收益率可以帮助投资者评估持有一只股票所能获得的现金回报。
计算公式:股息收益率 = 每股股息 / 股票价格
应用:
- 现金回报:股息收益率可以帮助投资者了解持有股票所能获得的现金回报。
- 盈利比较:通过比较不同公司的股息收益率,投资者可以了解公司的盈利能力和分红政策。
- 市场情绪:股息收益率也可以反映市场对公司的情绪和风险偏好。
④ 净利润(Net Profit)
净利润用于衡量一家公司在特定会计期间内实际获得的净收益,即扣除各项费用和税后利润。净利润是评估公司盈利能力和基本经营状况的重要指标。
计算公式:净利润 = 总收入 - 总成本 - 税收 - 其他费用
应用:
- 盈利能力评估:净利润是评估公司盈利能力的核心指标之一。
- 盈利趋势分析:观察净利润的变化趋势可以了解公司盈利的增长趋势和稳定性。
- 盈利比较:通过比较不同公司的净利润,投资者可以了解公司的盈利水平和业绩相对强弱。
⑤ 负债与资产比率(Debt-to-Asset Ratio)
负债与资产比率用于衡量公司的资本结构和债务风险水平。该比率反映了公司负债占总资产的比例(财务杠杆),可以帮助投资者了解公司负债情况以及对负债承受能力的评估。
计算公式:负债与资产比率 = 总负债 / 总资产
应用:
- 资本结构评估:通过负债与资产比率,投资者可以评估公司的资本结构。
- 债务风险评估:负债与资产比率可以帮助投资者评估公司的债务风险水平。
- 行业比较:通过比较同行业内不同公司的负债与资产比率,投资者可以了解公司在行业内的相对债务水平。
整理表格如下:
| 指标名称 | 描述 | 计算方法 | 应用 |
|---|---|---|---|
| 每股收益(EPS) | 用于衡量公司每股可供股东分配的净利润,即每股盈利能力。 | 计算公式:EPS = 净利润 / 流通股本 | - 估值比较:每股收益可以作为比较不同公司的盈利能力和估值水平的重要依据。 - 成长趋势:观察每股收益的变化趋势可以了解公司盈利能力的增长速度和稳定性。 - 盈利稳定性:通过比较每股收益的波动程度,可以判断公司的盈利稳定性。 |
| 市净率(P/B Ratio) | 用于衡量股票当前市场价格与公司每股净资产之间关系的指标。 | 计算公式:市净率 = 公司总市值 / 公司净资产 | - 市净率低于1:通常表示公司的市场价值低于其净资产,股票可能被低估。 - 市净率约等于1:表示公司的市场价值大致等于其净资产,股票被市场公平估价。 - 市净率高于1:通常表示公司的市场价值高于其净资产,股票可能被高估。 |
| 股息收益率(Dividend Yield) | 用于衡量股票派发的股息相对于股票的价格的比率。 | 计算公式:股息收益率 = 每股股息 / 股票价格 | - 现金回报:股息收益率可以帮助投资者了解持有股票所能获得的现金回报。 - 盈利比较:通过比较不同公司的股息收益率,投资者可以了解公司的盈利能力和分红政策。 - 市场情绪:股息收益率也可以反映市场对公司的情绪和风险偏好。 |
| 净利润(Net Profit) | 用于衡量一家公司在特定会计期间内实际获得的净收益,即扣除各项费用和税后利润。 | 计算公式:净利润 = 总收入 - 总成本 - 税收 - 其他费用 | - 盈利能力评估:净利润是评估公司盈利能力的核心指标之一。 - 盈利趋势分析:观察净利润的变化趋势可以了解公司盈利的增长趋势和稳定性。 - 盈利比较:通过比较不同公司的净利润,投资者可以了解公司的盈利水平和业绩相对强弱。 |
| 负债与资产比率(Debt-to-Asset Ratio) | 用于衡量公司的资本结构和债务风险水平。 | 计算公式:负债与资产比率 = 总负债 / 总资产 | - 资本结构评估:通过负债与资产比率,投资者可以评估公司的资本结构。 - 债务风险评估:负债与资产比率可以帮助投资者评估公司的债务风险水平。 - 行业比较:通过比较同行业内不同公司的负债与资产比率,投资者可以了解公司在行业内的相对债务水平。 |
三、数据获取
1.BaoStock 技术面数据
BaoStock 是一个免费、开源的证券数据平台,无需注册即可获取大量准确、完整的证券历史行情数据和上市公司财务数据。通过 Python API 获取数据信息,满足量化交易投资者、数量金融爱好者、计量经济从业者的数据需求。该工具包返回的数据格式为 pandas DataFrame 类型,方便使用 pandas/NumPy/Matplotlib 进行数据分析和可视化。此外,还支持将数据保存到本地进行分析,提供了更多的灵活性和便利性。
① 历史A股K线数据
历史A股K线数据 是指中国A股市场中股票价格在一段时间内的开盘价、收盘价、最高价和最低价等信息,通常以图表的形式展示。这些数据对于投资者和分析师来说非常重要,因为它们可以通过分析股票价格的变化趋势和波动来预测未来的市场走势,并制定合适的投资策略。此外,历史K线数据还可以用于研究股票的历史表现、估值水平、市场风险等方面,为决策提供参考依据。
query_history_k_data_plus() 方法可以通过API接口获取A股的历史交易数据,你可以根据需要设置参数来获得日线、周线、月线以及5分钟、15分钟、30分钟和60分钟线的数据。这些数据可以结合均线数据进行选股和分析。返回的数据是 pandas 库中 DataFrame 类型的格式。数据范围从1990年12月19日至今,可以查询不复权、前复权或后复权数据。
(1) 日线使用示例
日线是股票、期货等市场中的一种技术分析图表,每个数据点代表一天的交易信息。它记录了该品种在一天内的开盘价、最高价、最低价和收盘价等数据,并通过连续的数据点形成一条曲线,以反映该品种价格的走势。
import baostock as bs
import pandas as pd
from IPython.display import display
