小白学NLP:Sentence Transformers教程
Sentence Transformers(简称SBERT)是一个Python模块,用于访问、使用和训练最先进的文本和图像嵌入模型。**它可以用来通过Sentence Transformer模型计算嵌入向量,或者使用Cross-Encoder模型计算相似度分数。**本相似度和意译挖掘等。
Sentence Transformers(简称SBERT)是一个Python模块,用于访问、使用和训练最先进的文本和图像嵌入模型。**它可以用来通过Sentence Transformer模型计算嵌入向量,或者使用Cross-Encoder模型计算相似度分数。**本相似度和意译挖掘等。
Sentence Transformers提供了超过5,000个预训练的Sentence Transformer模型,这些模型可以在🤗 Hugging Face上立即使用,包括许多来自大规模文本嵌入基准(MTEB)排行榜的最先进的模型。
安装方法
pip install -U sentence-transformers
unsetunset使用案例unsetunset
语义编码
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# model = SentenceTransformer("all-MiniLM-L6-v2", device='cuda')
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
语义相似度计算
from sentence_transformers import SentenceTransformer, SimilarityFunction
# Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# Embed some sentences
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
embeddings = model.encode(sentences)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
# Change the similarity function to Manhattan distance
model.similarity_fn_name = SimilarityFunction.MANHATTAN
print(model.similarity_fn_name)
# => "manhattan"
similarities = model.similarity(embeddings, embeddings)
print(similarities)
语义搜索
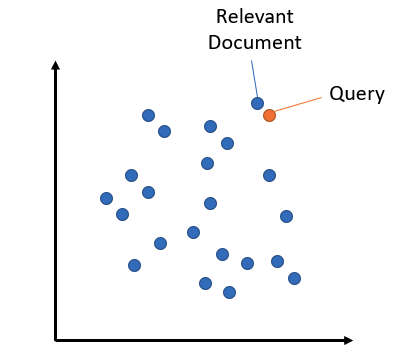
语义搜索旨在通过理解搜索查询和要搜索的语料库的语义含义来提高搜索准确性。与传统仅基于词汇匹配的关键词搜索引擎不同,语义搜索能够很好地处理同义词、缩写词和拼写错误。
-
对于对称语义搜索,你的查询和语料库中的条目长度大致相同,内容量也相似。
-
对于非对称语义搜索,你通常有一个简短的查询(如一个问题或一些关键词),你希望找到一个更长的段落来回答查询。
import torch
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Corpus with example sentences
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"A cheetah is running behind its prey.",
]
# Use "convert_to_tensor=True" to keep the tensors on GPU (if available)
corpus_embeddings = embedder.encode(corpus, convert_to_tensor=True)
# Query sentences:
queries = [
"A man is eating pasta.",
"Someone in a gorilla costume is playing a set of drums.",
"A cheetah chases prey on across a field.",
]
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(5, len(corpus))
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
similarity_scores = embedder.similarity(query_embedding, corpus_embeddings)[0]
scores, indices = torch.topk(similarity_scores, k=top_k)
print("\nQuery:", query)
print("Top 5 most similar sentences in corpus:")
for score, idx in zip(scores, indices):
print(corpus[idx], "(Score: {:.4f})".format(score))
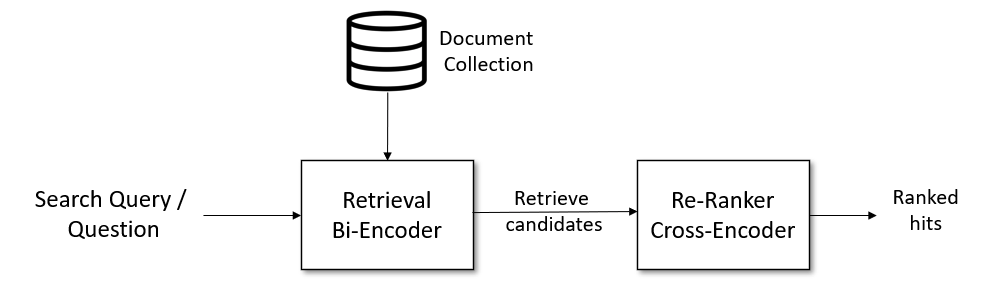
检索与重排序
检索与重排(Retrieve & Re-Rank)是一种信息检索和问答系统中常用的技术。这种方法首先使用检索系统(检索器)来获取一个可能与查询相关的大型候选列表,例如100个可能的命中项。
-
在检索阶段,可以使用基于词汇的搜索,例如使用Elasticsearch这样的向量搜索引擎,或者使用基于双编码器(bi-encoder)的密集检索。然而,检索系统可能会检索到与搜索查询不太相关的文档。
-
在第二阶段,我们使用基于交叉编码器(cross-encoder)的重排器来对所有候选文档针对给定搜索查询的相关性进行评分。
from sentence_transformers.cross_encoder import CrossEncoder
# 1. Load a pretrained CrossEncoder model
model = CrossEncoder("cross-encoder/stsb-distilroberta-base")
# We want to compute the similarity between the query sentence...
query = "A man is eating pasta."
# ... and all sentences in the corpus
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"A cheetah is running behind its prey.",
]
# 2. We rank all sentences in the corpus for the query
ranks = model.rank(query, corpus)
# Print the scores
print("Query: ", query)
for rank in ranks:
print(f"{rank['score']:.2f}\t{corpus[rank['corpus_id']]}")
文本聚类
from sklearn.cluster import KMeans
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"A man is eating pasta.",
"The girl is carrying a baby.",
"The baby is carried by the woman",
"A man is riding a horse.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"Someone in a gorilla costume is playing a set of drums.",
"A cheetah is running behind its prey.",
"A cheetah chases prey on across a field.",
]
corpus_embeddings = embedder.encode(corpus)
# Perform kmean clustering
num_clusters = 5
clustering_model = KMeans(n_clusters=num_clusters)
clustering_model.fit(corpus_embeddings)
cluster_assignment = clustering_model.labels_
clustered_sentences = [[] for i in range(num_clusters)]
for sentence_id, cluster_id in enumerate(cluster_assignment):
clustered_sentences[cluster_id].append(corpus[sentence_id])
for i, cluster in enumerate(clustered_sentences):
print("Cluster ", i + 1)
print(cluster)
print("")
特征量化
嵌入量化(Embedding Quantization)是一种用于优化大规模向量检索的技术,它通过减少嵌入向量中每个值的大小来解决内存和存储问题。
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
# 1. Load an embedding model
model = SentenceTransformer("all-MiniLM-L6-v2")
# 2a. Encode some text using "binary" quantization
binary_embeddings = model.encode(
["I am driving to the lake.", "It is a beautiful day."],
precision="binary",
)
# 2b. or, encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
binary_embeddings = quantize_embeddings(embeddings, precision="binary")
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 16
16 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

{kind=link}
所有评论(0)