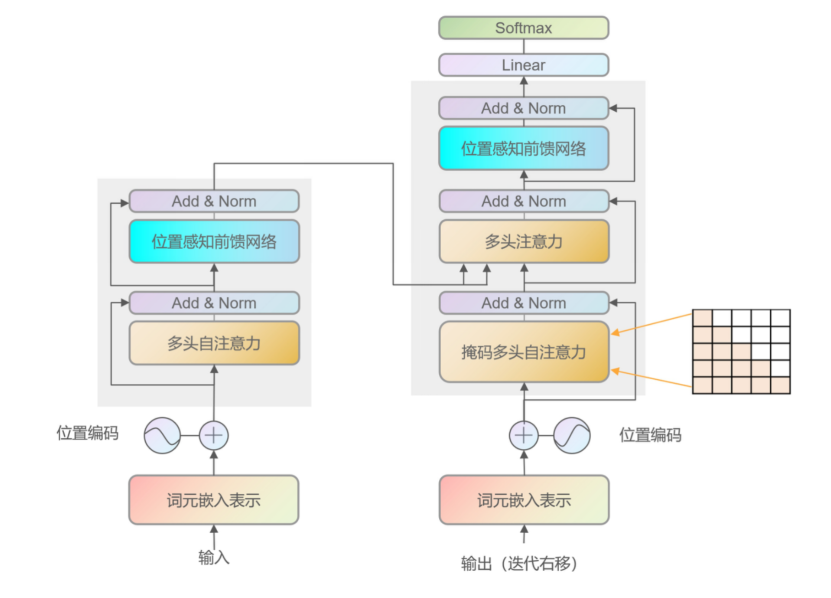
Transformer中的位置编码
在Transformer模型中,位置编码是一种特殊的编码方式,用于向模型提供关于输入序列中单词位置的信息。由于Transformer模型没有循环结构,无法像循环神经网络那样从输入序列中推断单词的位置顺序,因此需要引入位置编码来帮助模型理解单词在序列中的位置信息。Transformer 架构由于其自注意力机制 (Self-Attention Mechanism) 的特性,对序列中的元素没有固有的顺序
在Transformer模型中,位置编码是一种特殊的编码方式,用于向模型提供关于输入序列中单词位置的信息。由于Transformer模型没有循环结构,无法像循环神经网络那样从输入序列中推断单词的位置顺序,因此需要引入位置编码来帮助模型理解单词在序列中的位置信息。
自注意机制(Self-Attention Mechanism)
Transformer 架构由于其自注意力机制 (Self-Attention Mechanism) 的特性,对序列中的元素没有固有的顺序感知。这意味着,如果不加以处理,Transformer 无法区分序列中的元素的相对位置。为了解决这个问题,位置编码被引入。

自注意力机制
在上图中的嵌入表示x1,x2中如果没有位置信息,打乱输入的词序后,会导致Attention之后得到的分数没有变化。对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
采用Attention结构,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解决这种问题的方法。
位置编码 (Positional Encoding)
位置编码通常是通过在输入的词嵌入向量中添加特定的位置信息来实现的。这样一来,每个单词的词嵌入向量不仅包含单词的语义信息,还包含了关于单词在序列中位置的信息。位置编码的引入有助于Transformer模型更好地处理序列数据,特别是在处理长序列时,位置编码可以帮助模型区分不同位置的单词,从而提高模型的性能和泛化能力。
Transformer中的自注意力机制无法捕捉位置信息,这是因为其计算过程具有置换不变性(permutation invariant),导致打乱输入序列的顺序对输出结果不会产生任何影响。

自注意力中加入位置编码
位置编码(Position Encoding)通过把位置信息引入输入序列中,以打破模型的全对称性。上面式子中,为简化问题,考虑在m,n位置处加上不同位置编码,将位置信息加入到输入序列中,相当于引入索引的嵌入,通过微调自注意力运算过程使其能分辨不同token之间的相对位置。
从上面式中可以看出,在Transformer模型的自注意机制中,位置编码通常有两种形式:绝对位置编码和相对位置编码。
-
绝对位置编码:绝对位置编码是通过在词嵌入向量中添加固定的位置信息来表示单词在序列中的绝对位置。通常采用固定的公式或矩阵来计算每个位置的位置编码。
-
相对位置编码:相对位置编码是根据单词之间的相对位置关系来计算位置编码。这种编码方式更加灵活,能够捕捉到不同单词之间的相对位置信息,有助于模型更好地理解序列中单词之间的关系。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第k个向量xk中加入位置向量pk,输入变为xk+pk,其中pk只依赖于位置编号k。
1. 可学习
绝对位置编码的一个最朴素方案是不特意去设计什么,而是直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。
对于这种训练式的绝对位置编码,一般的认为它的缺点是没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调。
2. 三角式
三角函数式位置编码,一般也称为Sinusoidal位置编码,

其中pk,2i,pk,2i+1,分别是位置k的编码向量的第2i,2i+1个分量,d是位置向量的维度。三角函数式位置编码的特点是有显式的生成规律,因此可以期望于它有一定的外推性,由于sin(α+β)=sinαcosβ+cosαsinβ,cos(α+β)=cosαcosβ−sinαsinβ,这表明位置α+β的向量可以表示成位置α和位置β的向量组合。
相对位置编码
旋转位置编码(ROPE)
作用在每个transformer层的自注意力块,在计算完Q/K后,旋转位置编码作用在Q/K上,再计算注意力分数;其通过绝对位置编码的方式实现了相对位置编码,有良好的外推性。目前的大模型LLaMA,GLM, PaLM均用了相对ROPE位置编码。

旋转位置编码(ROPE)
ALiBi(Attention with Linear Biases)
在计算完注意力分数之后,直接为注意力分数矩阵上加上一个预设好的偏置矩阵,计算简洁;ALiBi的偏置矩阵根据Q和K的相对距离来惩罚注意力分数,相对距离越大,惩罚项越大。相当于两个token的距离越远,相互贡献就越小。ALiBi有良好的外推性。目前的大模型BLOOM用了ALiBi位置编码。

PS:欢迎扫码头像关注公众号^_^.


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)