#### 登陆系统 ####
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
#### 获取沪深A股历史K线数据 ####
rs = bs.query_history_k_data_plus("sh.600000",
"date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,isST",
start_date='2022-07-01', end_date='2022-12-31',
frequency="d", adjustflag="3")
print('query_history_k_data_plus respond error_code:'+rs.error_code)
print('query_history_k_data_plus respond error_msg:'+rs.error_msg)
#### 打印结果集 ####
data_list = []
while (rs.error_code == '0') & rs.next():
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
#### 结果集输出到csv文件 ####
result.to_csv("./history_A_stock_k_data.csv", index=False)
display(result)
#### 登出系统 ####
bs.logout()

(2)分钟线使用示例
分钟线指的是股票或其他交易品种的价格走势图,每根蜡烛图表示一定时间间隔内的开盘价、收盘价、最高价和最低价。例如,1分钟线表示每根蜡烛图代表1分钟的价格走势。分钟线对于交易者来说具有重要意义,可以帮助他们快速分析市场趋势和价格波动,做出更明智的交易决策。
import baostock as bs
import pandas as pd
from IPython.display import display
#### 登陆系统 ####
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
#### 获取沪深A股历史K线数据 ####
rs = bs.query_history_k_data_plus("sh.600000",
"date,time,code,open,high,low,close,volume,amount,adjustflag",
start_date='2022-07-01', end_date='2022-07-31',
frequency="5", adjustflag="3")
print('query_history_k_data_plus respond error_code:'+rs.error_code)
print('query_history_k_data_plus respond error_msg:'+rs.error_msg)
#### 打印结果集 ####
data_list = []
while (rs.error_code == '0') & rs.next():
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
#### 结果集输出到csv文件 ####
result.to_csv("./history_A_stock_k_data.csv", index=False)
display(result)
#### 登出系统 ####
bs.logout()

② 指数数据
指数数据 是用来表示某个经济或金融市场的整体表现的数字指标,通常由一组代表该市场重要公司股票价格的股票指数构成。指数数据的意义在于让人们更好地了解市场的走势和趋势。它可以显示出市场整体的涨跌情况,帮助投资者评估其投资组合的表现,并作为制定投资决策的参考。此外,指数数据还可以被用来创建各种金融衍生品产品,例如期货和期权等。
我们可以通过API接口获取不同类型的指数K线数据,包括综合指数(如上证指数、深证综指)、规模指数(如上证50、沪深300)、行业指数(一级行业、二级行业等)、策略指数、成长指数、价值指数、主题指数、基金指数和债券指数。每种指数都有其对应的代码,例如上证指数的代码为 sh.000001。
(1) 沪深指数K线数据
沪深指数K线数据是描述中国上海证券交易所和深圳证券交易所股市行情的一种图表表示方法。它通过显示每个交易周期(如日、周或月)的四个价格点:开盘价、最高价、最低价和收盘价,来展示股市的波动情况。
import baostock as bs
import pandas as pd
from IPython.display import display
# 登陆系统
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
# 获取指数K线数据
rs = bs.query_history_k_data_plus("sh.000001",
"date,code,open,high,low,close,preclose,volume,amount,pctChg",
start_date='2022-01-01', end_date='2022-06-30', frequency="d")
print('query_history_k_data_plus respond error_code:'+rs.error_code)
print('query_history_k_data_plus respond error_msg:'+rs.error_msg)
# 打印结果集
data_list = []
while (rs.error_code == '0') & rs.next():
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
# 结果集输出到csv文件
result.to_csv("./history_Index_k_data.csv", index=False)
display(result)
# 登出系统
bs.logout()

(2) 上证50成分股
上证50成分股 指的是上海证券交易所(Shanghai Stock Exchange)挑选出来的50家规模最大、流动性最好的公司,这些公司在中国A股市场中具有较高的影响力和代表性。上证50指数是由这些50家公司的股票组成的指数。这个指数通常被视为中国股市的核心指标之一,因为它覆盖了50家规模大、具有代表性的公司,在市场风险和涨跌幅方面具有重要的参考意义。
import baostock as bs
import pandas as pd
from IPython.display import display
# 登陆系统
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
# 获取上证50成分股
rs = bs.query_sz50_stocks()
print('query_sz50 error_code:'+rs.error_code)
print('query_sz50 error_msg:'+rs.error_msg)
# 打印结果集
sz50_stocks = []
while (rs.error_code == '0') & rs.next():
sz50_stocks.append(rs.get_row_data())
result = pd.DataFrame(sz50_stocks, columns=rs.fields)
# 结果集输出到csv文件
result.to_csv("D:/sz50_stocks.csv", encoding="gbk", index=False)
display(result)
# 登出系统
bs.logout()

2.BaoStock 基本面数据
BaoStock 除了可以获取技术面数据,还可以获取基本面数据。BaoStock 可以获取的基本面数据主要有季频盈利能力、季频营运能力、季频成长能力、季频偿债能力等。
① 季频盈利能力
季频盈利能力是指公司在每个季度内所实现的盈利水平和能力。这通常涉及到一些财务指标和比率,例如每股收益(EPS)、净利润率、毛利润率等等。
import baostock as bs
import pandas as pd
from IPython.display import display
# 登录 BaoStock 系统
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
# 获取600036招商银行季频盈利能力数据
profit_list = []
rs_profit = bs.query_profit_data(code="sh.600036", year=2022, quarter=4)
while (rs_profit.error_code == '0') & rs_profit.next():
profit_list.append(rs_profit.get_row_data())
# 转换为DataFrame格式
df_profit = pd.DataFrame(profit_list, columns=rs_profit.fields)
# 打印结果
display(df_profit)
# 将结果集输出到csv文件
df_profit.to_csv("D:\\profit_data.csv", encoding="gbk", index=False)
# 退出 BaoStock 系统
bs.logout()

② 季频营运能力
季频营运能力是指公司在每个季度内所实现的营运能力和效率。这通常涉及到一些财务指标和比率,例如存货周转率、应收账款周转率、总资产周转率等等。
import baostock as bs
import pandas as pd
from IPython.display import display
# 登录 BaoStock 系统
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
# 获取600036招商银行季频营运能力数据
operation_list = []
rs_operation = bs.query_operation_data(code="sh.600036", year=2022, quarter=4)
while (rs_operation.error_code == '0') & rs_operation.next():
operation_list.append(rs_operation.get_row_data())
# 转换为DataFrame格式
df_operation = pd.DataFrame(operation_list, columns=rs_operation.fields)
# 打印输出
display(df_operation)
# 将结果集输出到csv文件
df_operation.to_csv("D:\\operation_data.csv", encoding="gbk", index=False)
# 退出 BaoStock 系统
bs.logout()

③ 季频成长能力
季频成长能力是指公司在每个季度内所实现的成长水平和能力。这通常涉及到一些财务指标和比率,例如营收增长率、净利润增长率、每股收益增长率等等。
import baostock as bs
import pandas as pd
from IPython.display import display
# 登录 BaoStock 系统
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
# 获取600036招商银行季频成长能力数据
growth_list = []
rs_growth = bs.query_growth_data(code="sh.600036", year=2022, quarter=4)
while (rs_growth.error_code == '0') & rs_growth.next():
growth_list.append(rs_growth.get_row_data())
# 转换为DataFrame格式
df_growth = pd.DataFrame(growth_list, columns=rs_growth.fields)
# 打印输出
display(df_growth)
# 将结果集输出到csv文件
df_growth.to_csv("D:\\growth_data.csv", encoding="gbk", index=False)
# 退出 BaoStock 系统
bs.logout()

④ 季频偿债能力
季频偿债能力是指公司在每个季度内所实现的偿债能力和风险。这通常涉及到一些财务指标和比率,例如资产负债比率、流动比率、速动比率、利息保障倍数等等。
import baostock as bs
import pandas as pd
from IPython.display import display
# 登录 BaoStock 系统
lg = bs.login()
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
# 获取600036招商银行季频偿债能力数据
balance_list = []
rs_balance = bs.query_balance_data(code="sh.600036", year=2022, quarter=4)
while (rs_balance.error_code == '0') & rs_balance.next():
balance_list.append(rs_balance.get_row_data())
# 转换为DataFrame格式
df_balance = pd.DataFrame(balance_list, columns=rs_balance.fields)
# 打印输出
display(df_balance)
# 将结果集输出到csv文件
df_balance.to_csv("D:\\balance_data.csv", encoding="gbk", index=False)
# 退出 BaoStock 系统
bs.logout()

3.API整理
这里为了方便查看,作者将以上API整理为表格:
① 历史A股K线数据
| 方法名 | 参数 | 说明 |
|---|---|---|
query_history_k_data_plus | code | 股票代码,格式为 sh.600000 |
fields | 返回数据字段,如 date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,isST | |
start_date | 起始日期,格式为 YYYY-MM-DD | |
end_date | 结束日期,格式为 YYYY-MM-DD | |
frequency | 数据频率,如 d(日线)、5(5分钟线)等 | |
adjustflag | 复权类型,如 3(不复权)、1(后复权)、2(前复权) |
② 指数数据
| 方法名 | 参数 | 说明 |
|---|---|---|
query_history_k_data_plus | code | 指数代码,格式为 sh.000001 |
fields | 返回数据字段,如 date,code,open,high,low,close,preclose,volume,amount,pctChg | |
start_date | 起始日期,格式为 YYYY-MM-DD | |
end_date | 结束日期,格式为 YYYY-MM-DD | |
frequency | 数据频率,如 d(日线) |
③ 上证50成分股
| 方法名 | 参数 | 说明 |
|---|---|---|
query_sz50_stocks | 无 | 获取上证50成分股信息 |
④ 季频盈利能力
| 方法名 | 参数 | 说明 |
|---|---|---|
query_profit_data | code | 股票代码,格式为 sh.600036 |
year | 统计年份,格式为 YYYY | |
quarter | 统计季度,格式为 1、2、3、4 |
⑤ 季频营运能力
| 方法名 | 参数 | 说明 |
|---|---|---|
query_operation_data | code | 股票代码,格式为 sh.600036 |
year | 统计年份,格式为 YYYY | |
quarter | 统计季度,格式为 1、2、3、4 |
⑥ 季频成长能力
| 方法名 | 参数 | 说明 |
|---|---|---|
query_growth_data | code | 股票代码,格式为 sh.600036 |
year | 统计年份,格式为 YYYY | |
quarter | 统计季度,格式为 1、2、3、4 |
⑦ 季频偿债能力
| 方法名 | 参数 | 说明 |
|---|---|---|
query_balance_data | code | 股票代码,格式为 sh.600036 |
year | 统计年份,格式为 YYYY | |
quarter | 统计季度,格式为 1、2、3、4 |
四、Pandas常见指标的数据清洗
1. 既然有Excel,为什么还要Pandas?
虽然Excel是一个强大的数据处理工具,但在处理大规模数据时,Pandas具有以下优势:
- 可读性:Pandas代码更具可读性,便于维护和分享。
- 同步问题:Pandas可以轻松处理多线程和分布式数据,避免Excel的同步问题。
- 性能问题:Pandas在处理大规模数据时性能更优,Excel可能会出现卡顿或崩溃。
- 开发问题:Pandas支持自动化和脚本化处理,适合开发和生产环境。
2. Pandas的Series, Indexes和DataFrames
① Series
| 方法 | 代码 | 作用 |
|---|---|---|
| 创建 Series 对象 | ser = pd.Series(data=prices, index=dates) | 创建一个包含价格数据和对应日期索引的 Series 对象 |
| 选择元素 | prcs = ser['2020-01-06':'2020-01-10'] | 使用切片操作选择特定日期范围内的数据 |
| 访问数据数组 | ary = ser.array | 获取 Series 对象的底层数据数组 |
| 访问索引 | the_index = ser.index | 获取 Series 对象的索引 |
| 使用标签选择 | x = ser.loc['2020-01-10'] | 使用标签进行选择,返回单个值 |
| 使用位置索引选择 | x = ser.iloc[0] | 使用位置索引进行选择,返回单个值 |
| 使用方括号选择 | x = ser[0] | 使用方括号进行索引,选择单个元素 |
| 使用布尔值选择 | cond = df.loc[:, 'action'] == 'up'res = df.loc[cond] | 使用布尔值选择满足特定条件的行 |
# 创建 Series 对象
ser = pd.Series(data=prices, index=dates)
print("创建的 Series 对象:", ser) # 创建一个包含价格数据和对应日期索引的 Series 对象
# 选择元素
prcs = ser['2020-01-06':'2020-01-10']
print("选择的日期范围内的数据:", prcs) # 使用切片操作选择特定日期范围内的数据
# 访问数据数组
ary = ser.array
print("Series 对象的底层数据数组:", ary) # 获取 Series 对象的底层数据数组
# 访问索引
the_index = ser.index
print("Series 对象的索引:", the_index) # 获取 Series 对象的索引
# 使用标签选择
x = ser.loc['2020-01-10']
print("使用标签选择的值:", x) # 使用标签进行选择,返回单个值
# 使用位置索引选择
x = ser.iloc[0]
print("使用位置索引选择的值:", x) # 使用位置索引进行选择,返回单个值
# 使用方括号选择
x = ser[0]
print("使用方括号选择的值:", x) # 使用方括号进行索引,选择单个元素
# 使用布尔值选择
cond = df.loc[:, 'action'] == 'up'
res = df.loc[cond]
print("使用布尔值选择的行:", res) # 使用布尔值选择满足特定条件的行
② Indexes
| 方法 | 代码 | 作用 |
|---|---|---|
| 检查排序 | print(new_ser.is_monotonic_increasing) | 检查 Series 是否已排序 |
| 排序 Series | sorted_ser = new_ser.sort_index() | 对未排序的 Series 进行排序 |
| 格式化日期时间 | s = date.strftime('%Y-%m-%d') | 将日期时间对象格式化为字符串 |
# 检查排序
new_ser = pd.Series(data=[1,3,2], index=['a', 'c', 'b'])
print("Series 是否已排序:", new_ser.is_monotonic_increasing) # 检查 Series 是否已排序
# 排序 Series
sorted_ser = new_ser.sort_index()
print("排序后的 Series:", sorted_ser) # 对未排序的 Series 进行排序
# 格式化日期时间
date = dt.datetime(year=2020, month=12, day=31, hour=0)
s = date.strftime('%Y-%m-%d')
print("格式化后的日期时间:", s) # 将日期时间对象格式化为字符串
③ DataFrames
| 方法 | 代码 | 作用 |
|---|---|---|
| 创建 DataFrame 对象 | df = pd.DataFrame({'Close': prc_ser, 'Bday': bday_ser}) | 创建一个包含收盘价和交易日列的 DataFrame 对象 |
| 从 CSV 文件读取数据 | qan_naive_read = pd.read_csv(QAN_PRC_CSV) | 从 CSV 文件中读取数据 |
| 设置索引 | qan_naive_read.set_index('Date', inplace=True) | 设置 DataFrame 的索引 |
| 保存到 CSV 文件 | ser_no_name.to_csv(QAN_CLOSE_CSV, header=False) | 将数据保存到 CSV 文件中 |
| 读取 CSV 文件 | as_df = pd.read_csv(QAN_CLOSE_CSV, header=None, index_col=0) | 从 CSV 文件中读取数据 |
| 选择特定年份数据 | print(prc.loc['2020']) | 选择特定年份的数据 |
| 选择特定月份数据 | print(prc.loc['2020-01']) | 选择特定月份的数据 |
| 选择日期范围数据 | print(prc.loc['2020-01-01':'2020-01-05']) | 选择特定日期范围内的数据 |
| 计算回报 | rets = prc.loc[:, 'Close'].pct_change() | 计算股票的回报 |
| 组合 DataFrame 对象 | print(df + df2) | 对 DataFrame 进行加法运算 |
| 使用布尔值选择行 | `crit = (df.loc[:, ‘action’] == ‘up’) | (df.loc[:, ‘action’] == ‘down’)<br>print(df.loc[crit])` |
# 创建 DataFrame 对象
prc_ser = pd.Series(data=prices, index=dates)
bday_ser = pd.Series(data=bday, index=dates)
df = pd.DataFrame({'Close': prc_ser, 'Bday': bday_ser})
print("创建的 DataFrame 对象:", df) # 创建一个包含收盘价和交易日列的 DataFrame 对象
# 从 CSV 文件读取数据
qan_naive_read = pd.read_csv(QAN_PRC_CSV)
print("从 CSV 文件读取的数据:", qan_naive_read) # 从 CSV 文件中读取数据
# 设置索引
qan_naive_read.set_index('Date', inplace=True)
print("设置索引后的 DataFrame:", qan_naive_read) # 设置 DataFrame 的索引
# 保存到 CSV 文件
ser_no_name.to_csv(QAN_CLOSE_CSV, header=False)
print("保存到 CSV 文件的数据") # 将数据保存到 CSV 文件中
# 读取 CSV 文件
as_df = pd.read_csv(QAN_CLOSE_CSV, header=None, index_col=0)
print("从 CSV 文件读取的数据:", as_df) # 从 CSV 文件中读取数据
# 选择特定年份数据
print("2020 年的数据:", prc.loc['2020']) # 选择特定年份的数据
# 选择特定月份数据
print("2020 年 1 月的数据:", prc.loc['2020-01']) # 选择特定月份的数据
# 选择日期范围数据
print("2020 年 1 月 1 日至 2020 年 1 月 5 日的数据:", prc.loc['2020-01-01':'2020-01-05']) # 选择特定日期范围内的数据
# 计算回报
rets = prc.loc[:, 'Close'].pct_change()
print("计算的回报:", rets) # 计算股票的回报
# 组合 DataFrame 对象
df2 = df.iloc[1:3, [1]]
print("组合后的 DataFrame:", df + df2) # 对 DataFrame 进行加法运算
# 使用布尔值选择行
crit = (df.loc[:, 'action'] == 'up') | (df.loc[:, 'action'] == 'down')
print("使用布尔值选择的行:", df.loc[crit]) # 使用布尔值选择满足特定条件的行
五、其他数据获取平台
除了证券宝,还有许多其他数据获取平台可以帮助投资者获取股票数据,如:
- Wind金融终端:提供全面的金融市场数据和分析工具。
- 同花顺:提供实时股票行情和财经新闻。
- 东方财富网:提供丰富的财经数据和投资分析工具。
其中,TuShare 是一个免费、开源的 Python 财经数据接口包。主要实现对股票等金融产品从数据采集、清洗加工到数据存储的全过程自动化运作,为金融分析人士提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究和实现上。这里我们整理看一下案例代码:
# 安装 TuShare 库
# 如果你还没有安装 TuShare,可以使用以下命令进行安装
# pip install tushare
# 导入 TuShare 库
import tushare as ts
# 设置你的 token
# 你需要在 TuShare 官网注册并获取一个 token
ts.set_token('your_token')
# 选择你感兴趣的股票代码
stock_code = '603019'
# 获取历史交易数据
# 使用 get_hist_data 函数获取股票的历史交易数据
df = ts.get_hist_data(stock_code)
# 打印获取到的历史交易数据
print("获取到的历史交易数据:")
print(df)
# 计算 5 天和 20 天的移动平均线
# 使用 rolling 方法计算移动平均线
df['MA5'] = df['close'].rolling(window=5).mean() # 计算 5 天移动平均线
df['MA20'] = df['close'].rolling(window=20).mean() # 计算 20 天移动平均线
# 找到 5 天移动平均线从下方穿越 20 天移动平均线的点
# 使用 shift 方法比较前一天的移动平均线
buy_signals = (df['MA5'] > df['MA20']) & (df['MA5'].shift(1) < df['MA20'].shift(1))
# 如果存在买入信号,打印买入
if buy_signals.any():
print(f"Buy signal for {stock_code} on dates {buy_signals[buy_signals == True].index}")
else:
print(f"No buy signal for {stock_code} in the given period.")
作者测试时存在网络问题,遂放弃;💣
最后,投资需谨慎,本文仅供作者学习使用,切勿作为实践案例进行使用;若造成损失,作者可不负责哦!🙂
相关链接
- 项目地址:AlgoQuant-CookBook
- 相关文档:专栏地址
- 作者主页:GISer Liu-CSDN博客

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 22
22 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)